作者:@小萌新
专栏:@网络
作者简介:大二学生 希望能和大家一起进步
本篇博客简介:简单介绍传输层和UDP协议
UDP协议
- 传输层
- 端口号
- 端口号范围划分
- 知名端口号
- 端口号与进程
- netstat与iostat
- pidof
- UDP协议
- UDP协议格式
- udp的数据封装
- udp的数据解包
- UDP协议的特点
- UDP的缓冲区
- UDP使用注意事项
- 基于UDP的应用层协议
传输层
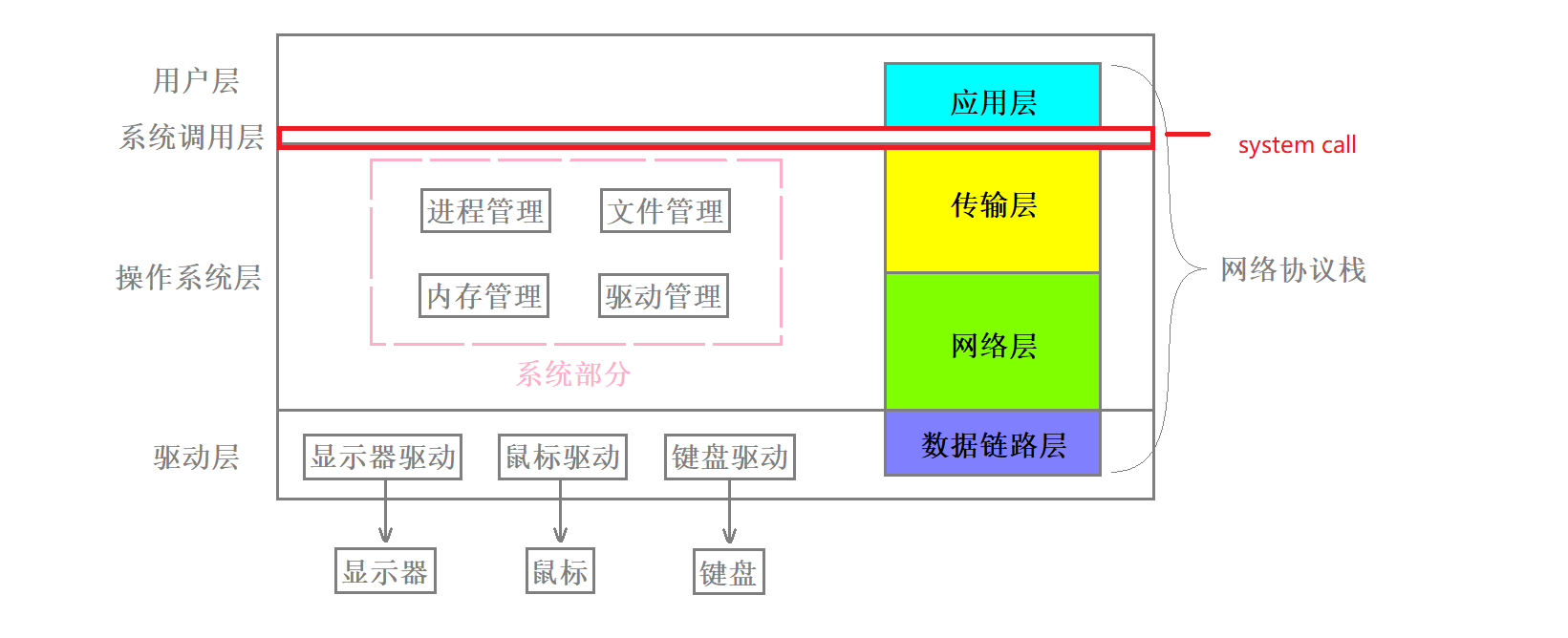
我们使用的TCP/IP协议中可以简单的把网络划分为四个部分
自顶向下分别是应用层 传输层 网络层和数据链路层
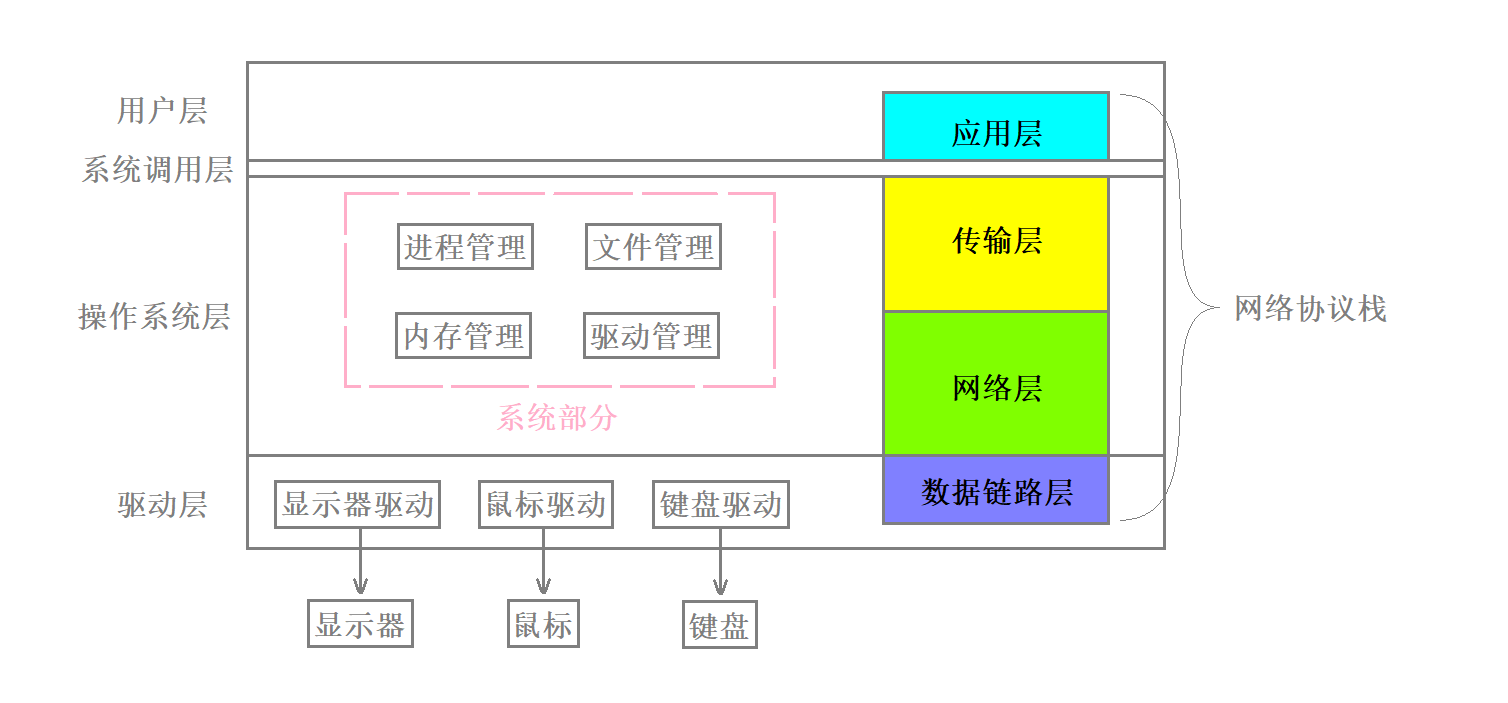
其中我们的HTTP协议就是应用层的协议 它是基于传输层的TCP协议设计的 与此同时传输层还有一个UDP协议
我们之前在学习HTTP协议等应用层协议的时候一般是认为它直接将访问和请求发送到了网络中 但是实际上并不是这样子的 实际过程中应用层会将数据交付给传输层 由传输层进行处理后再向下交付 该过程会贯穿整个网络协议栈
传输层主要是负责可靠性传输 也就是说要保证数据可靠的从一端到另一端 再下面的学习中 为了方便我们对于本层协议的学习我们忽视下面两层协议的作用 认为传输层和对面的传输层是直接沟通的
端口号
端口号在网络中可以唯一的标识一台主机上的一个进程
当主机从网络上获取数据之后 这个数据要交给哪个应用程序就是由端口号决定的
从网络中获取的数据在进行向上交付时 在传输层就会提取出该数据对应的目的端口号 进而确定该数据应该交付给当前主机上的哪一个服务进程
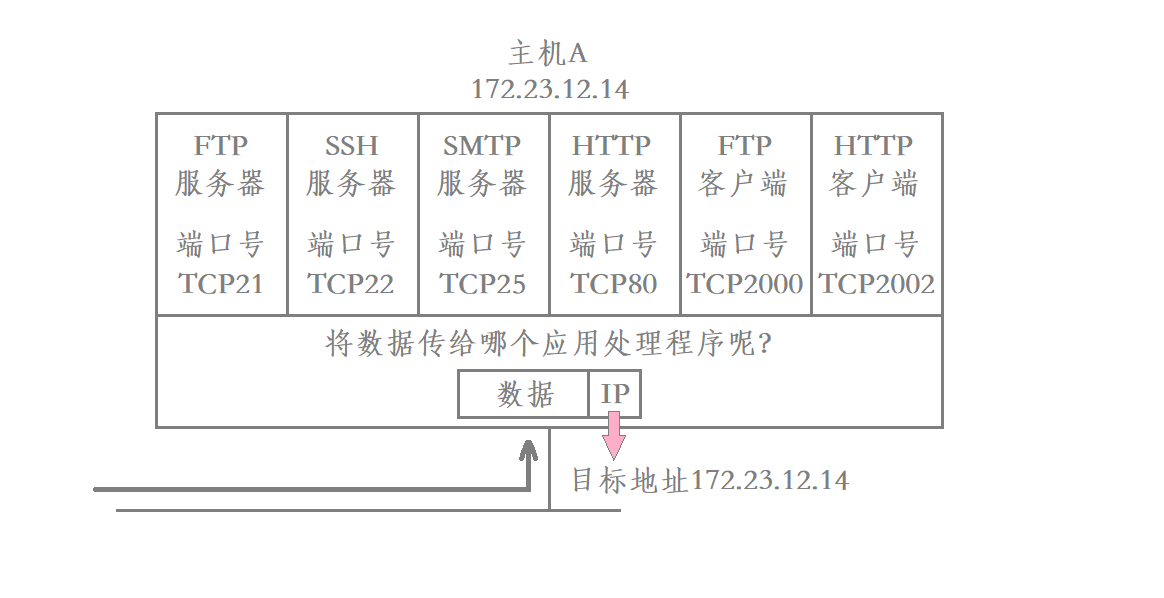
因此端口号是属于传输层的概念的 在传输层协议的报头当中就会包含与端口相关的字段
五元组标识一个通信
在TCP/IP协议中 用“源IP地址” “源端口号” “目的IP地址” “目的端口号” “协议号”这样一个五元组来标识一个通信
比如有多台客户端主机同时访问服务器 这些客户端主机上可能有一个客户端进程 也可能有多个客户端进程 它们都在访问同一台服务器
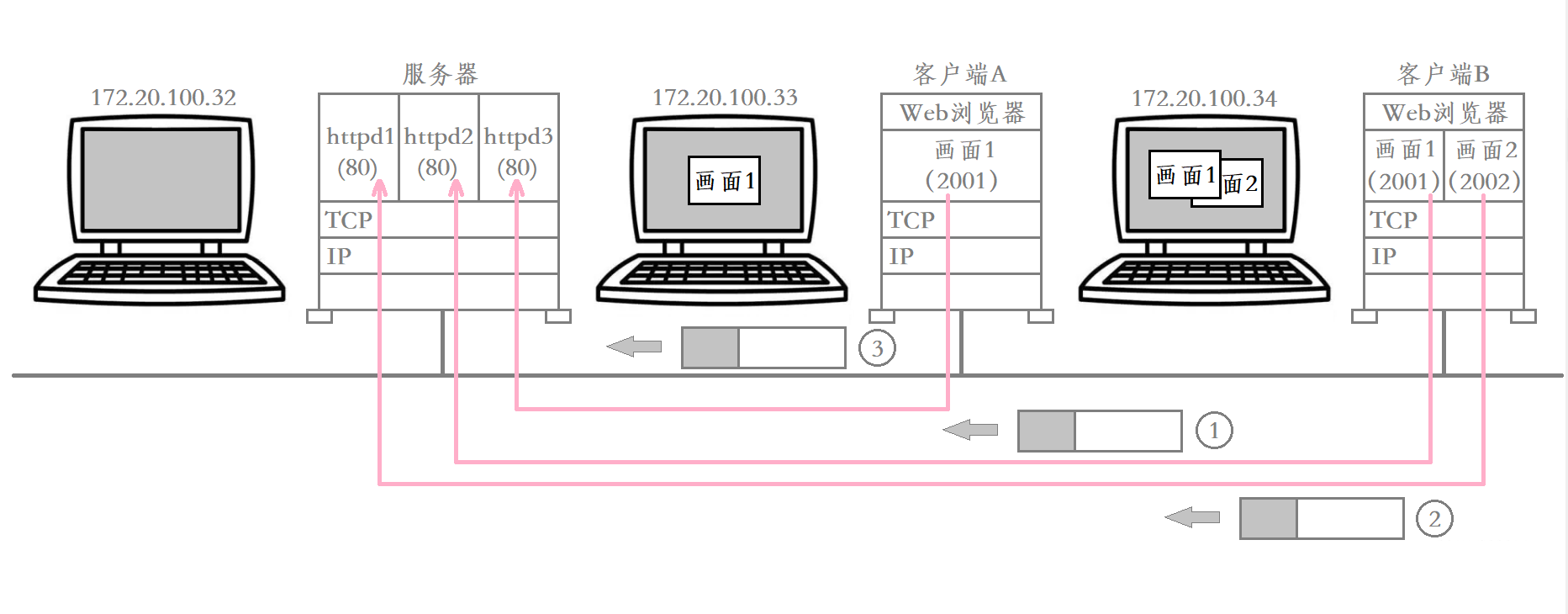
而这台服务器就是通过“源IP地址” “源端口号” “目的IP地址” “目的端口号” “协议号”来识别一个通信的
- 先提取出数据当中的目的IP地址和目的端口号 确定该数据是发送给当前服务进程的
- 然后提取出数据当中的协议号 为该数据提供对应类型的服务
- 最后提取出数据当中的源IP地址和源端口号 将其作为响应数据的目的IP地址和目的端口号 将响应结果发送给对应的客户端进程
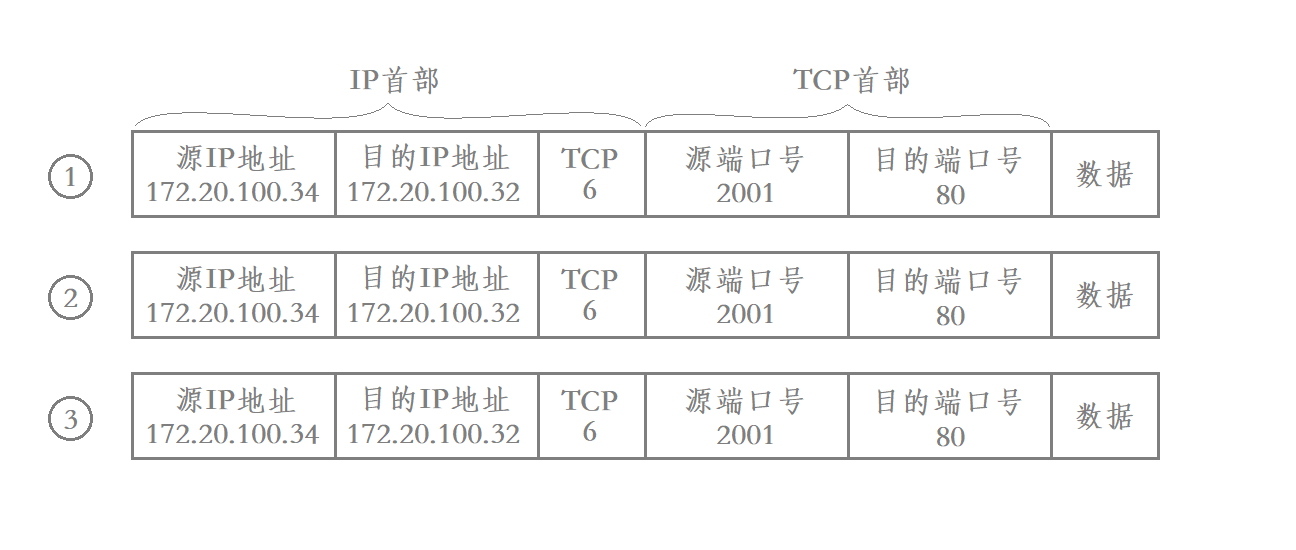
通过netstat命令可以查看到这样的五元组信息
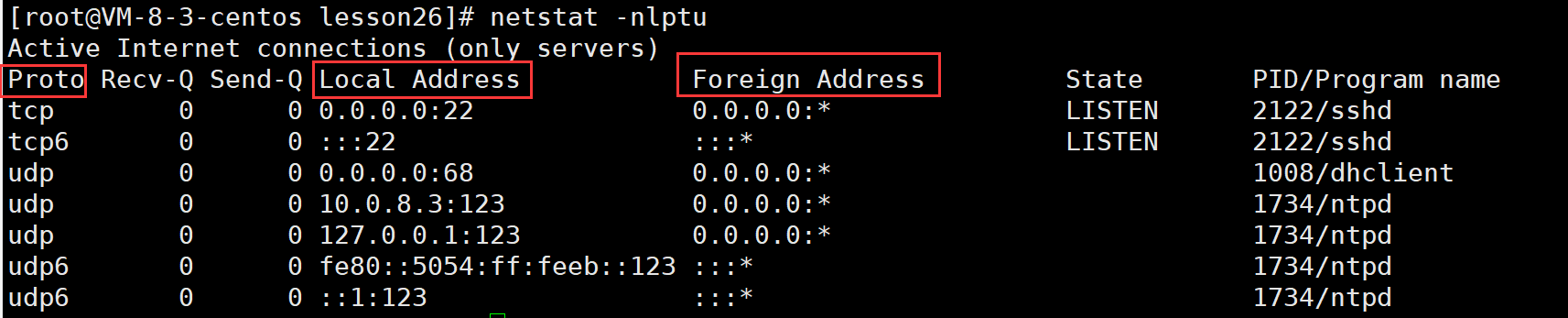
- Proto – 协议号
- Local Address – 源IP地址和源端口号
- Foreign Address – 目的IP地址和目的端口号
协议号 VS 端口号
协议号传输层中一般是指TCP或者是UDP协议 它存在于IP的报头中
因为传输层是有两个协议的TCP/UDP协议 所以说携带协议号的目的是让网络层明白应该交付给传输层的哪个数据
端口号是存在于UDP和TCP报头当中的
携带端口号的目的是让传输层明白应该交付给网络层的哪个进程
也就是说协议号是作用于传输层和网络层之间的 端口号是作用于应用层于传输层之间的
端口号范围划分
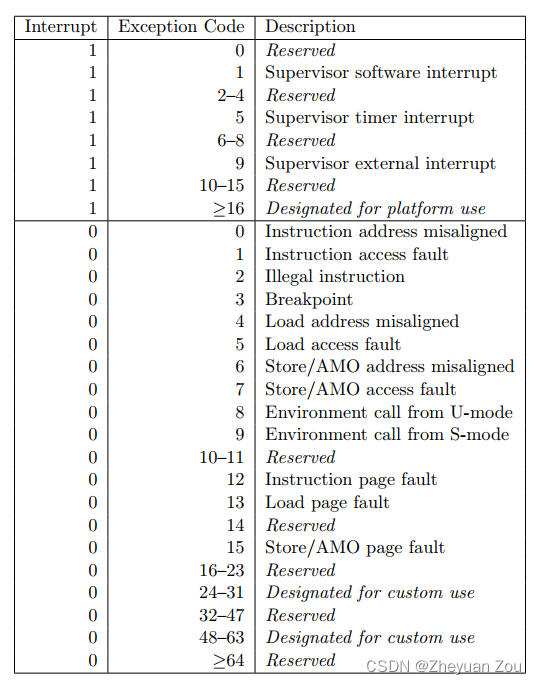
端口号的长度是16位 因此端口号的范围是0 ~ 65535:
- 0 ~ 1023:知名端口号 比如HTTP FTP SSH等这些广为使用的应用层协议 它们的端口号都是固定的
- 1024 ~ 65535:操作系统动态分配的端口号 客户端程序的端口号就是由操作系统从这个范围分配的
知名端口号
常见的知名端口号
有些服务器的端口号是常见的固定端口号 比如:
- ssh服务器 22号端口
- ftp服务器 21号端口
- telnet服务器 23号端口
- http服务器 80号端口
- https服务器 443号端口
查看知名端口号
我们可以通过查看/etc/services文件来查看一些知名的端口号 该文件是记录网络服务名和它们对应使用的端口号及协议
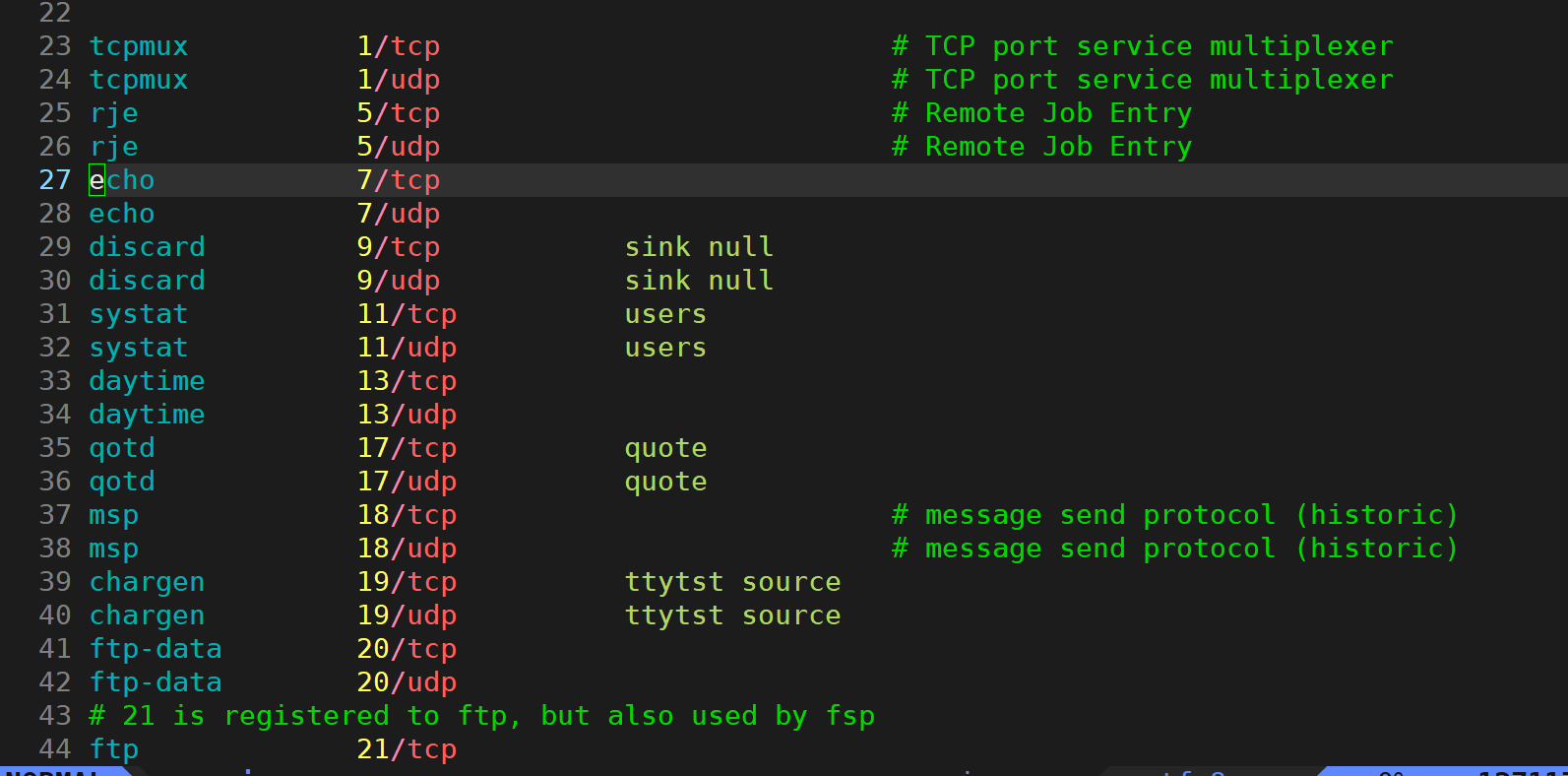
端口号与进程
端口号进程之间并不是简单的一对一关系 下面的两个问题可以很好的说明
一个端口号只能对应一个进程嘛?
是的 一个端口号只能对应一个进程
因为端口号的作用就是在网络中唯一标识一个进程 如果一个端口号不是唯一对应一个进程就失去意义了
一个进程只能对应一个端口号嘛?
不是 一个进程可以对应多个端口号
因为这和“端口号必须唯一标识一个进程没有冲突”
netstat与iostat
netstat命令
netstat是一个用来查看网络状态的重要工具
其常见的选项如下:
- n:拒绝显示别名 能显示数字的全部转换成数字
- l:仅列出处于LISTEN(监听)状态的服务
- p:显示建立相关链接的程序名
- t(tcp):仅显示tcp相关的选项
- u(udp):仅显示udp相关的选项
- a(all):显示所有的选项 默认不显示LISTEN相关
我们可以这样子使用
查看tcp相关网络信息
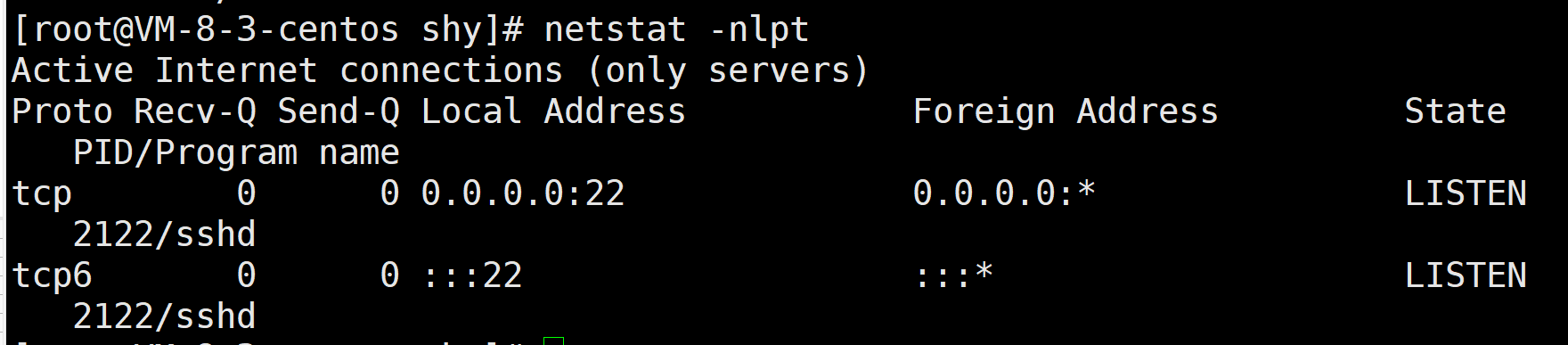
查看udp相关网络信息
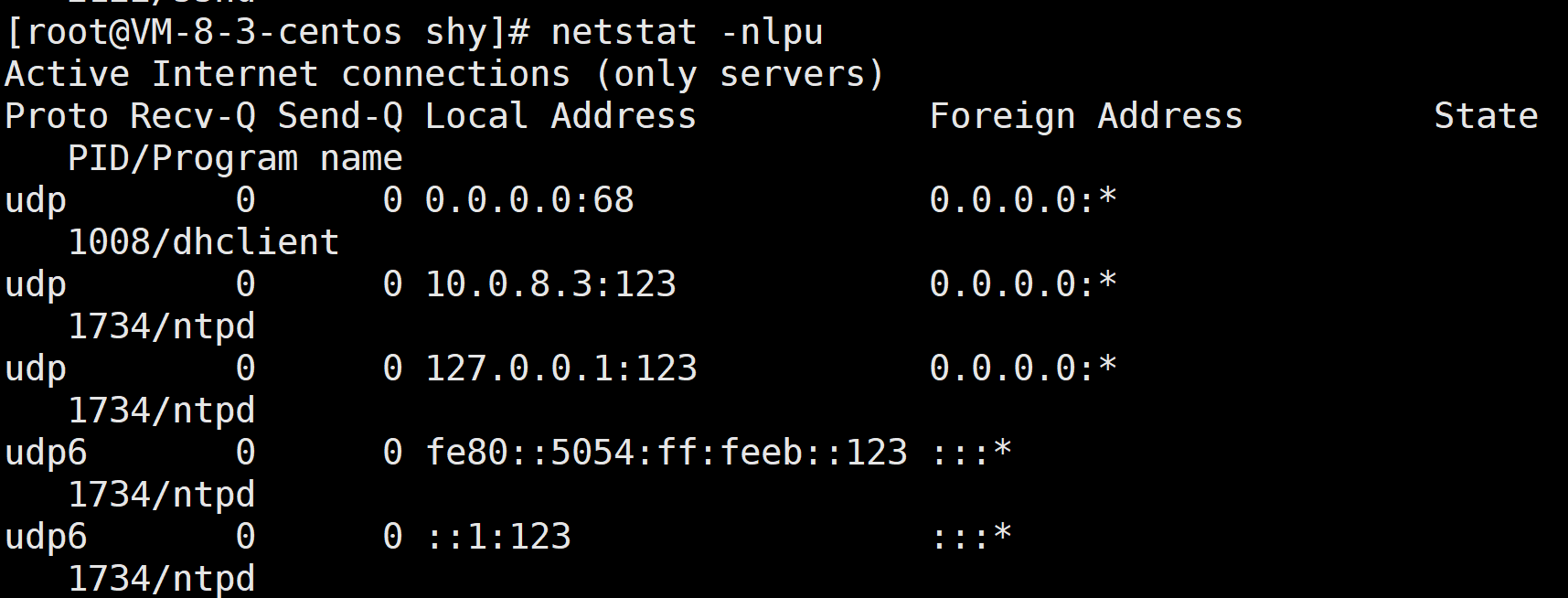
查看除LISTEN状态以外的信息
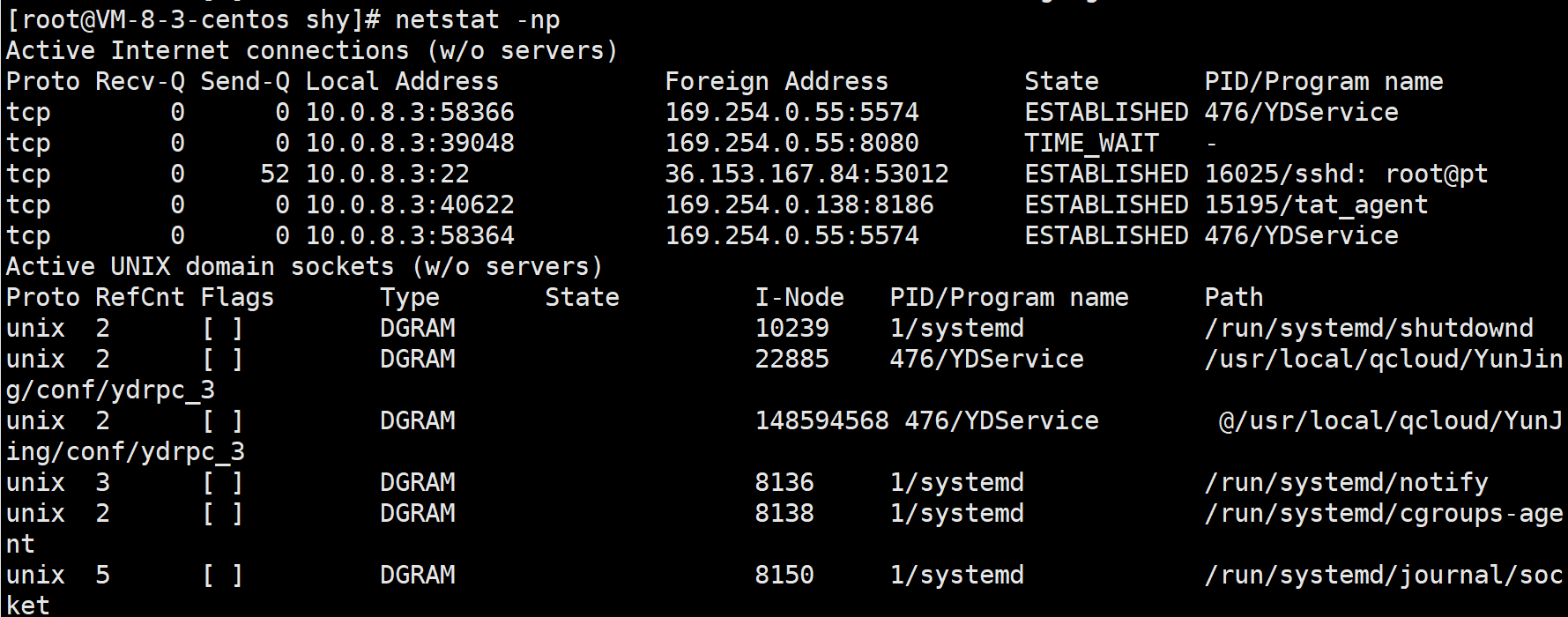
这里给大家一个记忆的小技巧
只需要记住 nlp + 查询的协议就可以了 t是tcp u是udp
iostat命令
iostat主要用于输出磁盘IO和CPU的统计信息
其常见的选项如下:
- c:显示CPU的使用情况
- d:显示磁盘的使用情况
- N:显示磁盘列阵(LVM)信息
- n:显示NFS使用情况
- k:以KB为单位显示
- m:以M为单位显示
- t:报告每秒向终端读取和写入的字符数和CPU的信息
- V:显示版本信息
- x:显示详细信息
- p:显示磁盘分区的情况
比如我们要查看磁盘IO和CPU的详细信息
CPU属性值说明:
- %user:CPU处在用户模式下的时间百分比
- %nice:CPU处在带NICE值的用户模式下的时间百分比
- %system:CPU处在系统模式下的时间百分比
- %iowait:CPU等待输入输出完成时间的百分比
- %steal:管理程序维护另一个虚拟处理器时 虚拟CPU的无意识等待时间百分比
- %idle:CPU空闲时间百分比
pidof
pidof命令可以通过进程名 查看进程id

我们可以使用它来配合kill命令快速杀死一个进程

UDP协议
UDP协议格式
UDP的位置
网络套接字编程时用到的各种接口 是位于应用层和传输层之间的一层系统调用接口 这些接口是系统提供的
我们可以通过这些接口搭建上层应用 比如HTTP 我们经常说HTTP是基于TCP的
实际就是因为HTTP在TCP套接字编程上搭建的
而socket接口往下的传输层实际就是由操作系统管理的 因此UDP是属于内核当中的 是操作系统本身协议栈自带的 其代码不是由上层用户编写的 UDP的所有功能都是由操作系统完成 因此网络也是操作系统的一部分
UDP协议格式
UDP协议格式如下:
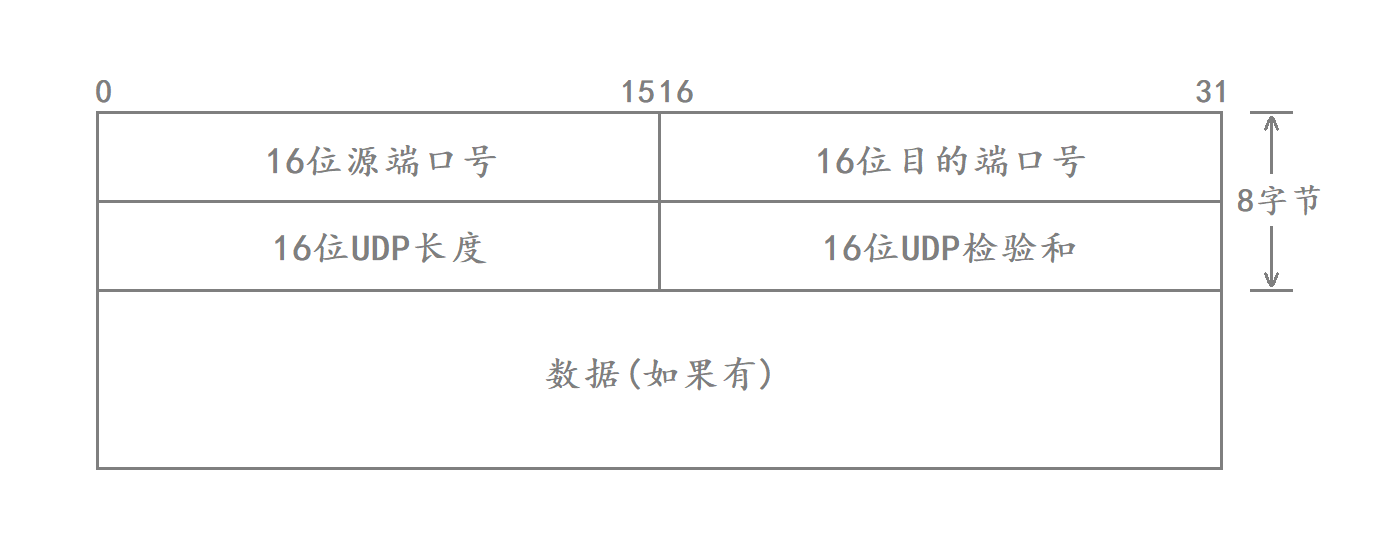
其中
- 16位源端口号表示数据从哪里来
- 16位目的端口号标识数据要去哪里
- 16位UDP长度:表示整个数据报(UDP首部+UDP数据)的长度
- 16位UDP检验和:如果UDP报文的检验和出错 就会直接将报文丢弃
我们在应用层看到的端口号大部分都是16位的 其根本原因就是因为传输层协议当中的端口号就是16位的
下面我们会通过几个问题来更好的理解UDP协议
UDP如何将报头与有效载荷进行分离?
UDP的报头当中只包含四个字段 每个字段的长度都是16位 总共8字节
因此UDP采用的实际上是一种定长报头 UDP在读取报文时读取完前8个字节后剩下的就都是有效载荷了
这也是16位UDP长度存在的意义 – 将报头和有效载荷进行分离
UDP如何决定将有效载荷交付给上层的哪一个协议?
UDP上层也有很多应用层协议 因此UDP必须想办法将有效载荷交给对应的上层协议 也就是交给应用层对应的进程
应用层的每一个网络进程都会绑定一个端口号 服务端进程必须显示绑定一个端口号 客户端进程则是由系统动态绑定的一个端口号 UDP就是通过报头当中的目的端口号来找到对应的应用层进程的
至于通过端口号能找到进程ID的原因是因为内核中用哈希的方式维护了端口号与进程ID之间的映射关系
传输层可以通过端口号得到对应的进程ID 进而找到对应的应用层进程
如何理解报头?
操作系统是C语言写的 而UDP协议又是属于内核协议栈的 因此UDP协议也一定是用C语言编写的 UDP报头实际就是一个位段类型
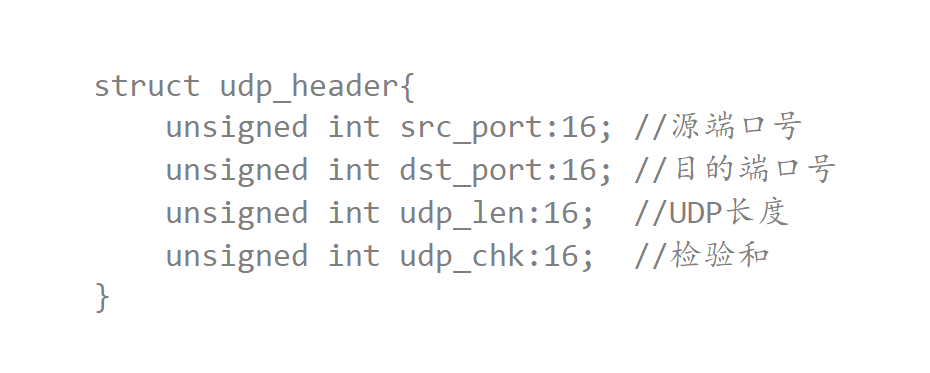
udp的数据封装
- 当应用层将数据交给传输层后 在传输层就会创建一个UDP报头类型的变量 然后填充报头当中的各个字段 此时就得到了一个UDP报头
- 此时操作系统再在内核当中开辟一块空间 将UDP报头和有效载荷拷贝到一起 此时就形成了UDP报文
udp的数据解包
- 当传输层从下层获取到一个报文后 就会读取该报文的钱8个字节 提取出对应的目的端口号
- 通过目的端口号找到对应的上层应用层进程 然后将剩下的有效载荷向上交付给该应用层进程
UDP协议的特点
应用层交给UDP多长的报文 UDP就原样发送 既不会拆分 也不会合并 这就叫做面向数据报
也就是说我们如果使用UDP传输一百字节的数据的话
我们发送端调用一次sendto 发送100字节的数据 那么接收端也必须调用对应的一次recvfrom 接收100个字节的数据
如果我们发送端调用了十次sendto 发送100字节的数据 每次发送十字节 那么接收端也必须调用十次recvfrom来接受这100字节的数据
UDP的缓冲区
UDP没有真正意义上的发送缓冲区 调用sendto会直接交给内核 由内核将数据传给网络层协议进行后续的传输动作
UDP具有接收缓冲区 但是这个接收缓冲区不能保证收到的UDP报的顺序和发送UDP报的顺序一致 如果缓冲区满了 再到达的UDP数据就会被丢弃
UDP的socket既能读也能写 所以说UDP是一种全双工的通信方式
为什么UDP要有接收缓冲区?
我们假设以下 如果UDP没有接收缓冲区会是一种什么样的情况
如果UDP没有接收缓冲区的话 那么就会要求上层立马将UDP获取到的报文读取上去
如果一个报文在UDP没有被读取 那么此时UDP从底层获取上来的报文数据就会被迫丢弃
但是这实际上是一种十分浪费网络资源的行为 一个报文花费了时间资源从一个主机的一端经过网络到另一个主机的一端 如果仅仅是因为没有及时读取就废弃掉一个可能没有错误的报文 那么大量的网络资源将会被浪费
因此UDP本身是会维护一个接收缓冲区 当有新的UDP报文到来时就会把这个报文放到接收缓冲区当中 此时上层在读数据的时就直接从这个接收缓冲区当中进行读取就行了
如果UDP接收缓冲区当中没有数据那上层在读取时就会被阻塞 因此UDP的接收缓冲区的作用就是 将接收到的报文暂时的保存起来 供上层读取
UDP使用注意事项
需要注意的是 UDP协议报头当中的UDP最大长度是16位的 因此一个UDP报文的最大长度是64K(包含UDP报头的大小)
然而64K在当今的互联网环境下 是一个非常小的数字 如果需要传输的数据超过64K 就需要在应用层进行手动分包 多次发送 并在接收端进行手动拼装
基于UDP的应用层协议
- NFS:网络文件系统
- TFTP:简单文件传输协议
- DHCP:动态主机配置协议
- BOOTP:启动协议(用于无盘设备启动)
- DNS:域名解析协议
当然 也包括你自己写UDP程序时自定义的应用层协议








![【群智能算法】一种改进的哈里斯鹰优化算法 IHHO算法[1]【Matlab代码#17】](https://img-blog.csdnimg.cn/cb50fe5045ea40ea85e0a17860ae65aa.png)