目录
- 本章重点
- 简单动态字符串SDS
- 集合底层实现原理
- zipList
- listPack
- skipList
- quickList
- Key 与Value中元素的数量
本章重点
- 掌握Redis简单动态字符串
- 了解Redis集合底层实现原理
简单动态字符串SDS
- SDS简介
我们Redis中无论是key还是value其数据类型都是字符串.我们Redis中的字符串是如何存储的呢?虽然我们的Redis是用C语言开发的,但是并没有直接套用其字符串形式.自定义了一种字符串.这种字符串结构简单,功能强大,称为简单动态字符串(Simple Dynamic String) 简称SDS
Redis中的字符串并非都是SDS,字面常量是C字符串
- SDS结构
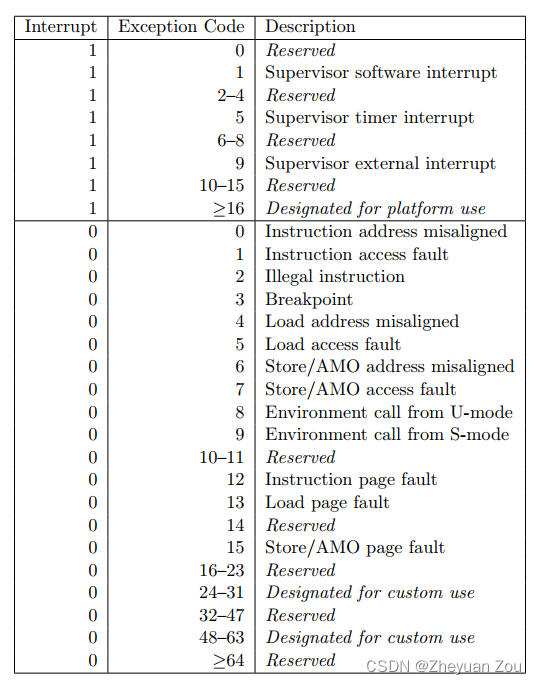
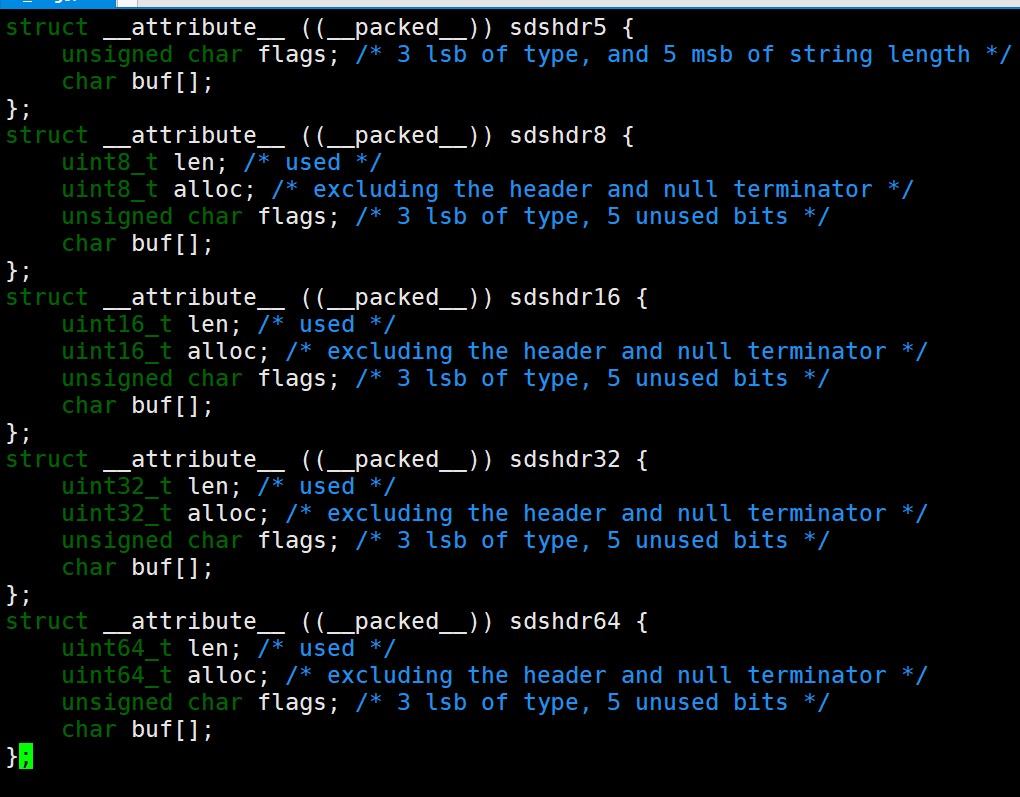
SDS是一个结构体,定义在Redis安装目录下的
src/sds.h中
sturct sdshdr
{
//字节数组,用于保存字符串
char buf[];
//buf[]中已使用的字节数量,称为SDS长度
int len;
//buf[]中尚未使用的字节数量
int free;
}
我们可以查看src/sds.h定义
例如我们执行一个set name "hello redis"命令时,这里的字符串是字面常量,在Redis存储方式如下:
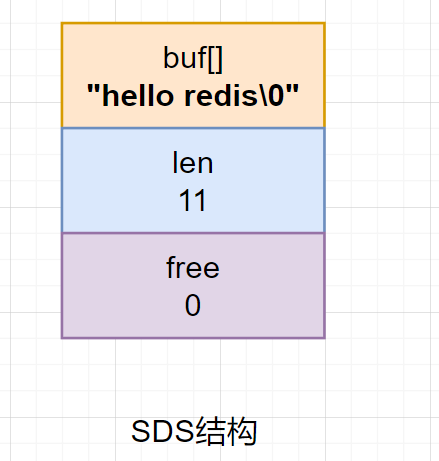
这里的\0是需要储存在buf中的,但是不记录长度len!
- SDS优势
- 字符串长度获取性能高,无需遍历字符串
- 保证二进制安全,我们的C字符串真能在字符串结尾出现
\0,而在图片,音频,视频等二进制文件数据以\0作为分隔符情况很是常见,所以C字符串无法保存其二进制数据,而SDS可以通过len判断字符串结尾位置.读取到什么,就存储,无需其他过滤操作即可!- 减少内存再分配次数,SDS采用了空间预分配策略和惰性空间释放策略,来避免再分配空间问题!
1.如果len<1M,那么free空间大小和len相同.
2.len>=1M,free固定大小=1M
如果sds长度len减小,那么free也不会释放,等到后期再次分配使用
如需释放可以手工调用函数释放- 兼容C函数
因为保留的C语言的\0我们的SDS也可以使用C语言字符串函数 strcmp等
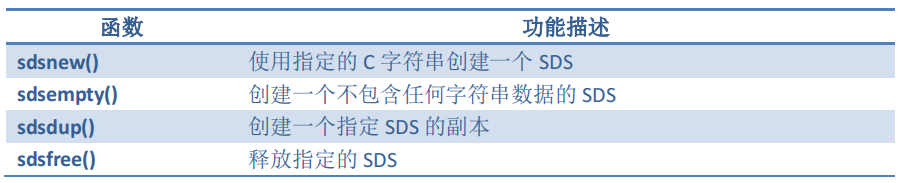
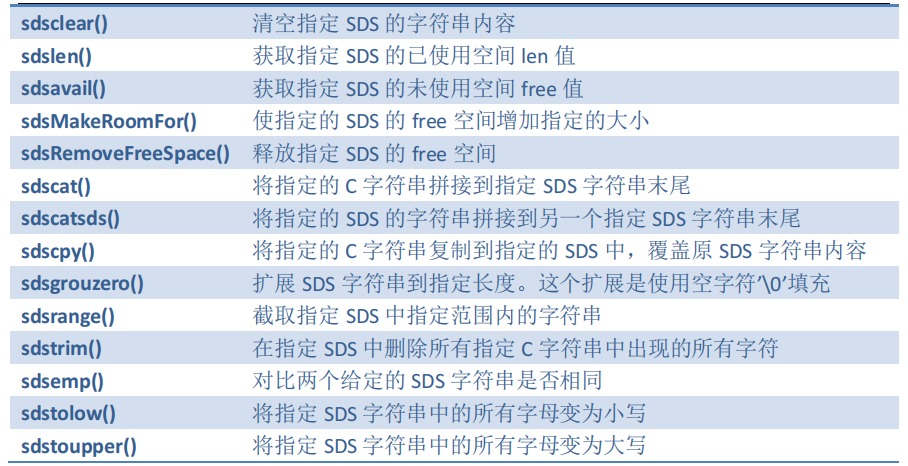
- 常用的SDS操作函数
集合底层实现原理
Redis中对于Set类型底层的实现,直接采用了hashTable,但是对于Hash,Zset,List集合的底层进行了特殊设计,保证Redis的高性能
- 2种实现的选择
对于Hash和Zset集合,其底层实现实际有2种:压缩
zipList和跳跃列表skipList
这两种实现,用户都是透明的,系统会根据用户写入数据的不同,选择不同的的实现.只有同时满足了配置文件redis.conf中配置d相关集合元素个阈值和元素大小阈值两个条件使用的就是压缩链表zipList.例如Zset集合满足下面2个条件就是zipList
- 集合元素个数
小于redis.conf 中zset-max-ziplist-entries属性的值,其默认值为128- 每个集合元素大小都
小于redis.conf 中zset-max-ziplist-value属性的值,其默认值为64字节
zipList
-
zipList
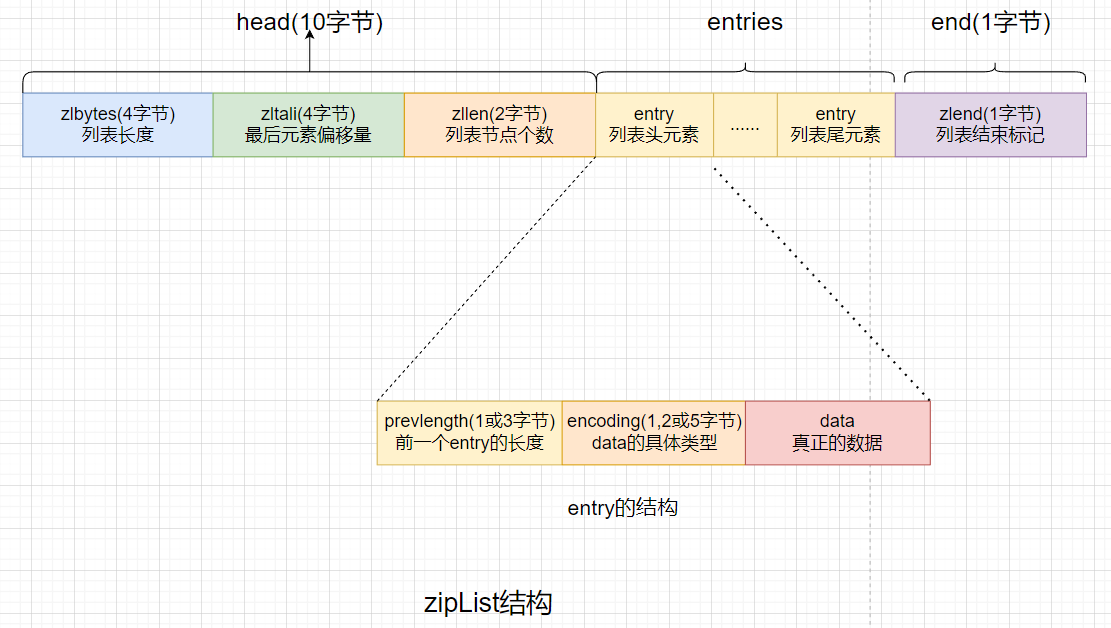
zipList通常称为压缩链表,是经过特殊编码的用于存储字符串或整数的的双向链表.其底层由3部分构成!
head,entries,end.这3部分在空间上是连续存放的.- head
head由3部分构成:
- zlbytes:占4个字节,用于存放整个ziplist的数据结构所占字节数,包括zlbytes本身长度!
- zltail:占用4个字节,用于存放最后一个entry在整个数据结构的偏移量(字节)可以快速定位列表尾位置,以便操作!
- zllen:占2个字节,用于存放列表包含的entry个数,由于只有16位,所有最多ziplist只能有65535个entry
- entries
entries是真正的列表,由很多的entry元素构成,由于不同的元素类型,数值的不同,从而导致entries的长度不同,entry也由3部分构成
- prevlength:记录上一个entry的长度,用于实现逆序遍历,默认长度为1个字节,如果上一个entry长度大于了254字节,prevlength就会扩展到3个字节
- encoding:该部分用于标志后面的data数据类型,如果data是整数,encoding部分长度为1个字节,如果是字符串类型,那么可能为1个字节/2/5个字节长度,由于data数据长度的不同对应的encoding长度也不同.
- end
end自包含一部分zlend占1个字节,是ziplist的结束标志. 二进制8个1固定255!
listPack
- listPack
对于我们的ziplist的entry结构,由于其实现的逆序遍历,保存了前一个entry的大小,如果进行了中间修改或者插入操作,会导致级联更新,影响性能.为了实现更紧凑,更快解析,更简单的实现,重写了实现了ziplist命名为listPack.
在Redis7.0已经将zipList全部替换成了listPack,为了兼容保留了zipList的相关属性!
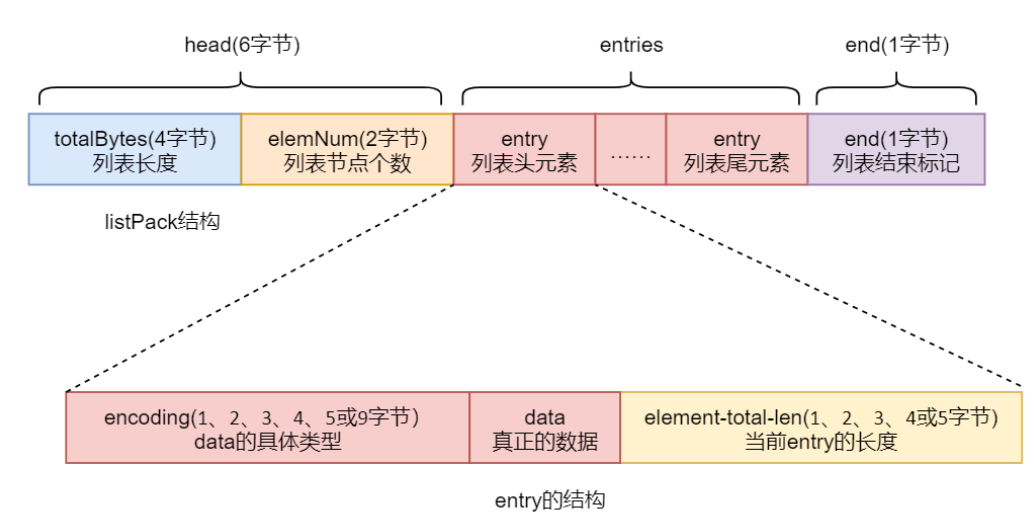
listPack结构
listPack是经过特殊编码的用于存储字符串或整数的双向链表.底层数据结构也由其3部分构成!
- head
head由2部分构成:
- totalBytes:占4个字节,用于存放listPack整个数据结构包含其本身长度,单位是字节
- elemNum:占2个字节,用于保存entry元素个数,最多为65535个!
- entry
这里就是和zipList的区别之处,这里没有了prevlength,增加了记录当前长度的element-total-len也可实现逆序遍历.而不会引发级联更新
- encoding:该部分用于标志后面的data的具体类型。如果data为整数类型,encoding 长度可能会是1、2、3、4、5或9字节。不同的字节长度,其标识位不同。如果data 为字符串类型,则encoding长度可能会是1、2或5字节。data字符串不同的长度,对应着不同的encoding长度。
- data:真正存储数据的位置,整数或者字符串类型,不同数据占用的字节长度不同
- element-total-len:记录当前entry长度,用于实现逆序遍历.可能的值[1,5]字节
- end
这里的end和zlend一样,都是结束标志,255,8个二进制1构成
skipList
- skipList
跳跃列表,简称跳表,是一种随机化的数据结构,基于并联的链表.实现简单,查询效率高.就是链表的一种不过在此基础上实现了跳跃功能.使得在查找元素具有较高的速率!
- 原理
skipList就是在list基础上随机增加一些高层指针,高层指针遍历效率高,层级越高,查找效率越高!我们可以先在高层遍历,然后再向下层级遍历查找指定位置
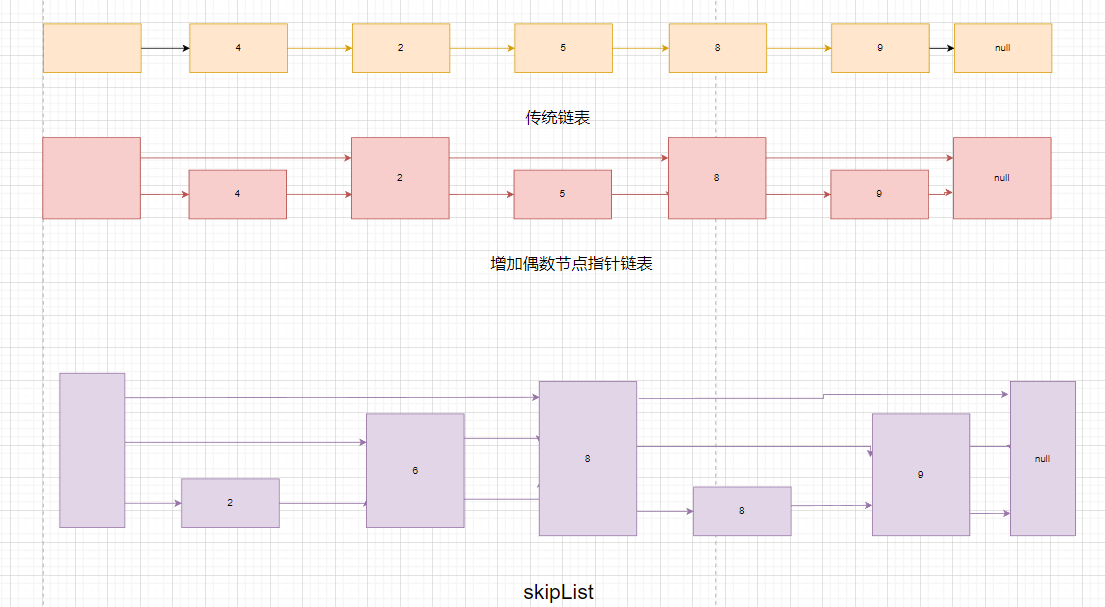
- 算法优化
这里的层级采用随机的方式,就有效的避免了按照指定规定元素个数的层级方式,插入或修改元素需要对链表的层级指针进行修改!而采用随机层级的方式就插入元素就随机层级,然后插入即可,删除也修改前后指针即可!
quickList
- quickList
快速链表,quickList本身是一个双向无循环链表.他的每一个节点都是一个zipList.由于zipList和linkedList都有明显不足,而quickList就进行了改进操作!
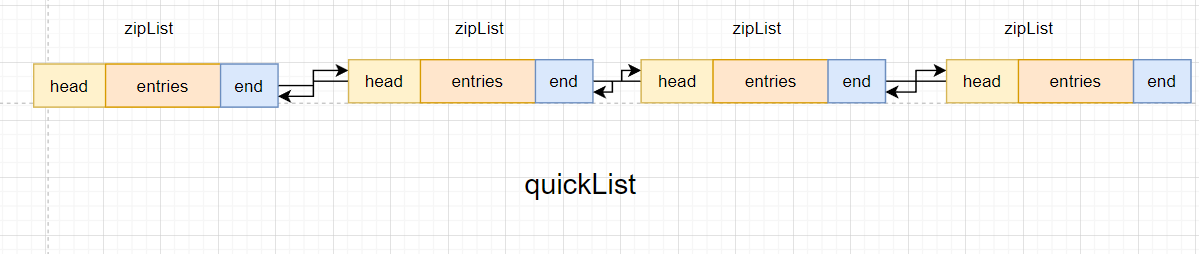
- 检索操作
我们的quickList可以通过zipList中head部分记录的totalNum进行检索!对其遍历的zipList的entry进行求和从而定位到指定的zipList的entry元素
- 插入操作
//设插入元素大小为: insertB
//查找到的插入位置元素大小为: zlB
//zipList最大值: zpMax
//前(后)一个元素大小: plB/nlB
1. insertB+zlB<=zpMax:
//直接插入zipList相应位置即可
2. insertB+zlB>zpMax 并且插入的位置位于元素首部位置
//2.1 insertB+plB<=zpMax:直接插入前一个元素尾部
//2.2 insetB+plB >zpMax: 构建一个新元素zipList然后连接到quickList
3. insertB+zlB>zpMax 并且插入的位置位于元素尾部位置
//3.1 insertB+nlB<=zpMax:直接插入前一个元素首部
//3.2 insetB+nlB >zpMax: 构建一个新元素zipList然后连接到quickList
4. insertB+zlB>zpMax 并且插入位置位于中间
//将当前zipList分割为2个zipList连接到quickList中,然后将元素插入到分割后的前一个元素的尾部位置
- 删除操作
直接删除即可,如果当前zipList已经没有元素了,就将当前zipList删除即可,然后修改指针连接
Key 与Value中元素的数量
- Redis最多可以处理
2^32个key(42亿) 实际每个Redis实例可以处理至少2.5亿个key- 每个Hash,List,Set,ZSet集合都可以包含
2^32个元素

![【群智能算法】一种改进的哈里斯鹰优化算法 IHHO算法[1]【Matlab代码#17】](https://img-blog.csdnimg.cn/cb50fe5045ea40ea85e0a17860ae65aa.png)