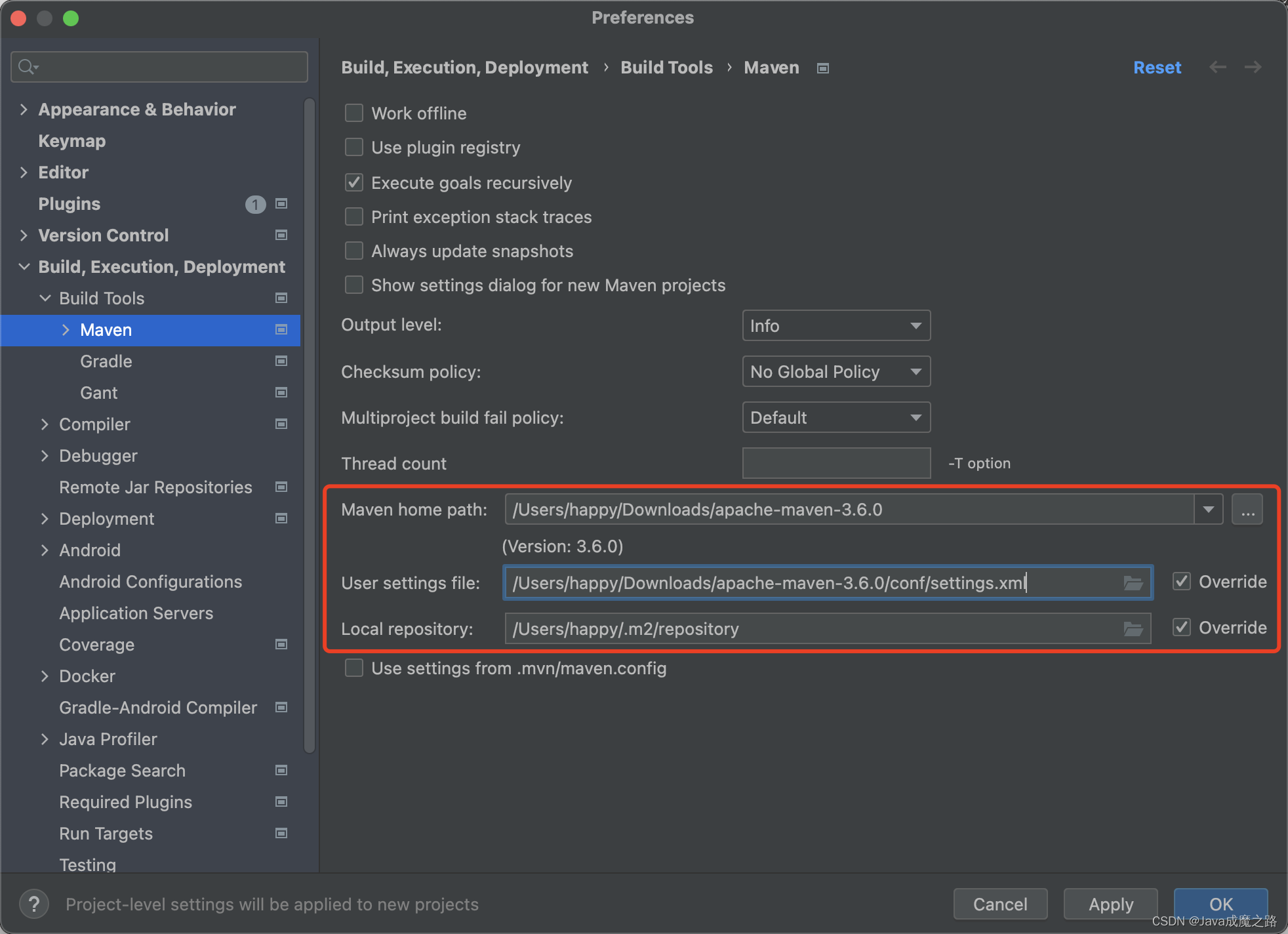
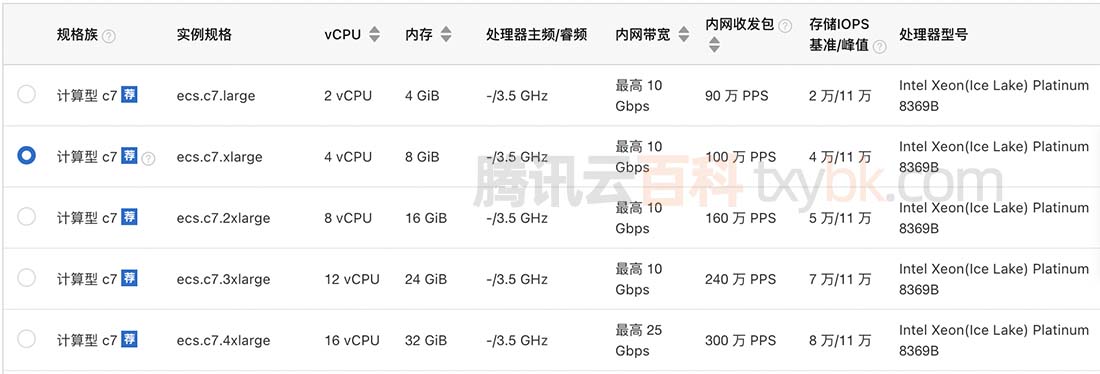
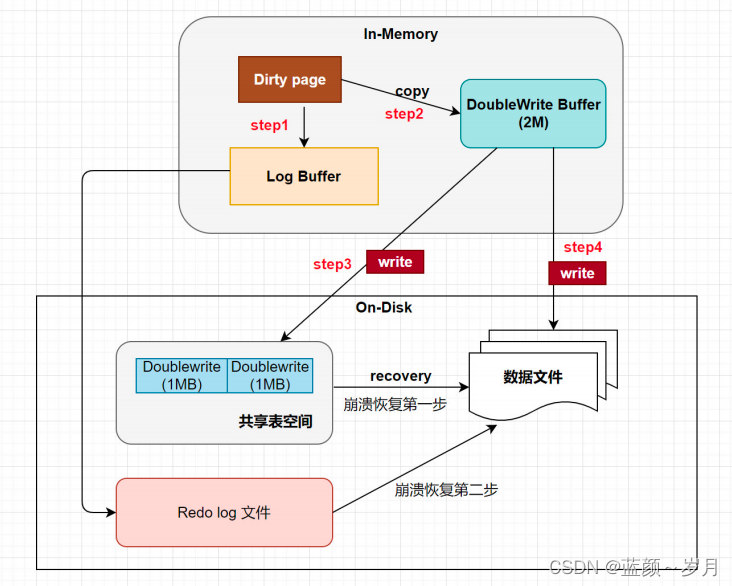
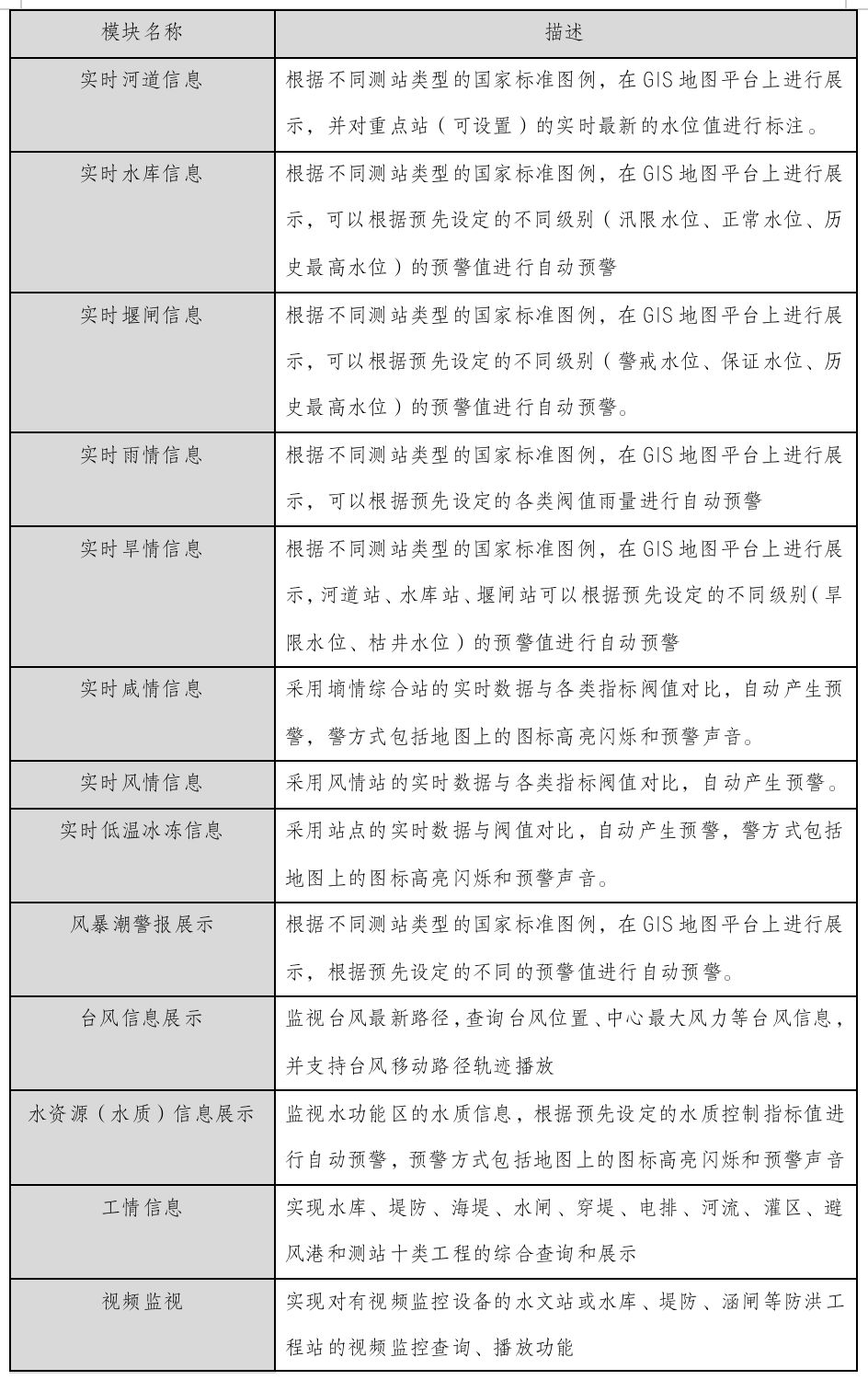
设备仪器仪表盘读数识别系统基于YoLov5网络模型分析技术,设备仪器仪表盘读数识别算法模型自动识别指针型仪表读数。Yolo算法采用一个单独的CNN模型实现end-to-end的目标检测,核心思想就是利用整张图作为网络的输入,直接在输出层回归 bounding box(边界框) 的位置及其所属的类别。YOLO系列算法是一类典型的one-stage目标检测算法,其利用anchor box将分类与目标定位的回归问题结合起来,从而做到了高效、灵活和泛化性能好。在介绍Yolo算法之前,我们回忆下RCNN模型,RCNN模型提出了候选区(Region Proposals)的方法,先从图片中搜索出一些可能存在对象的候选区(Selective Search),大概2000个左右,然后对每个候选区进行对象识别,但处理速度较慢。
如果你使用的是CNN分类器,那么滑动窗口是非常耗时的。但是结合卷积运算的特点,我们可以使用CNN实现更高效的滑动窗口方法。这里要介绍的是一种全卷积的方法,简单来说就是网络中用卷积层代替了全连接层,如图4所示。输入图片大小是16x16,经过一系列卷积操作,提取了2x2的特征图,但是这个2x2的图上每个元素都是和原图是一一对应的,如图上蓝色的格子对应蓝色的区域,这不就是相当于在原图上做大小为14x14的窗口滑动,且步长为2,共产生4个字区域。最终输出的通道数为4,可以看成4个类别的预测概率值,这样一次CNN计算就可以实现窗口滑动的所有子区域的分类预测。这其实是overfeat算法的思路。之所可以CNN可以实现这样的效果是因为卷积操作的特性,就是图片的空间位置信息的不变性,尽管卷积过程中图片大小减少,但是位置对应关系还是保存的。说点题外话,这个思路也被R-CNN借鉴,从而诞生了Fast R-cNN算法。
YOLOv5是一个在COCO数据集上预训练的物体检测架构和模型系列,它代表了Ultralytics对未来视觉AI方法的开源研究,其中包含了经过数千小时的研究和开发而形成的经验教训和最佳实践。YOLOv5是YOLO系列的一个延申,您也可以看作是基于YOLOv3、YOLOv4的改进作品。YOLOv5没有相应的论文说明,但是作者在Github上积极地开放源代码,通过对源码分析,我们也能很快地了解YOLOv5的网络架构和工作原理。
Adapter接口定义了如下方法:
public abstract void registerDataSetObserver (DataSetObserver observer)
Adapter表示一个数据源,这个数据源是有可能发生变化的,比如增加了数据、删除了数据、修改了数据,当数据发生变化的时候,它要通知相应的AdapterView做出相应的改变。为了实现这个功能,Adapter使用了观察者模式,Adapter本身相当于被观察的对象,AdapterView相当于观察者,通过调用registerDataSetObserver方法,给Adapter注册观察者。
public abstract void unregisterDataSetObserver (DataSetObserver observer)
通过调用unregisterDataSetObserver方法,反注册观察者。
public abstract int getCount () 返回Adapter中数据的数量。
public abstract Object getItem (int position)
Adapter中的数据类似于数组,里面每一项就是对应一条数据,每条数据都有一个索引位置,即position,根据position可以获取Adapter中对应的数据项。
public abstract long getItemId (int position)
获取指定position数据项的id,通常情况下会将position作为id。在Adapter中,相对来说,position使用比id使用频率更高。
public abstract boolean hasStableIds ()
hasStableIds表示当数据源发生了变化的时候,原有数据项的id会不会发生变化,如果返回true表示Id不变,返回false表示可能会变化。Android所提供的Adapter的子类(包括直接子类和间接子类)的hasStableIds方法都返回false。
public abstract View getView (int position, View convertView, ViewGroup parent)
getView是Adapter中一个很重要的方法,该方法会根据数据项的索引为AdapterView创建对应的UI项。