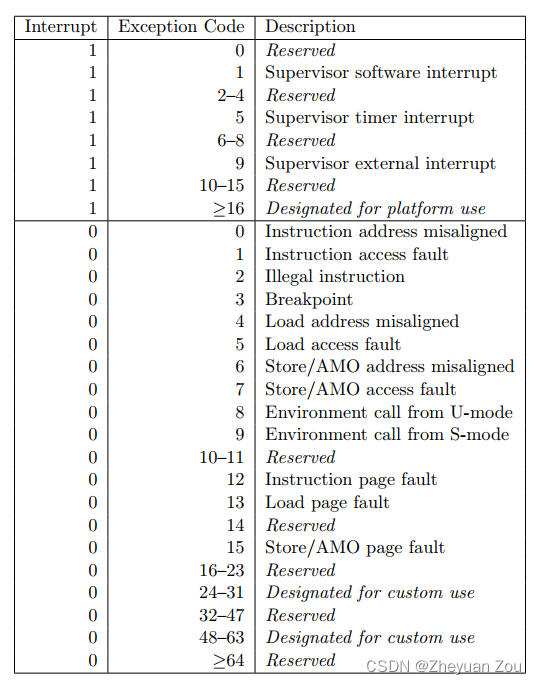
2.2 磁盘分区
一个磁盘可以被划分为多个分区,有一个磁盘并且将他们划分为C;D;E盘,那个C,D,E就是分区(partition)。
2.2.1 磁盘连接的方式与设备文件名的关系
个人计算机常见的磁盘接口有两种,分别是SATA与SAS接口,目前(2015)的主流是SATA接口。不过更老旧的计算机则有可能是已经不再流行的IDE界面。以前的IDE界面与SATA界面在Linux的磁盘代号并不相同,不过近年来为了统一处理,大部分Linux distribution已经将IDE界面的磁盘文件名也仿真成跟SATA一样。
正常的实体机器大概使用的都是 /dev/sd[a-] 的磁盘文件名,至于虚拟机环境下面,为了加速,可能就会使用 /dev/vd[a-p] 这种设备文件名。因此在实际处理你的系统时,可能得要了解为啥会有两种不同磁盘文件名的原因才好。
再以SATA接口来说,由于SATA/USB/SAS等磁盘接口都是使用SCSI模块来驱动的,因此这些接口的磁盘设备文件名都是/dev/sd[a-p]的格式。所以SATA/USB接口的磁盘根本就没有一定的顺序,那如何决定他的设备文件名呢? 这个时候就得要根据Linux核心侦测到磁盘的顺序了。
例题:如果你的PC上面有两个SATA磁盘以及一个USB磁盘,而主板上面有六个SATA的插槽。这两个SATA磁盘分别安插在主板上的SATA1, SATA5插槽上, 请问这三个磁盘在Linux中的设备文件名为何?答:由于是使用侦测到的顺序来决定设备文件名,并非与实际插槽代号有关,因此设备的文件名如下:
1. SATA1插槽上的文件名:/dev/sda
2. SATA5插槽上的文件名:/dev/sdb
3. USB磁盘(开机完成后才被系统捉到):/dev/sdc
接下来了解一下磁盘的组成,因为现今磁盘的分区与他物理的组成很有关系。我们在计算机概论谈过磁盘的组成主要有盘片、机械手臂、磁头与主轴马达所组成, 而数据的写入其实是在盘片上面。盘片上面又可细分出扇区(Sector)与磁道(Track)两种单位,其中扇区的物理量设计有两种大小,分别是 512Bytes 与 4KBytes。假设磁盘只有一个盘片,那么盘片有点像下面这样:
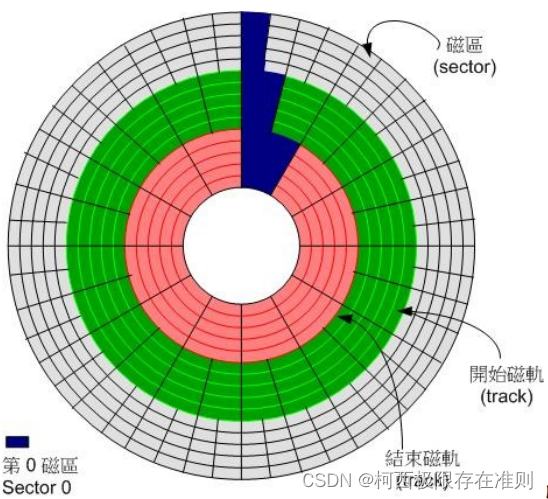 图2.2.1盘片组成示意图
图2.2.1盘片组成示意图
那么是否每个扇区都一样重要呢?其实整颗磁盘的第一个扇区特别的重要,因为他记录了整颗磁盘的重要信息。早期磁盘第一个扇区里面含有的重要信息我们称为MBR (Master BootRecord)格式,但是由于近年来磁盘的容量不断扩大,造成读写上的一些困扰,甚至有些大于2TB 以上的磁盘分区已经让某些操作系统无法存取。因此后来又多了一个新的磁盘分区格式,称为GPT(GUID partition table)。这两种分区格式与限制不太相同。
分区表就是针对硬盘进行分区,这样硬盘才可以被你使用。
2.2.2 MSDOS(MBR)与GPT磁盘分区表(partition table)
通常磁盘可能有多个盘片,所有盘片的同一个磁道我们称为柱面 (Cylinder), 通常那是文件系统的最小单位,也就是分区的最小单位。为什么说“通常”呢?因为近来有 GPT 这个可达到 64bit 纪录功能的分区表, 现在我们甚至可以使用扇区 (sector) 号码来作为分区单位。
所以主流的分区表有两种格式,对此来谈谈这两种分区表格式:
MSDOS (MBR) 分区表格式与限制
早期的 Linux 系统为了相容于 Windows 的磁盘,因此使用的是支持 Windows 的MBR(Master Boot Record,主要开机纪录区)的方式来处理开机管理程序与分区表!而开机管理程序纪录区与分区表则通通放在磁盘的第一个扇区,这个扇区通常是 512Bytes 的大小(旧的磁盘扇区都是512Bytes),所以说,第一个扇区 512Bytes 会有这两个数据:
主要开机记录区(Master Boot Record, MBR):可以安装开机管理程序的地方,有446Bytes
分区表(partition table):记录整颗硬盘分区的状态,有64 Bytes
由于分区表所在区块仅有64 Bytes容量,因此最多仅能有四组记录区,每组记录区记录了该区段的启始与结束的柱面号码。若将硬盘以长条形来看,然后将柱面以直条图来看,那么那64Bytes的记录区段有点像下面的图示:
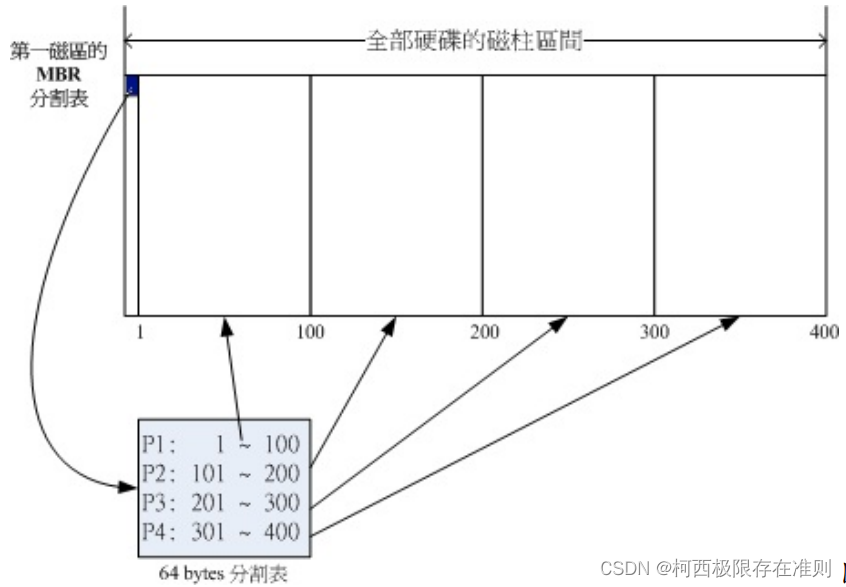
图2.2.2 磁盘分区表的作用示意图
假设上面的硬盘设备文件名为/dev/sda时,那么这四个分区在Linux系统中的设备文件名如下所示, 重点在于文件名后面会再接一个数字,这个数字与该分区所在的位置有关。
P1:/dev/sda1
P2:/dev/sda2
P3:/dev/sda3
P4:/dev/sda4
上图中我们假设硬盘只有400个柱面,共分区成为四个分区,第四个分区所在为第301到400号柱面的范围。当你的操作系统为Windows时,那么第一到第四个分区的代号应该就是C,D,E,F。当你有数据要写入F盘时, 你的数据会被写入这颗磁盘的301~400号柱面之间的意思。
由于分区表就只有64 Bytes而已,最多只能容纳四笔分区的记录, 这四个分区的记录被称为主要(Primary)或延伸(Extended)分区。 根据上面的图示与说明,我们可以得到几个重点信息:
1.其实所谓的“分区”只是针对那个64 Bytes的分区表进行设置而已。
2.硬盘默认的分区表仅能写入四组分区信息
3.这四组分区信息我们称为主要(Primary)或延伸(Extended)分区
4.分区的最小单位“通常”为柱面(cylinder)
5.当系统要写入磁盘时,一定会参考磁盘分区表,才能针对某个分区进行数据的处理
关于分区,主要考虑的是:
1. 数据的安全性:因为每个分区的数据是分开的!所以,当你需要将某个分区的数据重整时,例如你要将计算机中Windows的C 盘重新安装一次系统时, 可以将其他重要数据移动到其他分区,例如将邮件、桌面数据移动到D盘去,那么C盘重灌系统并不会影响到D盘。所以善用分区,可以让你的数据更安全。
2. 系统的性能考虑:由于分区将数据集中在某个柱面的区段,例如上图当中第一个分区位于柱面号码1~100号,如此一来当有数据要读取自该分区时,磁盘只,会搜寻前面1~100的柱面范围,由于数据集中了,将有助于数据读取的速度与性能。所以说分区是很重要的。
MBR 主要分区、延伸分区与逻辑分区的特性我们作个简单的定义:主要分区与延伸分区最多可以有四笔(硬盘的限制)
延伸分区最多只能有一个(操作系统的限制)
逻辑分区是由延伸分区持续切割出来的分区;
能够被格式化后,作为数据存取的分区为主要分区与逻辑分区。延伸分区无法格式化;
逻辑分区的数量依操作系统而不同,在Linux系统中SATA硬盘已经可以突破63个以上的分区限制;
事实上,分区是个很麻烦的东西,因为他是以柱面为单位的“连续”磁盘空间,且延伸分区又是个类似独立的磁盘空间,所以在分区的时候得要特别注意。我们举下面的例子来解释一下好了:
例题:在Windows操作系统当中,如果你想要将D与E盘整合成为一个新的分区,而如果有两种分区的情况如下图所示, 图中的特殊颜色区块为D与E盘的示意,请问这两种方式是否均可将D与E整合成为一个新的分区?
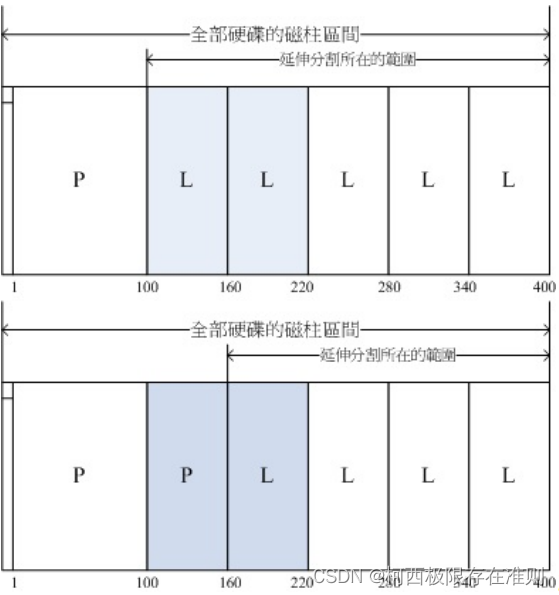
图2.2.4、磁盘空间整合示意图
上图可以整合:因为上图的D与E同属于延伸分区内的逻辑分区,因此只要将两个分区删除,然后再重新创建一个新的分区, 就能够在不影响其他分区的情况下,将两个分区的容量整合成为一个。
下图不可整合:因为D与E分属主分区与逻辑分区,两者不能够整合在一起。除非将延伸分区破坏掉后再重新分区。 但如此一来会影响到所有的逻辑分区,要注意的是:如果延伸分区被破坏,所有逻辑分区将会被删除。 因为逻辑分区的信息都记录在延伸分区里面。
由于第一个扇区所记录的分区表与MBR是这么的重要,几乎只要读取硬盘都会先由这个扇区先读起。因此,如果整颗硬盘的第一个扇区(就是MBR与partition table所在的扇区)物理实体坏掉了,那这个硬盘大概就没有用了。
例题:如果我想将一颗大硬盘“暂时”分区成为四个partitions,同时还有其他的剩余容量可以让我在未来的时候进行规划, 我能不能分区出四个Primary?若不行,那么你建议该如何分区?
答:由于Primary+Extended最多只能有四个,其中Extended最多只能有一个,这个例题想要分区出四个分区且还要预留剩余容量, 因此P+P+P+P的分区方式是不适合的。因为如果使用到四个P,则即使硬盘还有剩余容量, 因为无法再继续分区,所以剩余容量就被浪费掉了。
假设你想要将所有的四笔记录都花光,那么P+P+P+E是比较适合的。所以可以用的四个partitions有3个主要及一个逻辑分区, 剩余的容量在延伸分区中。
如果你要分区超过4个以上时,一定要有Extended分区,而且必须将所有剩下的空间都分配给Extended,然后再以logical的分区来规划Extended的空间。另外,考虑到磁盘的连续性,一般建议将Extended的柱面号码分配在最后面的柱面内。
MBR 分区表除了上述的主分区、延伸分区、逻辑分区需要注意之外,由于每组分区表仅有16Bytes 而已,因此可纪录的信息真的是相当有限的!
所以,在过去 MBR 分区表的限制中经常可以发现如下的问题:
操作系统无法抓取到 2.2T 以上的磁盘容量。
MBR 仅有一个区块,若被破坏后,经常无法或很难救援。
MBR 内的存放开机管理程序的区块仅446Bytes,无法容纳较多的程序码。
GUID partition table, GPT 磁盘分区表[1]
因为过去一个扇区大小就是 512Bytes 而已,不过目前已经有 4K 的扇区设计出现!为了相容于所有的磁盘,因此在扇区的定义上面, 大多会使用所谓的逻辑区块位址(Logical BlockAddress, LBA)来处理。GPT 将磁盘所有区块以此 LBA(默认为 512Bytes) 来规划,而第一个 LBA 称为 LBA0 (从 0 开始编号)。
与 MBR 仅使用第一个 512Bytes 区块来纪录不同, GPT 使用了 34 个 LBA 区块来纪录分区信息!同时与过去 MBR 仅有一的区块,被干掉就死光光的情况不同, GPT 除了前面 34 个LBA 之外,整个磁盘的最后 33 个 LBA 也拿来作为另一个备份,这样会比较安全。详细的结构如图下:
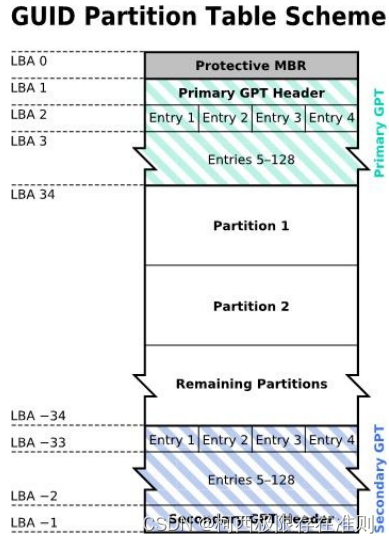
图2.2.7 GPT分区表的结构示意图
上述图示的解释说明如下:
LBA0 (MBR 相容区块)
与 MBR 模式相似的,这个相容区块也分为两个部份,一个就是跟之前 446 Bytes 相似的区块,储存了第一阶段的开机管理程序! 而在原本的分区表的纪录区内,这个相容模式仅放入一个特殊标志的分区,用来表示此磁盘为 GPT 格式之意。而不懂 GPT 分区表的磁盘管理程序, 就不会认识这颗磁盘,除非用户有特别要求要处理这颗磁盘,否则该管理软件不能修改此分区信息,进一步保护了此磁盘。
LBA1 (GPT 表头纪录)
这个部份纪录了分区表本身的位置与大小,同时纪录了备份用的 GPT 分区(就是前面谈到的在最后 34 个 LBA 区块)放置的位置,同时放置了分区表的检验机制码(CRC32),操作系统可以根据这个检验码来判断 GPT 是否正确。若有错误,还可以通过这个纪录区来取得备份的GPT(磁盘最后的那个备份区块)来恢复 GPT 的正常运行。
LBA2-33(实际纪录分区信息处)
从 LBA2 区块开始,每个 LBA 都可以纪录 4 笔分区纪录,所以在默认的情况下,总共可以有 432 = 128 笔分区纪录。因为每个 LBA 有 512Bytes,因此每笔纪录用到 128Bytes 的空间,除了每笔纪录所需要的识别码与相关的纪录之外,GPT在每笔纪录中分别提供了64bits来记载开始/结束的扇区号码,因此,GPT 分区表对於单一分区来说,他的最大容量限制就会在“ 264 512Bytes = 263 1KBytes = 233TB = 8 ZB ”,要注意1ZB= 230TB,所以足够大。
现在 GPT 分区默认可以提供多达 128 笔纪录,而在 Linux 本身的核心设备纪录中,针对单一磁盘来说,虽然过去最多只能到达 15 个分区,不过由于 Linux kernel 通过 udev 等方式的处理,现在 Linux 也已经没有这个限制在了。此外,GPT 分区已经没有所谓的主、延伸、逻辑分区的概念,既然每笔纪录都可以独立存在, 当然每个都可以视为是主分区,每一个分区都可以拿来格式化使用。








![【群智能算法】一种改进的哈里斯鹰优化算法 IHHO算法[1]【Matlab代码#17】](https://img-blog.csdnimg.cn/cb50fe5045ea40ea85e0a17860ae65aa.png)