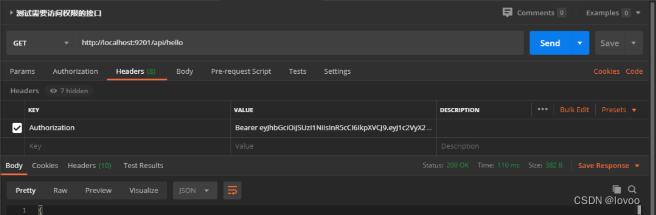
- 神经网络的可视化可以客观的解释 “黑盒” ,所以一直以来都是论文中必不可少的工作。
- 对于深度卷积神经网络,一般用CAM进行可视化研究。遗憾的是,基于Transformer的神经网络可视化,CAM并不奏效。所以,本文章提供一套基于DETR的可视化代码。
注意:本文章为了贯彻简洁高效的思想,没有对源代码做任何的改动,仅仅添加了两个py文件对图像进行检测和可视化操作。
目录
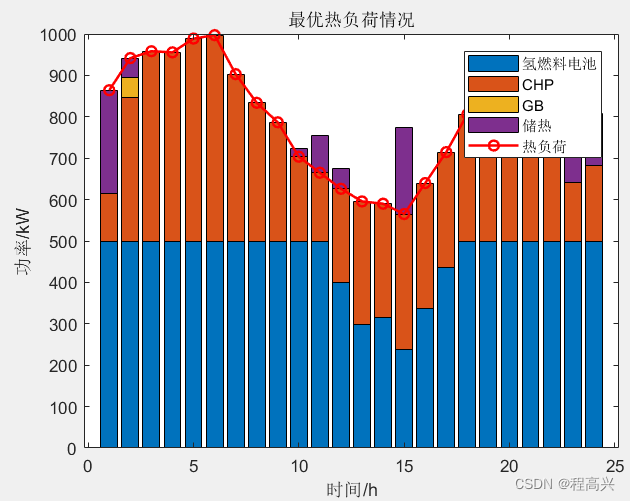
一、效果展示
二、代码实现
三、detr_detect.py文件
四、detr_see.py文件
五、DETR源码 + 图像 + 预训练权重 + detr_detect.py + detr_see.py 资源提供
一、效果展示

图1 原始图像

图2 绘制检测框的图像
图3 可视化注意力权重
二、代码实现
- 步骤一:Github官网上下载DETR源码 https://github.com/facebookresearch/detr
- 步骤二:用PyCharm打开DETR源码,并配置环境
- 步骤三:跑通detr_detect.py文件,获取检测结果
- 步骤四:跑通detr_See.py文件,获取可视化结果
注意:文章末尾处提供所有的文件,如果不想从官网下载,可以直接从百度网盘获取
三、detr_detect.py文件
import os
import time
from PIL import Image
import matplotlib.pyplot as plt
import torch
import torchvision.transforms as T
torch.set_grad_enabled(False)
from models import build_model
import argparse
def get_args_parser():
parser = argparse.ArgumentParser('Set transformer detector', add_help=False)
parser.add_argument('--lr', default=1e-4, type=float)
parser.add_argument('--lr_backbone', default=1e-5, type=float)
parser.add_argument('--batch_size', default=1, type=int)
parser.add_argument('--weight_decay', default=1e-4, type=float)
parser.add_argument('--epochs', default=300, type=int)
parser.add_argument('--lr_drop', default=200, type=int)
parser.add_argument('--clip_max_norm', default=0.1, type=float,
help='gradient clipping max norm')
# Model parameters
parser.add_argument('--frozen_weights', type=str, default=None,
help="Path to the pretrained model. If set, only the mask head will be trained")
# * Backbone
parser.add_argument('--backbone', default='resnet50', type=str,
help="Name of the convolutional backbone to use")
parser.add_argument('--dilation', action='store_true',
help="If true, we replace stride with dilation in the last convolutional block (DC5)")
parser.add_argument('--position_embedding', default='sine', type=str, choices=('sine', 'learned'),
help="Type of positional embedding to use on top of the image features")
# * Transformer
parser.add_argument('--enc_layers', default=6, type=int,
help="Number of encoding layers in the transformer")
parser.add_argument('--dec_layers', default=6, type=int,
help="Number of decoding layers in the transformer")
parser.add_argument('--dim_feedforward', default=2048, type=int,
help="Intermediate size of the feedforward layers in the transformer blocks")
parser.add_argument('--hidden_dim', default=256, type=int,
help="Size of the embeddings (dimension of the transformer)")
parser.add_argument('--dropout', default=0.1, type=float,
help="Dropout applied in the transformer")
parser.add_argument('--nheads', default=8, type=int,
help="Number of attention heads inside the transformer's attentions")
parser.add_argument('--num_queries', default=100, type=int,
help="Number of query slots") # 论文中对象查询为100
parser.add_argument('--pre_norm', action='store_true')
# * Segmentation
parser.add_argument('--masks', action='store_true',
help="Train segmentation head if the flag is provided")
# Loss
parser.add_argument('--no_aux_loss', dest='aux_loss', action='store_false',
help="Disables auxiliary decoding losses (loss at each layer)")
# * Matcher
parser.add_argument('--set_cost_class', default=1, type=float,
help="Class coefficient in the matching cost")
parser.add_argument('--set_cost_bbox', default=5, type=float,
help="L1 box coefficient in the matching cost")
parser.add_argument('--set_cost_giou', default=2, type=float,
help="giou box coefficient in the matching cost")
# * Loss coefficients
parser.add_argument('--mask_loss_coef', default=1, type=float)
parser.add_argument('--dice_loss_coef', default=1, type=float)
parser.add_argument('--bbox_loss_coef', default=5, type=float)
parser.add_argument('--giou_loss_coef', default=2, type=float)
parser.add_argument('--eos_coef', default=0.1, type=float,
help="Relative classification weight of the no-object class")
# dataset parameters
parser.add_argument('--dataset_file', default='coco')
parser.add_argument('--coco_path', default='', type=str)
parser.add_argument('--coco_panoptic_path', type=str)
parser.add_argument('--remove_difficult', action='store_true')
parser.add_argument('--output_dir', default='E:\project_yd\paper_sci_one_yd\Transformer\DETR\detr\\runs\\train',
help='path where to save, empty for no saving')
parser.add_argument('--device', default='cuda',
help='device to use for training / testing')
parser.add_argument('--seed', default=42, type=int)
# ============================================================================= #
parser.add_argument('--resume', default='', help='resume from checkpoint')
# ============================================================================= #
parser.add_argument('--start_epoch', default=0, type=int, metavar='N',
help='start epoch')
parser.add_argument('--eval', action='store_true')
parser.add_argument('--num_workers', default=2, type=int)
# distributed training parameters
parser.add_argument('--world_size', default=1, type=int,
help='number of distributed processes')
parser.add_argument('--dist_url', default='env://', help='url used to set up distributed training')
return parser
# classes
CLASSES = [
'N/A', 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus',
'train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'N/A',
'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse',
'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe', 'N/A', 'backpack',
'umbrella', 'N/A', 'N/A', 'handbag', 'tie', 'suitcase', 'frisbee', 'skis',
'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove',
'skateboard', 'surfboard', 'tennis racket', 'bottle', 'N/A', 'wine glass',
'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich',
'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake',
'chair', 'couch', 'potted plant', 'bed', 'N/A', 'dining table', 'N/A',
'N/A', 'toilet', 'N/A', 'tv', 'laptop', 'mouse', 'remote', 'keyboard',
'cell phone', 'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'N/A',
'book', 'clock', 'vase', 'scissors', 'teddy bear', 'hair drier',
'toothbrush'
]
print('有对象+无对象', len(CLASSES))
# colors for visualization
COLORS = [[0.000, 0.447, 0.741], [0.850, 0.325, 0.098], [0.929, 0.694, 0.125],
[0.494, 0.184, 0.556], [0.466, 0.674, 0.188], [0.301, 0.745, 0.933]]
# standard PyTorch mean-std input image normalization
transform = T.Compose([
T.Resize(800), # 改变图像尺寸
T.ToTensor(), # 转换成张量的类型
T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) # 符合正态分布的归一化
])
# for output bounding box post-processing
def box_cxcywh_to_xyxy(x):
print(x)
x_c, y_c, w, h = x.unbind(1)
b = [(x_c - 0.5 * w), (y_c - 0.5 * h),
(x_c + 0.5 * w), (y_c + 0.5 * h)]
return torch.stack(b, dim=1)
def rescale_bboxes(out_bbox, size):
img_w, img_h = size
b = box_cxcywh_to_xyxy(out_bbox)
# 保证都使用显卡处理数据
b = b * torch.tensor([img_w, img_h, img_w, img_h], dtype=torch.float32).to('cuda:0')
return b
def detect(im, model, transform):
# mean-std normalize the input image (batch-size: 1)
img = transform(im).unsqueeze(0).to('cuda:0') # 模型中的类型时CUDA.Tensor,保证img的类型和模型类型相同
print("输入图像尺寸", img.shape[:])
# demo model only support by default images with aspect ratio between 0.5 and 2
# if you want to use images with an aspect ratio outside this range
# rescale your image so that the maximum size is at most 1333 for best results
assert img.shape[-2] <= 1600 and img.shape[-1] <= 1600, 'demo model only supports images up to 1600 pixels on each side'
# propagate through the model
outputs = model(img)
# keep only predictions with 0.7+ confidence
probas = outputs['pred_logits'].softmax(-1)[0, :, :-1]
print('91个种类多对应的置信度', probas.size()) # [100, 91] 查询向量对91个种类的分数
# print(probas)
# tensor.max(-1) 返回每一行中的最大值和其对应的索引,分别以values和indices表示
keep = probas.max(-1).values > 0.7
print(probas[keep].size()) # [5, 91]
# convert boxes from [0; 1] to image scales
print(outputs['pred_boxes'].size()) # [1, 100, 4]
bboxes_scaled = rescale_bboxes(outputs['pred_boxes'][0, keep], im.size)
return probas[keep], bboxes_scaled
def plot_results(pil_img, prob, boxes):
plt.figure(figsize=(16, 10))
plt.imshow(pil_img)
ax = plt.gca() # get current axes 获取当前坐标区
for p, (xmin, ymin, xmax, ymax), c in zip(prob, boxes.tolist(), COLORS * 100):
ax.add_patch(plt.Rectangle((xmin, ymin), xmax - xmin, ymax - ymin,
fill=False, color=c, linewidth=3))
# 返回p的最大值索引
cl = p.argmax()
text = f'{CLASSES[cl]}: {p[cl]:0.2f}'
ax.text(xmin, ymin, text, fontsize=15,
bbox=dict(facecolor='yellow', alpha=0.5))
plt.axis('on') # 打开坐标轴
plt.show()
if __name__ == '__main__':
parser = argparse.ArgumentParser('DETR training and evaluation script', parents=[get_args_parser()])
args = parser.parse_args()
# 建立模型
detr, criterion, postprocessors = build_model(args)
detr.to('cuda:0')
url = r'pre_tran_weights/detr-r50-e632da11.pth'
state_dict = torch.load(url)
# print(state_dict)
# 加载模型参数,以字典的形式表示
detr.load_state_dict(state_dict['model'])
detr.eval() # 把字符串类型转换成字典类型
img = Image.open("img/dog.png")
# =============================================== #
start_time = time.time()
scores, boxes = detect(img, detr, transform)
print('检测一张图像所需的时间:{}s'.format(time.time() - start_time))
# =============================================== #
# 检测结果可视化
plot_results(img, scores, boxes)
四、detr_See.py文件
import time
from PIL import Image
import matplotlib.pyplot as plt
import torch
import torchvision.transforms as T
torch.set_grad_enabled(False)
from models import build_model
import argparse
from torch.nn.functional import dropout,linear,softmax
# ============================================== #
from torchcam.utils import overlay_mask
from torchvision.transforms.functional import normalize, resize, to_pil_image
def get_args_parser():
parser = argparse.ArgumentParser('Set transformer detector', add_help=False)
parser.add_argument('--lr', default=1e-4, type=float)
parser.add_argument('--lr_backbone', default=1e-5, type=float)
parser.add_argument('--batch_size', default=1, type=int)
parser.add_argument('--weight_decay', default=1e-4, type=float)
parser.add_argument('--epochs', default=300, type=int)
parser.add_argument('--lr_drop', default=200, type=int)
parser.add_argument('--clip_max_norm', default=0.1, type=float,
help='gradient clipping max norm')
# Model parameters
parser.add_argument('--frozen_weights', type=str, default=None,
help="Path to the pretrained model. If set, only the mask head will be trained")
# * Backbone
parser.add_argument('--backbone', default='resnet50', type=str,
help="Name of the convolutional backbone to use")
parser.add_argument('--dilation', action='store_true',
help="If true, we replace stride with dilation in the last convolutional block (DC5)")
parser.add_argument('--position_embedding', default='sine', type=str, choices=('sine', 'learned'),
help="Type of positional embedding to use on top of the image features")
# * Transformer
parser.add_argument('--enc_layers', default=6, type=int,
help="Number of encoding layers in the transformer")
parser.add_argument('--dec_layers', default=6, type=int,
help="Number of decoding layers in the transformer")
parser.add_argument('--dim_feedforward', default=2048, type=int,
help="Intermediate size of the feedforward layers in the transformer blocks")
parser.add_argument('--hidden_dim', default=256, type=int,
help="Size of the embeddings (dimension of the transformer)")
parser.add_argument('--dropout', default=0.1, type=float,
help="Dropout applied in the transformer")
parser.add_argument('--nheads', default=8, type=int,
help="Number of attention heads inside the transformer's attentions")
parser.add_argument('--num_queries', default=100, type=int,
help="Number of query slots") # 论文中对象查询为100
parser.add_argument('--pre_norm', action='store_true')
# * Segmentation
parser.add_argument('--masks', action='store_true',
help="Train segmentation head if the flag is provided")
# Loss
parser.add_argument('--no_aux_loss', dest='aux_loss', action='store_false',
help="Disables auxiliary decoding losses (loss at each layer)")
# * Matcher
parser.add_argument('--set_cost_class', default=1, type=float,
help="Class coefficient in the matching cost")
parser.add_argument('--set_cost_bbox', default=5, type=float,
help="L1 box coefficient in the matching cost")
parser.add_argument('--set_cost_giou', default=2, type=float,
help="giou box coefficient in the matching cost")
# * Loss coefficients
parser.add_argument('--mask_loss_coef', default=1, type=float)
parser.add_argument('--dice_loss_coef', default=1, type=float)
parser.add_argument('--bbox_loss_coef', default=5, type=float)
parser.add_argument('--giou_loss_coef', default=2, type=float)
parser.add_argument('--eos_coef', default=0.1, type=float,
help="Relative classification weight of the no-object class")
# dataset parameters
parser.add_argument('--dataset_file', default='coco')
parser.add_argument('--coco_path', default='', type=str)
parser.add_argument('--coco_panoptic_path', type=str)
parser.add_argument('--remove_difficult', action='store_true')
parser.add_argument('--output_dir', default='E:\project_yd\paper_sci_one_yd\Transformer\DETR\detr\\runs\\train',
help='path where to save, empty for no saving')
parser.add_argument('--device', default='cuda',
help='device to use for training / testing')
parser.add_argument('--seed', default=42, type=int)
# ============================================================================= #
parser.add_argument('--resume', default='', help='resume from checkpoint')
# ============================================================================= #
parser.add_argument('--start_epoch', default=0, type=int, metavar='N',
help='start epoch')
parser.add_argument('--eval', action='store_true')
parser.add_argument('--num_workers', default=2, type=int)
# distributed training parameters
parser.add_argument('--world_size', default=1, type=int,
help='number of distributed processes')
parser.add_argument('--dist_url', default='env://', help='url used to set up distributed training')
return parser
# classes
# COCO classes
CLASSES = [
'N/A', 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus',
'train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'N/A',
'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse',
'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe', 'N/A', 'backpack',
'umbrella', 'N/A', 'N/A', 'handbag', 'tie', 'suitcase', 'frisbee', 'skis',
'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove',
'skateboard', 'surfboard', 'tennis racket', 'bottle', 'N/A', 'wine glass',
'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich',
'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake',
'chair', 'couch', 'potted plant', 'bed', 'N/A', 'dining table', 'N/A',
'N/A', 'toilet', 'N/A', 'tv', 'laptop', 'mouse', 'remote', 'keyboard',
'cell phone', 'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'N/A',
'book', 'clock', 'vase', 'scissors', 'teddy bear', 'hair drier',
'toothbrush'
]
print('有对象+无对象', len(CLASSES))
# colors for visualization
COLORS = [[0.000, 0.447, 0.741], [0.850, 0.325, 0.098], [0.929, 0.694, 0.125],
[0.494, 0.184, 0.556], [0.466, 0.674, 0.188], [0.301, 0.745, 0.933]]
# standard PyTorch mean-std input image normalization
transform = T.Compose([
T.Resize(800), # 改变图像尺寸
T.ToTensor(), # 转换成张量的类型
T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) # 符合正态分布的归一化
])
# for output bounding box post-processing
def box_cxcywh_to_xyxy(x):
print(x)
x_c, y_c, w, h = x.unbind(1)
b = [(x_c - 0.5 * w), (y_c - 0.5 * h),
(x_c + 0.5 * w), (y_c + 0.5 * h)]
return torch.stack(b, dim=1)
def rescale_bboxes(out_bbox, size):
img_w, img_h = size
b = box_cxcywh_to_xyxy(out_bbox)
# 保证都使用显卡处理数据
b = b * torch.tensor([img_w, img_h, img_w, img_h], dtype=torch.float32).to('cuda:0')
return b
def plot_results(pil_img, prob, boxes):
plt.figure(figsize=(16, 10))
plt.imshow(pil_img)
ax = plt.gca() # get current axes 获取当前坐标区
for p, (xmin, ymin, xmax, ymax), c in zip(prob, boxes.tolist(), COLORS * 100):
ax.add_patch(plt.Rectangle((xmin, ymin), xmax - xmin, ymax - ymin,
fill=False, color=c, linewidth=3))
# 返回p的最大值索引
cl = p.argmax()
text = f'{CLASSES[cl]}: {p[cl]:0.2f}'
ax.text(xmin, ymin, text, fontsize=15,
bbox=dict(facecolor='yellow', alpha=0.5))
plt.axis('on') # 打开坐标轴
plt.show()
class Main():
def m(self):
parser = argparse.ArgumentParser('DETR training and evaluation script', parents=[get_args_parser()])
args = parser.parse_args()
# 建立模型
model, criterion, postprocessors = build_model(args)
model.to('cuda:0')
url = r'pre_tran_weights/detr-r50-e632da11.pth'
state_dict = torch.load(url)
# 加载模型参数,以字典的形式表示
model.load_state_dict(state_dict['model'])
model.eval() # 把字符串类型转换成字典类
img_path = r'img/dog.png'
im = Image.open(img_path)
# =============================================== #
start_time = time.time()
# scores, bboxes_scaled, keep = detect(im, model, transform)
# mean-std normalize the input image (batch-size: 1)
img = transform(im).unsqueeze(0).to('cuda:0') # 模型中的类型时CUDA.Tensor,保证img的类型和模型类型相同
print("输入图像尺寸", img.shape[:])
# demo model only support by default images with aspect ratio between 0.5 and 2
# if you want to use images with an aspect ratio outside this range
# rescale your image so that the maximum size is at most 1333 for best results
assert img.shape[-2] <= 1600 and img.shape[
-1] <= 1600, 'demo model only supports images up to 1600 pixels on each side'
# propagate through the model
outputs = model(img)
# keep only predictions with 0.7+ confidence
probas = outputs['pred_logits'].softmax(-1)[0, :, :-1]
print('91个种类多对应的置信度', probas.size()) # [100, 91] 查询向量对91个种类的分数
# print(probas)
# tensor.max(-1) 返回每一行中的最大值和其对应的索引,分别以values和indices表示
keep = probas.max(-1).values > 0.7
print(probas[keep].size()) # [5, 91]
# convert boxes from [0; 1] to image scales
print(outputs['pred_boxes'].size()) # [1, 100, 4]
bboxes_scaled = rescale_bboxes(outputs['pred_boxes'][0, keep], im.size)
print('检测一张图像所需的时间:{}s'.format(time.time() - start_time))
# =============================================== #
# 检测结果可视化
scores = probas[keep]
plot_results(im, scores, bboxes_scaled)
# =======================================各个注意力头学习到的特征======================================= #
for name, parameters in model.named_parameters():
# 获取训练好的object queries,即pq:[100,256]
if name == 'query_embed.weight':
pq = parameters
# 获取解码器的最后一层的交叉注意力模块中q和k的线性权重和偏置:[256*3,256],[768]
if name == 'transformer.decoder.layers.5.multihead_attn.in_proj_weight':
in_proj_weight = parameters
if name == 'transformer.decoder.layers.5.multihead_attn.in_proj_bias':
in_proj_bias = parameters
# use lists to store the outputs via up-values
conv_features, enc_attn_weights, dec_attn_weights = [], [], []
cq = [] # 存储detr中的 cq
pk = [] # 存储detr中的 encoder pos
memory = [] # 存储encoder的输出特征图memory
# 注册hook
# =======================================注意力权重学习到的特征======================================= #
hooks = [
# 获取resnet最后一层特征图
model.backbone[-2].register_forward_hook(
lambda self, input, output: conv_features.append(output)
),
# 获取encoder的图像特征图memory
model.transformer.encoder.register_forward_hook(
lambda self, input, output: memory.append(output)
),
# 获取encoder的最后一层layer的self-attn weights
model.transformer.encoder.layers[-1].self_attn.register_forward_hook(
lambda self, input, output: enc_attn_weights.append(output[1])
),
# 获取decoder的最后一层layer中交叉注意力的 weights
model.transformer.decoder.layers[-1].multihead_attn.register_forward_hook(
lambda self, input, output: dec_attn_weights.append(output[1])
),
# 获取decoder的最后一层layer中自注意力的 weights
# model.transformer.decoder.layers[-1].self_attn.register_forward_hook(
# lambda self, input, output: dec_attn_weights.append(output[1])
# ),
# 获取decoder最后一层self-attn的输出cq
model.transformer.decoder.layers[-1].norm1.register_forward_hook(
lambda self, input, output: cq.append(output)
),
# 获取图像特征图的位置编码pk
model.backbone[-1].register_forward_hook(
lambda self, input, output: pk.append(output)
),
]
# propagate through the model
outputs = model(img)
# 用完的hook后删除
for hook in hooks:
hook.remove()
# don't need the list anymore
conv_features = conv_features[0] # [1,2048,25,34]
enc_attn_weights = enc_attn_weights[0] # [1,1125,1125] : [N,L,S]
dec_attn_weights = dec_attn_weights[0] # [1,100,1125] : [N,L,S] --> [batch, tgt_len, src_len]
memory = memory[0] # [1125,1,256]
cq = cq[0] # decoder的self_attn:最后一层输出[100,1,256]
pk = pk[0] # [1,256,25,34]
# 绘制 position embedding
pk = pk.flatten(-2).permute(2, 0, 1) # [1,256,1125] --> [1125,1,256]
pq = pq.unsqueeze(1).repeat(1, 1, 1) # [100,1,256]
q = pq + cq # 对象查询+norm1(交叉注意力)
# q = pq # 对象查询(自注意力)
# ------------------------------------------------------#
# 1) k = pk,则可视化: (cq + oq)*pk
# 2_ k = pk + memory,则可视化 (cq + oq)*(memory + pk)
# 读者可自行尝试
# ------------------------------------------------------#
# k = pk
# k = memory
k = pk + memory
# ------------------------------------------------------#
# 将q和k完成线性层的映射,代码参考自nn.MultiHeadAttn()
_b = in_proj_bias
_start = 0
_end = 256
_w = in_proj_weight[_start:_end, :]
if _b is not None:
_b = _b[_start:_end]
q = linear(q, _w, _b)
_b = in_proj_bias
_start = 256
_end = 256 * 2
_w = in_proj_weight[_start:_end, :]
if _b is not None:
_b = _b[_start:_end]
k = linear(k, _w, _b)
scaling = float(256) ** -0.5
q = q * scaling
q = q.contiguous().view(100, 8, 32).transpose(0, 1) # 256 --> 8 * 32
k = k.contiguous().view(-1, 8, 32).transpose(0, 1)
attn_output_weights = torch.bmm(q, k.transpose(1, 2))
print(attn_output_weights.size())
attn_output_weights = attn_output_weights.view(1, 8, 100, 950)
attn_output_weights = attn_output_weights.view(1 * 8, 100, 950)
attn_output_weights = softmax(attn_output_weights, dim=-1)
attn_output_weights = attn_output_weights.view(1, 8, 100, 950)
# 获取注意力权重
idx = keep.nonzero()
try:
all_dec_attn_weight = dec_attn_weights[0][idx[0]] + dec_attn_weights[0][idx[1]]
except:
all_dec_attn_weight = dec_attn_weights[0][idx]
# ======================= 得到注意力权重后,绘制图像 ======================= #
h, w = conv_features['0'].tensors.shape[-2:]
self.weight = all_dec_attn_weight.reshape(h, w) * 200
# Resize the CAM and overlay it
# result = overlay_mask(to_pil_image(img1), to_pil_image(self.weight, mode='F'), alpha=0.5)
result = overlay_mask(im, to_pil_image(self.weight, mode='F'), alpha=0.5)
# Display it
fig1, axs1 = plt.subplots(ncols=2, nrows=1, figsize=(18, 18)) # [11,2]
axs1[0].axis('off')
axs1[0].imshow(im)
axs1[1].axis('off')
axs1[1].imshow(result)
# ============================================== #
plt.show()
main = Main()
main.m()
五、DETR源码 + 图像 + 预训练权重 + detr_detect.py + detr_See.py 资源提供
百度网盘分享链接:
- 链接:https://pan.baidu.com/s/1Uw04G0JPl1BTRdwpwCwMNQ?pwd=AIAT
- 提取码:AIAT
如果对您有帮助,还请在评论区多多支持 [抱拳][抱拳][抱拳]
>>> 如有疑问,欢迎评论区一起探讨。