一、前言
在前面我们通过以下章节对数据分片有了基础的了解:
Spring Boot集成ShardingSphere实现数据分片(一) | Spring Cloud 40
Spring Boot集成ShardingSphere实现数据分片(二) | Spring Cloud 41
知道数据分片产生的背景及面临的挑战和其各数据分片类型在业务场景下的优缺,感兴趣的小伙伴自行浏览。
书接上回,本章进行对以下部分进行集成演示:
- 通过
Spring Boot集成ShardingSphere-JDBC来实现数据分片,展示其集成步骤和各注意事项 - 对分库、分表进行示例展示
- 展示日常开发使用到的数据分片算法
下面我们开始正文内容。
二、ShardingSphere-JDBC介绍
Apache ShardingSphere 是一款分布式的数据库生态系统, 可以将任意数据库转换为分布式数据库,并通过数据分片、弹性伸缩、加密等能力对原有数据库进行增强。
Apache ShardingSphere 设计哲学为 Database Plus,旨在构建异构数据库上层的标准和生态。 它关注如何充分合理地利用数据库的计算和存储能力,而并非实现一个全新的数据库。 它站在数据库的上层视角,关注它们之间的协作多于数据库自身。
ShardingSphere-JDBC 定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
- 适用于任何基于
JDBC的ORM框架,如:JPA、Hibernate、Mybatis、Spring JDBC Template或直接使用JDBC; - 支持任何第三方的数据库连接池,如:
DBCP、C3P0、BoneCP、HikariCP等;
- 支持任意实现
JDBC规范的数据库,目前支持MySQL、PostgreSQL、Oracle、SQLServer以及任何可使用JDBC访问的数据库。
更多ShardingSphere介绍请见官网:https://shardingsphere.apache.org/document/current/cn/overview/
2.1 核心概念
2.1.1 表
表是透明化数据分片的关键概念。 Apache ShardingSphere 通过提供多样化的表类型,适配不同场景下的数据分片需求。
2.1.1.1 逻辑表
相同结构的水平拆分数据库(表)的逻辑名称,是 SQL 中表的逻辑标识。 例:订单数据根据主键尾数拆分为 10 张表,分别是 t_order_0 到 t_order_9,他们的逻辑表名为 t_order。
2.1.1.2 真实表
在水平拆分的数据库中真实存在的物理表。 即上个示例中的 t_order_0 到 t_order_9。
2.1.1.3 绑定表
指分片规则一致的一组分片表。 使用绑定表进行多表关联查询时,必须使用分片键进行关联,否则会出现笛卡尔积关联或跨库关联,从而影响查询效率。
例如:t_order 表和 t_order_item 表,均按照 order_id 分片,并且使用 order_id 进行关联,则此两张表互为绑定表关系。 绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升。 举例说明,如果 SQL 为:
SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
在不配置绑定表关系时,假设分片键 order_id 将数值 10 路由至第 0 片,将数值 11 路由至第 1 片,那么路由后的 SQL 应该为 4 条,它们呈现为笛卡尔积:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_0 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
在配置绑定表关系,并且使用 order_id 进行关联后,路由的 SQL 应该为 2 条:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
其中 t_order 表由于指定了分片条件,ShardingSphere 将会以它作为整个绑定表的主表。 所有路由计算将会只使用主表的策略,那么 t_order_item 表的分片计算将会使用 t_order 的条件。
2.1.1.4 广播表
指所有的分片数据源中都存在的表,表结构及其数据在每个数据库中均完全一致。 适用于数据量不大且需要与海量数据的表进行关联查询的场景,例如:字典表。
2.1.1.5 单表
指所有的分片数据源中仅唯一存在的表。 适用于数据量不大且无需分片的表。
2.1.2 数据节点
数据分片的最小单元,由数据源名称和真实表组成。 例:ds_0.t_order_0。 逻辑表与真实表的映射关系,可分为均匀分布和自定义分布两种形式。
2.1.2.1 均匀分布
指数据表在每个数据源内呈现均匀分布的态势, 例如:
db0
├── t_order0
└── t_order1
db1
├── t_order0
└── t_order1
数据节点的配置如下:
db0.t_order0, db0.t_order1, db1.t_order0, db1.t_order1
2.1.2.2 自定义分布
指数据表呈现有特定规则的分布, 例如:
db0
├── t_order0
└── t_order1
db1
├── t_order2
├── t_order3
└── t_order4
数据节点的配置如下:
db0.t_order0, db0.t_order1, db1.t_order2, db1.t_order3, db1.t_order4
2.1.3 分片
2.1.3.1 分片键
用于将数据库(表)水平拆分的数据库字段。
例:将订单表中的订单主键的尾数取模分片,则订单主键为分片字段。
SQL 中如果无分片字段,将执行全路由,性能较差。 除了对单分片字段的支持,Apache ShardingSphere 也支持根据多个字段进行分片。
2.1.3.2 分片算法
用于将数据分片的算法,支持 =、>=、<=、>、<、BETWEEN 和 IN 进行分片。 分片算法可由开发者自行实现,也可使用 Apache ShardingSphere 内置的分片算法语法糖,灵活度非常高。
2.1.3.3 自动化分片算法
分片算法语法糖,用于便捷的托管所有数据节点,使用者无需关注真实表的物理分布。 包括取模、哈希、范围、时间等常用分片算法的实现。
2.1.3.4 自定义分片算法
提供接口让应用开发者自行实现与业务实现紧密相关的分片算法,并允许使用者自行管理真实表的物理分布。 自定义分片算法又分为:
-
标准分片算法
用于处理使用单一键作为分片键的
=、IN、BETWEEN AND、>、<、>=、<=进行分片的场景。 -
复合分片算法
用于处理使用多键作为分片键进行分片的场景,包含多个分片键的逻辑较复杂,需要应用开发者自行处理其中的复杂度。
-
Hint分片算法用于处理使用
Hint行分片的场景。
2.1.3.5 分片策略
包含分片键和分片算法,由于分片算法的独立性,将其独立抽离。 真正可用于分片操作的是分片键 + 分片算法,也就是分片策略。
2.1.3.6 强制分片路由
对于分片字段并非由 SQL 而是其他外置条件决定的场景,可使用 SQL Hint 注入分片值。
例:按照员工登录主键分库,而数据库中并无此字段。 SQL Hint 支持通过 Java API 和 SQL 注释两种方式使用。 详情请参见强制分片路由。
2.1.4 行表达式
行表达式是为了解决配置的简化与一体化这两个主要问题。
在繁琐的数据分片规则配置中,随着数据节点的增多,大量的重复配置使得配置本身不易被维护。 通过行表达式可以有效地简化数据节点配置工作量。
对于常见的分片算法,使用 Java 代码实现并不有助于配置的统一管理。 通过行表达式书写分片算法,可以有效地将规则配置一同存放,更加易于浏览与存储。
行表达式的使用非常直观,只需要在配置中使用 ${ expression } 或 $->{ expression } 标识行表达式即可。 目前支持数据节点和分片算法这两个部分的配置。 行表达式的内容使用的是 Groovy 的语法,Groovy 能够支持的所有操作,行表达式均能够支持。 例如:
${begin..end} 表示范围区间 ${[unit1, unit2, unit_x]} 表示枚举值
行表达式中如果出现连续多个 ${ expression } 或 $->{ expression } 表达式,整个表达式最终的结果将会根据每个子表达式的结果进行笛卡尔组合。
例如,以下行表达式:
${['online', 'offline']}_table${1..3}
最终会解析为:
online_table1, online_table2, online_table3, offline_table1, offline_table2, offline_table3
2.1.5 分布式主键
传统数据库软件开发中,主键自动生成技术是基本需求。而各个数据库对于该需求也提供了相应的支持,比如 MySQL 的自增键,Oracle 的自增序列等。
数据分片后,不同数据节点生成全局唯一主键是非常棘手的问题。同一个逻辑表内的不同实际表之间的自增键由于无法互相感知而产生重复主键。 虽然可通过约束自增主键初始值和步长的方式避免碰撞,但需引入额外的运维规则,使解决方案缺乏完整性和可扩展性。
目前有许多第三方解决方案可以完美解决这个问题,如 UUID 等依靠特定算法自生成不重复键,或者通过引入主键生成服务等。
为了方便用户使用、满足不同用户不同使用场景的需求, Apache ShardingSphere 不仅提供了内置的分布式主键生成器,例如 UUID、SNOWFLAKE,还抽离出分布式主键生成器的接口,方便用户自行实现自定义的自增主键生成器。
三、分库分表示例
3.1 分库分表总体结构
3.1.1 数据源ds1
| 数据库地址 | 数据源名称 | 真实表名 | 逻辑表名称 | 业务描述 |
|---|---|---|---|---|
| 192.168.0.35 | ds1 | t_goods_0 | t_goods | 商品表-分库/分表 |
| 192.168.0.35 | ds1 | t_goods_1 | t_goods | 商品表-分库/分表 |
| 192.168.0.35 | ds1 | t_order_0 | t_order | 订单表-分库/分表 |
| 192.168.0.35 | ds1 | t_order_1 | t_order | 订单表-分库/分表 |
| 192.168.0.35 | ds1 | t_order_item_0 | t_order_item | 订单明细表-分库/分表 |
| 192.168.0.35 | ds1 | t_order_item_1 | t_order_item | 订单明细表-分库/分表 |
| 192.168.0.35 | ds1 | sys_dict | sys_dict | 系统字典表-单表 |
| 192.168.0.35 | ds1 | sys_dict_item | sys_dict_item | 系统字典子表-单表 |
3.1.1 数据源ds2
| 数据库地址 | 数据源名称 | 真实表名 | 逻辑表名称 | 业务描述 |
|---|---|---|---|---|
| 192.168.0.46 | ds2 | t_goods_0 | t_goods | 商品表-分库/分表 |
| 192.168.0.46 | ds2 | t_goods_1 | t_goods | 商品表-分库/分表 |
| 192.168.0.46 | ds2 | t_order_0 | t_order | 订单表-分库/分表 |
| 192.168.0.46 | ds2 | t_order_1 | t_order | 订单表-分库/分表 |
| 192.168.0.46 | ds2 | t_order_item_0 | t_order_item | 订单明细表-分库/分表 |
| 192.168.0.46 | ds2 | t_order_item_1 | t_order_item | 订单明细表-分库/分表 |
| 192.168.0.46 | ds2 | sys_dict | sys_dict | 系统字典表-单表 |
| 192.168.0.46 | ds2 | sys_dict_item | sys_dict_item | 系统字典子表-单表 |
3.1.1 逻辑商品表 t_goods
-- ----------------------------
-- Table structure for t_goods_0
-- ----------------------------
DROP TABLE IF EXISTS `t_goods_0`;
CREATE TABLE `t_goods_0` (
`goods_id` bigint NOT NULL,
`goods_name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '商品名称',
`main_class` bigint NULL DEFAULT NULL COMMENT '商品大类数据字典',
`sub_class` bigint NULL DEFAULT NULL COMMENT '商品小类数据字典',
PRIMARY KEY (`goods_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Table structure for t_goods_1
-- ----------------------------
DROP TABLE IF EXISTS `t_goods_1`;
CREATE TABLE `t_goods_1` (
`goods_id` bigint NOT NULL,
`goods_name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '商品名称',
`main_class` bigint NULL DEFAULT NULL COMMENT '商品大类数据字典',
`sub_class` bigint NULL DEFAULT NULL COMMENT '商品小类数据字典',
PRIMARY KEY (`goods_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
3.1.2 逻辑订单表 t_order
-- ----------------------------
-- Table structure for t_order_0
-- ----------------------------
DROP TABLE IF EXISTS `t_order_0`;
CREATE TABLE `t_order_0` (
`order_id` bigint NOT NULL AUTO_INCREMENT,
`create_by` bigint NULL DEFAULT NULL COMMENT '下单人',
`create_time` datetime NULL DEFAULT NULL COMMENT '下单时间',
PRIMARY KEY (`order_id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Table structure for t_order_1
-- ----------------------------
DROP TABLE IF EXISTS `t_order_1`;
CREATE TABLE `t_order_1` (
`order_id` bigint NOT NULL AUTO_INCREMENT,
`create_by` bigint NULL DEFAULT NULL COMMENT '下单人',
`create_time` datetime NULL DEFAULT NULL COMMENT '下单时间',
PRIMARY KEY (`order_id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
3.1.3 逻辑订单明细表
-- ----------------------------
-- Table structure for t_order_item_0
-- ----------------------------
DROP TABLE IF EXISTS `t_order_item_0`;
CREATE TABLE `t_order_item_0` (
`order_item_id` bigint NOT NULL AUTO_INCREMENT,
`order_id` bigint NOT NULL,
`goods_id` bigint NOT NULL COMMENT '商品ID',
`goods_name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`create_by` bigint NULL DEFAULT NULL COMMENT '下单人',
`create_time` datetime NULL DEFAULT NULL COMMENT '下单时间',
PRIMARY KEY (`order_item_id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Table structure for t_order_item_1
-- ----------------------------
DROP TABLE IF EXISTS `t_order_item_1`;
CREATE TABLE `t_order_item_1` (
`order_item_id` bigint NOT NULL AUTO_INCREMENT,
`order_id` bigint NOT NULL,
`goods_id` bigint NOT NULL COMMENT '商品ID',
`goods_name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`create_by` bigint NULL DEFAULT NULL COMMENT '下单人',
`create_time` datetime NULL DEFAULT NULL COMMENT '下单时间',
PRIMARY KEY (`order_item_id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
3.1.4 系统字典表
DROP TABLE IF EXISTS `sys_dict`;
CREATE TABLE `sys_dict` (
`id` bigint(18) NOT NULL AUTO_INCREMENT COMMENT '字典ID',
`dict_code` varchar(55) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '字典代码',
`dict_name` varchar(125) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '字典名称',
`dict_status` tinyint(4) NOT NULL DEFAULT 0 COMMENT '字典状态\r\n0: 停用\r\n1: 启用',
`dict_type` tinyint(4) NULL DEFAULT 0 COMMENT '字典类型(0-系统字典 5-公共 9-解析字典)',
PRIMARY KEY (`id`) USING BTREE,
UNIQUE INDEX `idx`(`dict_code`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = '系统-字典表' ROW_FORMAT = Dynamic;
DROP TABLE IF EXISTS `sys_dict_item`;
CREATE TABLE `sys_dict_item` (
`id` bigint(18) NOT NULL AUTO_INCREMENT COMMENT '字典子项id',
`dict_id` bigint(18) NOT NULL COMMENT '字典ID',
`dict_item_code` varchar(55) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '字典子项代码',
`dict_item_value` varchar(125) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '字典子项展示值',
`dict_item_desc` varchar(125) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT '' COMMENT '字典子项描述',
`item_status` tinyint(1) NOT NULL DEFAULT 0 COMMENT '字典子项状态\r\n0: 停用\r\n1: 启用',
`item_attrs` varchar(1024) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '自定义json字符串属性',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = '系统-字典子项表' ROW_FORMAT = Dynamic;
3.2 项目结构
3.2.1 项目总体结构
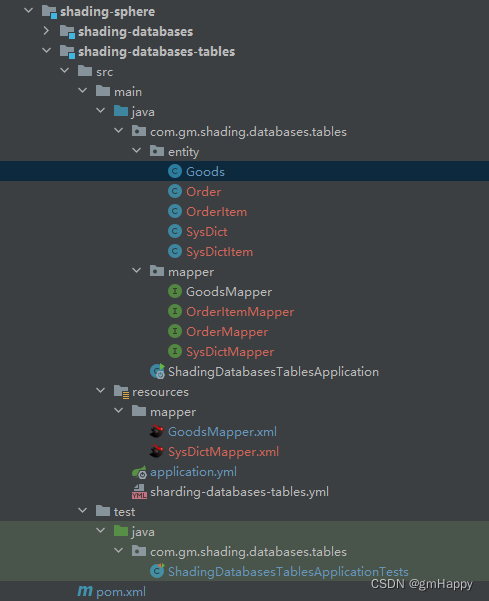
3.2.2 Maven 依赖
shading-sphere/shading-databases-tables/pom.xml:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>shading-sphere</artifactId>
<groupId>com.gm</groupId>
<version>0.0.1-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>shading-databases-tables</artifactId>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>5.2.1</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.3.1</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-generator</artifactId>
<version>3.5.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.velocity</groupId>
<artifactId>velocity-engine-core</artifactId>
<version>2.3</version>
</dependency>
<dependency>
<groupId>org.yaml</groupId>
<artifactId>snakeyaml</artifactId>
<version>1.33</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>2.0.25</version>
</dependency>
</dependencies>
</project>
shardingsphere-jdbc-core-spring-boot-starter使用版本5.2.1JDBC的ORM框架选用mybatis-plus
3.2.3 配置文件
shading-sphere/shading-databases-tables/src/main/resources/application.yml:
server:
port: 8844
spring:
application:
name: @artifactId@
shardingsphere:
# 数据源配置
datasource:
names: ds1,ds2
ds1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.0.35:3306/db1?useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true&allowMultiQueries=true&serverTimezone=Asia/Shanghai
username: root
password: '1qaz@WSX'
ds2:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.0.46:3306/db2?useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true&allowMultiQueries=true&serverTimezone=Asia/Shanghai
username: root
password: '1qaz@WSX'
# 定义规则
rules:
sharding:
# 数据分片规则配置
tables:
# 指定某个表的分片配置,逻辑表名,此商品表按照大类进行分库,按照小类进行分表
t_goods:
# 这个配置是告诉sharding有多少个库和多少个表及所在实际的数据库节点,由数据源名 + 表名组成(参考 Inline 语法规则)
actual-data-nodes: ds$->{1..2}.t_goods_$->{0..1}
# 配置库分片策略
database-strategy:
# 用于单分片键的标准分片场景
standard:
# 分片列名称
sharding-column: main_class
# 分片算法名称
sharding-algorithm-name: t_goods_database_inline
# 配置表分片策略
table-strategy:
# 用于单分片键的标准分片场景
standard:
# 分片列名称
sharding-column: sub_class
# 分片算法名称
sharding-algorithm-name: t_goods_table_inline
# 分布式序列策略
key-generate-strategy:
# 自增列名称,缺省表示不使用自增主键生成器
column: goods_id
# 分布式序列算法名称
key-generator-name: snowflake
# 指定某个表的分片配置,逻辑表名,此订单表缺省分库策略表示使用默认分库策略,按照订单ID进行分表
t_order:
# 这个配置是告诉sharding有多少个库和多少个表及所在实际的数据库节点,由数据源名 + 表名组成(参考 Inline 语法规则)
actual-data-nodes: ds$->{1..2}.t_order_$->{0..1}
# 配置表分片策略
table-strategy:
# 用于单分片键的标准分片场景
standard:
# 分片列名称
sharding-column: order_id
# 分片算法名称
sharding-algorithm-name: t_order_table_inline
# 分布式序列策略
key-generate-strategy:
# 自增列名称,缺省表示不使用自增主键生成器
column: order_id
# 分布式序列算法名称
key-generator-name: snowflake
# 指定某个表的分片配置,逻辑表名,此订单明细表缺省分库策略表示使用默认分库策略,按照订单ID进行分表
t_order_item:
# 这个配置是告诉sharding有多少个库和多少个表及所在实际的数据库节点,由数据源名 + 表名组成(参考 Inline 语法规则)
actual-data-nodes: ds$->{1..2}.t_order_item_$->{0..1}
# 配置表分片策略
table-strategy:
# 用于单分片键的标准分片场景
standard:
# 分片列名称
sharding-column: order_id
# 分片算法名称
sharding-algorithm-name: t_order_order_item_inline
# 分布式序列策略
key-generate-strategy:
# 自增列名称,缺省表示不使用自增主键生成器
column: order_item_id
# 分布式序列算法名称
key-generator-name: snowflake
# 分片算法配置
sharding-algorithms:
# 分片算法名称
t_goods_table_inline:
# 分片算法类型
type: INLINE
# 分片算法属性配置
props:
algorithm-expression: t_goods_${sub_class % 2}
# 分片算法名称
t_goods_database_inline:
# 分片算法类型
type: INLINE
# 分片算法属性配置
props:
algorithm-expression: ds$->{main_class % 2 + 1}
# 分片算法名称
t_order_table_inline:
# 分片算法类型
type: INLINE
# 分片算法属性配置
props:
algorithm-expression: t_order_${order_id % 2}
# 分片算法名称
t_order_order_item_inline:
# 分片算法类型
type: INLINE
# 分片算法属性配置
props:
algorithm-expression: t_order_item_${order_id % 2}
# 分片算法名称
default_database_inline:
# 分片算法类型
type: INLINE
# 分片算法属性配置
props:
algorithm-expression: ds$->{create_by % 2 + 1}
# 分布式序列算法配置(如果是自动生成的,在插入数据的sql中就不要传id,null也不行,直接插入字段中就不要有主键的字段)
keyGenerators:
# 分布式序列算法名称
snowflake:
# 分布式序列算法类型
type: SNOWFLAKE
# 绑定表规则列表
binding-tables:
- t_goods
- t_order_item
broadcast-tables:
- sys_dict,sys_dict_item
# 默认数据库分片策略,当分库策略缺省表示使用默认分库策略
defaultDatabaseStrategy:
# 用于单分片键的标准分片场景
standard:
# 分片列名称
sharding-column: create_by
# 分片算法名称
sharding-algorithm-name: default_database_inline
props:
sql-show: true #显示sql
mybatis:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
配置简要说明:
- 商品逻辑表
t_goods:
- 按照商品大类取模分片算法进行分库
- 按照商品小类取模分片算法进行分表
- 订单逻辑表
t_order:
- 按照下单人取模分片算法进行分库
- 按照订单ID取模分片算法进行分表
- 订单明细逻辑表
t_order_item:
- 按照下单人取模分片算法进行分库
- 按照订单ID取模分片算法进行分表
- 广播表:
t_goods、t_order_item- 真实表:
sys_dict、sys_dict_item- 分布式序列:采用雪花算法(针对分布式序列,在插入数据的
sql中就不要传对应列名,null也不行)
更多配置项详解:https://shardingsphere.apache.org/document/current/cn/user-manual/shardingsphere-jdbc/yaml-config/rules/sharding/
更多分片算法详解:https://shardingsphere.apache.org/document/current/cn/dev-manual/sharding/
完整源码可见:https://gitee.com/gm19900510/springboot-cloud-example.git
后续介绍定义的分片算法的使用。