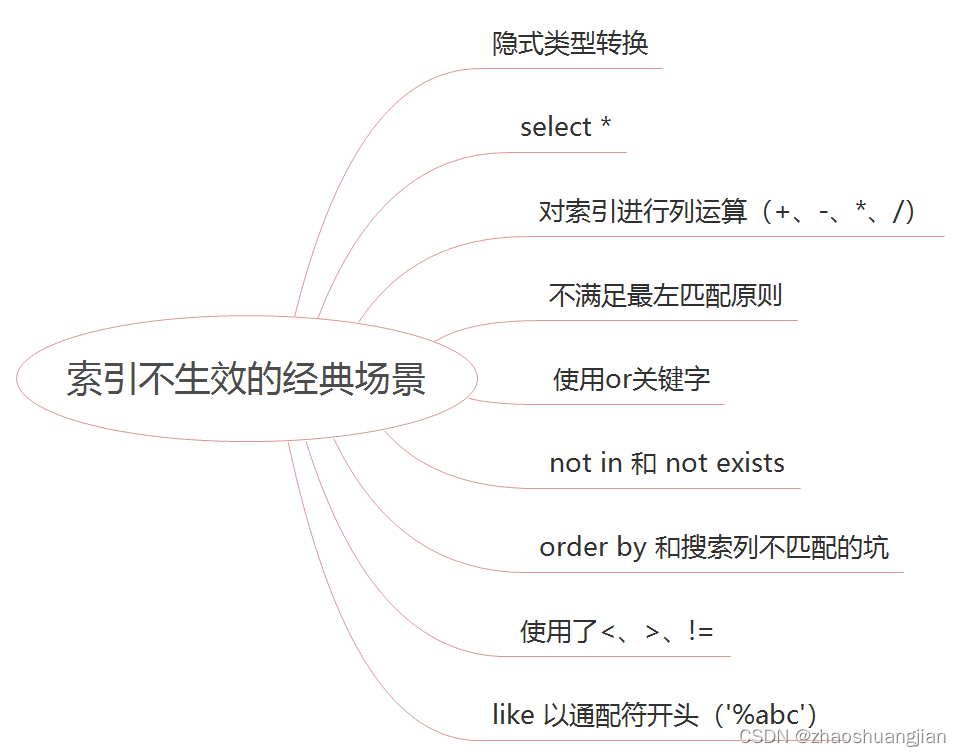
1. 窗口函数
- 窗口函数的应用
排名问题:每个部门按业绩来排名
topN问题:找出每个部门排名前N的员工进行奖励
- 窗口函数的语法
<窗口函数> over (partition by <用于分组的列名>
order by <用于排序的列名>)
<窗口函数>的位置,可以放以下两种函数:
1) 专用窗口函数,包括rank, dense_rank, row_number等专用窗口函数。
2) 聚合函数,如sum, avg, count, max, min等
因为窗口函数是对where或者group by子句处理后的结果进行操作,所以窗口函数原则上只能写在select子句中。
- 专用窗口函数rank, dense_rank, row_number的区别?
举个例子
select *,
rank() over (order by 成绩 desc) as ranking,
dense_rank() over (order by 成绩 desc) as dese_rank,
row_number() over (order by 成绩 desc) as row_num
from 班级表
得到结果
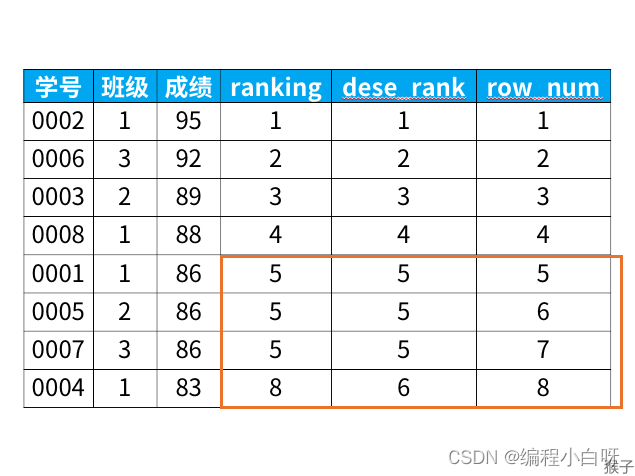
从上面的结果可以看出:
rank函数:这个例子中是5位,5位,5位,8位,也就是如果有并列名次的行,会占用下一名次的位置。比如正常排名是1,2,3,4,但是现在前3名是并列的名次,结果是:1,1,1,4。
dense_rank函数:这个例子中是5位,5位,5位,6位,也就是如果有并列名次的行,不占用下一名次的位置。比如正常排名是1,2,3,4,但是现在前3名是并列的名次,结果是:1,1,1,2。
row_number函数:这个例子中是5位,6位,7位,8位,也就是不考虑并列名次的情况。比如前3名是并列的名次,排名是正常的1,2,3,4。
2. 行转列
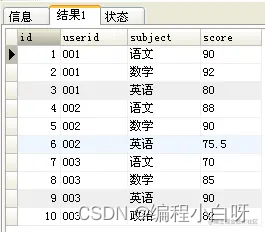
转换后的结果为:
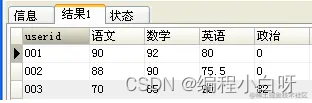
因此,行转列是指将原来subject字段的多行记录选择出来,作为结果表的不同列,并根据userid进行分组显示对应的score。
2.1 case when进行行转列
SELECT userid,
SUM(CASE `subject` WHEN '语文' THEN score ELSE 0 END) as '语文',
SUM(CASE `subject` WHEN '数学' THEN score ELSE 0 END) as '数学',
SUM(CASE `subject` WHEN '英语' THEN score ELSE 0 END) as '英语',
SUM(CASE `subject` WHEN '政治' THEN score ELSE 0 END) as '政治'
FROM tb_score
GROUP BY userid
2.2 使用if进行行转列
SELECT userid,
SUM(IF(`subject`='语文',score,0)) as '语文',
SUM(IF(`subject`='数学',score,0)) as '数学',
SUM(IF(`subject`='英语',score,0)) as '英语',
SUM(IF(`subject`='政治',score,0)) as '政治'
FROM tb_score
GROUP BY userid
注意点:
- SUM() 是为了能够使用GROUP BY根据userid进行分组,因为每一个userid对应的subject="语文"的记录只有一条,所以SUM() 的值就等于对应那一条记录的score的值。
3. 列转行
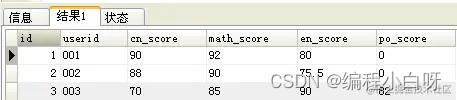
转换后: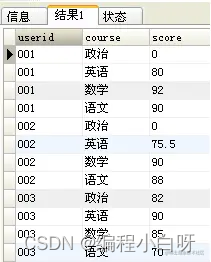
以上转换的本质:将userid的每个科目分数分散成一条记录显示出来。
SELECT userid,'语文' AS course,cn_score AS score FROM tb_score1
UNION ALL
SELECT userid,'数学' AS course,math_score AS score FROM tb_score1
UNION ALL
SELECT userid,'英语' AS course,en_score AS score FROM tb_score1
UNION ALL
SELECT userid,'政治' AS course,po_score AS score FROM tb_score1
ORDER BY userid
这里将userid多个科目的成绩查询出来,用union all 对结果集进行加起来。
总结
- 行转列用groupby+sumif,
列转行用union all - UNION和UNION ALL效率:
UNION和UNION ALL关键字都是将两个结果集合并为一个,但这两者从使用和效率上来说都有所不同。
- 对重复结果的处理:UNION在进行表链接后会筛选掉重复的记录,Union All不会去除重复记录。
- 对排序的处理:Union将会按照字段的顺序进行排序;UNION ALL只是简单的将两个结果合并后就返回。
从效率上说,UNION ALL要比UNION快很多,所以,如果可以确认合并的两个结果集中不包含重复数据且不需要排序时的话,那么就使用UNION ALL。
• 注意:两个要联合的SQL语句字段个数必须一样,而且字段类型要“相容”(一致);
拓展—表格转换问题
- 表格转换总结
4. join连接查询
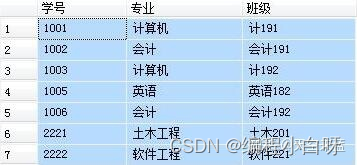
首先,设定两张表,作为下面例子的操作对象。
表1 学生信息表
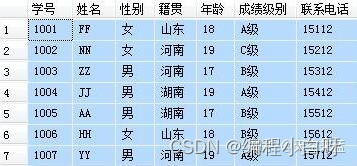
表2 专业班级表
语法总结
4.1 内连接
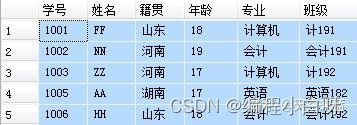
- 获取两个表中指定字段满足匹配关系的记录
--查询每个学生的学号、姓名、籍贯、年龄、专业、班级
--涉及到student和major两张表,用共有字段“学号”为连接字段
--写法1:使用INNER JOIN
SELECT A.学号, A.姓名, A.籍贯, A.年龄, B.专业, B.班级
FROM student A
INNER JOIN major B
ON A.学号=B.学号
--写法2:--省去了INNER,直接写JOIN,与INNER JOIN没有区别
SELECT A.学号, A.姓名, A.籍贯, A.年龄, B.专业, B.班级
FROM student A
JOIN major B
ON A.学号=B.学号
--写法3: --使用WHERE,已经逐渐被淘汰
SELECT A.学号, A.姓名, A.籍贯, A.年龄, B.专业, B.班级
FROM student A, major B
WHERE A.学号=B.学号
--上面三种写法的结果都是一样的,推荐使用写法2
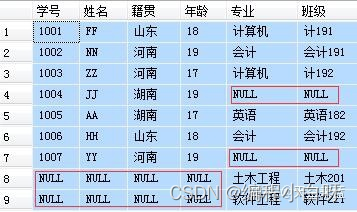
4.2 left join
- 获取左表中的所有记录,即使在右表没有对应匹配的记录。
--左连接:显示左表student所有记录,如右表中没有与之
--匹配的项则以NULL值代替。
SELECT A.学号, A.姓名, A.籍贯, A.年龄, B.专业, B.班级
FROM student A LEFT JOIN major B
ON A.学号=B.学号
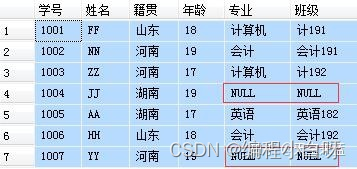
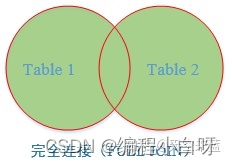
4.3 FULL JOIN— 完全连接
- 返回两个表中的所有行
--完全连接:显示两张表的并集,如果其中一张表的记录
--在另一张表中没有匹配的行,则对应的数据项填充NULL
SELECT A.学号, A.姓名, A.籍贯, A.年龄, B.专业, B.班级
FROM student A FULL JOIN major B
ON A.学号=B.学号
5. case when语法
CASE WHEN SCORE = 'A' THEN '优'
WHEN SCORE = 'B' THEN '良'
WHEN SCORE = 'C' THEN '中' ELSE '不及格' END
常用场景
场景1:有分数score,score<60返回不及格,score>=60返回及格,score>=80返回优秀
SELECT
STUDENT_NAME,
(CASE WHEN score < 60 THEN '不及格'
WHEN score >= 60 AND score < 80 THEN '及格'
WHEN score >= 80 THEN '优秀'
ELSE '异常' END) AS REMARK
FROM
TABLE
场景2:现老师要统计班中,有多少男同学,多少女同学,并统计男同学中有几人及格,女同学中有几人及格,要求用一个SQL输出结果。
其中STU_SEX字段,0表示男生,1表示女生
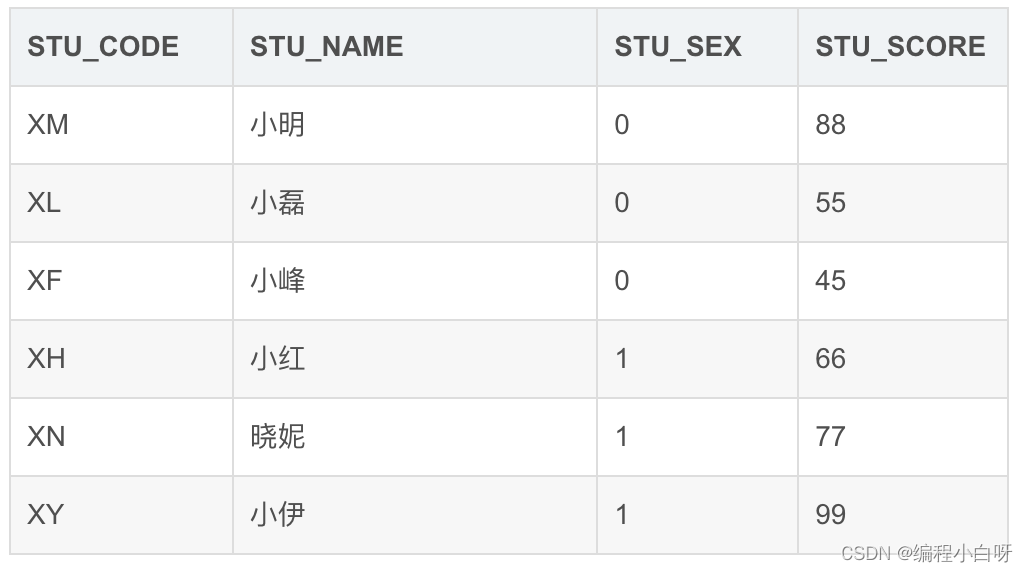
SELECT
SUM (CASE WHEN STU_SEX = 0 THEN 1 ELSE 0 END) AS MALE_COUNT,
SUM (CASE WHEN STU_SEX = 1 THEN 1 ELSE 0 END) AS FEMALE_COUNT,
SUM (CASE WHEN STU_SCORE >= 60 AND STU_SEX = 0 THEN 1 ELSE 0 END) AS MALE_PASS,
SUM (CASE WHEN STU_SCORE >= 60 AND STU_SEX = 1 THEN 1 ELSE 0 END) AS FEMALE_PASS
FROM
THTF_STUDENTS
场景3:经典行转列,并配合聚合函数做统计
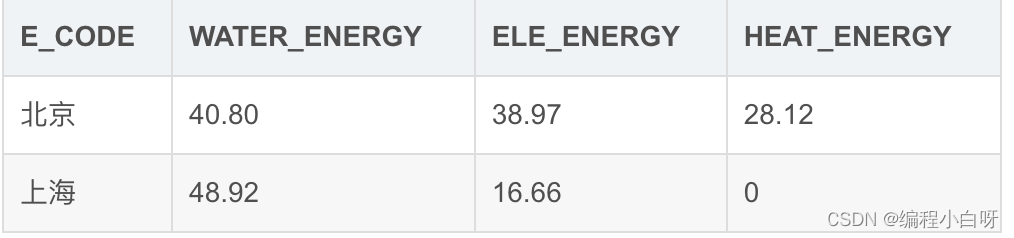
现要求统计各个城市,总共使用了多少水耗、电耗、热耗,使用一条SQL语句输出结果
有能耗表如下:其中,E_TYPE表示能耗类型,0表示水耗,1表示电耗,2表示热耗
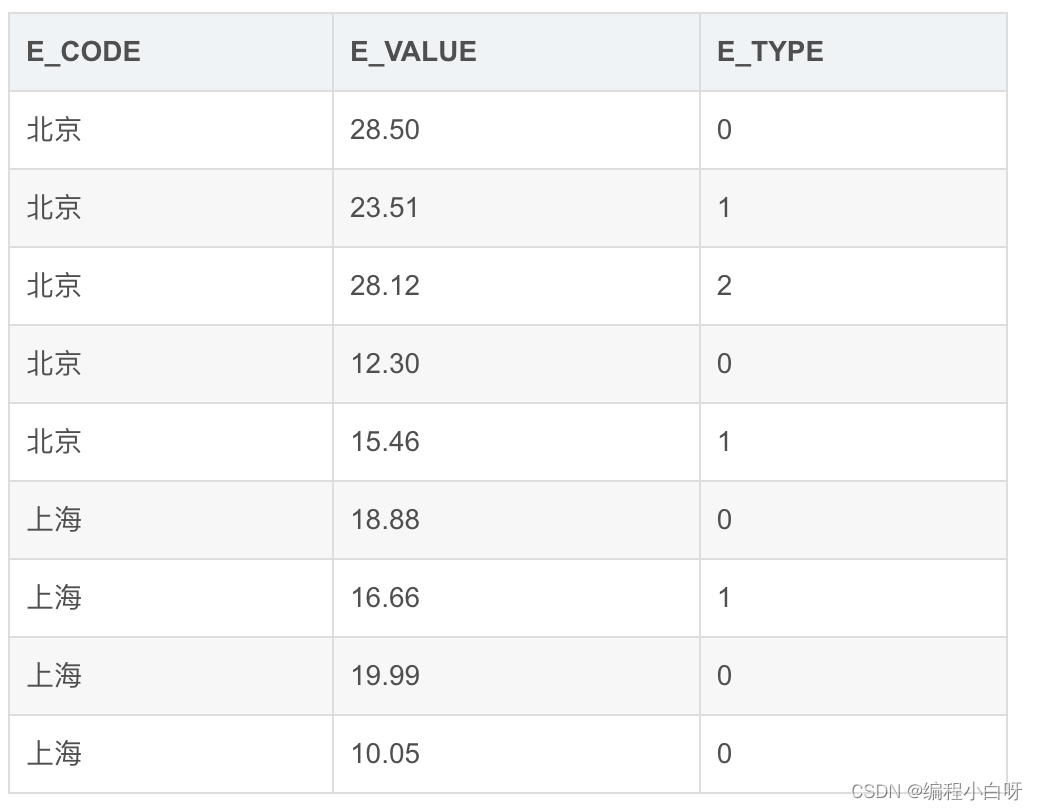
SELECT
E_CODE,
SUM(CASE WHEN E_TYPE = 0 THEN E_VALUE ELSE 0 END) AS WATER_ENERGY,--水耗
SUM(CASE WHEN E_TYPE = 1 THEN E_VALUE ELSE 0 END) AS ELE_ENERGY,--电耗
SUM(CASE WHEN E_TYPE = 2 THEN E_VALUE ELSE 0 END) AS HEAT_ENERGY--热耗
FROM
THTF_ENERGY_TEST
GROUP BY
E_CODE
输出如下:
- 练习见【SQL篇】面试篇之连接
6. 常见用法
6.1 left
left的使用,left(str,len)表示从str最左边一个字符开始返回指定数目(len)的字符。若len的值大于 str 的长度,则返回字符表达式的全部字符str。如果 len为负值或 0,则返回空字符串。
6.2 case when
使用case when:sum(case when a > 0 then a else 0 end)
6.3 IFNULL
ifNull的使用:IFNULL(expression_1,expression_2);如果expression_1不是null,返回expression_1,如果为null,返回expression_2。
6.4 concat_ws
CONCAT_WS() 是一种 SQL 函数,用于将多个字符串拼接成一个字符串。其中 WS 代表 with separator,也就是“使用分隔符”。
该函数的语法如下:
CONCAT_WS(separator, str1, str2, …)
其中 separator 是用于分隔字符串的分隔符,str1, str2, ... 是要拼接的字符串。可以指定任意数量的字符串,但第一个参数(分隔符)是必需的。
下面是一个例子,展示如何使用 CONCAT_WS() 函数将两个字符串 first_name 和 last_name 拼接在一起,并使用空格作为分隔符:
SELECT CONCAT_WS(' ', first_name, last_name) AS full_name
FROM users;
在上面的例子中,我们从一个名为 users 的表中选择了 first_name 和 last_name 两列,并将它们拼接在一起,使用空格作为分隔符,将结果列命名为 full_name。
需要注意的是,在 CONCAT_WS() 函数中,分隔符的位置总是出现在两个字符串之间,而不是字符串的前面或后面。如果其中一个字符串为空,则分隔符也不会出现在该位置。
6.5 group_concat()
一年过的很快,文中后来的两位员工 馮大 和 馮二 也要面对无情的 KPI 考核了,他们工作干的很不错,performance 分别是 4 和 5
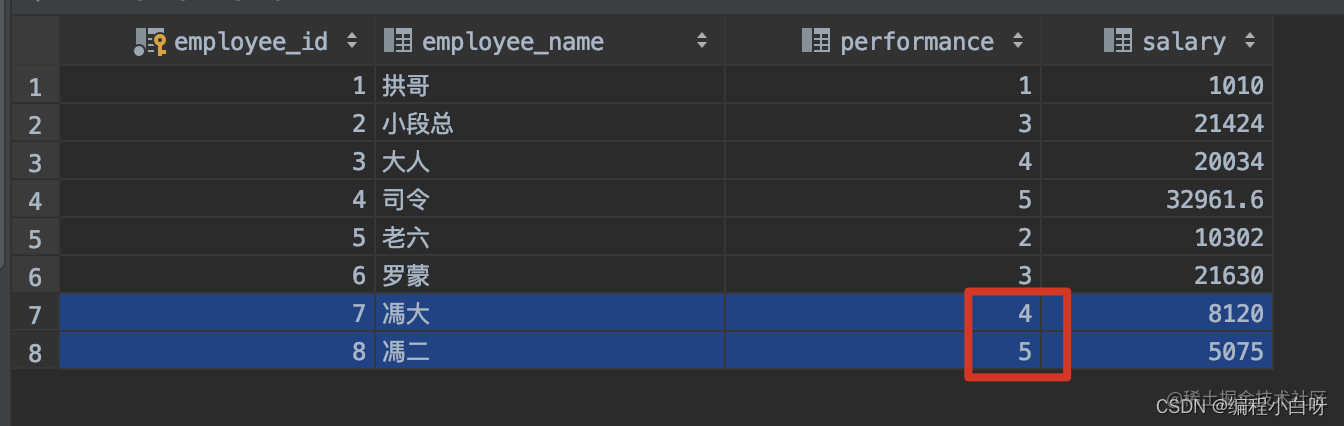
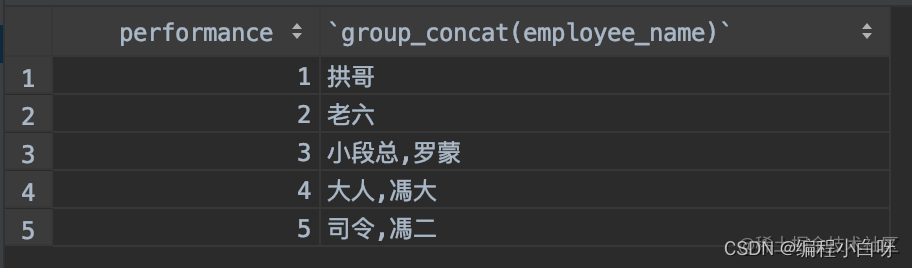
新需求来了,静悄悄的来了!!! 领导想要查看每个 performance 下都有谁,同时要求将这些人的名称要逗号拼接成一个字符串,也就是说要得到下面的结果:

要将结果集中某个指定的列进行字符串拼接,这要怎么做呢?使用GROUP_CONCAT()!
定义
该函数返回一个字符串结果,该字符串结果是通过分组串联的非NULL值。如果没有非NULL值,则返回NULL。完整语法如下:
GROUP_CONCAT([DISTINCT] expr [,expr ...]
[ORDER BY {unsigned_integer | col_name | expr} [ASC | DESC] [,col_name ...]]
[SEPARATOR str_val])
使用案例来进行讲解
1 完成开头需求
SELECT performance, GROUP_CONCAT(employee_name) AS employees
FROM employees
GROUP BY performance;
我们是国际化的团队,我们的家乡遍布五湖四海
领导想关怀一下员工,要查看公司全部员工的家乡都有哪些地方。员工们可能来自同一个地方,所以要将结果集去重复,DISTINCT 关键字就派上用场了
SELECT GROUP_CONCAT(DISTINCT home_town)
FROM employees;

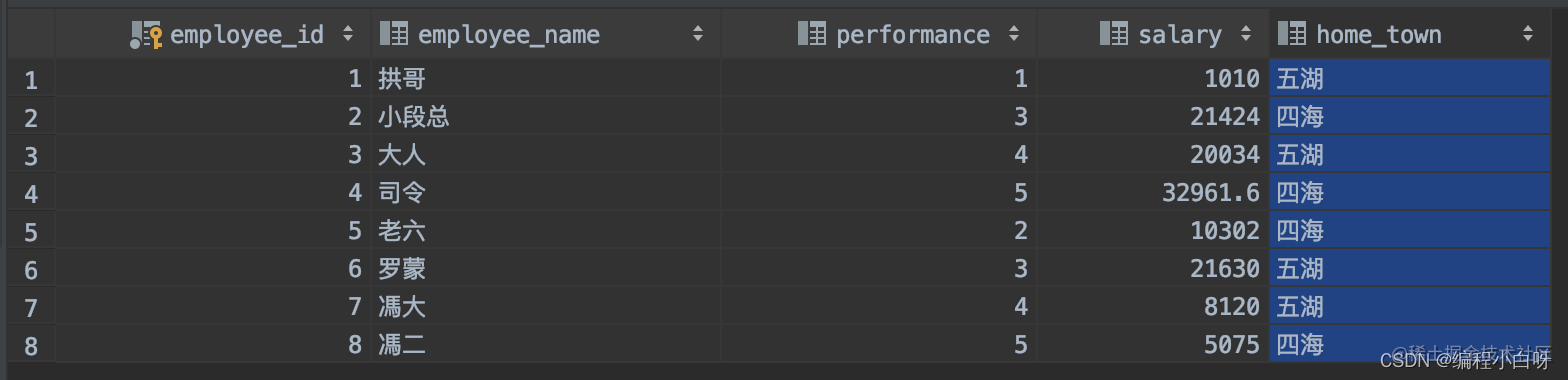
- 若想改成四海五湖,那么
ORDER BY关键字就派上用场了
SELECT GROUP_CONCAT(DISTINCT home_town ORDER BY home_town DESC) AS '领导关怀地区'
FROM employees;
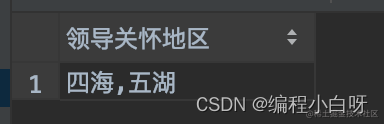
这里你看到 GROUP_CONCAT 函数拼接字符串默认的分隔符是逗号 , 领导不开心,逗号么的感情,要用!才能体现出关怀的强烈, SEPARATOR 关键字就派上用场了
SELECT GROUP_CONCAT(DISTINCT home_town ORDER BY home_town DESC SEPARATOR '!') AS '领导关怀地区'
FROM employees;
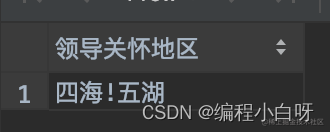
SELECT GROUP_CONCAT(DISTINCT home_town SEPARATOR '') AS '领导关怀地区'
FROM employees;
分组拼接的值之间默认分隔符是逗号(,)。要明确指定分隔符,需要使用 SEPARATOR 关键字,紧跟其后的是你想设置的分隔符。要完全消除分隔符,就在 SEPARATOR 关键字后面写 ‘’ 就好了
有时候 GROUP_CONCAT() 还要搭配 CONCAT_WS() 发挥出一点点威力,举个简单的例子
将消费者的名和姓用逗号进行分隔,然后再用 ; 进行分隔
SELECT
GROUP_CONCAT(
CONCAT_WS(', ', contactLastName, contactFirstName)
SEPARATOR ';')
FROM
customers;
6.6 datediff
datediff(date1,date2)
date1的日期,减去date2的日期,得到两个日期的天数差
select datediff('2019-01-09','2019-02-09');
+-------------------------------------+
| datediff('2019-01-09','2019-02-09') |
+-------------------------------------+
| -31 |
+-------------------------------------+
select datediff('2019-01-09','2018-02-09');
+-------------------------------------+
| datediff('2019-01-09','2018-02-09') |
+-------------------------------------+
| 334 |
+-------------------------------------+
select datediff('2018-02-09','2018-02-09');
+-------------------------------------+
| datediff('2018-02-09','2018-02-09') |
+-------------------------------------+
| 0 |
+-------------------------------------+
6.7 count(*) count(1) count(列名)

6.8 not in 与 Null
select * from users
where age not in (select age from class)
如果class表中某一行的 age 是 null 的话,返回结果是空的,因为它的查询如下。
select * from users
where age not in (21, 24,13,18, null)
这个SQL语句会被转换为:
select * from users
where age != 1 and age != 2 and age != null
d != null 结果是个未知值, null,而任意值和 null 进行 and 运算的结果都是 null, 所以相当于没有其他条件。那么出这种结果的原因就是 null 的逻辑值不为 true。
注意:age in(21,24,13,18,null)时会忽略null,非空查询才会出错。
- null值和空值不是一个概念,我们可以使用
not in (select page_id from Likes where user_id = 1)来发现不和用户1相同的页面,这个page_id可以为空,我们可以使用not in来判断,但不能使用!=来判断。 not in后可跟空,但是却不能判断null,也就是说若page_id为null的话,这个语句都是false。- 例子608可以告诉我们
not in后不能跟null值,例子1264告诉我们!=后不可以跟空,但not in可以判断空。
608 树节点


# Write your MySQL query statement below
select id, (
case when p_id is null then 'Root'
when p_id is not null and id in (select p_id from tree) then 'Inner'
else 'Leaf'
end
) as Type
from tree
总结
- not in中包含有null时,结果集一直为Empty set
- 例如,下列代码就是错误的写法:
select
id,
case when p_id is null then "Root"
when id not in (select p_id from tree) then "Leaf"
else "Inner"
end as Type
from
tree
-
A not in B的原理是拿A表值与B表值做是否不等的比较, 也就是a != b. 在sql中, null是缺失未知值而不是空值(详情请见MySQL reference).
-
当你判断任意值a != null时, 官方说,
"You cannot use arithmetic comparison operators such as =, <, or <> to test for NULL", 任何与null值的对比都将返回null. 因此返回结果为否,这点可以用代码select if(1 = null, 'true', 'false')证实. -
从上述原理可见, 当询问
id not in (select p_id from tree)时, 因为p_id有null值, 返回结果全为false, 于是跳到else的结果, 返回值为inner. 所以在答案中,leaf结果从未彰显,全被inner取代。
7. over函数
OVER的定义
OVER用于为行定义一个窗口,它对一组值进行操作,不需要使用GROUP BY子句对数据进行分组,能够在同一行中同时返回基础行的列和聚合列。
OVER ([ PARTITION BY column ] [ ORDER BY culumn ])
-
PARTITION BY子句进行分组 -
ORDER BY子句进行排序
OVER的用法
OVER开窗函数必须与聚合函数或排序函数一起使用,- 聚合函数一般指
SUM(),MAX(),MIN,COUNT(),AVG()等常见函数。 - 排序函数一般指
RANK(),ROW_NUMBER(),DENSE_RANK(),NTILE()等。
- 常见用法
-
SUM(Salary) OVER (PARTITION BY Groupname)只对
PARTITION BY后面的列Groupname进行分组,分组后求解Salary的和。 -
SUM(Salary) OVER (PARTITION BY Groupname ORDER BY ID)对
PARTITION BY后面的列Groupname进行分组,然后按ORDER BY后的ID进行排序,然后在组内对Salary进行累加处理。 -
SUM(Salary) OVER (ORDER BY ID)只对
ORDER BY后的ID内容进行排序,对排完序后的Salary进行累加处理。 -
SUM(Salary) OVER ()对
Salary进行汇总处理
练习例子(hard)
select round(avg(num), 1) as median
from (
select *,
sum(frequency) over(order by num desc) as rk1, # 右边频率总数
sum(frequency) over(order by num) as rk2, # 左边频率总数
sum(frequency) over() as s # 总的频率总数 12
from Numbers
) t
where rk1 >= s/2 and rk2 >= s/2; # 筛选出大于一半的频率数
- 这里用到了
over开窗函数的用法。 - 首先,中位数要大于所有左边频率总数也要大于右边频率总数,因此我们首先按照正序反序计算累加频率总数
rk1和rk2,再计算总的频率总数s - 其次,筛选出大于前面一半的数的
num为多少,倒序也一样 - 将这些
num求平均即为中位数
8. 练习
- 【SQL】面试篇之排序和分组练习
- 【SQL篇】面试之聚合函数
- 【SQL篇】面试之高级查询和连接
- 【SQL篇】面试篇之子查询
- 【SQL篇】窗口函数和公共表达式
对于not in 和!= 我仍然还有疑惑,因此写的可能存在问题,如果有大佬知道,麻烦给我指出下错误,谢谢啦~
参考
- SQL窗口函数
- 一篇文章搞定mysql的 行转列(7种方法) 和 列转行
- SQL多表查询:SQL JOIN连接查询各种用法总结
- sql concat_ws函数
- MySQL拼接字符串,GROUP_CONCAT 值得拥有
- 执行count(1)、count(*) 与 count(列名) 到底有什么区别?
- SQL学习笔记——MySQL——datediff函数(日期间的天数)
- 数据库11mysql之坑null专题






![P1915 [NOI2010] 成长快乐](https://img-blog.csdnimg.cn/a164f63cd9ac4a71acf90885c53b1857.png)