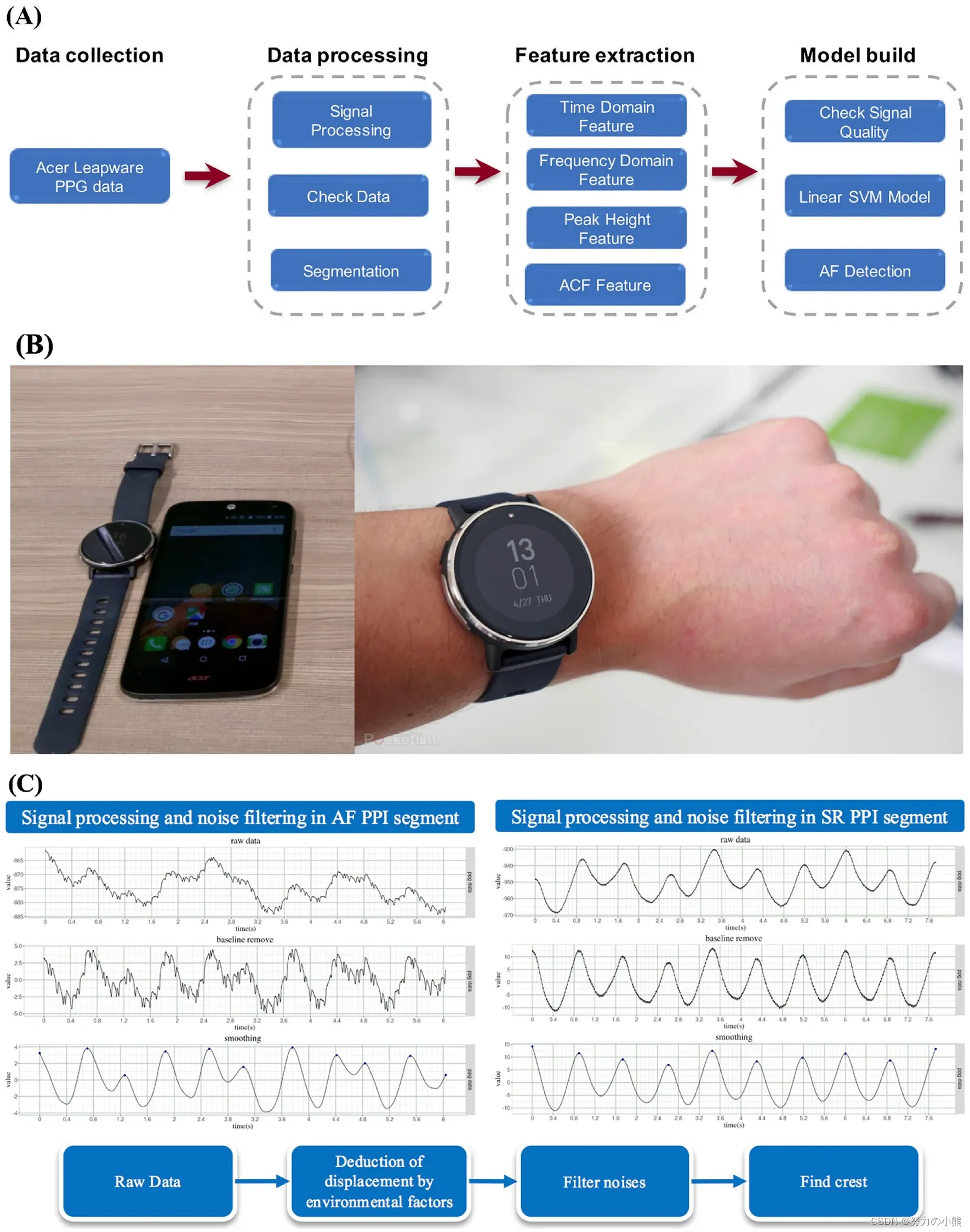
Item冷启动的目标:
1.精准推荐。
2.激励发布。
3.挖掘高潜。
Item冷启动优化措施:
1.优化全链路(召回和排序)
2.流量调控(新老物品的流量分配)
评价指标:
-
- 作者侧: 发布渗透率(发布uv/日活uv)、人均发布率。
- 用户侧:
item自身:新笔记点击率、交互率。(一定时间内,区分高、低曝光看ctr cvr)
大盘的:消费时长、日活、月活。(不能过度损害大盘消费指标) - 内容侧(选择使用):
高热笔记占比(统计前30天内获得1w曝光的item占比)
适用召回:
-
- 双塔召回
ID Embedding优化方法一:item_id向量使用defaultEmbedding
ID Embedding优化方法二:利用多模态(CNN+Bert)把item表征成向量,取多个高曝光的item的向量meanpooling作为冷启item的Embedding。
线上应用:增加多个召回池(1小时新笔记、6小时新笔记、24小时新笔记、30天老笔记)向量相同,合并多个召回结果。 - 类目、关键词召回
- 双塔召回
使用用户画像的关键词进行召回。维护类目_id 或者 关键词 -> item_i的时间倒排,召回合并多个列表。(弱个性化、但是强时间)
物料自身的基本属性,关键词提取召回(比如物料中包含的公司名,人名,地名等)
-
- 聚类召回
- 思想:根据用户行为last_n ,推荐内容相似的笔记
- 离线:训练基于图文(Bert+CNN+FC)神经网络模型,(利用类目和点击数据生成pair-wise样本)。
- 线下训练:多模态神经网络把图文内容映射到向量。
- 线上服务:last n->n个特征向量->n个Cluster->n*m个新笔记。
- 实现细节:使用(CNN+Bert)对item的图文进行表征得到向量,K-means聚类(余弦)得到1000个cluster。新item发布后想转成向量,然后计算最相似的Cluster,然后加到当前cluster的索引中【Cluster->item_id时间倒序】。
- Look-Alike召回
- 线下训练:用item交互过的user的向量mean-pooling得到item的向量,存到milvus。
- 线上服务:先得到user的向量,然后从milvus取TopK个item
- 聚类召回
实现细节:Look-Alike其实就是一种特殊的ucf,并且对于item冷启是比较有利的,因为新item的emb是学习不充分的,但是交互的user不一定是新用户,他的emb可能是学习充分的,这样利于item冷启
流量调控:
-
-
- 强插
- Boost:排序分数做提权
在粗排、精排处理,但是固定权重很难调到比较合适的权重。 - 静态保量:通过提权保量
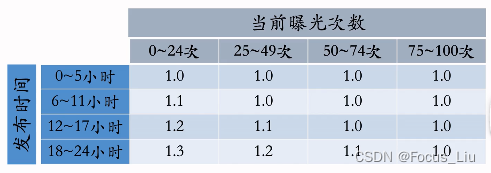
-
为了:保证24小时内获得100次曝光。
-
-
- 动态保量:通过提权保量
-
根据目标时间、目标曝光、发布时间、已有曝光,决定权重。

需要调整调权。
-
-
- 差异化保量:24小时内高质量保300 低质量保100。
-
通过内容质量、作者质量等决定保量目标。
-
-
- 退场策略,设置曝光和点击阈值,过滤低质物料,增加优质资源的曝光
-
线上环境(新召回、精排变动、重排规则)的变化都有可能导致保量失败。
冷启AB:
其他:
召回只分发最近30天内的。
参考资料:ShusenWang的个人空间-ShusenWang个人主页-哔哩哔哩视频



![P1915 [NOI2010] 成长快乐](https://img-blog.csdnimg.cn/a164f63cd9ac4a71acf90885c53b1857.png)