本文要介绍的是由上海交通大学的研究人员提出的PNN(Product-based Neural Networks)模型,该模型包含一个embedding层来学习类别数据的分布式表示,此外还包含product层来捕获字段之间的特征交互模式,最后包含一个全连接层去挖掘更高阶的特征交互。
相比Deep Crossing模型,PNN模型在输入、EMbedding层、多层神经网络、以及最终的输出层并没有什么结构上的不同,唯一的区别在于PNN引入了Product(乘积)层来代替了Deep Crossing中的Stack层,即不同特征的embedding向量不再是简单地拼接在一起,而是使用Product操作来进行两两交互,更有针对性地获取特征之间的交叉信息。
PNN模型出自论文《Product-based Neural Networks for User Response Prediction》。
文章目录
- 完整源码&技术交流
- 模型简介
- 输出层
- L2隐层
- L1隐层
- Product层
- IPNN
- OPNN
- 代码实践
完整源码&技术交流
技术要学会分享、交流,不建议闭门造车。一个人走的很快、一堆人可以走的更远。
文章中的完整源码、资料、数据、技术交流提升, 均可加知识星球交流群获取,群友已超过2000人,添加时切记的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、添加微信号:mlc2060,备注:来自 获取推荐资料
方式②、微信搜索公众号:机器学习社区,后台回复:推荐资料
模型简介
先看一下整体的模型结构图:
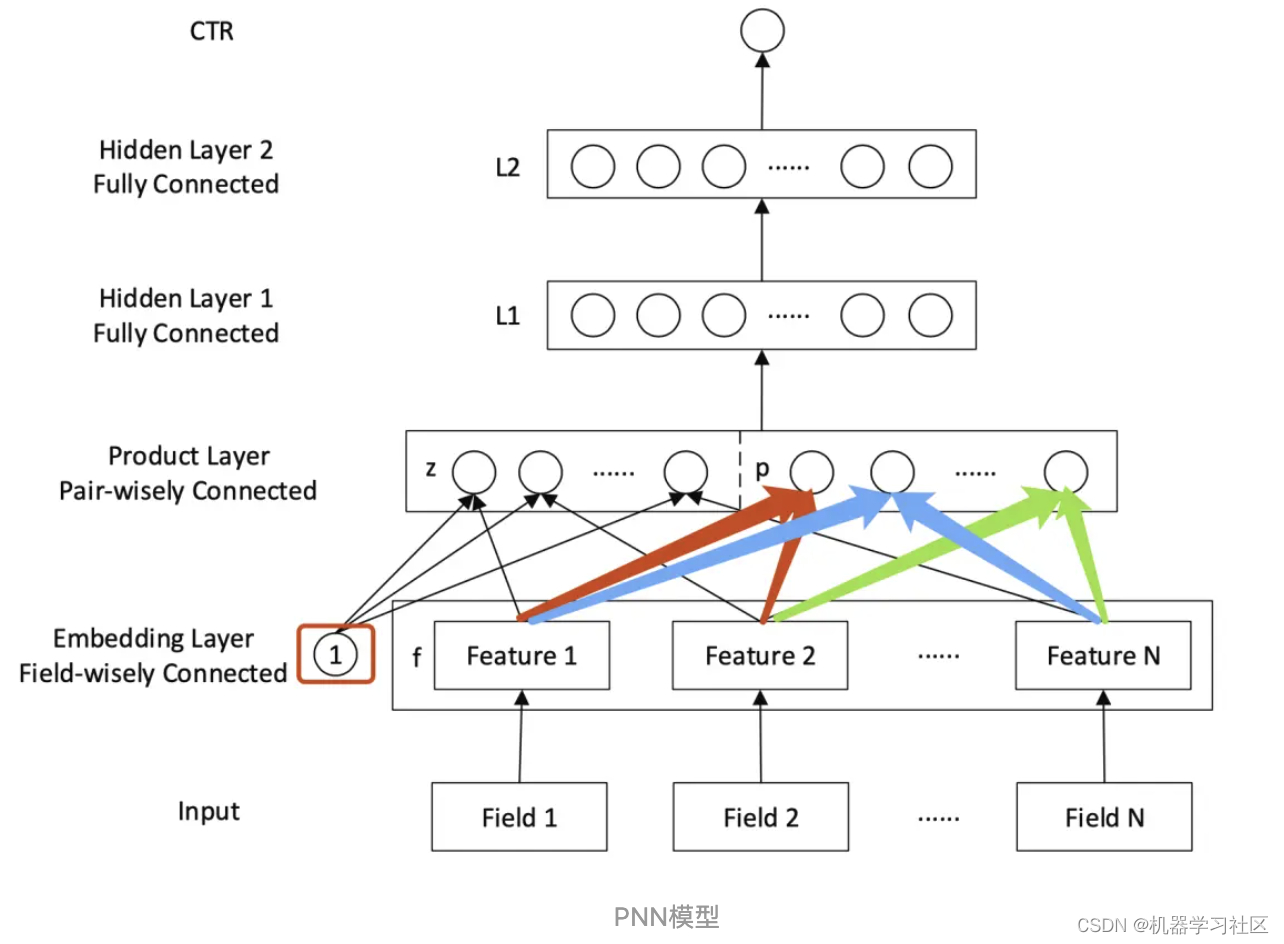
从自顶向下的视角对模型结构逐步分析:
输出层
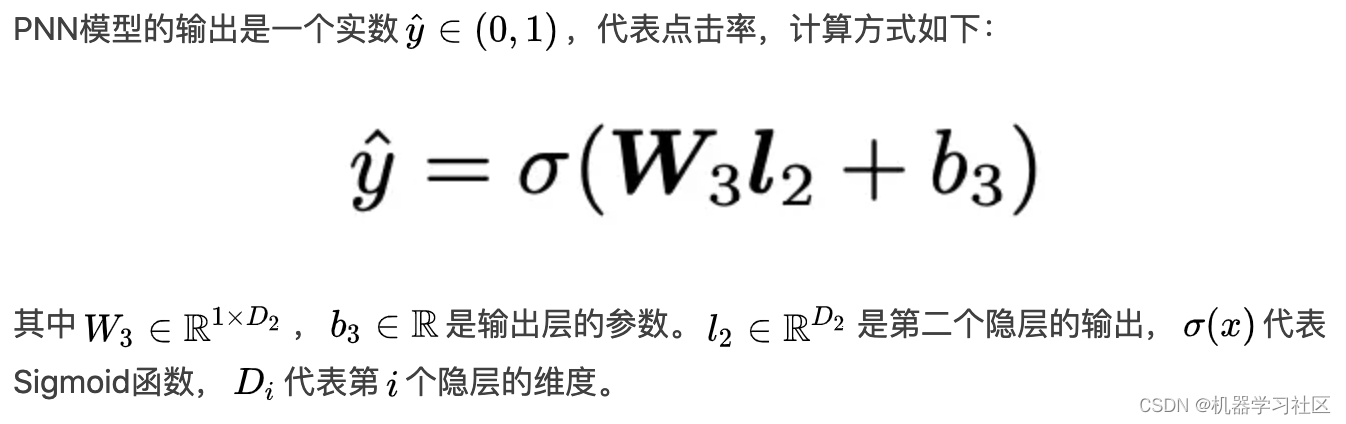
L2隐层

L1隐层

Product层
PNN模型对深度学习结构的创新主要体现在Product层的引入,下面详细介绍下它们的计算方式。首先定义向量的内积操作:
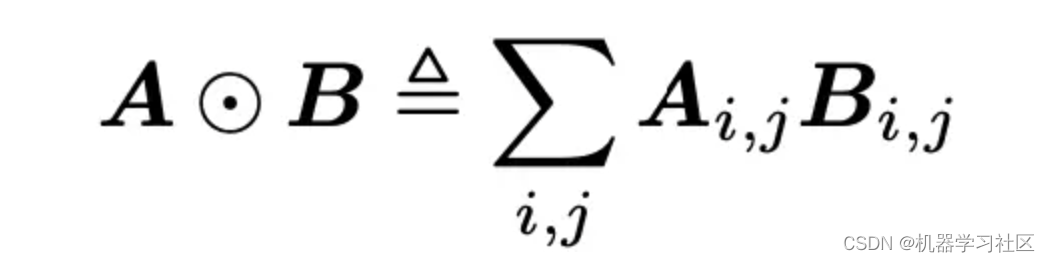
IPNN
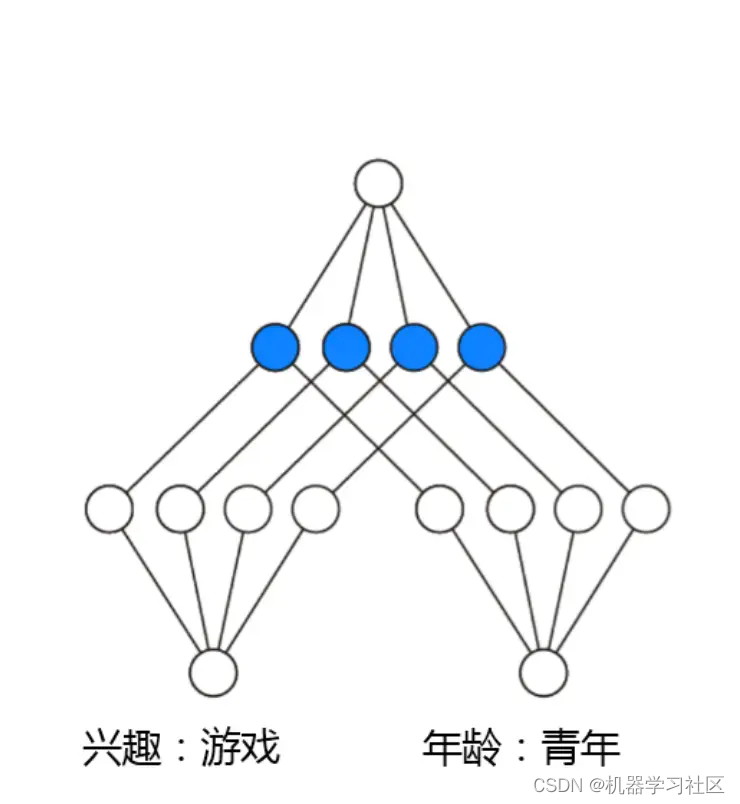
首先定义向量的内积操作:
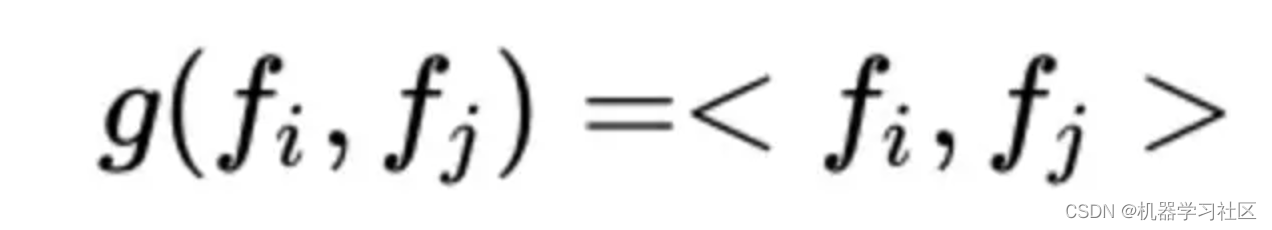
内积操作可以可视化如下:
OPNN
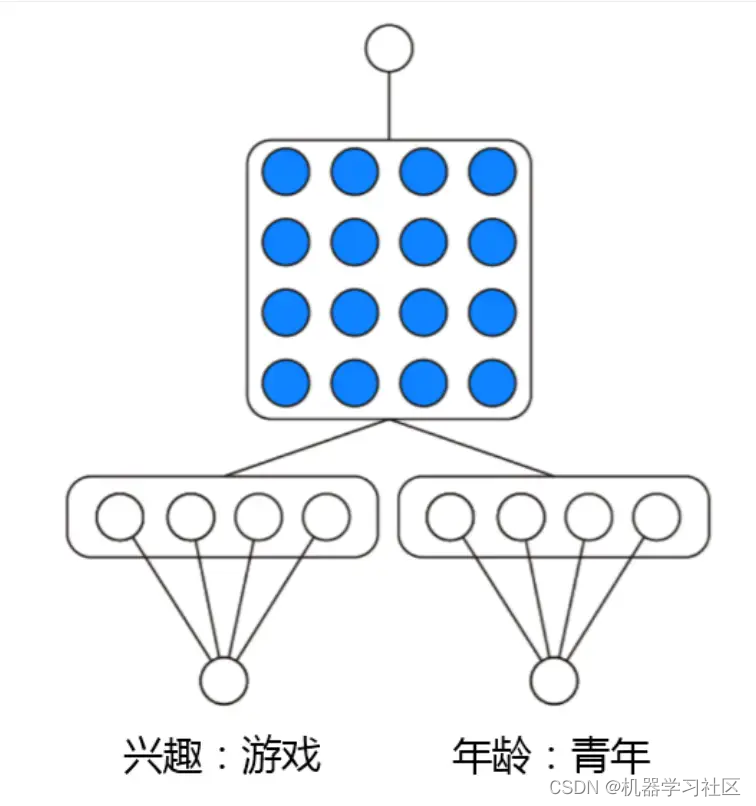
将特征交叉的方式由内积变为外积,则可得到OPNN的形式。外积的示意图如下:
代码实践
模型部分包含了InnerProduct、OutterProduct、以及PNN模型,代码如下:
import torch
import torch.nn as nn
from BaseModel.basemodel import BaseModel
class InnerProduct(nn.Module):
"""InnerProduct Layer used in PNN that compute the element-wise
product or inner product between feature vectors.
Input shape
- a list of 3D tensor with shape: ``(batch_size,1,embedding_size)``.
Output shape
- 3D tensor with shape: ``(batch_size, N*(N-1)/2 ,1)`` if use reduce_sum. or 3D tensor with shape:
``(batch_size, N*(N-1)/2, embedding_size )`` if not use reduce_sum.
Arguments
- **reduce_sum**: bool. Whether return inner product or element-wise product
"""
def __init__(self, reduce_sum=True):
super(InnerProduct, self).__init__()
self.reduce_sum = reduce_sum
def forward(self, inputs):
embed_list = inputs
row,col = [], []
num_inputs = len(embed_list)
# 这里为了形成n(n-1)/2个下标的组合
for i in range(num_inputs - 1):
for j in range(i + 1, num_inputs):
row.append(i)
col.append(j)
p = torch.cat([embed_list[idx] for idx in row], dim=1) # batch num_pairs k
q = torch.cat([embed_list[idx] for idx in col], dim=1)
# inner_product 中包含了 n(n-1)/2 个 embedding size大小的向量,为了减少计算复杂度,将最后的维度求和,即将embedding size大小变为1
inner_product = p * q
if self.reduce_sum:
# 默认打开,将最后一维的数据累加起来,降低计算复杂度
inner_product = torch.sum(inner_product, dim=2, keepdim=True)
return inner_product
class OutterProduct(nn.Module):
"""
Input shape
- A list of N 3D tensor with shape: ``(batch_size,1,embedding_size)``.
Output shape
- 2D tensor with shape:``(batch_size,N*(N-1)/2 )``.
Arguments
- **filed_size** : Positive integer, number of feature groups.
- **kernel_type**: str. The kernel weight matrix type to use,can be mat,vec or num
"""
def __init__(self, field_size, embedding_size, kernel_type='mat'):
super(OutterProduct, self).__init__()
self.kernel_type = kernel_type
num_inputs = field_size
num_pairs = int(num_inputs * (num_inputs - 1) / 2)
embed_size = embedding_size
if self.kernel_type == 'mat':
self.kernel = nn.Parameter(torch.Tensor(embed_size, num_pairs, embed_size))
elif self.kernel_type == 'vec':
self.kernel = nn.Parameter(torch.Tensor(num_pairs, embed_size))
elif self.kernel_type == 'num':
self.kernel = nn.Parameter(torch.Tensor(num_pairs, 1))
nn.init.xavier_uniform_(self.kernel)
def forward(self, inputs):
embed_list = inputs
row = []
col = []
num_inputs = len(embed_list)
for i in range(num_inputs - 1):
for j in range(i + 1, num_inputs):
row.append(i)
col.append(j)
p = torch.cat([embed_list[idx] for idx in row], dim=1) # batch num_pairs k
q = torch.cat([embed_list[idx] for idx in col], dim=1)
# -------------------------
if self.kernel_type == 'mat':
p.unsqueeze_(dim=1)
# k k* pair* k
# batch * pair
kp = torch.sum(
# batch * pair * k
torch.mul(
# batch * pair * k
torch.transpose(
# batch * k * pair
torch.sum(
# batch * k * pair * k
torch.mul(p, self.kernel), dim=-1), 2, 1),
q),
dim=-1)
else:
# 1 * pair * (k or 1)
k = torch.unsqueeze(self.kernel, 0)
# batch * pair
kp = torch.sum(p * q * k, dim=-1)
# p q # b * p * k
return kp
class PNN(BaseModel):
def __init__(self, config, dense_features_cols, sparse_features_cols):
super(PNN, self).__init__(config)
# 稠密和稀疏特征的数量
self._num_of_dense_feature = dense_features_cols.__len__()
self._num_of_sparse_feature = sparse_features_cols.__len__()
# create embedding layers for all the sparse features
self.embedding_layers = nn.ModuleList([
# 根据稀疏特征的个数创建对应个数的Embedding层,Embedding输入大小是稀疏特征的类别总数,输出稠密向量的维度由config文件配置
nn.Embedding(num_embeddings=sparse_features_cols[idx], embedding_dim=config['embed_dim']) for idx in range(self._num_of_sparse_feature)
])
self.use_inner = config['use_inner']
self.use_outter = config['use_outter']
self.kernel_type = config['kernel_type']
if self.kernel_type not in ['mat', 'vec', 'num']:
raise ValueError("kernel_type must be mat,vec or num")
num_inputs = self._num_of_sparse_feature
# 计算两两特征交互的总数
num_pairs = int(num_inputs * (num_inputs - 1) / 2)
if self.use_inner:
self.innerproduct = InnerProduct()
if self.use_outter:
self.outterproduct = OutterProduct(num_inputs, config['embed_dim'], kernel_type=config['kernel_type'])
# 计算L1全连接层的输入维度
if self.use_outter and self.use_inner:
product_out_dim = 2*num_pairs + self._num_of_dense_feature + config['embed_dim'] * self._num_of_sparse_feature
elif self.use_inner or self.use_outter:
product_out_dim = num_pairs + self._num_of_dense_feature + config['embed_dim'] * self._num_of_sparse_feature
else:
raise Exception("you must specify at least one product operation!")
self.L1 = nn.Sequential(
nn.Linear(in_features=product_out_dim, out_features=config['L2_dim']),
nn.ReLU()
)
self.L2 = nn.Sequential(
nn.Linear(in_features=config['L2_dim'], out_features=1, bias=False),
nn.Sigmoid()
)
def forward(self, x):
# 先区分出稀疏特征和稠密特征,这里是按照列来划分的,即所有的行都要进行筛选
dense_input, sparse_inputs = x[:, :self._num_of_dense_feature], x[:, self._num_of_dense_feature:]
sparse_inputs = sparse_inputs.long()
# 求出稀疏特征的隐向量
sparse_embeds = [self.embedding_layers[i](sparse_inputs[:, i]) for i in range(sparse_inputs.shape[1])]
# 线性信号lz
linear_signal = torch.cat(sparse_embeds, axis=-1)
sparse_embeds = [e.reshape(e.shape[0], 1, -1) for e in sparse_embeds]
if self.use_inner:
inner_product = torch.flatten(self.innerproduct(sparse_embeds), start_dim=1)
product_layer = torch.cat([linear_signal, inner_product], dim=1)
if self.use_outter:
outer_product = self.outterproduct(sparse_embeds)
product_layer = torch.cat([linear_signal, outer_product], dim=1)
if self.use_outter and self.use_inner:
product_layer = torch.cat([linear_signal, inner_product, outer_product], dim=1)
# 将dense特征和sparse特征聚合起来
dnn_input = torch.cat([product_layer, dense_input], axis=-1)
output = self.L1(dnn_input)
output = self.L2(output)
return output
上述代码实现的模型与论文中有些许差异,主要在L1层。实际上,PNN模型在经过对特征的线性和乘积操作之后,并没有结果直接送到上层的L1全连接层,而是在乘积层内部又进行了局部全连接层的转换,这其实也并不影响我们理解论文的思想。
测试部分代码:
import torch
from DeepCross.trainer import Trainer
from PNN.network import PNN
from Utils.criteo_loader import getTestData, getTrainData
import torch.utils.data as Data
pnn_config = \
{
'L2_dim': 256, # 设置L2隐层的输入维度
'embed_dim': 8,
'kernel_type': 'mat',
'use_inner': True,
'use_outter': False,
'num_epoch': 25,
'batch_size': 32,
'lr': 1e-3,
'l2_regularization': 1e-4,
'device_id': 0,
'use_cuda': False,
'train_file': '../Data/criteo/processed_data/train_set.csv',
'fea_file': '../Data/criteo/processed_data/fea_col.npy',
'validate_file': '../Data/criteo/processed_data/val_set.csv',
'test_file': '../Data/criteo/processed_data/test_set.csv',
'model_name': '../TrainedModels/pnn.model'
}
if __name__ == "__main__":
####################################################################################
# PNN 模型
####################################################################################
training_data, training_label, dense_features_col, sparse_features_col = getTrainData(pnn_config['train_file'], pnn_config['fea_file'])
train_dataset = Data.TensorDataset(torch.tensor(training_data).float(), torch.tensor(training_label).float())
test_data = getTestData(pnn_config['test_file'])
test_dataset = Data.TensorDataset(torch.tensor(test_data).float())
pnn = PNN(pnn_config, dense_features_cols=dense_features_col, sparse_features_cols=sparse_features_col)
####################################################################################
# 模型训练阶段
####################################################################################
# # 实例化模型训练器
trainer = Trainer(model=pnn, config=pnn_config)
# 训练
trainer.train(train_dataset)
# 保存模型
trainer.save()
####################################################################################
# 模型测试阶段
####################################################################################
pnn.eval()
if pnn_config['use_cuda']:
pnn.loadModel(map_location=lambda storage, loc: storage.cuda(pnn_config['device_id']))
pnn = pnn.cuda()
else:
pnn.loadModel(map_location=torch.device('cpu'))
y_pred_probs = pnn(torch.tensor(test_data).float())
y_pred = torch.where(y_pred_probs>0.5, torch.ones_like(y_pred_probs), torch.zeros_like(y_pred_probs))
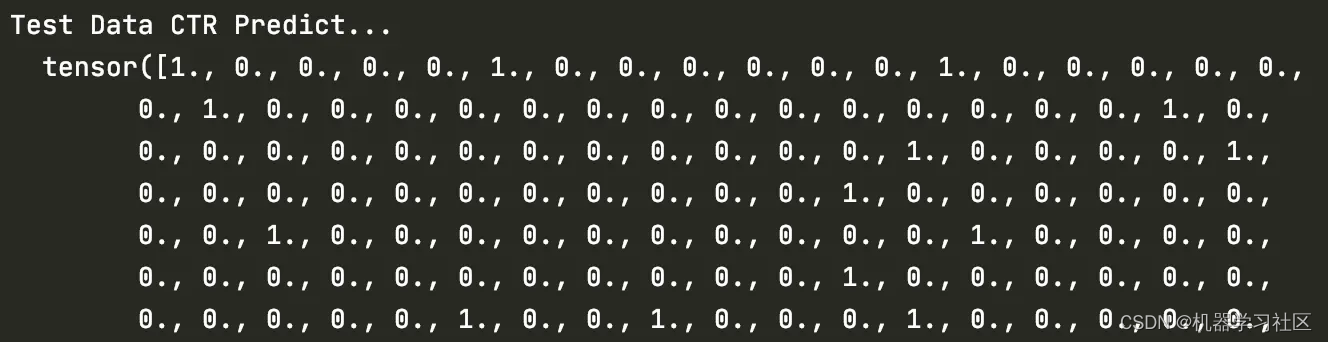
print("Test Data CTR Predict...\n ", y_pred.view(-1))
使用了criteo数据集的一个很小的子集进行训练和测试,输出是点击率预测,判断点击率大于0.5的就认为用户会点击,否则不点击。以下是部分结果,其中’0‘代表预测用户不点击,’1‘代表预测用户点击。





![P1915 [NOI2010] 成长快乐](https://img-blog.csdnimg.cn/a164f63cd9ac4a71acf90885c53b1857.png)