1、发送请求403报错排查
参考链接链接: 使用scrapy做爬虫遇到的一些坑:爬虫使用scrapy爬取网页返回403错误大全以及解决方案
参考链接链接: 使用scrapy做爬虫遇到的一些坑:网站常用的反爬虫策略,如何机智的躲过反爬虫Crawled (403)
参考链接链接: 如何查看scrapy 爬取过程中的报错(附解决方法及运行结果解读)
2、使用selenium登陆网页获取cookie
3、同一个网站,同一个请求头,request可以成功,scrapy却不行

我自己的试过所有方法都不行,最后在scrapy中请求,host放到第一个就可以了
4、报错:[scrapy.core.scraper] ERROR: Spider must return request, item, or None, got ‘str’ in <GET https://XXX>

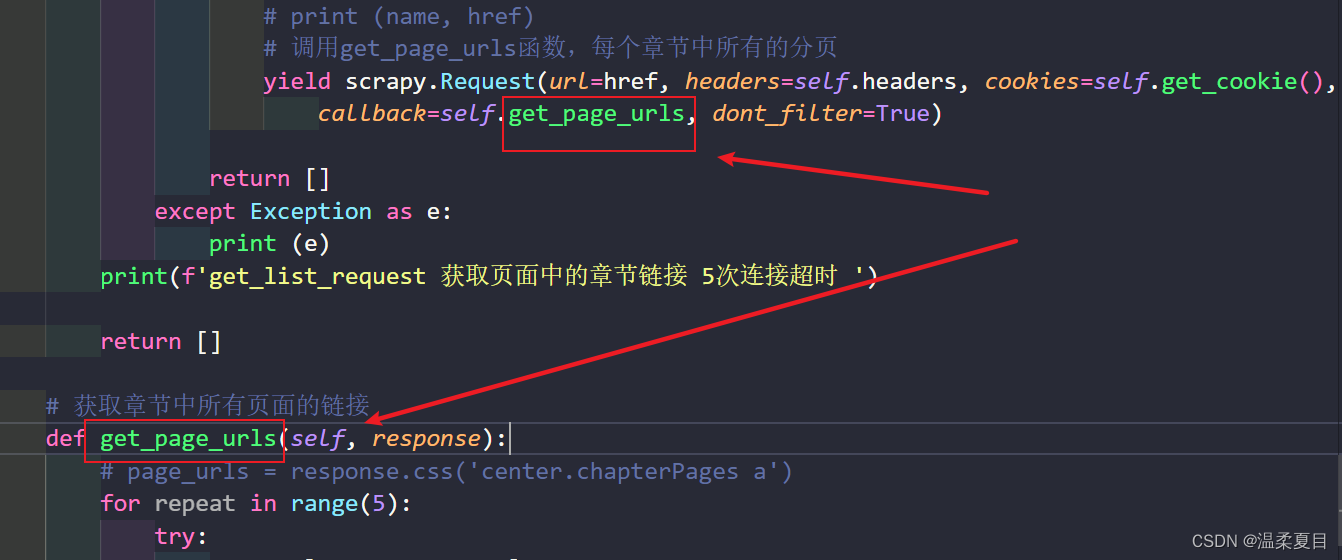
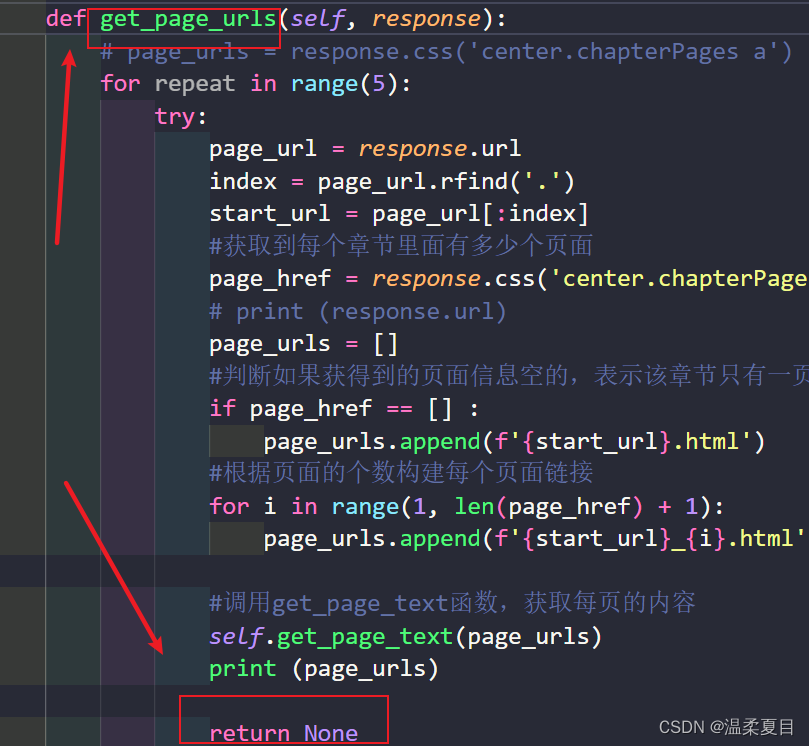
上一个函数中使用了:yield关键字,回调函数是下一个get_page_urls函数,则在get_page_urls中的return返回的类型必须是:请求、item、None这3个类型,其他类型会报错,一开始我返回的一个列表报错,改了之后就好了
5、重写start_requests方法,传入自定义header和cookie
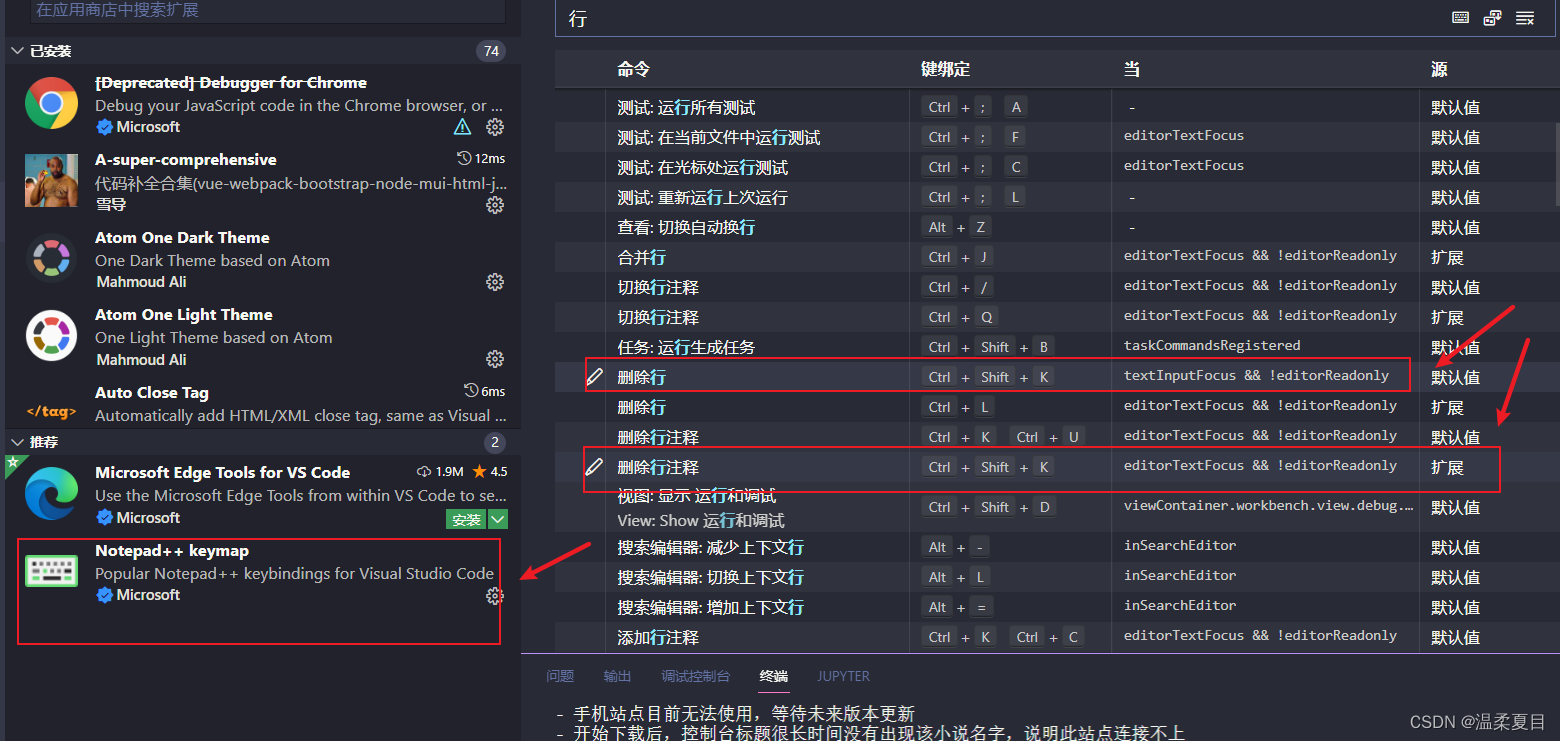
6、vscode多个快捷键重合
因为安装了推荐的Notepad++ keymap扩展,卸载就可以了
7。报错:too many values to unpack (expected 2)
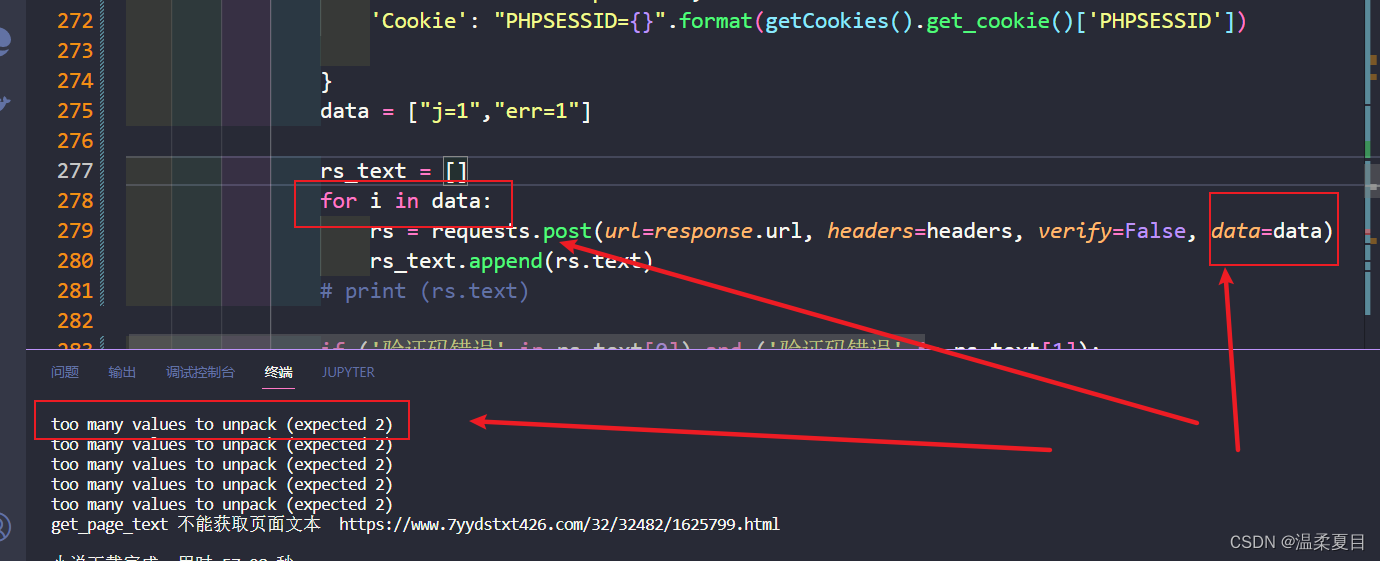
自己改了data字符为列表,在请求中没有更改,报错
8、使用yield提交item数据,数据重复,错乱,不正确- 使用深度复制
参考下面博主方法即可:使用深度复制
参考链接: 提莫_:scrapy里面item传递数据后数据不正确的问题
import copy
yield copy.deepcopy(item)
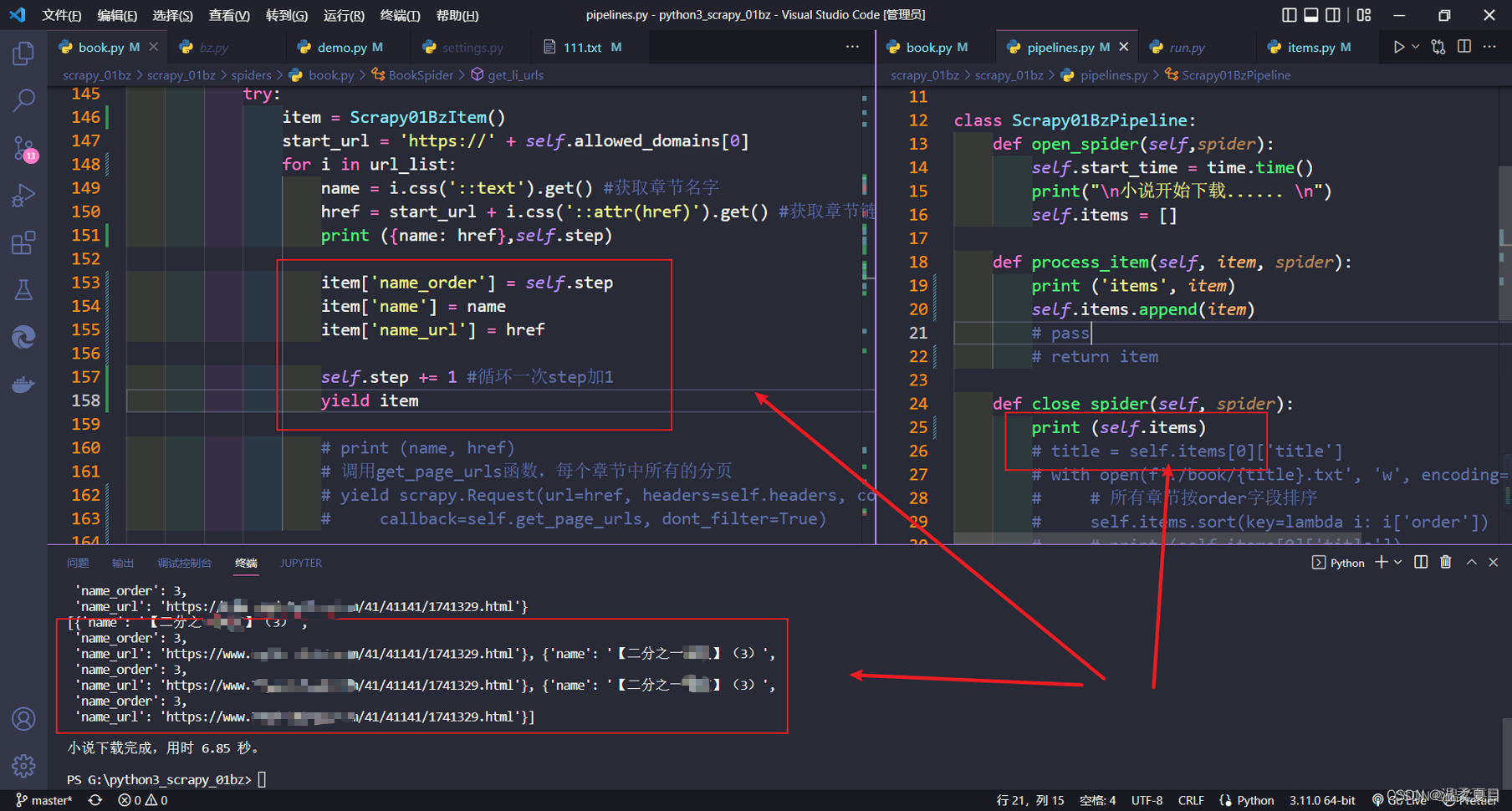
引入copy模块,改为深复制即可,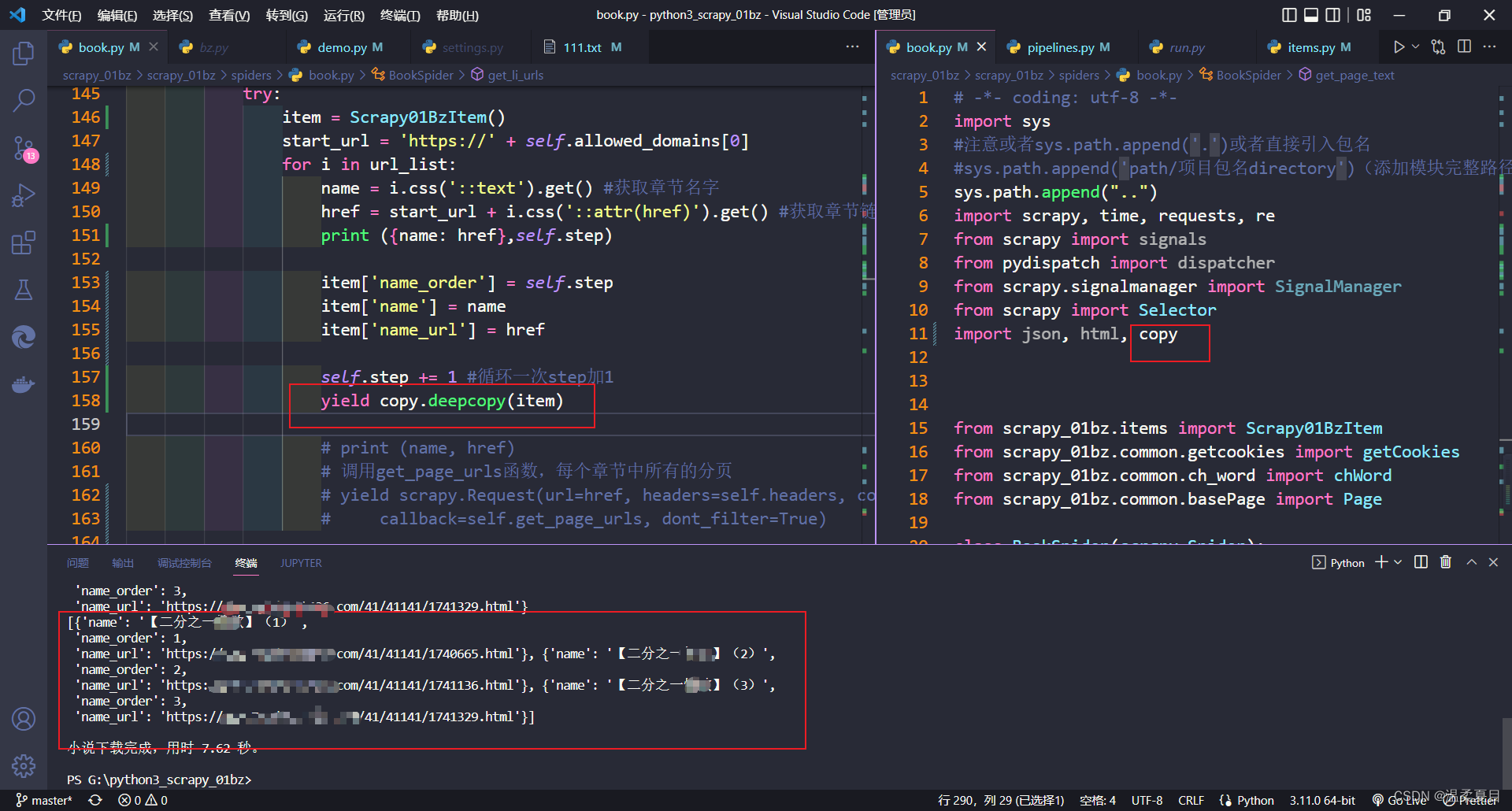
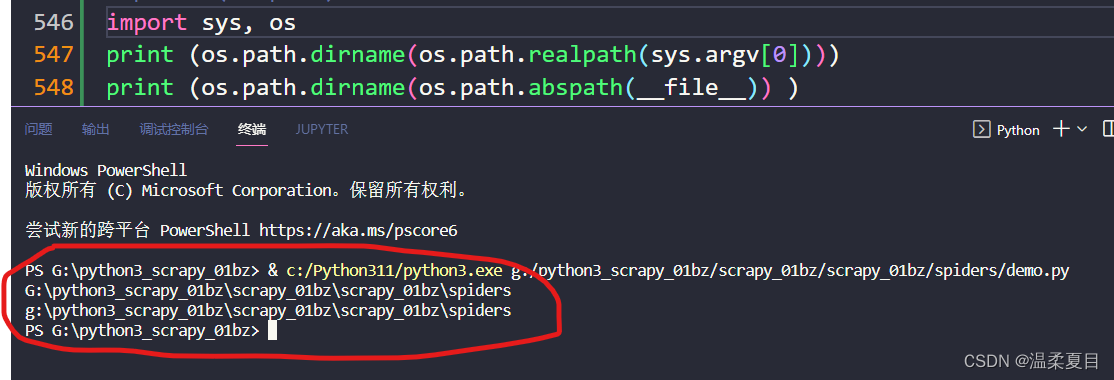
9、python代码获取正常windows路径,打包exe后在windows环境下获取工作目录路径为C:\Users\用户名\AppData\Local\Temp…
参考链接: python获取工作目录路径为C:\Users\用户名\AppData\Local\Temp…解决方案
参考链接: python获取windows路径_python在windows环境下获取工作目录路径为C:\Users\用户名\AppData\Local\Temp…
以下两句代码都可以:
import sys, os
print (os.path.dirname(os.path.realpath(sys.argv[0])))
print (os.path.dirname(os.path.abspath(__file__)) )
10、scrapy中取消所有日志打印、不影响代码运行的提醒
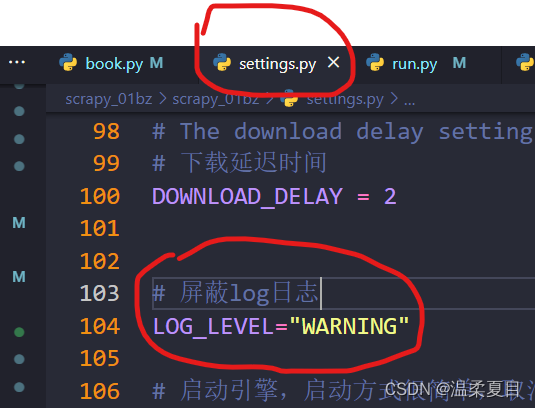
1、scrapy运行日志
在setting.cfg文件中更改日志级别
# 屏蔽log日志
LOG_LEVEL="WARNING"

2、selenium在cmd运行提示设备连接失败:DevTools listening on ### USB: usb_device_handle_win.cc:1046 Failed to read descriptor from node connection: 连到系统上的设备没有发挥作用。
参考链接: 记录一个selenium和scrapy 框架一起使用出错的记录,以及解决它的方法
# 配置选项
options = webdriver.ChromeOptions()
# 忽略证书错误
options.add_argument('--ignore-certificate-errors')
# 忽略 Bluetooth: bluetooth_adapter_winrt.cc:1075 Getting Default Adapter failed. 错误
options.add_experimental_option('excludeSwitches', ['enable-automation'])
# 忽略 DevTools listening on ws://127.0.0.1... 提示
options.add_experimental_option('excludeSwitches', ['enable-logging'])
driver = webdriver.Chrome(options=options)

3、requests使用verify=false,运行提示:
InsecureRequestWarning: Unverified HTTPS request is being made to host ‘www.dytt89.com‘
参考链接: requests.exceptions.SSLError 请求异常,SSL错误,证书认证失败问题解决
参考链接: 【解决】InsecureRequestWarning: Unverified HTTPS request is being made to host ‘www.dytt89.com‘
代码:
import requests
requests.packages.urllib3.disable_warnings() #取消证书的验证verify=False问题警告信息
4、运行scrapy会有警告日志:[py.warnings] WARNING: C:\Python311\Lib\site-packages\scrapy\selector\unified.py:83: UserWarning: Selector got both text and root, root is being ignored.
参考链接: Python之warnings模块忽略warning警告错误
使用代码:
import warnings
warnings.filterwarnings("ignore") #去除不影响程序运行的警告

11、解决selenium正常进入抖音没问题,headless无头模式报错的问题
参考链接: 解决selenium正常进入抖音没问题,headless无头模式报错的问题
在options中添加用户头即可
#防止有的元素在无头模式下无法操作,加入谷歌浏览器的user-agent信息,版本信息不能超过驱动的版本,否则无头模式会报错
chrome_options.add_argument("User-Agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like
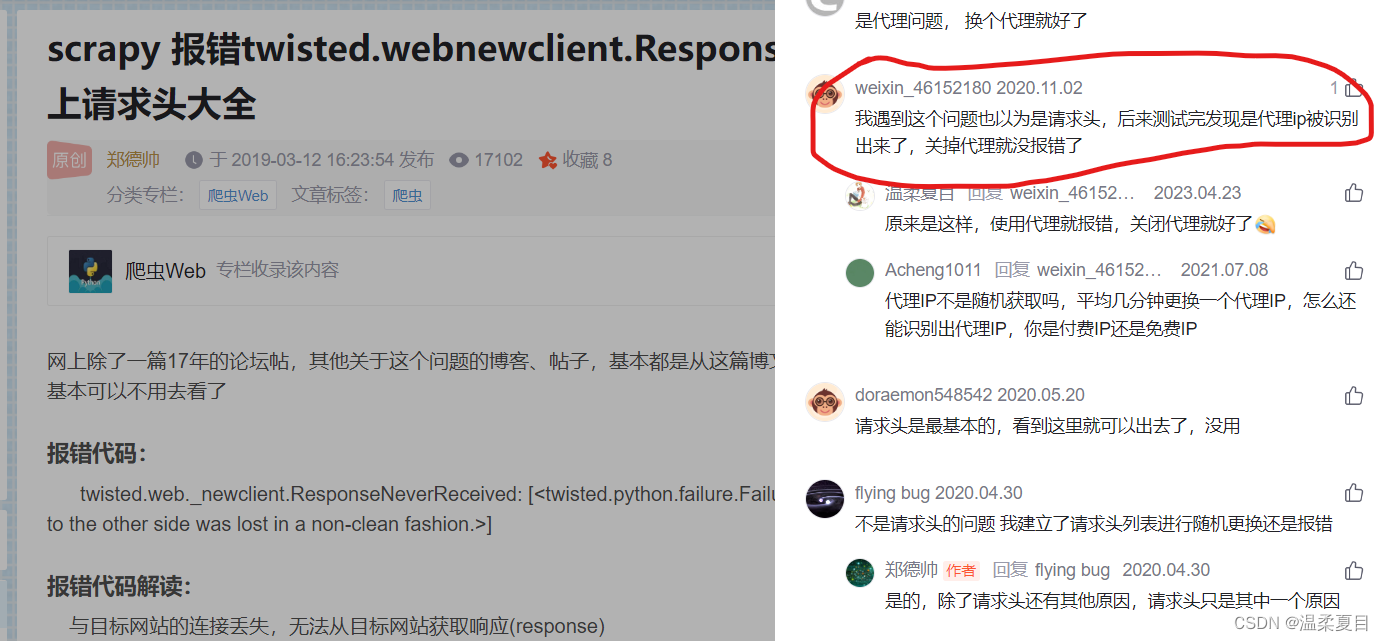
12、scrapy 报错twisted.webnewclient.ResponseNeverReceived
参考链接: scrapy 报错twisted.webnewclient.ResponseNeverReceived。。。及附上请求头大全
评论:代理问题,关闭即可





![[stable-diffusion-art] 指北-2 如何为sd提出好的prompt](https://img-blog.csdnimg.cn/4e58f54a484b4e0d891c711cf8ef76c9.png)