🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
自然语言处理
句子分割
Tokenization
词性标注
词干和词形还原
停止词的识别
短语提取
命名实体识别
共指消解
词袋
结论
随着最近技术的进步,通信是出现革命性发展的领域之一。通信和信息构成了现代社会的支柱,正是语言和通信导致了人类知识在各个领域的这种进步。人类一直对机器或机器人具有类似人类的能力来用我们的语言进行交谈的想法着迷。许多科幻书籍和媒体都讨论过这个话题。图灵测试就是为此目的而设计的,以测试人类是否能够破译通信通道另一端的实体是人还是机器。
对于计算机,我们从计算机可以解释的二进制语言开始,然后根据指令进行计算。然而,随着时间的推移,我们提出了过程语言和面向对象的语言,这些语言使用更自然的语言语法和指令,并且与人类交流的词语和方式相对应。此类构造的示例是 for 循环和 if 构造。
随着计算能力的提高和计算机处理大量数据的能力的提高,使用机器学习 (ML)和深度学习模型来理解人类语言变得更加容易。随着神经网络、递归神经网络 (RNN)和其他深度学习技术的普及以及运行这些模型的计算能力的可用,开发人员可以使用各种自然语言处理 (NLP)平台在云端和其他平台上工作前提。本章将带您了解 NLP 的基础知识。
自然语言处理
NLP 是人工智能(AI)的一个分支, 它使计算机能够阅读、理解和处理人类语言。计算机很容易从电子表格、数据库、JavaScript 对象表示法 (JSON) 文件等结构化系统中读取数据。然而,很多信息都表示为非结构化数据,这对计算机理解和生成知识或信息来说非常具有挑战性。为了解决这些问题,NLP 提供了一套技术或方法论阅读、处理和理解人类语言并从中产生知识。目前,包括 IBM、谷歌、微软、Facebook、OpenAI 等在内的众多公司一直在提供各种 NLP 技术作为服务。一些开源库,如 NLTK、spaCy 等,也是分解和理解语言文本背后含义的关键推动者。
众所周知,文本的处理和理解是一个非常复杂的问题。数据科学家、研究人员和开发人员一直在通过构建管道来解决 NLP 问题:将 NLP 问题分解成更小的部分;使用相应的 NLP 技术和 ML 方法(如实体识别、文档摘要等)解决每个子部分;最后将所有零件或模型组合或堆叠在一起作为问题的最终解决方案。
-
语法 :定义文本中单词排序的规则。例如,主语、动词和宾语的顺序应该正确,句子的句法才正确。
-
语义 :定义文本中单词的含义以及这些单词应该如何组合在一起。例如,在“我想将钱存入此银行帐户”这句话中,“银行”一词指的是金融机构。
-
语用学 :定义特定上下文中单词的用法或选择。例如,“银行”这个词可以根据上下文有不同的含义。例如,“银行”也可以指金融机构或河边的土地。
-
语言翻译:语言翻译被认为是 NLP 和 NLU 中最复杂的问题之一。您可以提供文本片段或文档,这些系统会将它们转换成另一种语言。谷歌、微软和 IBM 等一些主要的云供应商将此功能作为服务提供,任何人都可以将其用于基于 NLP 的系统。例如,从事对话系统开发的开发人员可以利用这些供应商的翻译服务在对话系统中启用多语言功能,甚至无需进行任何实际开发。
-
问答系统 :如果你想实现一个系统来从文档、段落、数据库或任何其他系统中找到问题的答案,这种类型的系统非常有用。在这里,NLU 负责理解用户的查询以及包含该问题答案的文档或段落(非结构化文本)。问答系统存在一些变体,例如基于阅读理解的系统、数学系统、多项选择系统、问答系统等。
-
支持工单的自动路由 :这些系统通读客户支持工单的内容并将其路由给可以解决问题的人。在这里,NLU 使这些系统能够处理和理解电子邮件、主题、聊天数据等,并将它们路由到适当的支持人员,从而避免由于错误分配而导致的额外跃点。
问答系统、机器翻译、命名实体识别 (NER)、文档摘要、词性 (POS) 标记和搜索引擎等系统是基于 NLP的系统的一些示例。
机器学习 (ML)是对算法和统计模型的科学研究,计算机系统使用这些算法和统计模型来执行特定任务,而无需使用明确的指令,而是依赖于模式和推理。机器学习算法用于各种应用,例如电子邮件过滤和计算机视觉。它可以分为两种类型,即监督学习和非监督学习。
-
机器学习的应用有哪些?
-
机器学习指的是什么类型的研究?
-
计算机使用什么类型的模型来执行特定任务?
-
句子分割
-
Tokenization
-
词性标注
-
词干提取和词形还原
-
停用词的识别
句子分割
-
机器学习 (ML) 是对算法和统计模型的科学研究,计算机系统使用这些算法和统计模型来执行特定任务,而无需使用明确的指令,而是依赖于模式和推理。
-
机器学习算法用于各种应用,例如电子邮件过滤和计算机视觉。
-
它可以分为两种类型,即监督学习和非监督学习。
早期的句子分割实现非常简单,只需根据标点符号或“句号”来分割文本。但是,当文档或一段文本格式不正确或语法不正确时,有时会失败。现在,有一些高级的 NLP 方法,例如序列学习,即使句号不存在或文档格式不正确,也能分割一段文本,基本上是通过使用语义理解和句法理解来分解文本来提取短语。
Tokenization
NLP 管道中的下一个任务是标记化 。在此任务中,我们将每个句子分成多个标记。标记可以是字符、单词或短语。标记化中使用的基本方法是将一个句子拆分成单独的单词,只要它们之间有空格。例如,考虑我们示例文本中的第二句话:“机器学习算法用于各种应用程序,例如电子邮件过滤和计算机视觉。” 这是将标记化应用于此示例的结果。
但是,有一些高级标记化方法,例如可以从句子中提取短语的马尔可夫链模型。例如,可以通过应用高级 ML 和 NLP 方法将“机器学习”提取为短语。
词性标注
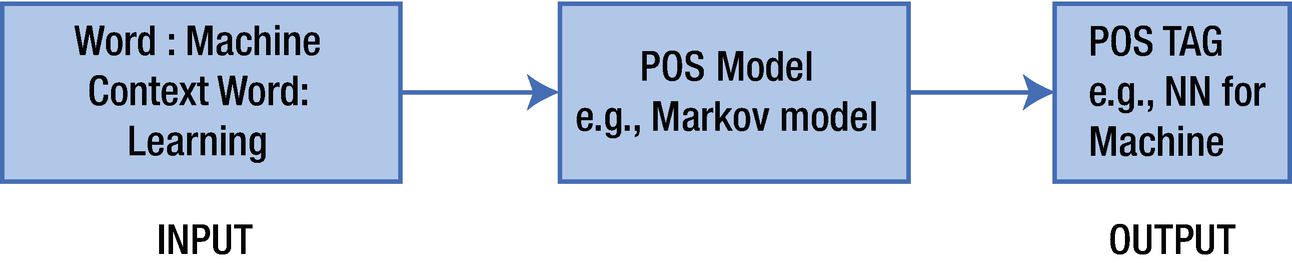
这些模型在目标语言的大量(数百万或数十亿)文学句子语料库上进行训练,其中每个单词及其词性标签都用作词性分类器的训练数据。前面提到的模型完全基于训练数据的统计数据,而不是实际解释。该模型试图根据句子与历史句子的句法相似性为每个单词找到 POS 标签 。例如,对于句子“机器学习算法用于各种应用程序,例如电子邮件过滤和计算机视觉”,POS 标签如下所示:
从这些结果中我们可以看出,有各种名词(即Machine、learning、variety、computer和vision)。因此我们可以得出结论,该句子可能在谈论机器和计算机。
词干和词形还原
有时 同一个词以不同的形式出现在多个句子中。词干提取可以定义为通过删除后缀将单词简化为词根或基本形式的过程。这里,缩减词可以是词典词或非词典词。例如,单词“machine”可以简化为词根形式“machin”。它没有考虑使用单词的上下文。这是我们例句的标记化单词的词干表示。
在这个结果中,一些词被表示为非字典词;例如,“machine”简化为“machin”,这是一个词干词而不是字典词。
词形还原可以定义为导出词的规范形式或词元的过程。它使用上下文来识别单词的词元,它必须是字典单词。然而,词干提取却不是这样。使用我们前面的例子,“机器”这个词将被转换成它的规范形式“机器”。以下是我们例句中标记化单词的词形还原表示。它使用单词标签作为上下文来导出单词的规范形式。
在这些结果中,一些词,如“过滤”,被简化为它们的规范形式,在这种情况下是“过滤”,而不是“过滤”,因为“过滤”这个词在句子中被用作动词。
应根据要求谨慎使用词形还原和词干提取。例如,如果您正在使用搜索引擎系统,那么应该首选词干提取,但如果您正在处理问题回答,其中推理很重要,那么词形还原应该优先于词干提取。
停止词的识别
文本片段包含重要词和填充词。例如,在我们的例句中,这些是填充词。
-
根据出现频率将词标记为停用词。它可能是最频繁的,也可能是最不频繁的。
-
如果词在语料库中的所有文档中都很常见,则将它们标记为停用词。
短语提取
-
机器:使用机械动力来执行某些任务的装置。
-
学习:通过学习、经验或被教导获得知识或技能。
从这两个词的定义可以很清楚地看出,我们的例句应该是在谈论某种机械装置和各种获取知识的媒介。但是,当这些词一起使用时(即“机器学习”),它指的是 AI 的一个分支,它涉及对计算机用于执行特定任务而无需明确编程的算法和统计模型进行科学研究。
为了提取短语,我们需要将多个单词组合在一起,或者识别短语。这里,短语可以分为两种类型,名词短语和动词短语。我们可以定义规则来从句子中提取短语。例如,要提取一个名词短语,我们可以定义这样一个规则:“一个句子中连续出现两次的名词应该被认为是一个名词短语。” 例如,短语“machine learning”在我们的例句中是一个名词短语。以类似的方式,我们可以定义更多的规则来从句子中提取名词短语和动词短语。
命名实体识别
实体被定义为对象或名词,例如人、组织或其他从文本中提供重要信息的对象。此信息可用作下游任务的特征。例如,Google、Microsoft 和 IBM 是Organization类型的实体。
NER 是一种信息提取技术,可根据训练模型将实体提取和分类。例如,英语中的一些基本类别是人名、组织、位置、日期、电子邮件地址、电话号码等。例如,在我们的示例句子中,“机器学习”和“计算机视觉”等短语是AI_Branch 类型的实体,它指的是 AI 的分支。
目前,IBM、谷歌、微软等人工智能领域的大型厂商都提供了经过训练的模型来从文本中提取命名实体。它们还使您能够构建自己的特定于您的应用程序和领域的 NER 模型。spaCy 等开源项目还提供了训练和使用您自己的自定义 NER 模型的能力。
共指消解
NLP 领域(尤其是英语)的主要挑战之一是代词的使用。在英语中,代词广泛用于指代先前上下文或句子中的名词。为了执行语义分析或识别这些句子之间的关系,系统应该以某种方式建立句子之间的依赖关系是非常重要的。
例如,考虑句子“它可以分为两种类型,即监督学习和非监督学习”,其中“它”在第一句和第二句中指的是机器学习。它可以通过在数据集中注释此类依赖关系以训练模型并在看不见的文本片段或文档上使用相同模型来提取此类关系来实现。
词袋
众所周知,计算机只处理数字数据;因此,要理解文本的含义,必须将其转换为数字形式。词袋是将文本转换为数字数据的方法之一。
-
Sentence A::机器学习 (ML) 是对算法和统计模型的科学研究,计算机系统使用这些算法和统计模型来执行特定任务,而不使用显式指令,而是依赖于模式和推理。
-
Sentence B:机器学习算法用于各种应用,例如电子邮件过滤和计算机视觉。
-
Sentence C : 可以分为两种,即Supervised Learning和Unsupervised Learning。

-
句子的向量表示长度随着词汇量的增加而增加。这需要对下游任务进行更高的计算。它还增加了句子的维度。
-
它无法根据文本中的上下文来识别具有相似含义的不同单词。
还有其他方法可以减少以向量形式表示句子的计算和内存要求。词嵌入是我们可以在低维空间中表示词同时保留词的语义的方法之一。稍后我们将详细了解词嵌入如何成为下游 NLP 任务的重大突破。
结论
本章讨论了 NLP 的基础知识,以及一些基本的 NLP 任务,例如标记化、词干提取等。在下一章中,我们将讨论 NLP 领域中的神经网络。




![[附源码]Python计算机毕业设计Django的网上点餐系统](https://img-blog.csdnimg.cn/6aeb15d5074d4ac796003b50782decc1.png)