大家好,我是易安!
之前我们讲过架构设计的一些原则,和架构设计的方法论,今天我们谈谈高性能数据库集群的设计与应用。
读写分离原理
读写分离的基本原理是将数据库读写操作分散到不同的节点上,下面是其基本架构图。
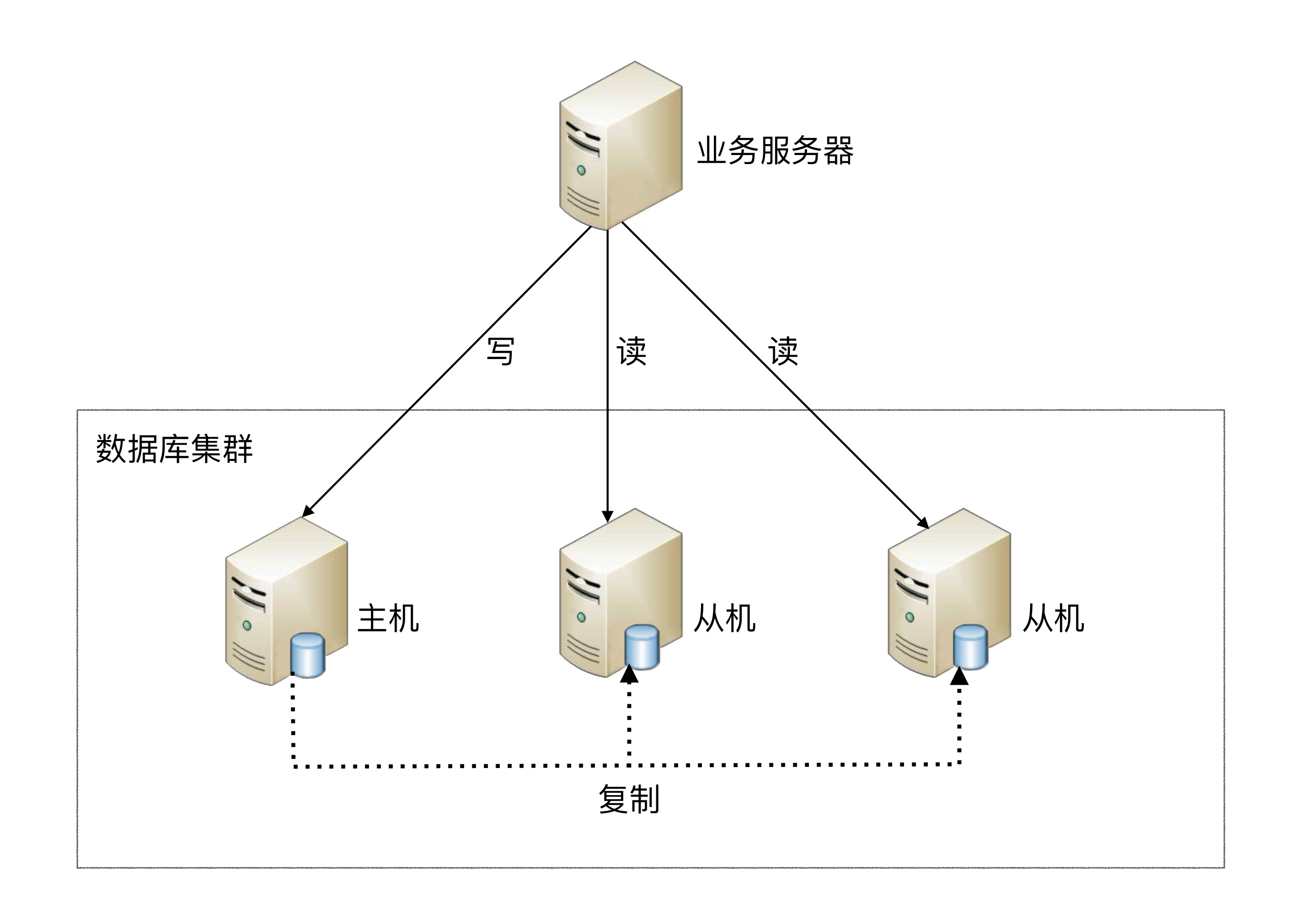
读写分离的基本实现是:
-
数据库服务器搭建主从集群,一主一从、一主多从都可以。
-
数据库主机负责读写操作,从机只负责读操作。
-
数据库主机通过复制将数据同步到从机,每台数据库服务器都存储了所有的业务数据。
-
业务服务器将写操作发给数据库主机,将读操作发给数据库从机。
需要注意的是,这里用的是“主从集群”,而不是“主备集群”。“从机”的“从”可以理解为“仆从”,仆从是要帮主人干活的,“从机”是需要提供读数据的功能的;而“备机”一般被认为仅仅提供备份功能,不提供访问功能。所以使用“主从”还是“主备”,是要看场景的,这两个词并不是完全等同的。
读写分离的实现逻辑并不复杂,但有两个细节点将引入设计复杂度: 主从复制延迟 和 分配机制。
复制延迟
以MySQL为例,主从复制延迟可能达到1秒,如果有大量数据同步,延迟1分钟也是有可能的。主从复制延迟会带来一个问题:如果业务服务器将数据写入到数据库主服务器后立刻(1秒内)进行读取,此时读操作访问的是从机,主机还没有将数据复制过来,到从机读取数据是读不到最新数据的,业务上就可能出现问题。例如,用户刚注册完后立刻登录,业务服务器会提示他“你还没有注册”,而用户明明刚才已经注册成功了。
解决主从复制延迟有几种常见的方法:
1.写操作后的读操作指定发给数据库主服务器
例如,注册账号完成后,登录时读取账号的读操作也发给数据库主服务器。这种方式和业务强绑定,对业务的侵入和影响较大,如果哪个新来的程序员不知道这样写代码,就会导致一个bug。
2.读从机失败后再读一次主机
这就是通常所说的“二次读取”,二次读取和业务无绑定,只需要对底层数据库访问的API进行封装即可,实现代价较小,不足之处在于如果有很多二次读取,将大大增加主机的读操作压力。例如,黑客暴力破解账号,会导致大量的二次读取操作,主机可能顶不住读操作的压力从而崩溃。
3.关键业务读写操作全部指向主机,非关键业务采用读写分离
例如,对于一个用户管理系统来说,注册+登录的业务读写操作全部访问主机,用户的介绍、爱好、等级等业务,可以采用读写分离,因为即使用户改了自己的自我介绍,在查询时却看到了自我介绍还是旧的,业务影响与不能登录相比就小很多,还可以忍受。
分配机制
将读写操作区分开来,然后访问不同的数据库服务器,一般有两种方式: 程序代码封装 和 中间件封装。
1.程序代码封装
程序代码封装指在代码中抽象一个数据访问层(所以有的文章也称这种方式为“中间层封装”),实现读写操作分离和数据库服务器连接的管理。例如,基于Hibernate进行简单封装,就可以实现读写分离,基本架构是:
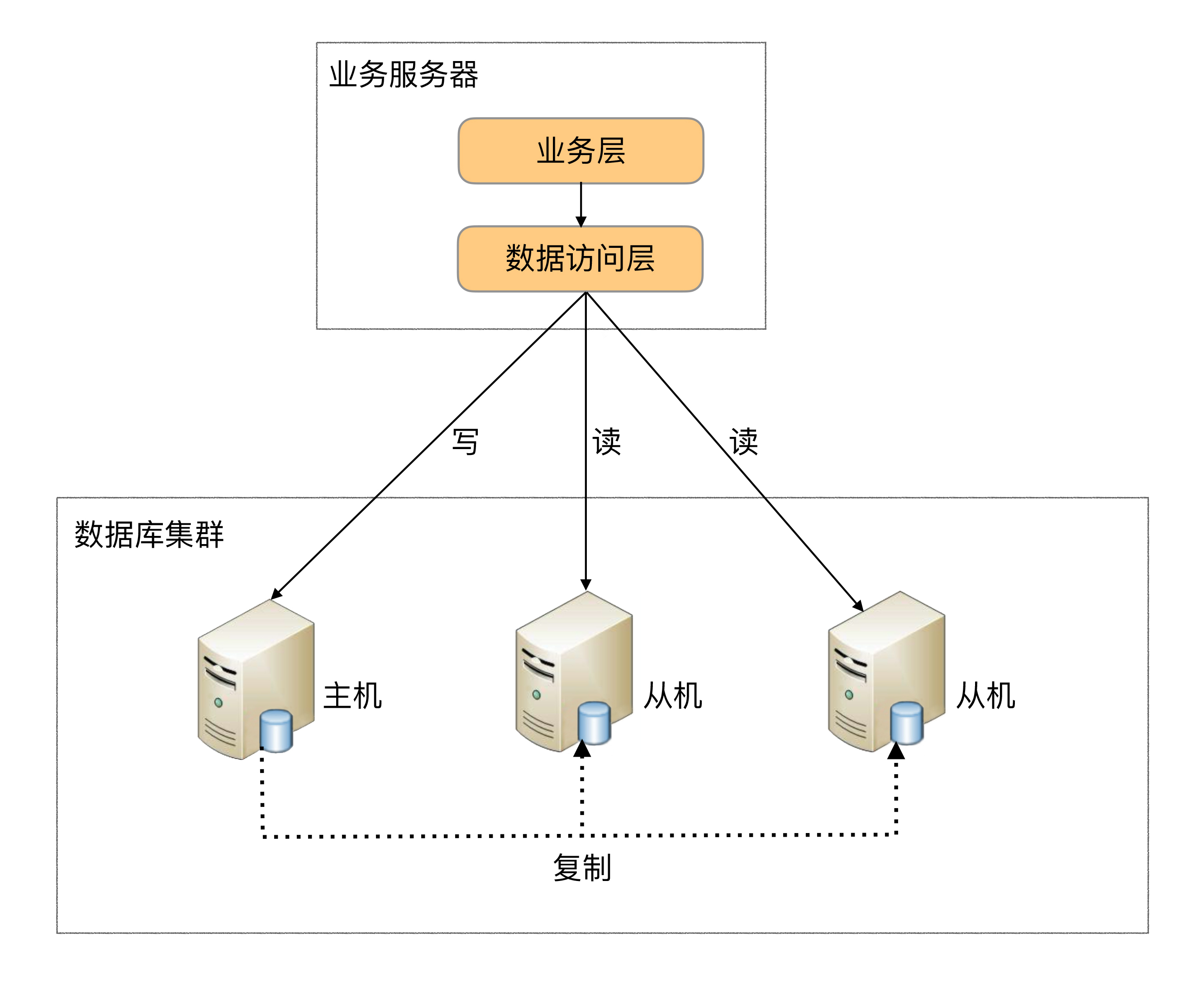
程序代码封装的方式具备几个特点:
-
实现简单,而且可以根据业务做较多定制化的功能。
-
每个编程语言都需要自己实现一次,无法通用,如果一个业务包含多个编程语言写的多个子系统,则重复开发的工作量比较大。
-
故障情况下,如果主从发生切换,则可能需要所有系统都修改配置并重启。
目前开源的实现方案中,淘宝的TDDL(Taobao Distributed Data Layer,外号:头都大了)是比较有名的。它是一个通用数据访问层,所有功能封装在jar包中提供给业务代码调用。其基本原理是一个基于集中式配置的 jdbc datasource实现,具有主备、读写分离、动态数据库配置等功能,基本架构是:
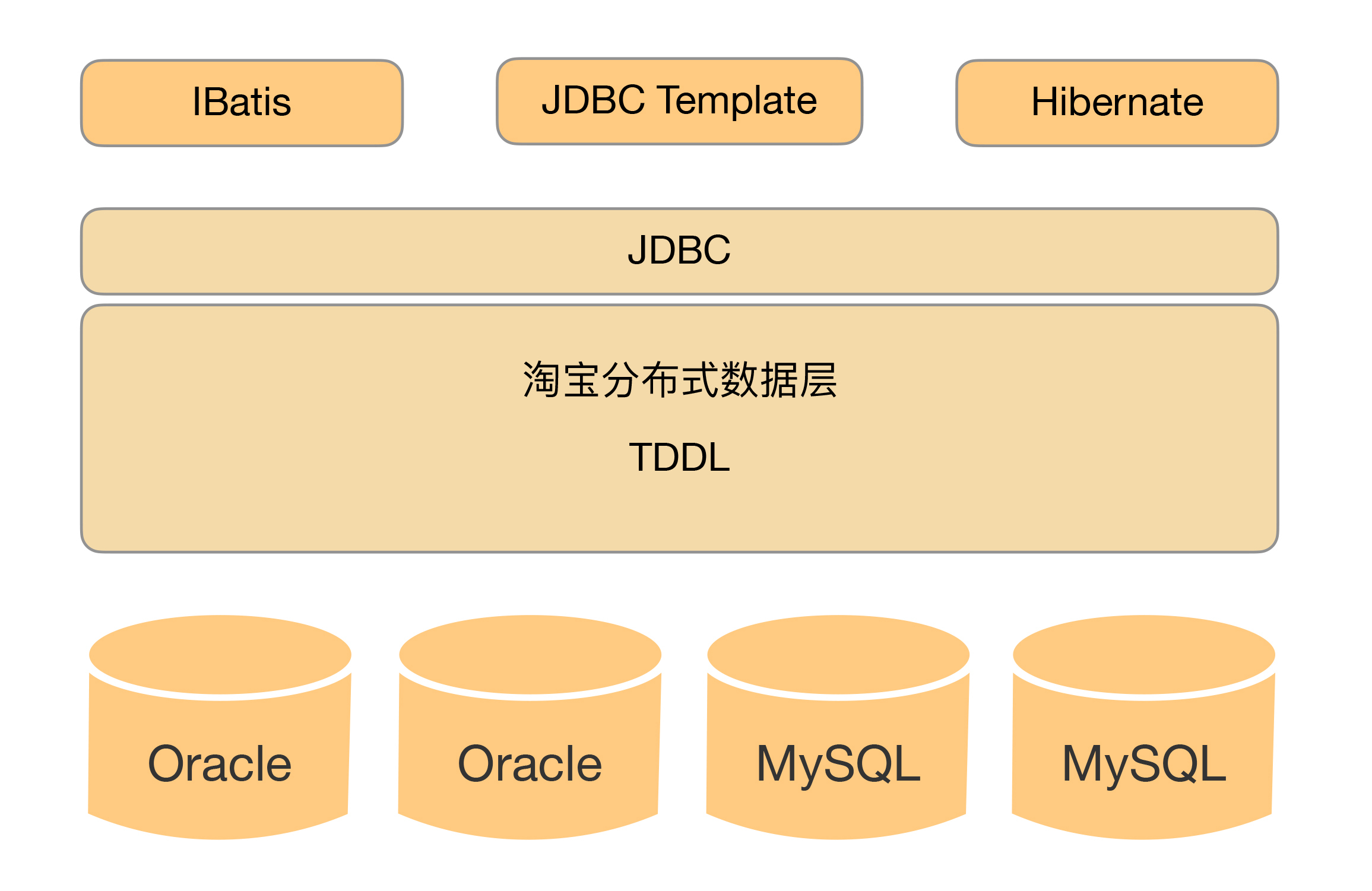
2.中间件封装
中间件封装指的是独立一套系统出来,实现读写操作分离和数据库服务器连接的管理。中间件对业务服务器提供SQL兼容的协议,业务服务器无须自己进行读写分离。对于业务服务器来说,访问中间件和访问数据库没有区别,事实上在业务服务器看来,中间件就是一个数据库服务器。其基本架构是:
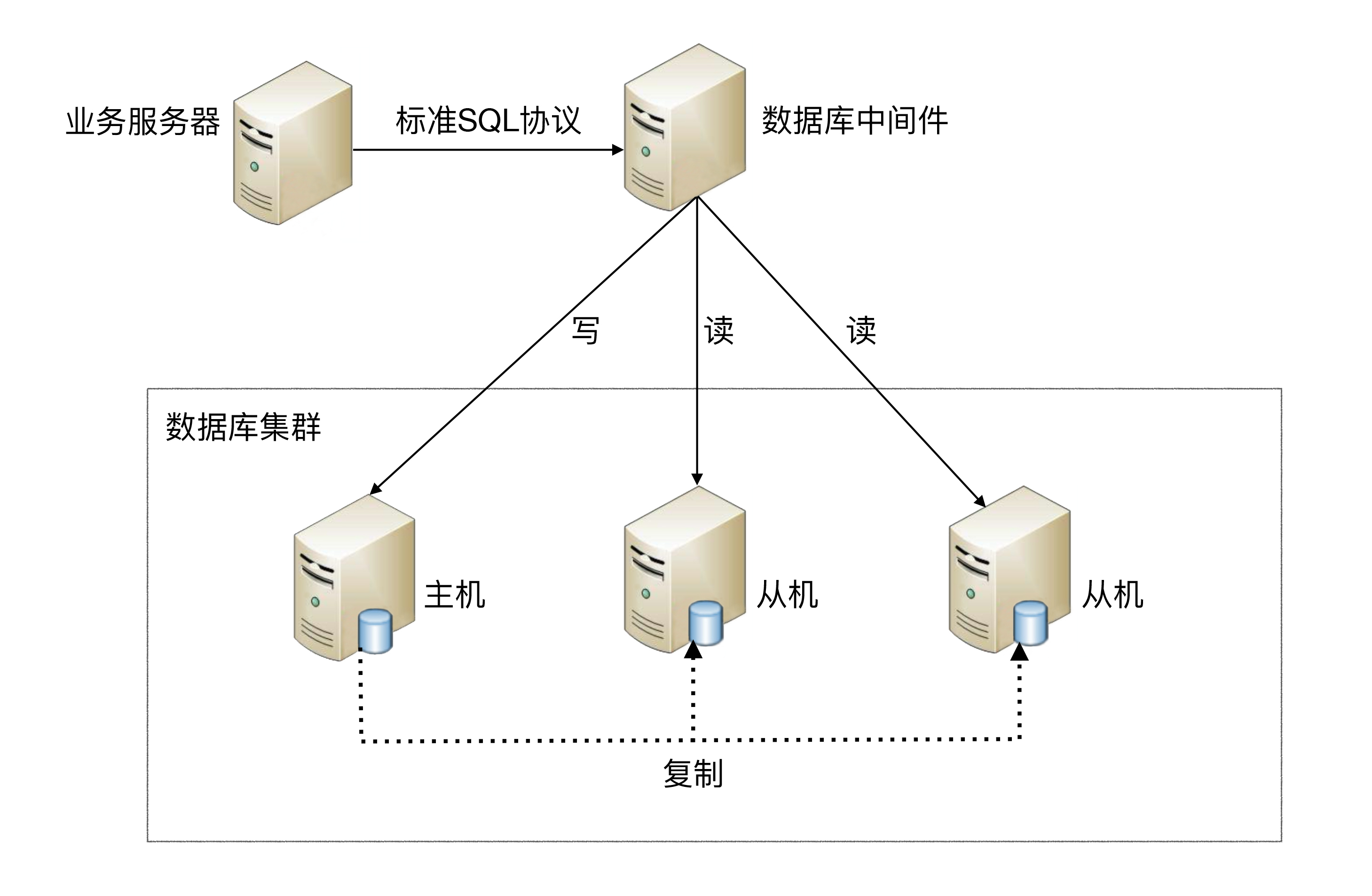
数据库中间件的方式具备的特点是:
-
能够支持多种编程语言,因为数据库中间件对业务服务器提供的是标准SQL接口。
-
数据库中间件要支持完整的SQL语法和数据库服务器的协议(例如,MySQL客户端和服务器的连接协议),实现比较复杂,细节特别多,很容易出现bug,需要较长的时间才能稳定。
-
数据库中间件自己不执行真正的读写操作,但所有的数据库操作请求都要经过中间件,中间件的性能要求也很高。
-
数据库主从切换对业务服务器无感知,数据库中间件可以探测数据库服务器的主从状态。例如,向某个测试表写入一条数据,成功的就是主机,失败的就是从机。
由于数据库中间件的复杂度要比程序代码封装高出一个数量级,一般情况下建议采用程序语言封装的方式,或者使用成熟的开源数据库中间件。如果是大公司,可以投入人力去实现数据库中间件,因为这个系统一旦做好,接入的业务系统越多,节省的程序开发投入就越多,价值也越大。
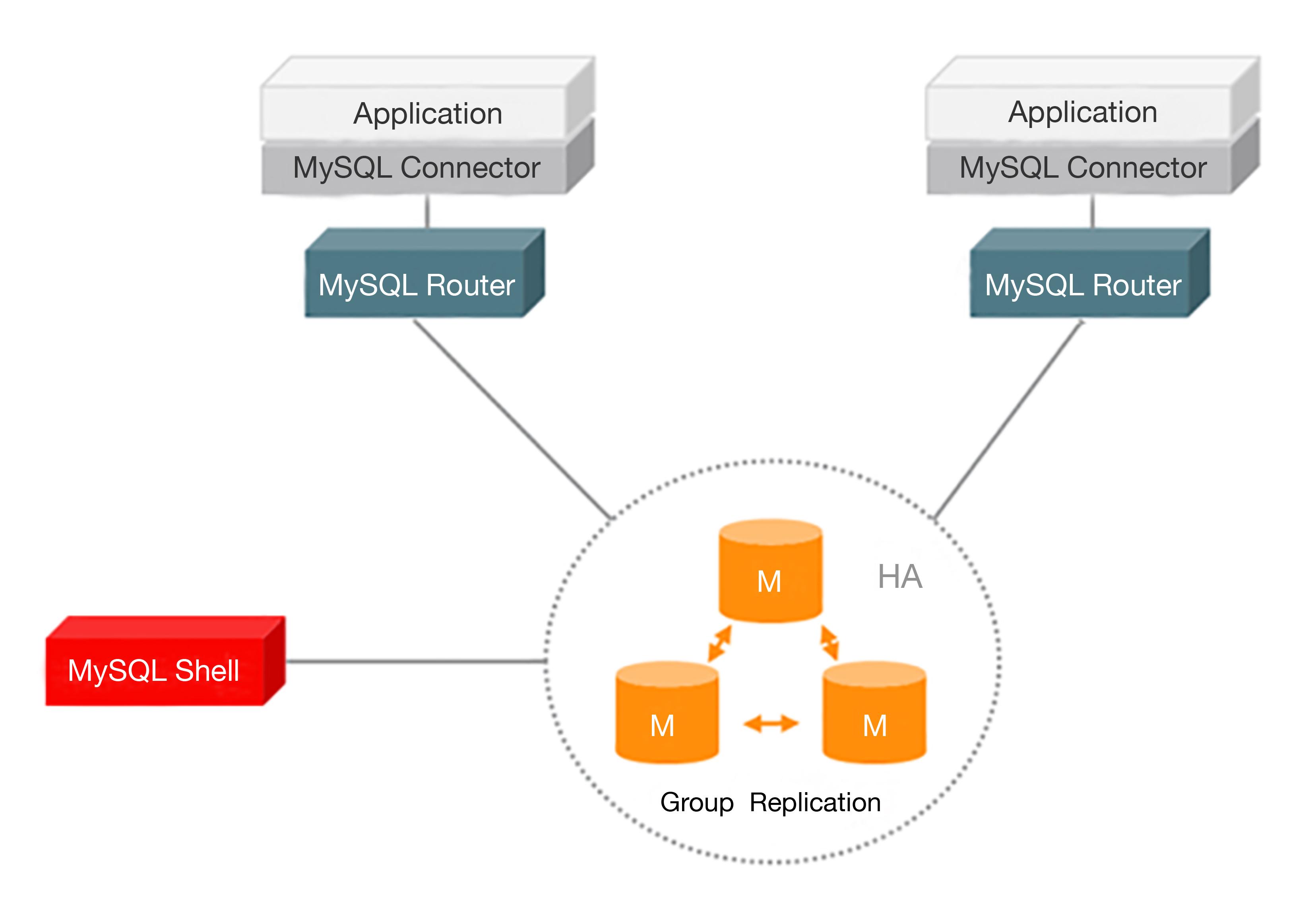
目前的开源数据库中间件方案中,MySQL官方先是提供了MySQL Proxy,但MySQL Proxy一直没有正式GA,现在MySQL官方推荐MySQL Router。MySQL Router的主要功能有读写分离、故障自动切换、负载均衡、连接池等,其基本架构如下:
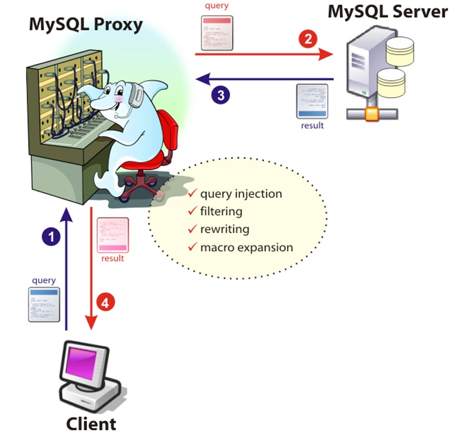
奇虎360公司也开源了自己的数据库中间件Atlas,Atlas是基于MySQL Proxy实现的,基本架构如下:
以下是官方介绍,更多内容你可以参考 这里。
Atlas是一个位于应用程序与MySQL之间中间件。在后端DB看来,Atlas相当于连接它的客户端,在前端应用看来,Atlas相当于一个DB。Atlas作为服务端与应用程序通信,它实现了MySQL的客户端和服务端协议,同时作为客户端与MySQL通信。它对应用程序屏蔽了DB的细节,同时为了降低MySQL负担,它还维护了连接池。
刚才我们讲了“读写分离”,读写分离分散了数据库读写操作的压力,但没有分散存储压力,当数据量达到千万甚至上亿条的时候,单台数据库服务器的存储能力会成为系统的瓶颈,主要体现在这几个方面:
-
数据量太大,读写的性能会下降,即使有索引,索引也会变得很大,性能同样会下降。
-
数据文件会变得很大,数据库备份和恢复需要耗费很长时间。
-
数据文件越大,极端情况下丢失数据的风险越高(例如,机房火灾导致数据库主备机都发生故障)。
基于上述原因,单个数据库服务器存储的数据量不能太大,需要控制在一定的范围内。为了满足业务数据存储的需求,就需要将存储分散到多台数据库服务器上。
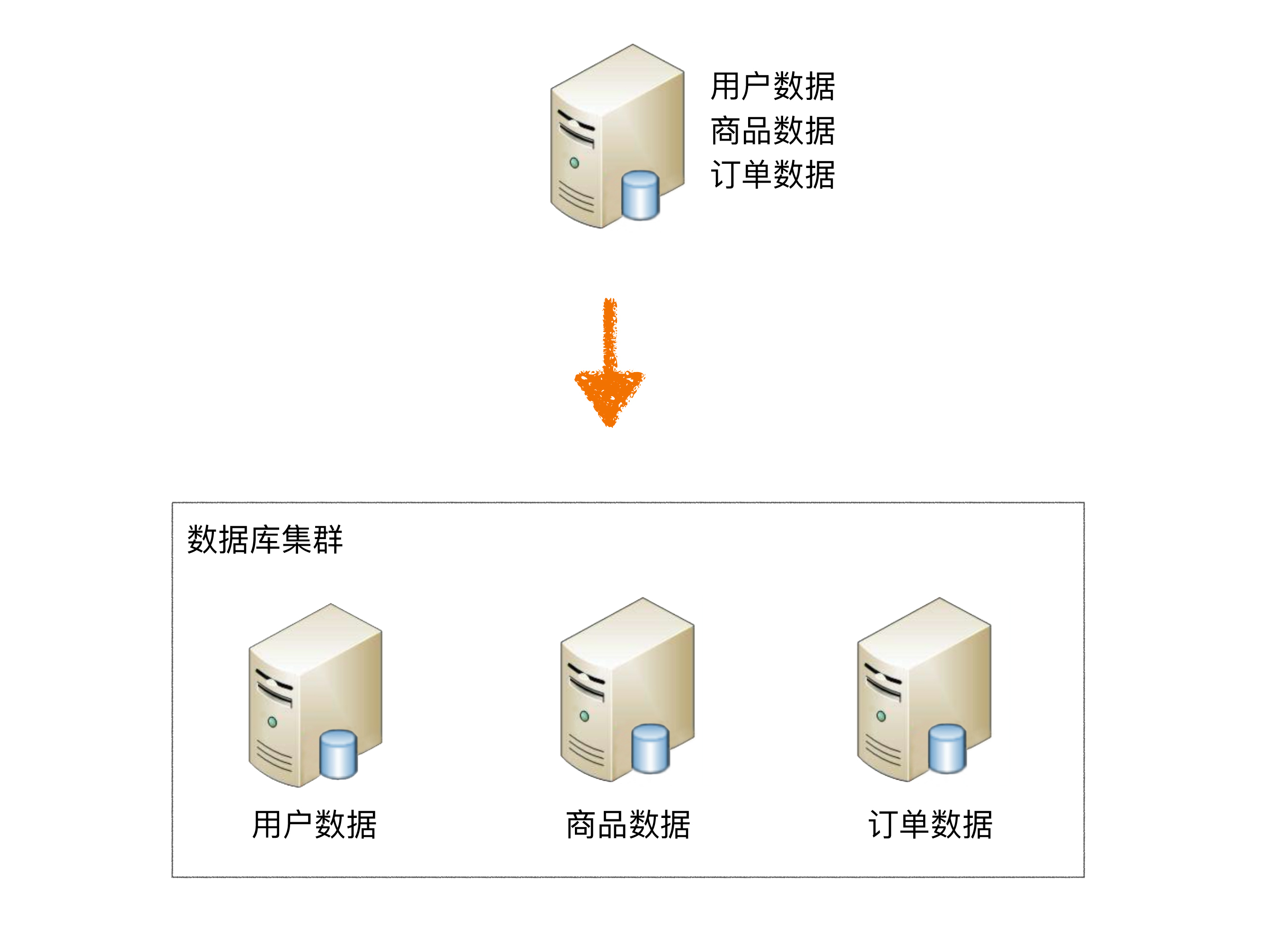
业务分库
业务分库指的是按照业务模块将数据分散到不同的数据库服务器。 例如,一个简单的电商网站,包括用户、商品、订单三个业务模块,我们可以将用户数据、商品数据、订单数据分开放到三台不同的数据库服务器上,而不是将所有数据都放在一台数据库服务器上。
虽然业务分库能够分散存储和访问压力,但同时也带来了新的问题,接下来我进行详细分析。
1.join操作问题
业务分库后,原本在同一个数据库中的表分散到不同数据库中,导致无法使用SQL的join查询。
例如:“查询购买了化妆品的用户中女性用户的列表”这个功能,虽然订单数据中有用户的ID信息,但是用户的性别数据在用户数据库中,如果在同一个库中,简单的join查询就能完成;但现在数据分散在两个不同的数据库中,无法做join查询,只能采取先从订单数据库中查询购买了化妆品的用户ID列表,然后再到用户数据库中查询这批用户ID中的女性用户列表,这样实现就比简单的join查询要复杂一些。
2.事务问题
原本在同一个数据库中不同的表可以在同一个事务中修改,业务分库后,表分散到不同的数据库中,无法通过事务统一修改。虽然数据库厂商提供了一些分布式事务的解决方案(例如,MySQL的XA),但性能实在太低,与高性能存储的目标是相违背的。
例如,用户下订单的时候需要扣商品库存,如果订单数据和商品数据在同一个数据库中,我们可以使用事务来保证扣减商品库存和生成订单的操作要么都成功要么都失败,但分库后就无法使用数据库事务了,需要业务程序自己来模拟实现事务的功能。例如,先扣商品库存,扣成功后生成订单,如果因为订单数据库异常导致生成订单失败,业务程序又需要将商品库存加上;而如果因为业务程序自己异常导致生成订单失败,则商品库存就无法恢复了,需要人工通过日志等方式来手工修复库存异常。
3.成本问题
业务分库同时也带来了成本的代价,本来1台服务器搞定的事情,现在要3台,如果考虑备份,那就是2台变成了6台。
基于上述原因,对于小公司初创业务,并不建议一开始就这样拆分,主要有几个原因:
-
初创业务存在很大的不确定性,业务不一定能发展起来,业务开始的时候并没有真正的存储和访问压力,业务分库并不能为业务带来价值。
-
业务分库后,表之间的join查询、数据库事务无法简单实现了。
-
业务分库后,因为不同的数据要读写不同的数据库,代码中需要增加根据数据类型映射到不同数据库的逻辑,增加了工作量。而业务初创期间最重要的是快速实现、快速验证,业务分库会拖慢业务节奏。
有的架构师可能会想:如果业务真的发展很快,岂不是很快就又要进行业务分库了?那为何不一开始就设计好呢?
首先,这里的“如果”事实上发生的概率比较低,做10个业务有1个业务能活下去就很不错了,更何况快速发展,和中彩票的概率差不多。如果我们每个业务上来就按照淘宝、微信的规模去做架构设计,不但会累死自己,还会害死业务。
其次,如果业务真的发展很快,后面进行业务分库也不迟。因为业务发展好,相应的资源投入就会加大,可以投入更多的人和更多的钱,那业务分库带来的代码和业务复杂的问题就可以通过增加人来解决,成本问题也可以通过增加资金来解决。
再者,单台数据库服务器的性能其实也没有想象的那么弱,一般来说,单台数据库服务器能够支撑10万用户量量级的业务,初创业务从0发展到10万级用户,并不是想象得那么快。
而对于业界成熟的大公司来说,由于已经有了业务分库的成熟解决方案,并且即使是尝试性的新业务,用户规模也是海量的, 这与前面提到的初创业务的小公司有本质区别,因此最好在业务开始设计时就考虑业务分库。例如,在淘宝上做一个新的业务,由于已经有成熟的数据库解决方案,用户量也很大,需要在一开始就设计业务分库甚至接下来介绍的分表方案。
分表
将不同业务数据分散存储到不同的数据库服务器,能够支撑百万甚至千万用户规模的业务,但如果业务继续发展,同一业务的单表数据也会达到单台数据库服务器的处理瓶颈。例如,淘宝的几亿用户数据,如果全部存放在一台数据库服务器的一张表中,肯定是无法满足性能要求的,此时就需要对单表数据进行拆分。
单表数据拆分有两种方式: 垂直分表 和 水平分表。示意图如下:
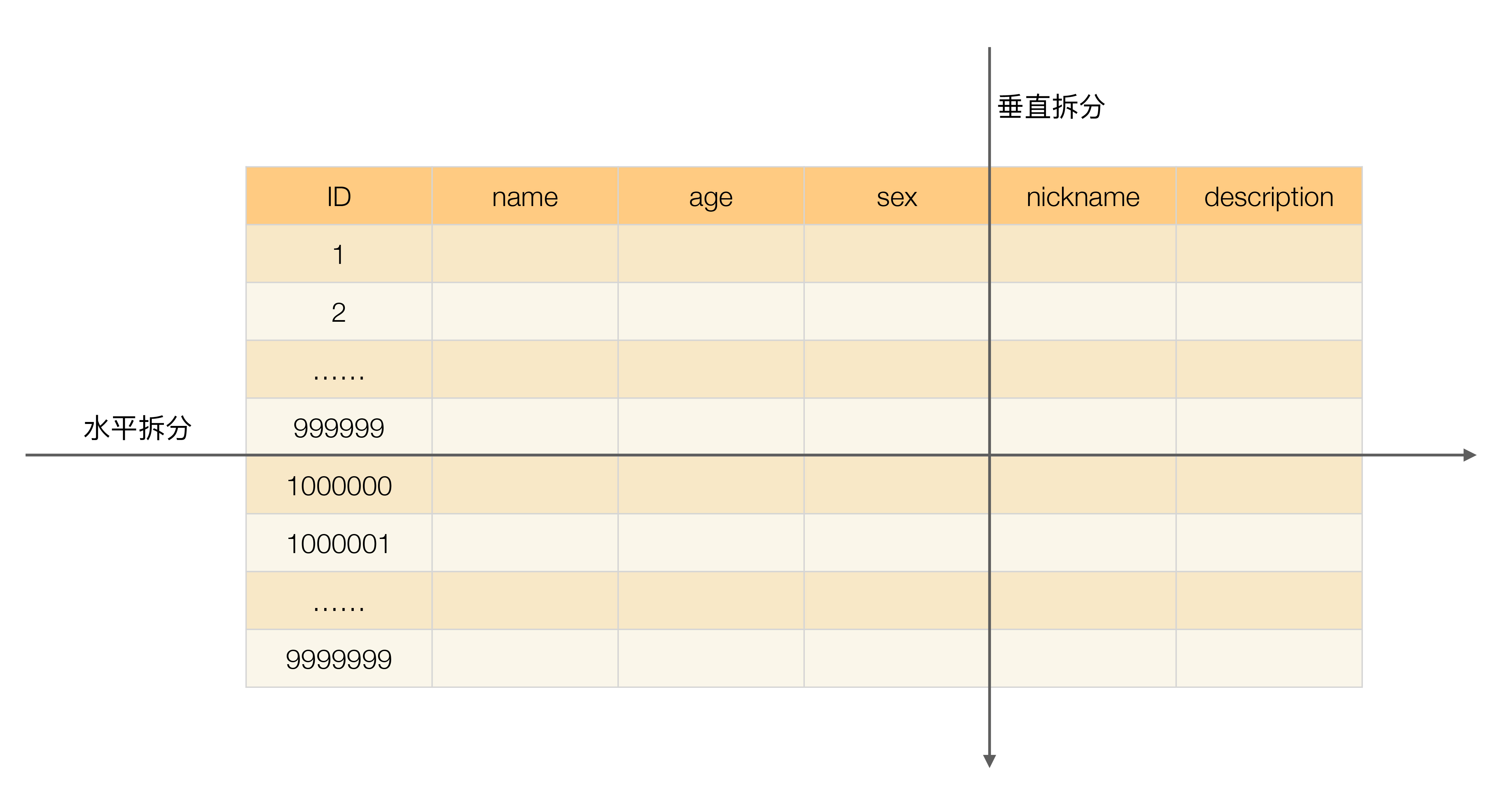
为了形象地理解垂直拆分和水平拆分的区别,可以想象你手里拿着一把刀,面对一个蛋糕切一刀:
-
从上往下切就是垂直切分,因为刀的运行轨迹与蛋糕是垂直的,这样可以把蛋糕切成高度相等(面积可以相等也可以不相等)的两部分,对应到表的切分就是表记录数相同但包含不同的列。例如,示意图中的垂直切分,会把表切分为两个表,一个表包含ID、name、age、sex列,另外一个表包含ID、nickname、description列。
-
从左往右切就是水平切分,因为刀的运行轨迹与蛋糕是平行的,这样可以把蛋糕切成面积相等(高度可以相等也可以不相等)的两部分,对应到表的切分就是表的列相同但包含不同的行数据。例如,示意图中的水平切分,会把表分为两个表,两个表都包含ID、name、age、sex、nickname、description列,但是一个表包含的是ID从1到999999的行数据,另一个表包含的是ID从1000000到9999999的行数据。
上面这个示例比较简单,只考虑了一次切分的情况,实际架构设计过程中并不局限切分的次数,可以切两次,也可以切很多次,就像切蛋糕一样,可以切很多刀。
单表进行切分后,是否要将切分后的多个表分散在不同的数据库服务器中,可以根据实际的切分效果来确定,并不强制要求单表切分为多表后一定要分散到不同数据库中。原因在于单表切分为多表后,新的表即使在同一个数据库服务器中,也可能带来可观的性能提升,如果性能能够满足业务要求,是可以不拆分到多台数据库服务器的,毕竟我们在上面业务分库的内容看到业务分库也会引入很多复杂性的问题;如果单表拆分为多表后,单台服务器依然无法满足性能要求,那就不得不再次进行业务分库的设计了。
分表能够有效地分散存储压力和带来性能提升,但和分库一样,也会引入各种复杂性。
1.垂直分表
垂直分表适合将表中某些不常用且占了大量空间的列拆分出去。例如,前面示意图中的nickname和description字段,假设我们是一个婚恋网站,用户在筛选其他用户的时候,主要是用age和sex两个字段进行查询,而nickname和description两个字段主要用于展示,一般不会在业务查询中用到。description本身又比较长,因此我们可以将这两个字段独立到另外一张表中,这样在查询age和sex时,就能带来一定的性能提升。
垂直分表引入的复杂性主要体现在表操作的数量要增加。例如,原来只要一次查询就可以获取name、age、sex、nickname、description,现在需要两次查询,一次查询获取name、age、sex,另外一次查询获取nickname、description。
不过相比接下来要讲的水平分表,这个复杂性就是小巫见大巫了。
2.水平分表
水平分表适合表行数特别大的表,有的公司要求单表行数超过5000万就必须进行分表,这个数字可以作为参考,但并不是绝对标准,关键还是要看表的访问性能。对于一些比较复杂的表,可能超过1000万就要分表了;而对于一些简单的表,即使存储数据超过1亿行,也可以不分表。但不管怎样,当看到表的数据量达到千万级别时,作为架构师就要警觉起来,因为这很可能是架构的性能瓶颈或者隐患。
水平分表相比垂直分表,会引入更多的复杂性,主要表现在下面几个方面:
-
路由
水平分表后,某条数据具体属于哪个切分后的子表,需要增加路由算法进行计算,这个算法会引入一定的复杂性。
常见的路由算法有:
范围路由: 选取有序的数据列(例如,整形、时间戳等)作为路由的条件,不同分段分散到不同的数据库表中。以最常见的用户ID为例,路由算法可以按照1000000的范围大小进行分段,1 ~ 999999放到数据库1的表中,1000000 ~ 1999999放到数据库2的表中,以此类推。
范围路由设计的复杂点主要体现在分段大小的选取上,分段太小会导致切分后子表数量过多,增加维护复杂度;分段太大可能会导致单表依然存在性能问题,一般建议分段大小在100万至2000万之间,具体需要根据业务选取合适的分段大小。
范围路由的优点是可以随着数据的增加平滑地扩充新的表。例如,现在的用户是100万,如果增加到1000万,只需要增加新的表就可以了,原有的数据不需要动。
范围路由的一个比较隐含的缺点是分布不均匀,假如按照1000万来进行分表,有可能某个分段实际存储的数据量只有1000条,而另外一个分段实际存储的数据量有900万条。
Hash路由: 选取某个列(或者某几个列组合也可以)的值进行Hash运算,然后根据Hash结果分散到不同的数据库表中。同样以用户ID为例,假如我们一开始就规划了10个数据库表,路由算法可以简单地用user_id % 10的值来表示数据所属的数据库表编号,ID为985的用户放到编号为5的子表中,ID为10086的用户放到编号为6的字表中。
Hash路由设计的复杂点主要体现在初始表数量的选取上,表数量太多维护比较麻烦,表数量太少又可能导致单表性能存在问题。而用了Hash路由后,增加子表数量是非常麻烦的,所有数据都要重分布。
Hash路由的优缺点和范围路由基本相反,Hash路由的优点是表分布比较均匀,缺点是扩充新的表很麻烦,所有数据都要重分布。
配置路由: 配置路由就是路由表,用一张独立的表来记录路由信息。同样以用户ID为例,我们新增一张user_router表,这个表包含user_id和table_id两列,根据user_id就可以查询对应的table_id。
配置路由设计简单,使用起来非常灵活,尤其是在扩充表的时候,只需要迁移指定的数据,然后修改路由表就可以了。
配置路由的缺点就是必须多查询一次,会影响整体性能;而且路由表本身如果太大(例如,几亿条数据),性能同样可能成为瓶颈,如果我们再次将路由表分库分表,则又面临一个死循环式的路由算法选择问题。
-
join操作
水平分表后,数据分散在多个表中,如果需要与其他表进行join查询,需要在业务代码或者数据库中间件中进行多次join查询,然后将结果合并。
-
count()操作
水平分表后,虽然物理上数据分散到多个表中,但某些业务逻辑上还是会将这些表当作一个表来处理。例如,获取记录总数用于分页或者展示,水平分表前用一个count()就能完成的操作,在分表后就没那么简单了。常见的处理方式有下面两种:
count()相加: 具体做法是在业务代码或者数据库中间件中对每个表进行count()操作,然后将结果相加。这种方式实现简单,缺点就是性能比较低。例如,水平分表后切分为20张表,则要进行20次count(*)操作,如果串行的话,可能需要几秒钟才能得到结果。
记录数表: 具体做法是新建一张表,假如表名为“记录数表”,包含table_name、row_count两个字段,每次插入或者删除子表数据成功后,都更新“记录数表”。
这种方式获取表记录数的性能要大大优于count()相加的方式,因为只需要一次简单查询就可以获取数据。缺点是复杂度增加不少,对子表的操作要同步操作“记录数表”,如果有一个业务逻辑遗漏了,数据就会不一致;且针对“记录数表”的操作和针对子表的操作无法放在同一事务中进行处理,异常的情况下会出现操作子表成功了而操作记录数表失败,同样会导致数据不一致。
此外,记录数表的方式也增加了数据库的写压力,因为每次针对子表的insert和delete操作都要update记录数表,所以对于一些不要求记录数实时保持精确的业务,也可以通过后台定时更新记录数表。定时更新实际上就是“count()相加”和“记录数表”的结合,即定时通过count()相加计算表的记录数,然后更新记录数表中的数据。
-
order by操作
水平分表后,数据分散到多个子表中,排序操作无法在数据库中完成,只能由业务代码或者数据库中间件分别查询每个子表中的数据,然后汇总进行排序。
实现方法
和数据库读写分离类似,分库分表具体的实现方式也是“程序代码封装”和“中间件封装”,但实现会更复杂。读写分离实现时只要识别SQL操作是读操作还是写操作,通过简单的判断SELECT、UPDATE、INSERT、DELETE几个关键字就可以做到,而分库分表的实现除了要判断操作类型外,还要判断SQL中具体需要操作的表、操作函数(例如count函数)、order by、group by操作等,然后再根据不同的操作进行不同的处理。例如order by操作,需要先从多个库查询到各个库的数据,然后再重新order by才能得到最终的结果。
高性能No SQL
关系数据库经过几十年的发展后已经非常成熟,强大的SQL功能和ACID的属性,使得关系数据库广泛应用于各式各样的系统中,但这并不意味着关系数据库是完美的,关系数据库存在如下缺点。
-
关系数据库存储的是行记录,无法存储数据结构
以微博的关注关系为例,“我关注的人”是一个用户ID列表,使用关系数据库存储只能将列表拆成多行,然后再查询出来组装,无法直接存储一个列表。
-
关系数据库的schema扩展很不方便
关系数据库的表结构schema是强约束,操作不存在的列会报错,业务变化时扩充列也比较麻烦,需要执行DDL(data definition language,如CREATE、ALTER、DROP等)语句修改,而且修改时可能会长时间锁表(例如,MySQL可能将表锁住1个小时)。
-
关系数据库在大数据场景下I/O较高
如果对一些大量数据的表进行统计之类的运算,关系数据库的I/O会很高,因为即使只针对其中某一列进行运算,关系数据库也会将整行数据从存储设备读入内存。
-
关系数据库的全文搜索功能比较弱
关系数据库的全文搜索只能使用like进行整表扫描匹配,性能非常低,在互联网这种搜索复杂的场景下无法满足业务要求。
针对上述问题,分别诞生了不同的NoSQL解决方案,这些方案与关系数据库相比,在某些应用场景下表现更好。但世上没有免费的午餐,NoSQL方案带来的优势,本质上是牺牲ACID中的某个或者某几个特性, 因此我们不能盲目地迷信NoSQL是银弹,而应该将NoSQL作为SQL的一个有力补充,NoSQL != No SQL,而是NoSQL = Not Only SQL。
常见的NoSQL方案分为4类。
-
K-V存储:解决关系数据库无法存储数据结构的问题,以Redis为代表。
-
文档数据库:解决关系数据库强schema约束的问题,以MongoDB为代表。
-
列式数据库:解决关系数据库大数据场景下的I/O问题,以HBase为代表。
-
全文搜索引擎:解决关系数据库的全文搜索性能问题,以Elasticsearch为代表。
下面,我介绍一下各种高性能NoSQL方案的典型特征和应用场景。
K-V存储
K-V存储的全称是Key-Value存储,其中Key是数据的标识,和关系数据库中的主键含义一样,Value就是具体的数据。
Redis是K-V存储的典型代表,它是一款开源(基于BSD许可)的高性能K-V缓存和存储系统。Redis的Value是具体的数据结构,包括string、hash、list、set、sorted set、bitmap和hyperloglog,所以常常被称为数据结构服务器。
以List数据结构为例,Redis提供了下面这些典型的操作(更多请参考链接: http://redis.cn/commands.html#list):
-
LPOP key从队列的左边出队一个元素。
-
LINDEX key index获取一个元素,通过其索引列表。
-
LLEN key获得队列(List)的长度。
-
RPOP key从队列的右边出队一个元素。
以上这些功能,如果用关系数据库来实现,就会变得很复杂。例如,LPOP操作是移除并返回 key对应的list的第一个元素。如果用关系数据库来存储,为了达到同样目的,需要进行下面的操作:
-
每条数据除了数据编号(例如,行ID),还要有位置编号,否则没有办法判断哪条数据是第一条。注意这里不能用行ID作为位置编号,因为我们会往列表头部插入数据。
-
查询出第一条数据。
-
删除第一条数据。
-
更新从第二条开始的所有数据的位置编号。
可以看出关系数据库的实现很麻烦,而且需要进行多次SQL操作,性能很低。
Redis的缺点主要体现在并不支持完整的ACID事务,Redis虽然提供事务功能,但Redis的事务和关系数据库的事务不可同日而语,Redis的事务只能保证隔离性和一致性(I和C),无法保证原子性和持久性(A和D)。
虽然Redis并没有严格遵循ACID原则,但实际上大部分业务也不需要严格遵循ACID原则。以上面的微博关注操作为例,即使系统没有将A加入B的粉丝列表,其实业务影响也非常小,因此我们在设计方案时,需要根据业务特性和要求来确定是否可以用Redis,而不能因为Redis不遵循ACID原则就直接放弃。
文档数据库
为了解决关系数据库schema带来的问题,文档数据库应运而生。文档数据库最大的特点就是no-schema,可以存储和读取任意的数据。目前绝大部分文档数据库存储的数据格式是JSON(或者BSON),因为JSON数据是自描述的,无须在使用前定义字段,读取一个JSON中不存在的字段也不会导致SQL那样的语法错误。
文档数据库的no-schema特性,给业务开发带来了几个明显的优势。
1.新增字段简单
业务上增加新的字段,无须再像关系数据库一样要先执行DDL语句修改表结构,程序代码直接读写即可。
2.历史数据不会出错
对于历史数据,即使没有新增的字段,也不会导致错误,只会返回空值,此时代码进行兼容处理即可。
3.可以很容易存储复杂数据
JSON是一种强大的描述语言,能够描述复杂的数据结构。例如,我们设计一个用户管理系统,用户的信息有ID、姓名、性别、爱好、邮箱、地址、学历信息。其中爱好是列表(因为可以有多个爱好);地址是一个结构,包括省市区楼盘地址;学历包括学校、专业、入学毕业年份信息等。如果我们用关系数据库来存储,需要设计多张表,包括基本信息(列:ID、姓名、性别、邮箱)、爱好(列:ID、爱好)、地址(列:省、市、区、详细地址)、学历(列:入学时间、毕业时间、学校名称、专业),而使用文档数据库,一个JSON就可以全部描述。
{
"id": 10000,
"name": "James",
"sex": "male",
"hobbies": [
"football",
"playing",
"singing"
],
"email": "user@google.com",
"address": {
"province": "GuangDong",
"city": "GuangZhou",
"district": "Tianhe",
"detail": "PingYun Road 163"
},
"education": [
{
"begin": "2000-09-01",
"end": "2004-07-01",
"school": "UESTC",
"major": "Computer Science & Technology"
},
{
"begin": "2004-09-01",
"end": "2007-07-01",
"school": "SCUT",
"major": "Computer Science & Technology"
}
]
}
通过这个样例我们看到,使用JSON来描述数据,比使用关系型数据库表来描述数据方便和容易得多,而且更加容易理解。
文档数据库的这个特点,特别适合电商和游戏这类的业务场景。以电商为例,不同商品的属性差异很大。例如,冰箱的属性和笔记本电脑的属性差异非常大,如下图所示。

即使是同类商品也有不同的属性。例如,LCD和LED显示器,两者有不同的参数指标。这种业务场景如果使用关系数据库来存储数据,就会很麻烦,而使用文档数据库,会简单、方便许多,扩展新的属性也更加容易。
文档数据库no-schema的特性带来的这些优势也是有代价的,最主要的代价就是不支持事务。例如,使用MongoDB来存储商品库存,系统创建订单的时候首先需要减扣库存,然后再创建订单。这是一个事务操作,用关系数据库来实现就很简单,但如果用MongoDB来实现,就无法做到事务性。异常情况下可能出现库存被扣减了,但订单没有创建的情况。因此某些对事务要求严格的业务场景是不能使用文档数据库的。
文档数据库另外一个缺点就是无法实现关系数据库的join操作。例如,我们有一个用户信息表和一个订单表,订单表中有买家用户id。如果要查询“购买了苹果笔记本用户中的女性用户”,用关系数据库来实现,一个简单的join操作就搞定了;而用文档数据库是无法进行join查询的,需要查两次:一次查询订单表中购买了苹果笔记本的用户,然后再查询这些用户哪些是女性用户。
列式数据库
顾名思义,列式数据库就是按照列来存储数据的数据库,与之对应的传统关系数据库被称为“行式数据库”,因为关系数据库是按照行来存储数据的。
关系数据库按照行式来存储数据,主要有以下几个优势:
-
业务同时读取多个列时效率高,因为这些列都是按行存储在一起的,一次磁盘操作就能够把一行数据中的各个列都读取到内存中。
-
能够一次性完成对一行中的多个列的写操作,保证了针对行数据写操作的原子性和一致性;否则如果采用列存储,可能会出现某次写操作,有的列成功了,有的列失败了,导致数据不一致。
我们可以看到,行式存储的优势是在特定的业务场景下才能体现,如果不存在这样的业务场景,那么行式存储的优势也将不复存在,甚至成为劣势,典型的场景就是海量数据进行统计。例如,计算某个城市体重超重的人员数据,实际上只需要读取每个人的体重这一列并进行统计即可,而行式存储即使最终只使用一列,也会将所有行数据都读取出来。如果单行用户信息有1KB,其中体重只有4个字节,行式存储还是会将整行1KB数据全部读取到内存中,这是明显的浪费。而如果采用列式存储,每个用户只需要读取4字节的体重数据即可,I/O将大大减少。
除了节省I/O,列式存储还具备更高的存储压缩比,能够节省更多的存储空间。普通的行式数据库一般压缩率在3:1到5:1左右,而列式数据库的压缩率一般在8:1到30:1左右,因为单个列的数据相似度相比行来说更高,能够达到更高的压缩率。
同样,如果场景发生变化,列式存储的优势又会变成劣势。典型的场景是需要频繁地更新多个列。因为列式存储将不同列存储在磁盘上不连续的空间,导致更新多个列时磁盘是随机写操作;而行式存储时同一行多个列都存储在连续的空间,一次磁盘写操作就可以完成,列式存储的随机写效率要远远低于行式存储的写效率。此外,列式存储高压缩率在更新场景下也会成为劣势,因为更新时需要将存储数据解压后更新,然后再压缩,最后写入磁盘。
基于上述列式存储的优缺点,一般将列式存储应用在离线的大数据分析和统计场景中,因为这种场景主要是针对部分列单列进行操作,且数据写入后就无须再更新删除。
全文搜索引擎
传统的关系型数据库通过索引来达到快速查询的目的,但是在全文搜索的业务场景下,索引也无能为力,主要体现在:
-
全文搜索的条件可以随意排列组合,如果通过索引来满足,则索引的数量会非常多。
-
全文搜索的模糊匹配方式,索引无法满足,只能用like查询,而like查询是整表扫描,效率非常低。
我举一个具体的例子来看看关系型数据库为何无法满足全文搜索的要求。假设我们做一个婚恋网站,其主要目的是帮助程序员找朋友,但模式与传统婚恋网站不同,是“程序员发布自己的信息,用户来搜索程序员”。程序员的信息表设计如下:

我们来看一下这个简单业务的搜索场景:
-
美女1:听说PHP是世界上最好的语言,那么PHP的程序员肯定是钱最多的,而且我妈一定要我找一个上海的。
美女1的搜索条件是“性别 + PHP + 上海”,其中“PHP”要用模糊匹配查询“语言”列,“上海”要查询“地点”列,如果用索引支撑,则需要建立“地点”这个索引。
-
美女2:我好崇拜这些技术哥哥啊,要是能找一个鹅厂技术哥哥陪我旅游就更好了。
美女2的搜索条件是“性别 + 鹅厂 + 旅游”,其中“旅游”要用模糊匹配查询“爱好”列,“鹅厂”需要查询“单位”列,如果要用索引支撑,则需要建立“单位”索引。
-
美女3:我是一个“女程序员”,想在北京找一个猫厂的Java技术专家。
美女3的搜索条件是“性别 + 猫厂 + 北京 + Java + 技术专家”,其中“猫厂 + 北京”可以通过索引来查询,但“Java”“技术专家”都只能通过模糊匹配来查询。
-
帅哥4:程序员妹子有没有漂亮的呢?试试看看。
帅哥4的搜索条件是“性别 + 美丽 + 美女”,只能通过模糊匹配搜索“自我介绍”列。
以上只是简单举个例子,实际上搜索条件是无法列举完全的,各种排列组合非常多,通过这个简单的样例我们就可以看出关系数据库在支撑全文搜索时的不足。
1.全文搜索基本原理
全文搜索引擎的技术原理被称为“倒排索引”(Inverted index),也常被称为反向索引、置入档案或反向档案,是一种索引方法,其基本原理是建立单词到文档的索引。之所以被称为“倒排”索引,是和“正排“索引相对的,“正排索引”的基本原理是建立文档到单词的索引。我们通过一个简单的样例来说明这两种索引的差异。
假设我们有一个技术文章的网站,里面收集了各种技术文章,用户可以在网站浏览或者搜索文章。
正排索引示例:
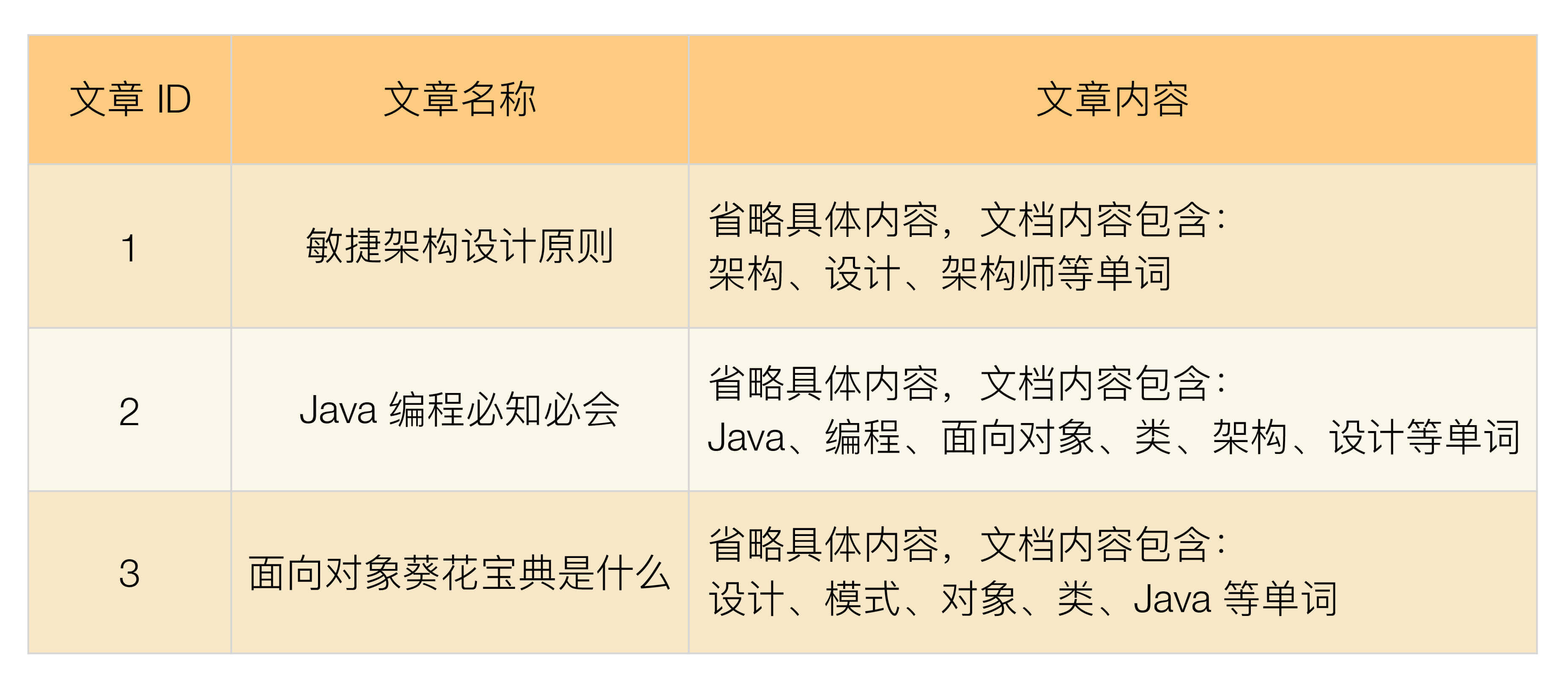
正排索引适用于根据文档名称来查询文档内容。例如,用户在网站上单击了“面向对象葵花宝典是什么”,网站根据文章标题查询文章的内容展示给用户。
倒排索引示例:
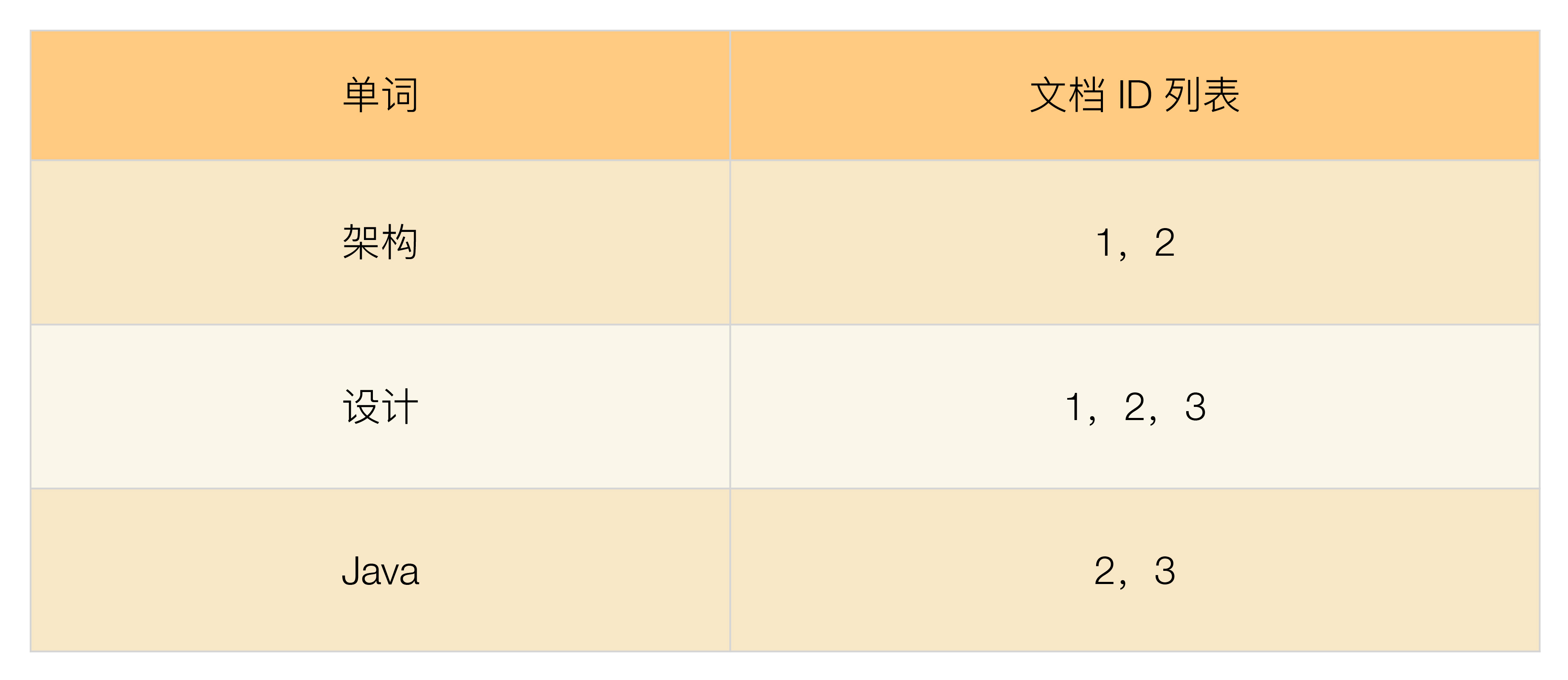
倒排索引适用于根据关键词来查询文档内容。例如,用户只是想看“设计”相关的文章,网站需要将文章内容中包含“设计”一词的文章都搜索出来展示给用户。
2.全文搜索的使用方式
全文搜索引擎的索引对象是单词和文档,而关系数据库的索引对象是键和行,两者的术语差异很大,不能简单地等同起来。因此,为了让全文搜索引擎支持关系型数据的全文搜索,需要做一些转换操作,即将关系型数据转换为文档数据。
目前常用的转换方式是将关系型数据按照对象的形式转换为JSON文档,然后将JSON文档输入全文搜索引擎进行索引。我同样以程序员的基本信息表为例,看看如何转换。
将前面样例中的程序员表格转换为JSON文档,可以得到3个程序员信息相关的文档,我以程序员1为例:
{
"id": 1,
"姓名": "多隆",
"性别": "男",
"地点": "北京",
"单位": "猫厂",
"爱好": "写代码,旅游,马拉松",
"语言": "Java、C++、PHP",
"自我介绍": "技术专家,简单,为人热情"
}
全文搜索引擎能够基于JSON文档建立全文索引,然后快速进行全文搜索。以Elasticsearch为例,其索引基本原理如下:
Elastcisearch是分布式的文档存储方式。它能存储和检索复杂的数据结构——序列化成为JSON文档——以实时的方式。
在Elasticsearch中,每个字段的所有数据都是默认被索引的。即每个字段都有为了快速检索设置的专用倒排索引。而且,不像其他多数的数据库,它能在相同的查询中使用所有倒排索引,并以惊人的速度返回结果。
总结
今天我讲了读写分离方式的原理,以及两个设计复杂度:复制延迟和分配机制,紧接着讲了高性能数据库集群的分库分表架构,包括业务分库产生的问题和分表的两种方式及其带来的复杂度,最后谈了谈为了弥补关系型数据库缺陷而产生的NoSQL技术。如果本文对你有帮助的话,欢迎点赞分享,这对我继续分享&创作优质文章非常重要。感谢 !
本文由 mdnice 多平台发布








![「OceanBase 4.1 体验」|快速安装部署[OBD方式]](https://img-blog.csdnimg.cn/fc511c8d9aa44f289a0bd3357c36f33c.png)