文章目录
- SQL操作
- 数据准备
- 查询索引下的数据
- SQL转化为DSL(本质)
- SQL与DSL混合使用
- 查看所有索引
- 查询指定索引
- 查看索引(表)结构
- where条件过滤
- group by分组
- having 对分组后的数据进行过滤
- order by 排序
- limit 限制查询数量
- cursor 游标->为缓存设计
- 聚合操作
- 支持的函数和运算
- 比较运算符
- 逻辑运算符
- 数学运算符
- 类型转换
- 模糊查询
- 聚合分析函数
- 分组函数
- 数学通用函数
- 三角函数
- 日期时间函数
- 全文检索函数
- 字符串检索函数
- 条件分支函数
- 系统函数
SQL操作
通常使用es的时候,都会使用query dsl来查询数据,从es6.3之后,es就支持SQL查询啦
本质就是 Elasticsearch SQL 这个 X-Pack 组件,将SQL翻译成SQL DSL
-
Elasticsearch SQL 具有如下特性:
- 原生支持:Elasticsearch SQL 是专门为 Elasticsearch 打造的。
- 没有额外的零件:无需其他硬件,处理器,运行环境或依赖库即可查询 Elasticsearch,Elasticsearch SQL 直接在 Elasticsearch 内部运行。
- 轻巧高效:Elasticsearch SQL 并未抽象化其搜索功能,相反的它拥抱并接受了 SQL 来实现全文搜索,以简洁的方式实时运行全文搜索。
-
SQL和Elasticsearch的对应关系
SQL ES 描述 Column field 对比两个,数据都存储在命名条目中,具有多种数据类型,包含个值。SQL 将此类条目称为列,而 Elasticsearch 称为字段。请注意在 Elasticsearch 中,一个字段可以包含多个相同类型的值 (本质上是一个列表),而在 SQL 中,一个列可以只包含一个所述类型的值。Elasticsearch SQL 将尽最大努力保留 SQL 语义,并根据查询拒绝那些返回具有多个值的字段的查询 Row document Columns 和 fields 本身不存在;它们是 row或 a的一部分 document两者的语义略有不同:row 趋于严格 (并且有更多的强制执行),而document 趋于更加灵活或松散(同时仍然具有结构) Table Index 执行查询的目标 Schema Mapping 在 RDBMS 中,schem 主要是表的命名空间,通常用作安全边界。Elasticsearch 没有为它提供等效的概念。但是,当启用安全性时Elasticsearch 会自动应用安全性强制,以便角色只能看到它被允许访
问的数据Database Cluster 实例 在 SQL 中,catalog 或者 database 从概念上可以互换使用,表示一组模式,即多个表。在 Elasticsearch 中,可用的索引集被分组在一个cluster,语义也有所不同。database 本质上是另一个命名空间 (可能对数据的存储方式有一些影响),而 Elasticsearch cluster 是一个运行时实例,或者更确切地说是一组至少一个 Elasticsearch 实例(通常是分布式运行)。在实践中,这意味着虽然在 SQL 中,一个实例中可能有多个目录,但在 Elasticsearch 中,一个目录仅限于一个 -
_sql?format=xxx
format 参数控制返回结果的格式,默认为 json 格式
- txt:表示文本格式,看起来更直观点.
- csv:使用逗号隔开的数据
- json:JSON 格式数据
- tsv: 使用 tab 键隔开数据
- yaml:属性配置格式
数据准备
创建索引并增加数据,等同于创建表和数据
PUT my-sql-index/_bulk?refresh
{"index":{"_id": "JAVA"}}
{"name": "JAVA", "author": "zhangsan", "release_date": "2022-05-01", "page_count": 561}
{"index":{"_id": "BIGDATA"}}
{"name": "BIGDATA", "author": "lisi", "release_date": "2022-05-02", "page_count": 482}
{"index":{"_id": "SCALA"}}
{"name": "SCALA", "author": "wangwu", "release_date": "2022-05-03", "page_count": 604}
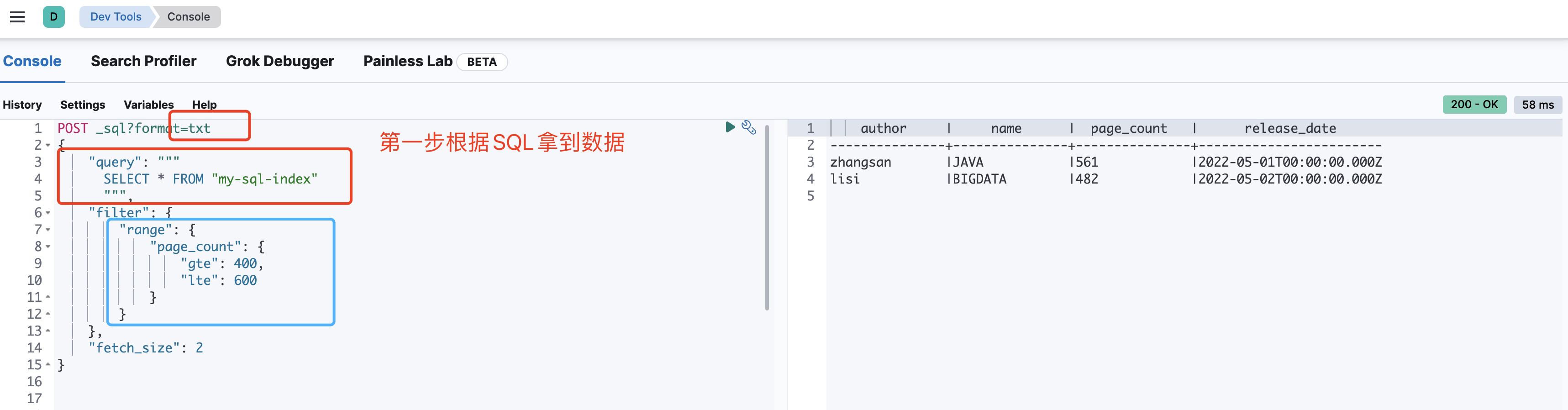
查询索引下的数据
POST _sql?format=txt
{
"query": """
SELECT * FROM "my-sql-index"
"""
}
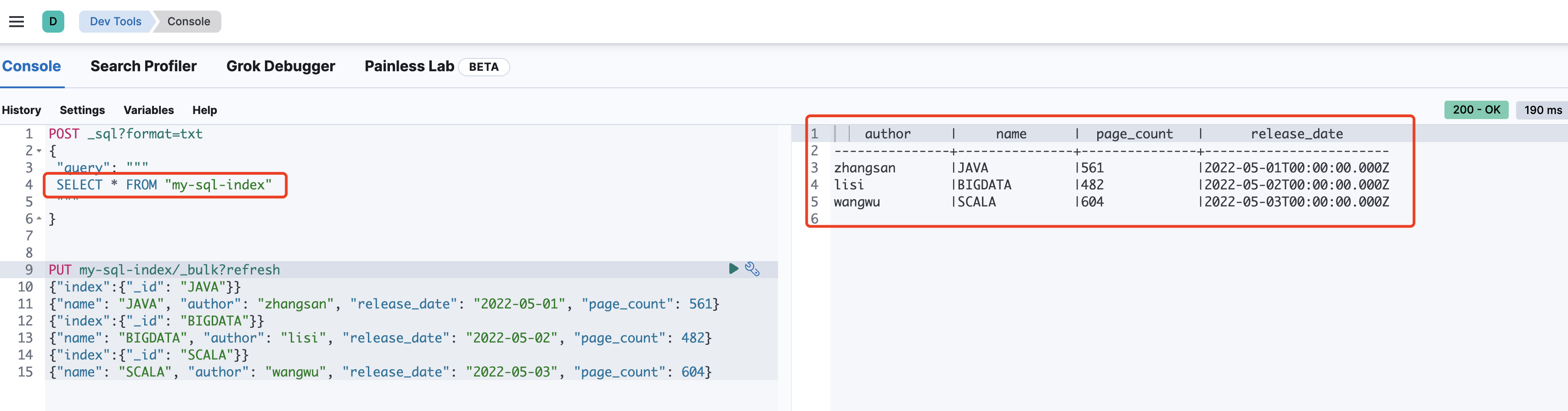
SQL转化为DSL(本质)
# 转换 SQL 为 DSL 进行操作
POST _sql/translate
{
"query": """
SELECT * FROM "my-sql-index" where page_count > 500
"""
}
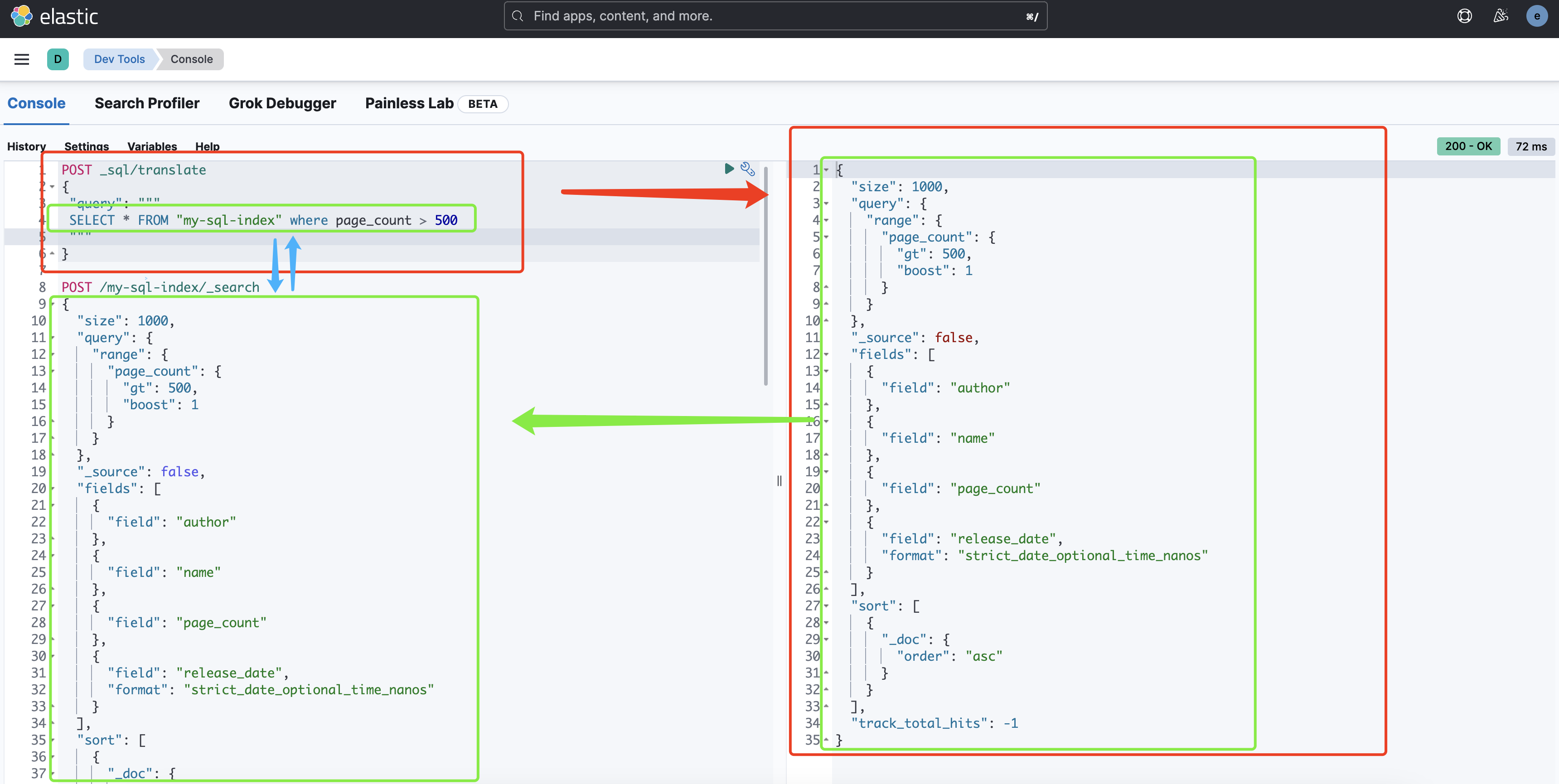
SQL与DSL混合使用
ES 会先根据 SQL 进行查询,然后根据 DSL 语句对 SQL 的执行结果进行二次查询
# 由于索引中含有横线,所以作为表名时需要采用双引号,且外层需要三个引号包含
POST _sql?format=txt
{
"query": """
SELECT * FROM "my-sql-index"
""",
"filter": {
"range": {
"page_count": {
"gte": 400,
"lte": 600
}
}
},
"fetch_size": 2
}
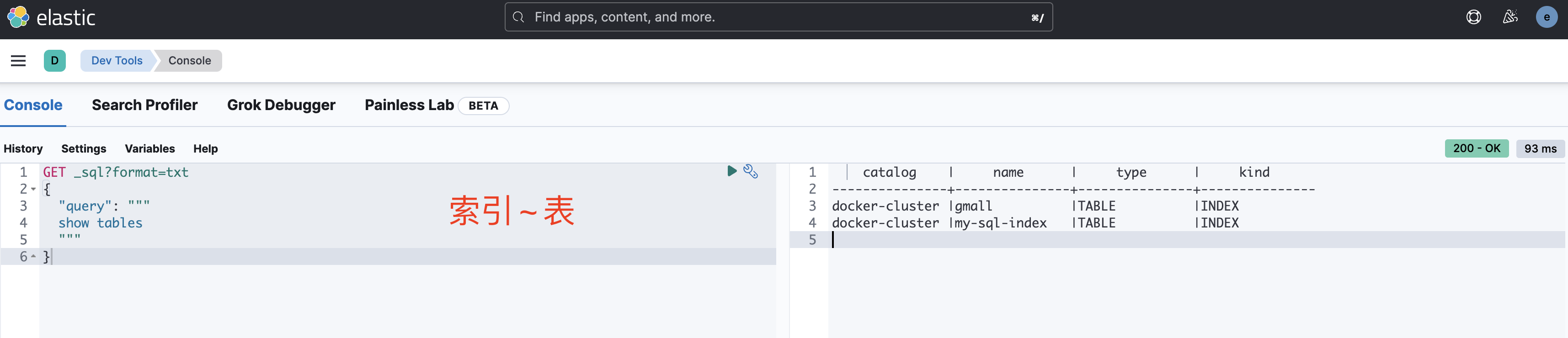
查看所有索引
GET _sql?format=txt
{
"query": """
show tables
"""
}
查询指定索引
# 直接查询
GET _sql?format=txt
{
"query": """
show tables like 'my-sql-index'
"""
}
# 模糊查询
# 直接查询
GET _sql?format=txt
{
"query": """
show tables like 'my%'
"""
}

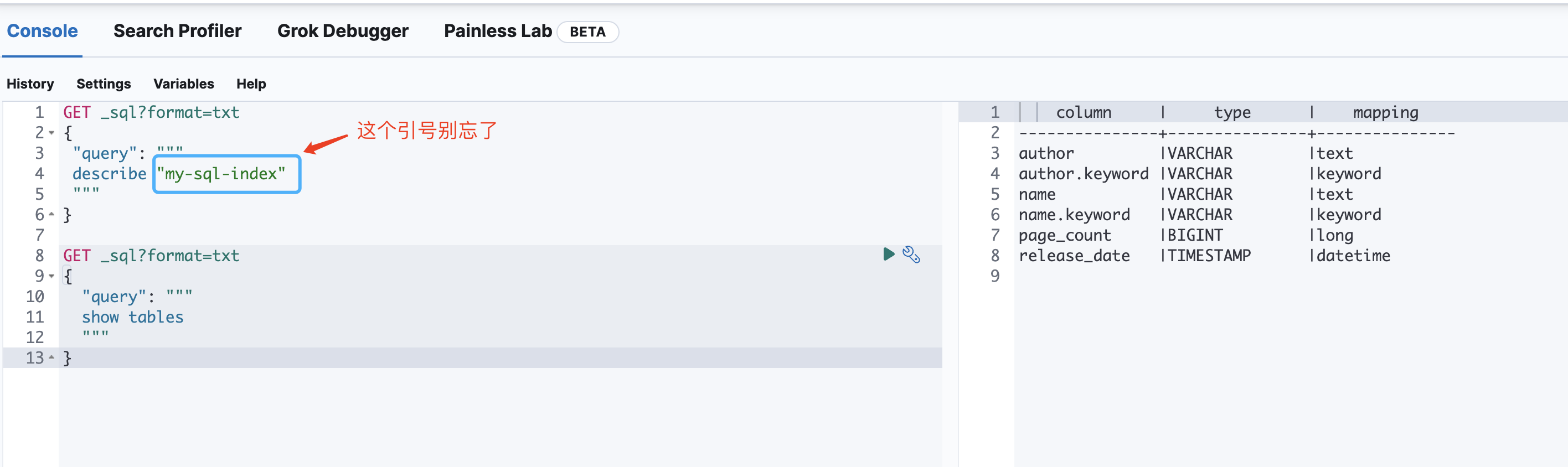
查看索引(表)结构
GET _sql?format=txt
{
"query": """
describe "my-sql-index"
"""
}
where条件过滤
POST _sql?format=txt
{
"query": """
SELECT * FROM "my-sql-index" where page_count > 500 and name = 'JAVA'
"""
}

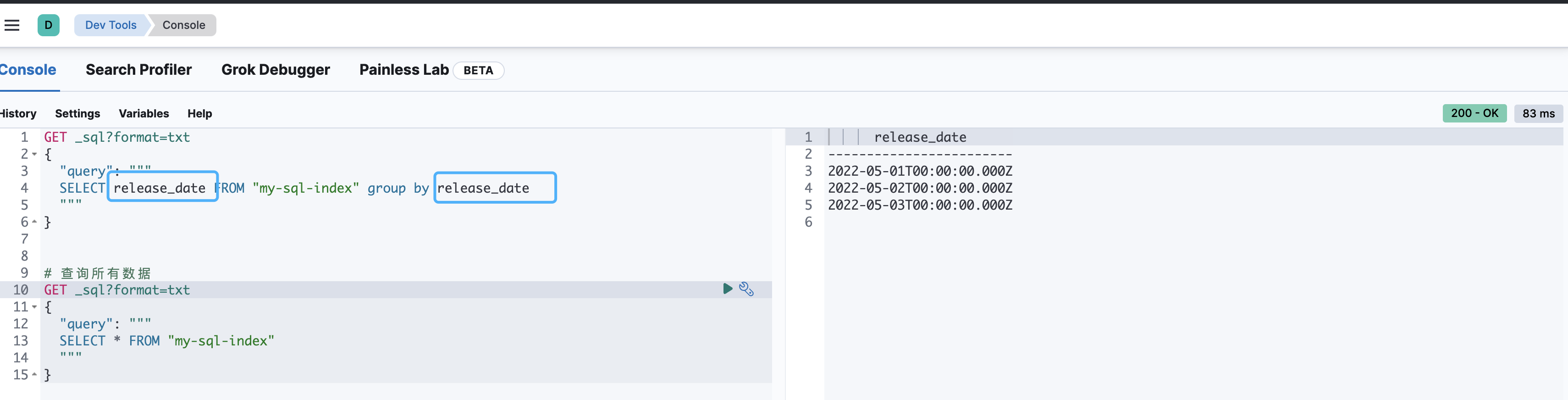
group by分组
# 查询所有数据
GET _sql?format=txt
{
"query": """
SELECT * FROM "my-sql-index"
"""
}
# 按照日期进行分组
GET _sql?format=txt
{
"query": """
SELECT release_date FROM "my-sql-index" group by release_date
"""
}
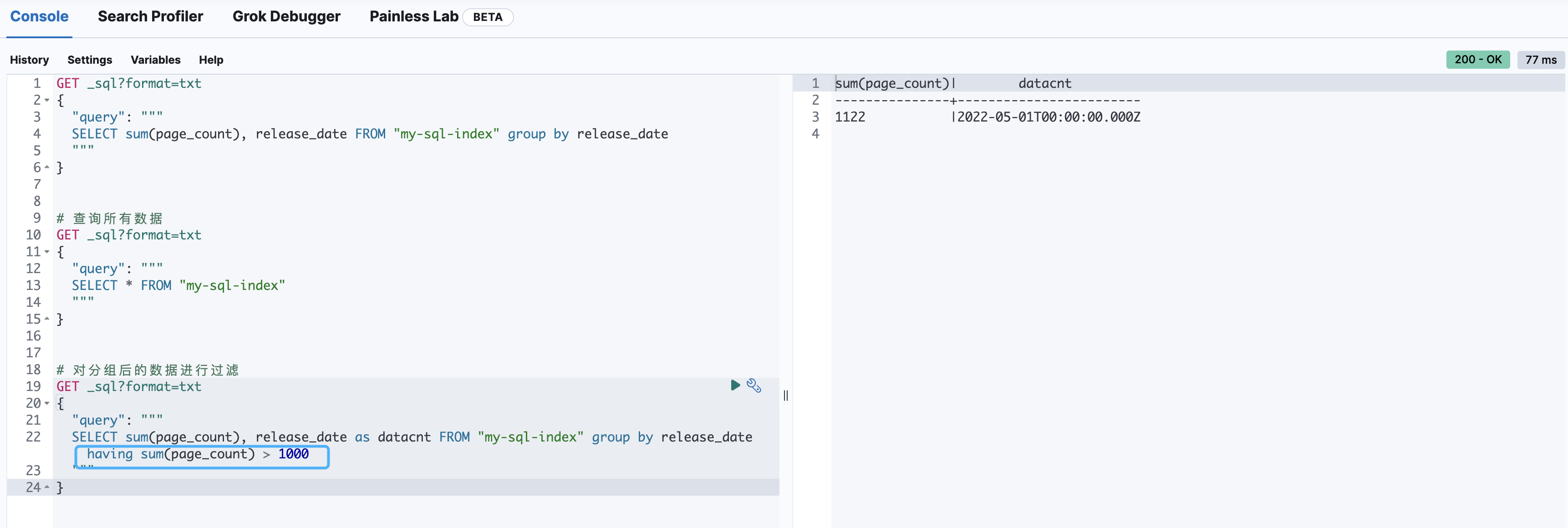
having 对分组后的数据进行过滤
HAVING子句中的条件是对分组后的结果进行筛选的,因此只能使用聚合函数的结果或分组列的比较。如果要对原始数据进行筛选,请使用WHERE子句。
# 对分组后的数据进行过滤
GET _sql?format=txt
{
"query": """
SELECT sum(page_count), release_date as datacnt FROM "my-sql-index" group by release_date having sum(page_count) > 1000
"""
}
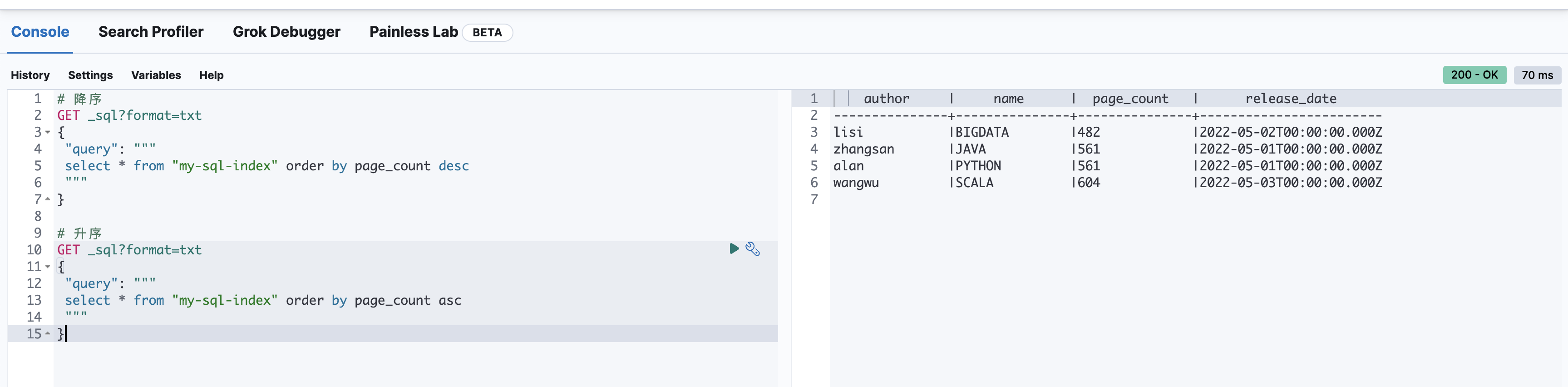
order by 排序
# 对页面数量进行排序(降序desc、升序asc)
GET _sql?format=txt
{
“query”: “”"
select * from “my-sql-index” order by page_count desc
“”"
}
limit 限制查询数量
GET _sql?format=txt
{
"query": """
select * from "my-sql-index" limit 2
"""
}

cursor 游标->为缓存设计
本质上,游标就是一种能从包括多条数据记录的结果集中每次提取一条或多条记录的机制
作上有点类似于迭代器,可多次执行
-
首次取数据
# 查询数据 # 因为查询结果较多,但是获取的数据较少,所以为了提高效果,会将数据存储到临时缓冲区中 # 此处数据展示格式为 json POST _sql?format=json { "query": """ SELECT * FROM "my-sql-index" order by page_count desc """, "fetch_size": 1 }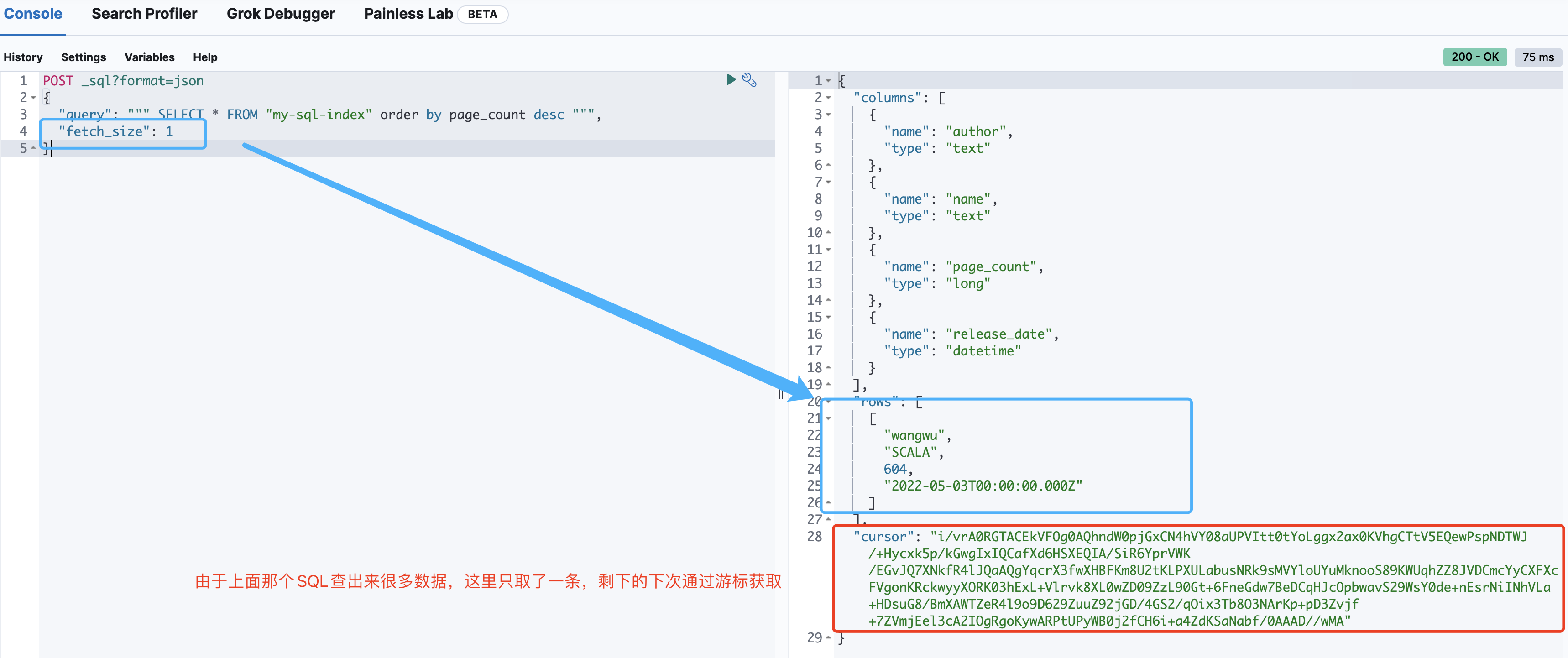
-
通过游标再获取数据
# 此处游标 cursor 值需要根据读者执行的操作进行修改,请勿直接使用 POST /_sql?format=json { "cursor": "i/vrA0RGTACEkVFOwkAQhnfWhhhi4hG8AlhMfOGhKBUSwGjd1jYmm7VsaaXtNu2AlRN5AO+nXVIiPvk/TGYmM/8k30BAICYUiNZ3o/N9RggAdKNEpkteqRK7hVhJHqpNjqTDo6SsEICAkap81c5/wQmhtFnUQYu+tAnRXe0NRkdsMFYloUYuMknosS89K2UqRSX5UqCEiwrLJMR9wVWBicpFyjHJJM9FrioKn5DwbWm9j+evz2sMTbuaeekmuHMHdob3DsPdvFc7LOlPfDN4W3jTmq3t2EvHlp0VPcGud/Km77CsPwtvR3UwXkSOd1W5l6F10LQeeE9m/OivsfQmrsNy1/R3gRt6Re0z9cEerNF/tyxrOCTdFq4BUYsADJQ1NmCiPYrf8gjJgS9Ef9GcaiaaRLPe/OsHAAD//wMA" }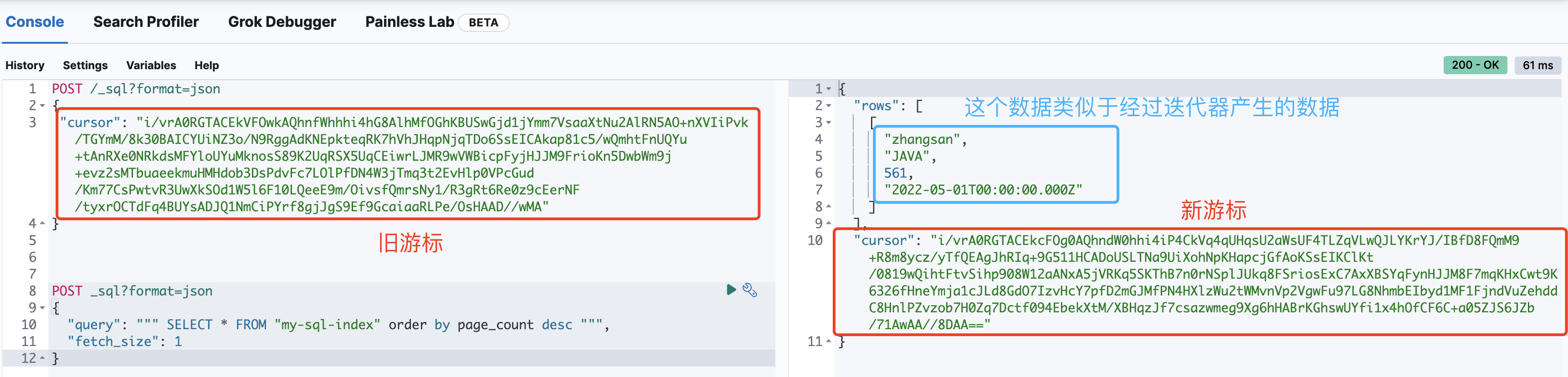
-
知道取完报
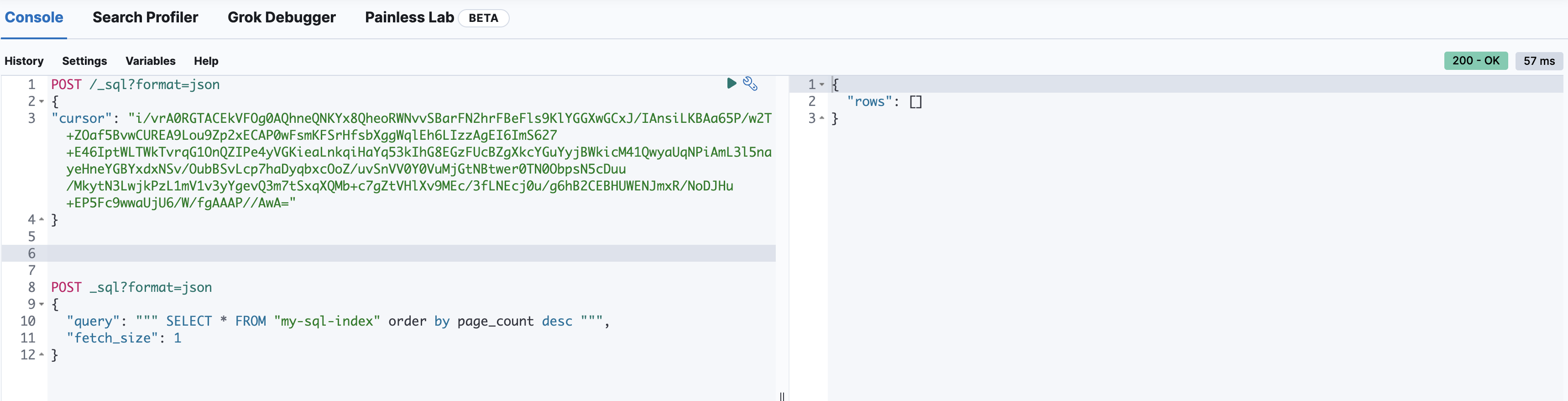
-
关闭游标缓存
# 此处游标 cursor 值需要根据读者执行的操作进行修改,请勿直接使用 POST _sql/close { "cursor": "8/LoA0RGTABEissKgkAYRh2QiAh8FZVcuExKaWisxEbHTUzO7wVH7TKSb19Gi87ig8N3UIaeox/IgdmjlQW0YLY7iICuhO9aIpHNJvWtLMXOKXGaqKUms0vPb8wXSSJCtyE7N3JP2ggfKCZRjHdxmq9/eFc8Zndi0wJoeGY0PJLOq7lZVWJrJXFaee8JQ0fFjA+q6h9IVzAqTUOF3vEW/rq48RIueT90Cumy78pvs3yABP6Ei+AK0Py7qm5huowPAAAA//8DAA==" }
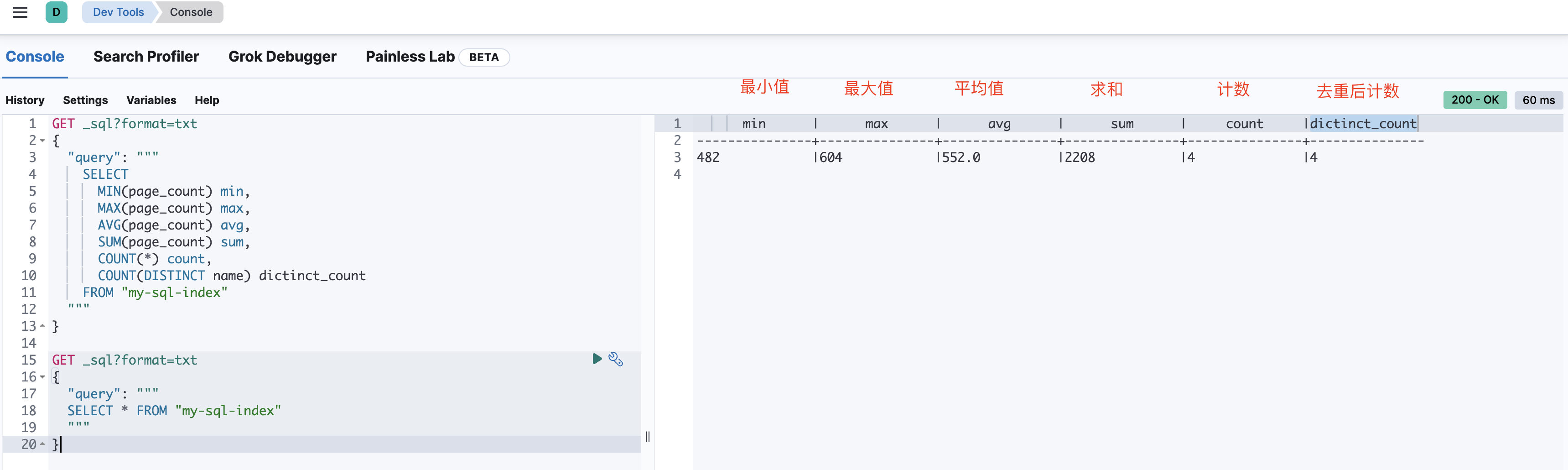
聚合操作
GET _sql?format=txt
{
"query": """
SELECT
MIN(page_count) min,
MAX(page_count) max,
AVG(page_count) avg,
SUM(page_count) sum,
COUNT(*) count,
COUNT(DISTINCT name) dictinct_count
FROM "my-sql-index"
"""
}
支持的函数和运算
比较运算符
# Equality
SELECT * FROM "my-sql-index" WHERE name = 'JAVA'
# Null Safe Equality
SELECT 'elastic' <=> null AS "equals"
SELECT null <=> null AS "equals"
# Inequality
SELECT * FROM "my-sql-index" WHERE name <> 'JAVA'
SELECT * FROM "my-sql-index" WHERE name != 'JAVA'
# Comparison
SELECT * FROM "my-sql-index" WHERE page_count > 500
SELECT * FROM "my-sql-index" WHERE page_count >= 500
SELECT * FROM "my-sql-index" WHERE page_count < 500
SELECT * FROM "my-sql-index" WHERE page_count <= 500
# BETWEEN
SELECT * FROM "my-sql-index" WHERE page_count between 100 and 500
# Is Null / Is Not Null
SELECT * FROM "my-sql-index" WHERE name is not null
SELECT * FROM "my-sql-index" WHERE name is null
# IN
SELECT * FROM "my-sql-index" WHERE name in ('JAVA', 'SCALA')
逻辑运算符
# AND
SELECT * FROM "my-sql-index" WHERE name = 'JAVA' AND page_count > 100
# OR
SELECT * FROM "my-sql-index" WHERE name = 'JAVA' OR name = 'SCALA'
# NOT
SELECT * FROM "my-sql-index" WHERE NOT name = 'JAVA'
数学运算符
select 1 + 1 as x
select 1 - 1 as x
select - 1 as x
select 6 * 6 as x
select 30 / 5 as x
select 30 % 7 as x
类型转换
SELECT '123'::long AS long
模糊查询
# LIKE 通配符
SELECT * FROM "my-sql-index" WHERE name like 'JAVA%'
SELECT * FROM "my-sql-index" WHERE name like 'JAVA_'
# 如果需要匹配通配符本身,使用转义字符
SELECT * FROM "my-sql-index" WHERE name like 'JAVA/%' ESCAPE '/'
# RLIKE 不要误会,这里的 R 表示的不是方向,而是正则表示式 Regex
SELECT * FROM "my-sql-index" WHERE name like 'JAV*A'
SELECT * FROM "my-sql-index" WHERE name rlike 'JAV*A'
# 尽管 LIKE在 Elasticsearch SQL 中搜索或过滤时是一个有效的选项,但全文搜索 MATCH 和 QUERY
速度更快、功能更强大,并且是首选替代方案。
聚合分析函数
# FIRST / FIRST_VALUE : FIRST(第一个字段,排序字段)
SELECT first(name, release_date) FROM "my-sql-index"
SELECT first_value(substring(name,2,1)) FROM "my-sql-index"
# LAST / LAST_VALUE : LAST (第一个字段,排序字段)
SELECT last(name, release_date) FROM "my-sql-index"
SELECT last_value(substring(name,2,1)) FROM "my-sql-index"
# KURTOSIS 量化字段的峰值分布
SELECT KURTOSIS(page_count) FROM "my-sql-index"
# MAD
SELECT MAD(page_count) FROM "my-sql-index"
分组函数
# HISTOGRAM : 直方矩阵
SELECT HISTOGRAM(page_count, 100) as c, count(*) FROM "my-sql-index" group by c
数学通用函数
# ABS:求数字的绝对值
select ABS(page_count) from "myindex" limit 5
# CBRT:求数字的立方根,返回 double
select page_count v,CBRT(page_count) cbrt from "myindex" limit 5
# CEIL:返回大于或者等于指定表达式最小整数(double)
select page_count v,CEIL(page_count) from "myindex" limit 5
# CEILING:等同于 CEIL
select page_count v,CEILING(page_count) from "myindex" limit 5
# E:返回自然常数 e(2.718281828459045)
select page_count,E(page_count) from "myindex" limit 5
# ROUND:四舍五入精确到个位
select ROUND(-3.14)
# FLOOR:向下取整
select FLOOR(3.14)
# LOG:计算以 2 为底的自然对数
select LOG(4)
# LOG10:计算以 10 为底的自然对数
select LOG10(100)
# SQRT:求一个非负实数的平方根
select SQRT(9)
# EXP:此函数返回 e(自然对数的底)的 X 次方的值
select EXP(3)
三角函数
# DEGREES:返回 X 从弧度转换为度值
select DEGREES(x)
# RADIANS:返回 X 从度转换成弧度的值
select RADIANS(x)
# SIN:返回 X 的正弦
select SIN(x)
# COS:返回 X,X 值是以弧度给出的余弦值
select COS(角度)
# TAN:返回参数 X,表示以弧度的切线值
select TAN(角度)
# ASIN:返回 X 的反正弦,X 的值必须在-1 至 1 范围内,返回 NULL
select ASIN(x)
# ACOS:返回 X 的反正弦,X 值必须-1 到 1 之间范围否则将返回 NULL
select ACOS(x)
# ATAN:返回 X 的反正切
select ATAN(x)
# SINH:返回 X 的双曲正弦值
select SINH(x)
# COSH:返回 X 的双曲余弦值
select COSH(x)
日期时间函数
# YEAR:
SELECT YEAR(CAST('2022-05-01T00:00:00Z' AS TIMESTAMP)) AS year
# MONTH_OF_YEAR() or MONTH():
SELECT MONTH(CAST('2022-05-01T00:00:00Z' AS TIMESTAMP)) AS month
# WEEK_OF_YEAR() or WEEK():
SELECT WEEK(CAST('2022-05-01T00:00:00Z' AS TIMESTAMP)) AS week
# DAY_OF_YEAR() or DOY() ,效果等同于 EXTRACT(<datetime_function> FROM
<expression>):
SELECT DOY(CAST('2022-05-01T00:00:00Z' AS TIMESTAMP)) AS day
# DAY_OF_MONTH(), DOM(), or DAY():
SELECT DAY(CAST('2022-05-01T00:00:00Z' AS TIMESTAMP)) AS day
# DAY_OF_WEEK() or DOW():
SELECT DOW(CAST('2022-05-01T00:00:00Z' AS TIMESTAMP)) AS day
# HOUR_OF_DAY() or HOUR():
SELECT HOUR(CAST('2022-05-01T00:00:00Z' AS TIMESTAMP)) AS hour
# MINUTE_OF_DAY():
SELECT MINUTE_OF_DAY(CAST('2022-05-01T00:00:00Z' AS TIMESTAMP)) AS minute
# MINUTE_OF_HOUR() or MINUTE():
SELECT MINUTE(CAST('2022-05-01T00:00:00Z' AS TIMESTAMP)) AS minute
# SECOND_OF_MINUTE() or SECOND():
SELECT SECOND(CAST('2022-05-01T00:00:00Z' AS TIMESTAMP)) AS second
全文检索函数
# MATCH:MATCH(匹配字段,规则, 配置参数(可选))
SELECT * FROM "my-sql-index" where MATCH(name, 'JAVA')
SELECT * FROM "my-sql-index" where MATCH(name, 'java')
# MATCH:MATCH(('匹配字段^权重 1,匹配字段^权重 2',规则, 配置参数(可选))
SELECT * FROM "my-sql-index" where MATCH('author^2,name^5', 'java')
# QUERY
SELECT * FROM "my-sql-index" where QUERY('name:Java')
# SCORE : 评分
SELECT *, score() FROM "my-sql-index" where QUERY('name:Java')
字符串检索函数
# ASCII : 字符串转成 ASC 码
SELECT ASCII('Elastic')
# BIT_LENGTH : 位长度
SELECT BIT_LENGTH('Elastic')
SELECT BIT_LENGTH('中国')
# CHAR :转换字符
SELECT CHAR(69)
# CHAR_LENGTH :字符长度
SELECT CHAR_LENGTH('Elastic')
# CONCAT:合并
SELECT CONCAT('Elastic', 'search')
# INSERT : INSERT(字符串,起始位置,长度,插入的内容)
SELECT INSERT('Elastic', 8, 1, 'search')
SELECT INSERT('Elastic', 7, 1, 'search')
# LCASE :转换小写
SELECT LCASE('Elastic')
# LEFT : 获取左边最多 N 个字符
SELECT LEFT('Elastic',3)
# LENGTH
SELECT length('Elastic')
SELECT length('中国')
# LOCATE : LOCATE(表达式,字符串,起始位置),获取满足条件的位置
SELECT LOCATE('a', 'Elasticsearch')
SELECT LOCATE('a', 'Elasticsearch', 5)
# LTRIM :去除左边的空格
SELECT LTRIM(' Elastic')
# OCTET_LENGTH : 字节长度
SELECT OCTET_LENGTH('Elastic')
SELECT OCTET_LENGTH('中国')
# POSITION :获取指定字符串的位置
SELECT POSITION('Elastic', 'Elasticsearch')
# REPEAT :将字符串重复指定次数
SELECT REPEAT('Elastic', 3)
# REPLACE :替换数据
SELECT REPLACE('Elastic','El','Fant')
# RIGHT :从右边获取指定数量的数据
SELECT RIGHT('Elastic',3)
# RTRIM :去除右边的空格
SELECT RTRIM('Elastic ')
# SPACE : 生成指定数量的空格
SELECT concat(SPACE(3),'abc')
# STARTS_WITH : 判断是否以指定字符串开头
SELECT STARTS_WITH('Elasticsearch', 'Elastic')
# SUBSTRING : 截取字符串,必须传递三个参数
SELECT SUBSTRING('Elasticsearch', 0, 7)
# TRIM :去掉首尾空格
SELECT TRIM(' Elastic ') AS trimmed
# UCASE : 转换大写
SELECT UCASE('Elastic')
条件分支函数
# 多重分支判断
SELECT CASE 5
WHEN 1 THEN 'elastic'
WHEN 2 THEN 'search'
WHEN 3 THEN 'elasticsearch'
ELSE 'default'
END AS "case"
SELECT CASE WHEN 1 > 2 THEN 'elastic'
WHEN 2 > 10 THEN 'search'
ELSE 'default'
END AS "case"
# IFNULL
SELECT IFNULL('elastic', null) AS "ifnull"
SELECT IFNULL(null, 'search') AS "ifnull"
# IIF
SELECT IIF(1 < 2, 'TRUE', 'FALSE') AS result1, IIF(1 > 2, 'TRUE', 'FALSE') AS result2
# ISNULL
SELECT ISNULL('elastic', null) AS "isnull"
SELECT ISNULL(null, 'search') AS "isnull"
# LEAST:获取除 null 外的最小值
SELECT LEAST(null, 2, 11) AS "least"
SELECT LEAST(null, null, null, null) AS "least"
# NULLIF : 如果两个字符串不相同,则返回第一个字符串,如果相同,返回 null
SELECT NULLIF('elastic', 'search') AS "nullif"
SELECT NULLIF('elastic', 'elastic') AS "nullif"
# NVL : 返回第一个不是 null 的字符串,如果都是 null,那么返回 Null
SELECT NVL('elastic', null) AS "nvl"
SELECT NVL(null, null) AS "nvl"
系统函数
# ES 集群
SELECT DATABASE()
# 用户
SELECT USER()


![「OceanBase 4.1 体验」|快速安装部署[OBD方式]](https://img-blog.csdnimg.cn/fc511c8d9aa44f289a0bd3357c36f33c.png)