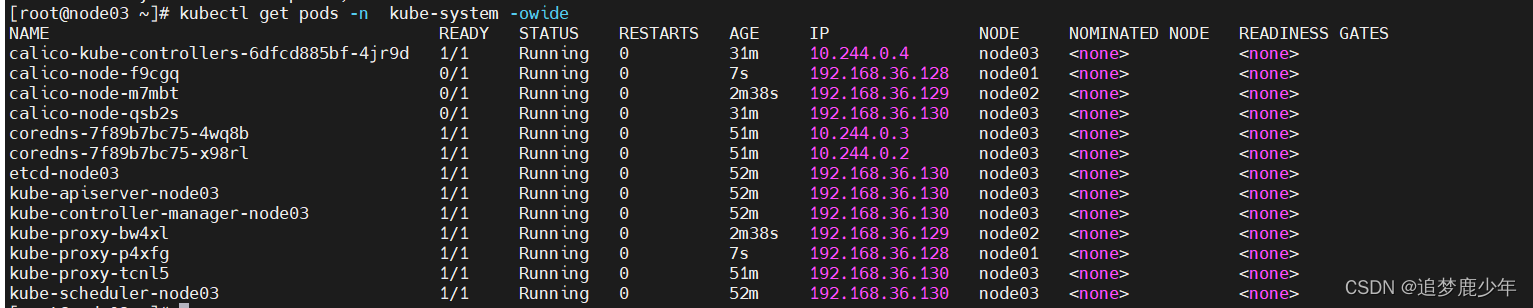
目录
一、基本结论:InnoDB存储引擎B+树的树高3-4层
二、存储引擎B+树结构简单分析
三、主键索引B+树推导
四、InnoDB页的内部结构推导
五、剖析InnoDB数据文件推导
六、一般思路推导计算B+树高度总结
参考文献、书籍及链接
一、基本结论:InnoDB存储引擎B+树的树高3-4层
InnoDB存储引擎的B+树的树高通常是比较小的,通常在3-4层左右。这是因为InnoDB存储引擎采用了很多优化策略来减小B+树的高度。其中包括:
- 聚簇索引:InnoDB存储引擎的聚簇索引是按照主键进行组织的,这样可以避免在非聚簇索引中再次存储主键,从而减小了B+树的高度。
- 页分裂:当B+树中的某个页面已经满了时,InnoDB存储引擎会对该页面进行分裂,以保证B+树的平衡性。
- 页合并:当B+树中某些叶子节点的空间利用率较低时,InnoDB存储引擎会将这些节点合并成一个更大的节点,以减小B+树的高度。
- 自适应哈希索引:在InnoDB存储引擎中,如果某个表的某些查询经常使用某个非聚簇索引,那么InnoDB会自动为该索引创建哈希索引,从而提高查询效率。
这些优化策略的使用可以使得InnoDB存储引擎的B+树的高度通常比较小,从而提高数据库的查询效率。
二、存储引擎B+树结构简单分析
在InnoDB存储引擎中,使用B+树结构存放和组织索引和数据,一个典型的索引组织表结构如下:
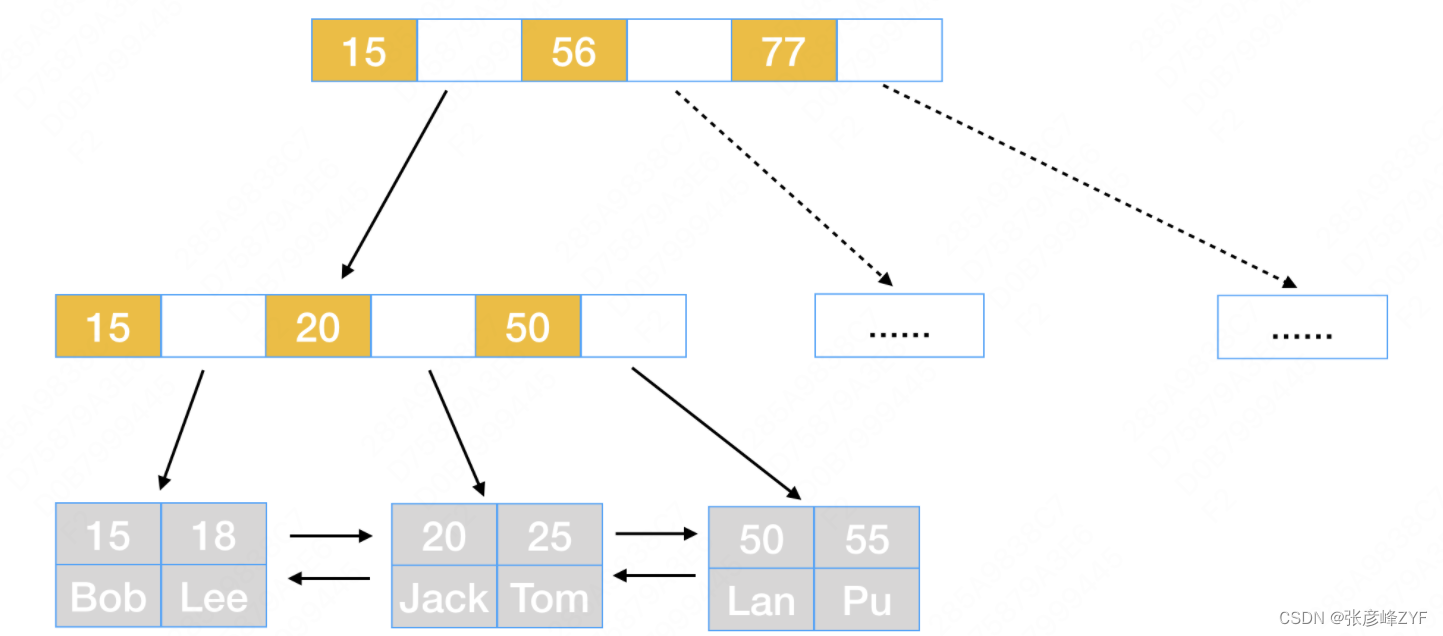
这是一个包含(id,name)字段的数据在B+树上存放的方式。
在B+树中非叶子节点上存放主键ID以及指向下一层节点的指针,而在叶子节点上,则存放真正的数据。在叶子节点之间通过双链表的方式将相邻节点连接起来。
这里的“节点”就是InnoDB中的“页Page”。“页”是InnoDB存储数据的最小单元,默认大小为16K。对“页”理解,可以延伸到其他存储模型中,例如在文件系统和磁盘上都是自己的最小存储单元,文件系统中最小存储单元是4k,而在磁盘上最小存储单元是512字节。InnoDB从磁盘中加载数据就是通过以下的数据关系进行的。
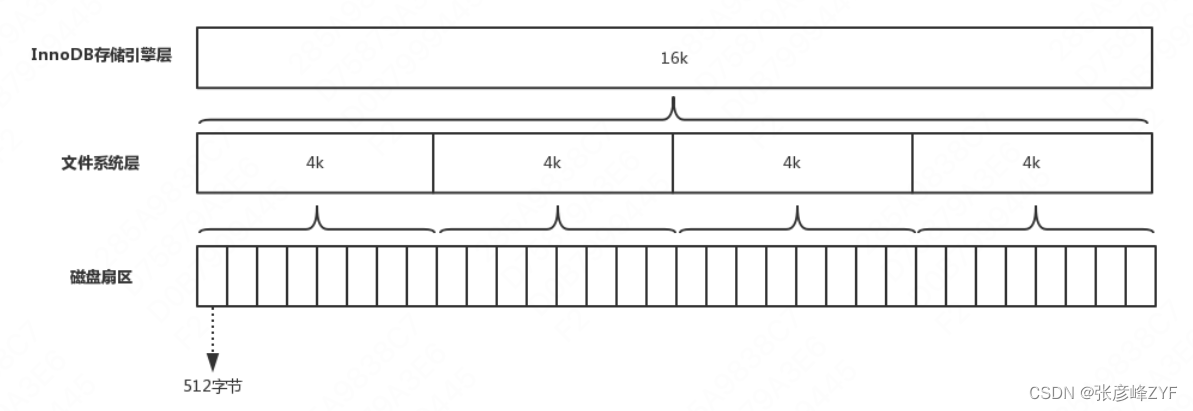
从InnoDB的“页”的大小,可以推演出的结论是:一个表不管是否存放有数据,在InnoDB中至少占用16K空间;一个表不管有多大,InnoDB中使用的空间必然是16的整数倍。
三、主键索引B+树推导
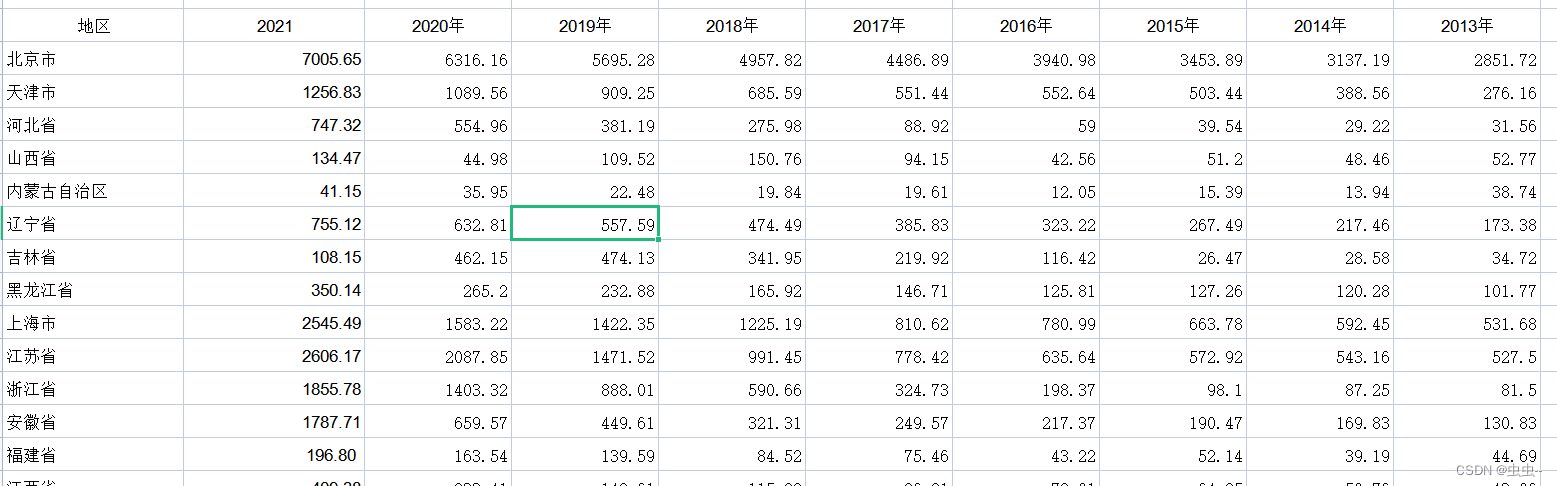
当树高=1时:这时B+树只有一个节点,即根节点,同时也是叶子节点,所有的数据就存放在这个节点中。假设单行数据大小为1k。则该节点可以存放的数据行数=节点容量/单行数据大小=16K/1K=16行数据。
当树高=2时:这样B+树有根节点和叶子节点,根节点中存在主键和指针,叶子节点中存放数据。
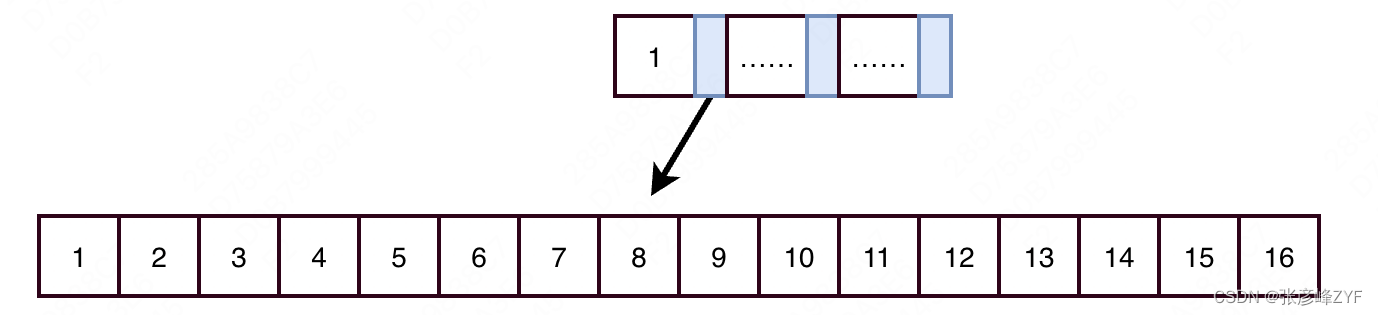
每个叶子节点可以存放的数据行数,按上述推算=节点容量/单行数据大小=16K/1K=16行数据。而根节点中可以存放的指针数量=节点容量 / (主键长度+指针长度)=16K/(8byte+6byte)=1170。(注:指针长度固定为6字节,这里假设主键使用bigint类型,长度为8字节)
因此一个树高为2的B+树,可以存放的数据行数=单个叶子节点存放数据行数 X 根节点指针数量=16 X 1170 = 18720。
当树高=3时:这时B+树,包括一个根节点,一个非叶子节点和一个叶子节点。
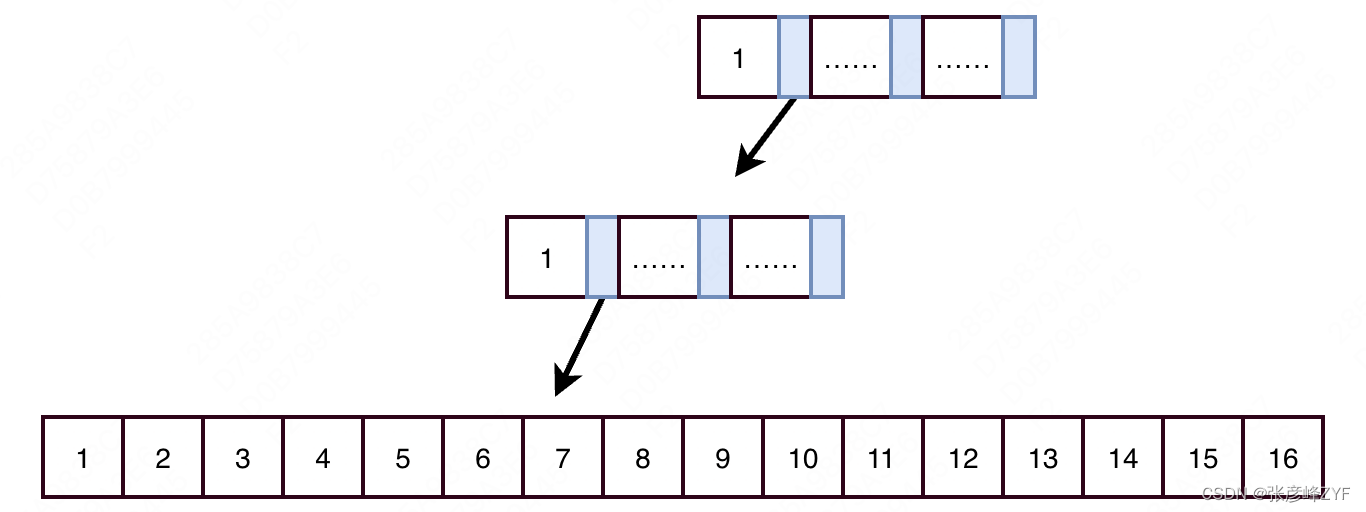
按上述推算方式得出,树高=3时,可以存放的数量行数=单个叶子节点存放数据行数 X 非叶子节点指针数量 X 根节点指针数量 = 16 X 1170 X 1170 = 21902400。
因此推演得出结论:当单行数据大小为S字节,树高为H时,一个bigint类型的主键B+树索引中可以存放的数量行数N等于:
![]()
按公式计算:当树高为4时,可以存放200百多亿行数据。这样的数据容量,可以满足绝大部分应用的需求,因此我们可以说在绝大部分应用中,B+树高度为3或4就可以满足数据存储的需求。B+树这种高扇出低树高的特征,也大大的提高了主键查询性能。
四、InnoDB页的内部结构推导
假设一个“页”的空间均用于存储用户数据,然而真实的“页”除了存储用户数据以外,还预留了空间存放一些辅助性的信息。一个完整的“页”由以下7个部分组成:
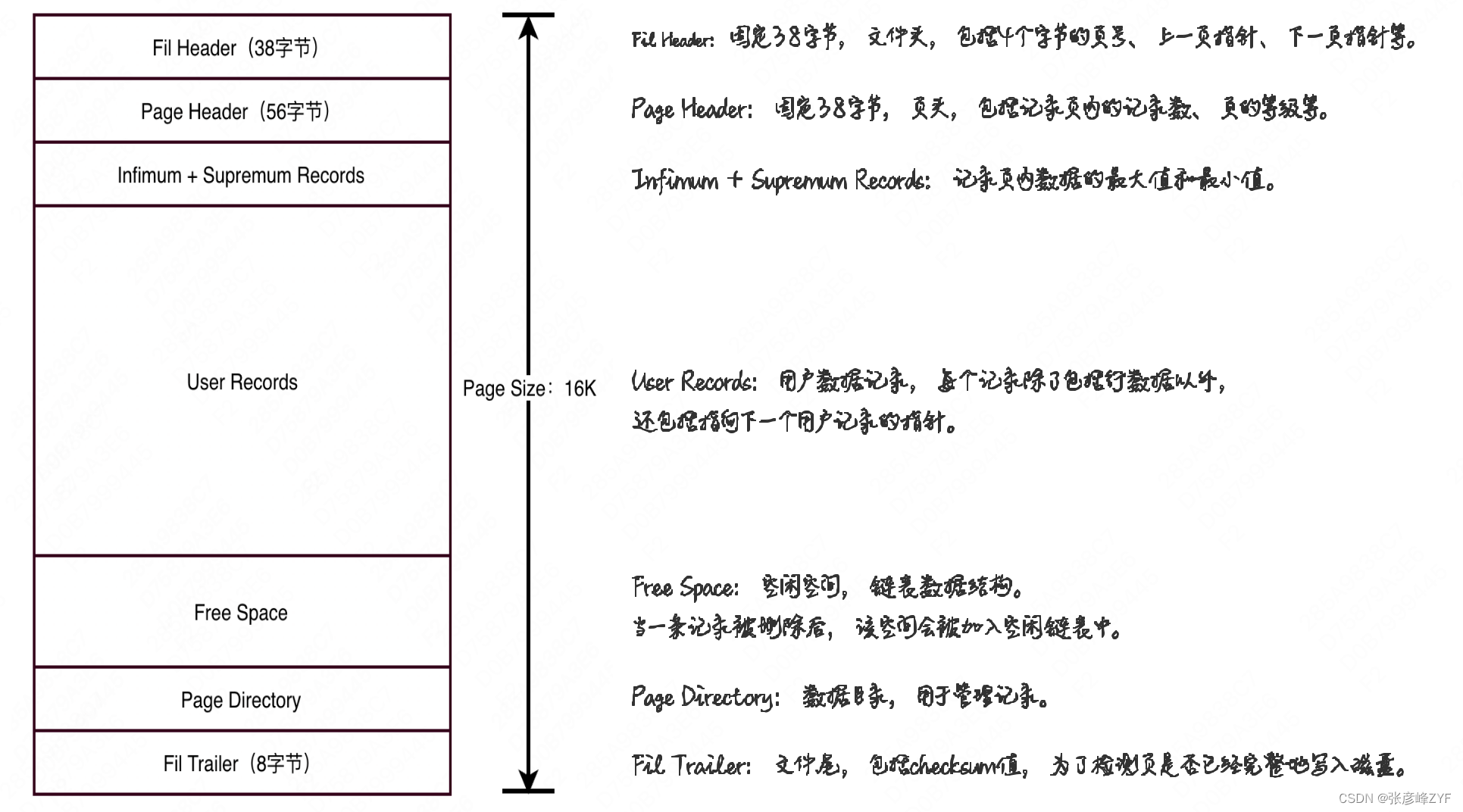
在“页”中占用空间最多是的User Records,即用于存放用户数据记录的空间。如果忽略Infimum + Supremum Records、Free Space、Page Directory使用的极少部分空间,则粗略认为用于存放数据记录的空间为:页容量 - Fil Header - Page Header - Fil Trailer = 16384 - 38 - 56 - 8 = 16282字节。按照该结果,更新公式:
![]()
通过推演计算B+树可以存放的数据行数,从侧面证明了普遍情况下B+树的树高为1-4层。
五、剖析InnoDB数据文件推导
通过以上对InnoDB页的结构解析,知道在Page Header部分存在了一个Page Level的字段,该字段表示当前页在整个索引树中的位置。
- 如果当前页位于树的叶子节点,则Page Level=0
- 如果当前页位于叶子节点的上一层,则Page Level=1
- 以此类推,假如一棵树有3层,那么:叶子节点Page Level=0,非叶节点Page Level=1,根节点Page Level=2
- 如果通过Page Level反推树高的话,可以看出树高=根节点的Page Level+1
因此如果可以在InnoDB数据文件中找到主键索引中根节点的Page Level值,就可以推算出主键索引树的树高。
找出主键索引在InnoDB数据文件中的页码
解析InnoDB数据文件中的主键索引根节点,需要先找到主键索引在数据文件中的位置。在MySQL内置的information_schema.INNODB_SYS_INDEXES、information_schema.INNODB_SYS_TABLES中包含主键索引所在的页码的信息。
SELECT
b.name as tableName, a.name as indexName, index_id, type, a.space, a.PAGE_NO
FROM
information_schema.INNODB_SYS_INDEXES a,
information_schema.INNODB_SYS_TABLES b
WHERE
a.table_id = b.table_id AND a.space <> 0 and b.name ='dbt3/lineitem' and a.name='PRIMARY';通过该SQL查询到的lineitem表主键索引,页码为3。事实上在InnoDB中所有表的主键索引所在的页码都是3,这点可以通过查询其他表证实。
计算Page Level在数据文件中的位置
每页的大小(16K),可以在数据文件中定位主键索引所在页的位置。从而进一步找到Page Level字段在数据文件中的位置。
根据InnoDB页的结构特征,可以看到Fil Header部分占用了前38个字节,而Page Level字段在Page Header部分的26字节偏移量位置,并占用2个字节。因此可得出,Page Level字段在整个页中的位置是64字节偏移量的位置。
如果想解析数据文件(lineitem.idb文件)中的Page Level字段,需要跳过的偏移量=3 * 16384(16K) + 38+ 26 = 49152+64=49216 。Page Level的值,就在该偏移量的后续2个字节中。可以看出解析出lineitem.idb文件的Page Level=2,即树高=Page Level+1=3层。
六、一般思路推导计算B+树高度总结
当我们在InnoDB存储引擎中使用B+树时,通常可以通过以下推导来计算B+树的高度:
- 首先,我们需要知道B+树的节点大小以及每个节点可以容纳的索引项数量,这可以通过InnoDB存储引擎的页面大小、节点头大小和索引项大小等参数来确定。
- 接着,我们可以根据B+树的定义来计算出根节点、中间节点和叶子节点的最小索引项数量。通常情况下,根节点和中间节点最少有两个子节点,而叶子节点的索引项数量通常是最多的。
- 然后,我们可以根据B+树的结构和定义来计算出根节点、中间节点和叶子节点的最大容纳索引项数量。对于中间节点和叶子节点,这个数量取决于节点大小和每个索引项的大小。
- 最后,我们可以使用B+树的定义和最小/最大索引项数量来计算出B+树的高度。在InnoDB存储引擎中,通常会尽量使B+树的高度趋近于最小值,以提高查询性能和减少磁盘IO开销。
需要注意的是,这只是计算B+树的高度的一种方法,不同的存储引擎和数据库可能会采用不同的优化策略,因此计算结果可能会有所不同。同时,B+树的高度也不是唯一影响查询性能的因素,还需要考虑索引选择性、数据分布情况等因素。
参考文献、书籍及链接
1.《MySQL技术内幕:InnoDB存储引擎》(第2版):MySQL技术内幕 (豆瓣)
2.《Inside InnoDB: The InnoDB Storage Engine》:MySQL :: MySQL 8.0 Reference Manual :: 15 The InnoDB Storage Engine
3.《InnoDB: The Ultimate Guide》:https://www.percona.com/blog/2018/06/05/innodb-the-ultimate-guide/
4.《InnoDB Storage Engine Internals》:https://mariadb.com/kb/en/innodb-storage-engine-internals/
5.InnoDB的数据页结构