◆了解Hive架构原理
◆了解Hive和RDBMS的对比
Hive架构原理
Hive架构原理 - 知乎
Hive 是基于 Hadoop 的数据仓库工具,它提供了类 SQL 查询语言 HQL(Hive Query Language),可以将 SQL 语句转化为 MapReduce 任务进行数据处理。
Hive 的架构可以分为三层:
- 用户接口层:Hive 提供了 CLI(Command Line Interface)和 JDBC/ODBC 接口,用户可以通过这些接口向 Hive 发送 HQL 查询语句。
- 元数据层:Hive 的元数据存储在关系型数据库中,包括表的元数据、分区信息、表的属性等。Hive 通过 Hive Metastore 组件管理元数据,支持多种元数据存储方式,如 Derby、MySQL 等。
- 执行引擎层:Hive 执行引擎将 HQL 查询语句转化为 MapReduce 任务进行数据处理。在执行引擎层中,还包括了优化器和执行器两个组件。优化器会对 HQL 查询语句进行优化,提高查询效率;执行器负责执行 MapReduce 任务,并将结果返回给用户。
总体来说,Hive 的架构与传统的关系型数据库相似,但是底层的数据存储和处理方式不同,它是基于 Hadoop 生态系统的 MapReduce 模型实现的。



HIVE和rdbms(关系数据库)区别

hive的计算引擎是hadoop的mapreduce,存储是hadoop的hdfs文件系统,适合做数据仓库
rdbms的引擎由数据库自己设计实现例如mysql的innoDB,存储用的是数据库服务器本地的文件系统
Hive并非为联机事务处理而设计,Hive并不提供实时的查询和基于行级的数据更新操作。Hive是建立在Hadoop之上的数据仓库软件工具,它提供了一系列的工具,帮助用户对大规模的数据进行提取、转换和加载,即通常所称的ETL(Extraction,Transformation,and Loading)操作。Hive可以直接访问存储在HDFS或者其他存储系统(如Hbase)中的数据,然后将这些数据组织成表的形式,在 其上执行ETL操作。 Hive的最佳使用场合是大数据集的批处理作业,例如,网络日志分析。
Hive的数据存储 Hive与传统数据库对比 - 腾讯云开发者社区-腾讯云
1、Hive中所有的数据都存储在 HDFS 中,没有专门的数据存储格式(可支持Text,SequenceFile,ParquetFile,ORC格式RCFILE等)
2、只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据。
3、Hive中包含以下数据模型:DB、Table,External Table,Partition,Bucket。 db:在hdfs中表现为${hive.metastore.warehouse.dir}目录下一个文件夹 table:在hdfs中表现所属db目录下一个文件夹 external external table:与table类似,不过其数据存放位置可以在任意指定路径 partition:在hdfs中表现为table目录下的子目录 bucket:在hdfs中表现为同一个表目录下根据hash散列之后的多个文件





一.Hive本地模式安装
Hive 本地模式安装,具体步骤如下:
1. 安装 MySQL
(1)解压安装包
1.1 解压安装包
现在已经为大家下载好了 MySQL 5.7.25 的安装包,存放在 /root/software 目录下,首先进入此目录下,使用如下命令进行解压即可使用:
tar-xvf mysql-5.7.25-1.el7.x86_64.rpm-bundle.tar将其解压到当前目录下,即 /root/software 中。
1.2 安装 MySQL 组件
安装 MySQL 组件,顺序为:
common——》libs——》libs-compat——》client——》server
使用 rpm -ivh 命令依次安装以下组件:
(1)首先安装mysql-community-common (服务器和客户端库的公共文件),使用命令:
rpm-ivh mysql-community-common-5.7.25-1.el7.x86_64.rpm(2)其次安装mysql-community-libs(MySQL数据库客户端应用程序的共享库),使用命令:
rpm-ivh mysql-community-libs-5.7.25-1.el7.x86_64.rpm(3)之后安装 mysql-community-libs-compat(MySQL 之前版本的共享兼容库),使用命令:
rpm-ivh mysql-community-libs-compat-5.7.25-1.el7.x86_64.rpm(4)之后安装 mysql-community-client(MySQL客户端应用程序和工具),使用命令:
rpm-ivh mysql-community-client-5.7.25-1.el7.x86_64.rpm(5)最后安装 mysql-community-server(数据库服务器和相关工具),使用命令:
rpm-ivh mysql-community-server-5.7.25-1.el7.x86_64.rpm1.3登录 MySQL
初始化 MySQL 的数据库
/usr/sbin/mysqld --initialize-insecure --user=mysql
启动 MySQL 服务
使用如下命令开启 MySQL 服务,让其在后台运行,说明:一定要加“&”,才能把脚本放到后台运行
/usr/sbin/mysqld --user=mysql &
登录 MySQL
使用root用户无密码登录 MySQL:
mysql -uroot
重置 MySQL 密码(没用)
在 5.7 版本后,我们可以使用 alter user...identified by命令把root用户的密码修改为“123456”,具体命令如下所示
alter user 'root'@'localhost' identified by '123456';
修改完成,使用exit或者quit命令退出 MySQL,重新登录验证密码是否修改成功,具体命令如下所示:
mysql -uroot -p123456

增加远程登录权限
当我们的帐号不允许从远程登录,只能在localhost连接时。这个时候只要在 MySQL 服务器上,更改mysql 数据库里的 user 表里的 host 项,从localhost改成%即可实现用户远程登录。
(1)首先我们来查看 mysql 数据库下的 user表信息
use mysql; # 切换成mysql数据库
select user,host from user; # 查询用户信息
可以看到在user表中已创建的root用户。host字段表示登录的主机,其值可以用IP地址,也可用主机名。
(2)实现远程连接(授权法)
将 host 字段的值改为%就表示在任何客户端机器上能以root用户登录到 MySQL 服务器,建议在开发时设为%。
# 设置远程登录权限
mysql> updateuserset host='%'where host='localhost';
# 刷新配置信息
mysql> flushprivileges;
2. Hive 安装部署
你需要在安装 Hive 之前安装并配置好 Hadoop。如果您还没有安装 Hadoop,请先安装 Hadoop,然后再安装 Hive。
可以参考我以前的教程
https://blog.csdn.net/m0_69379600/category_12306373.html
(1)解压安装包
现在已经为大家下载好了 hive2.3.4 的安装包,存放在 /root/software 目录下,首先进入此目录下,使用如下命令进行解压即可使用:
tar -zxvf apache-hive-2.3.4-bin.tar.gz
将其解压到当前目录下,即 /root/software 中
(2)配置环境变量:/etc/profile 文件
1.首先打开 /etc/profile 文件:
vim /etc/profile
2.将以下内容添加到配置文件的底部,添加完成输入“:wq”保存退出:
# 配置Hive的安装目录
export HIVE_HOME=/root/software/apache-hive-2.3.4-bin
# 在原PATH的基础上加入Hive的bin目录,环境变量
export PATH=$PATH:$HIVE_HOME/bin
3.让配置文件立即生效,使用如下命令:
source /etc/profile
4.检测 Hive 环境变量是否设置成功,使用如下命令查看 Hive 版本:
hive --version
执行此命令后,若是出现 Hive 版本信息说明配置成功:

(3)修改配置文件hive-env.sh
Hive中,hive-env.sh是一个用于设置环境变量和其他配置选项的脚本文件。
修改该文件可能是为了更改某些Hive的配置选项,例如JVM选项、Hadoop配置选项或其他选项,以确保Hive在特定环境下运行良好。可能需要修改该文件,以便Hive能够正确地连接到其他服务或资源,并且可以正常地读取和写入数据。
具体来说,修改配置文件hive-env.sh可能涉及编辑该文件并更改其中的一些变量值或添加新的变量。这些更改可能需要在启动Hive之前进行,以确保更改在Hive启动时生效。
具体步骤
切换到 ${HIVE_HOME}/conf 目录下,将 hive-env.sh.template 文件复制一份并重命名为 hive-env.sh:
cp hive-env.sh.template hive-env.sh
修改完成,使用 vi 编辑器进行编辑:
vim hive-env.sh
在文件中配置 HADOOP_HOME、HIVE_CONF_DIR 以及HIVE_AUX_JARS_PATH 参数:
# 配置Hadoop安装路径
HADOOP_HOME=/root/software/hadoop-2.7.7
# 配置Hive配置文件存放路径
export HIVE_CONF_DIR=/root/software/apache-hive-2.3.4-bin/conf
# 配置Hive运行资源库路径
export HIVE_AUX_JARS_PATH=/root/software/apache-hive-2.3.4-bin/lib
配置完成,输入“:wq”保存退出。
3. Hive元数据配置到MySQL
(1)驱动拷贝:
将MySQL 驱动包 mysql-connector-java-5.1.47-bin.jar 拷贝到 ${HIVE_HOME}/lib 目录下。
将/root/software目录下的 MySQL 驱动包 mysql-connector-java-5.1.47-bin.jar 拷贝到 ${HIVE_HOME}/lib 目录下。
cd /root/software/
cp mysql-connector-java-5.1.47-bin.jar apache-hive-2.3.4-bin/lib/
(2)配置 Metastore到MySQL:hive-site.xml
在${HIVE_HOME}/conf目录下创建一个名为hive-site.xml的文件,并使用vi编辑器进行编辑:
touch hive-site.xml
vim hive-site.xml
根据官方文档配置参数(难点)
(AdminManual Metastore Administration - Apache Hive - Apache Software Foundation),拷贝数据到 hive-site.xml 文件中:
配置成自己的
<configuration>
<!-- 连接元数据库的链接信息 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hivedb?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<!-- 连接数据库驱动 -->
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<!-- 连接数据库用户名称 -->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<!-- 连接数据库用户密码 -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password to use against metastore database</description>
</property>
</configuration>
(3)初始化元数据库
如果使用的是 2.x 版本的 Hive,那么就必须手动初始化元数据库。 使用 schematool -dbType <db type> -initSchema 命令进行初始化、
schematool -dbType mysql -initSchema
若是出现“schemaTool completed”则初始化成功

(4)Hive 连接
在任意目录下使用 Hive 的三种连接方式之一:CLI 启动 Hive。由于已经在环境变量中配置了 HIVE_HOME ,所以这里直接在命令行执行如下命令即可:
hive
或者
hive --service cli
效果如下图所示:
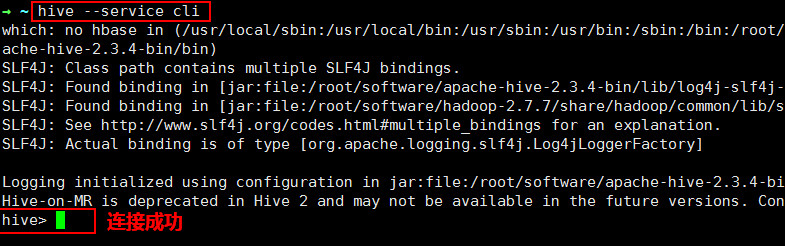
可以使用如下命令退出 Hive 客户端:
hive> exit;
或者
hive> quit;