什么是图数据库Neo4j
所谓的图数据库一般由节点和关系构成,neo4j是其中的一种
在寻求数据的关联性中优于传统数据库mysql
且neo4j支持上亿级别的节点和关系
传统图运算一般在内存中进行,无法处理整个知识图谱,neo4j可以在磁盘中完成图运算
因此在问答系统中常常使用neo4j作为数据的载体,用于快速搜索关键词信息
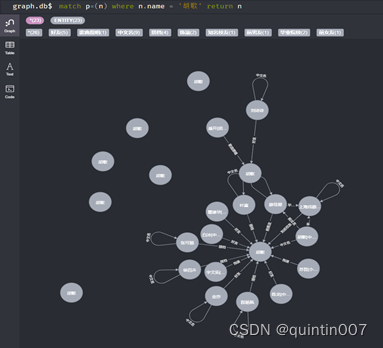
创建节点:
create (n:人名{name:小明了)-[p:年龄{name:'年龄了]->(m:年龄{name:183)

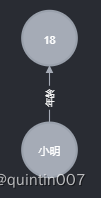
展示一级关系
match p-(n)-[ ] ->(m) where n.name ='小明’return n,m
展示一级至二级间的关系
match p=(n)-[*1…2]->(m) where n.name ='习近’return n,m
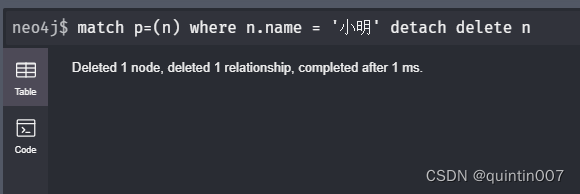
删除节点
match p=(n) where nname =’ ’ detach delete n
在结点和关系数量庞大的图中,有更快的数据库操作速度
支持分布式存取,能够利用集群来扩展内存和磁盘容量
支持分布式高可用性,可以支持大规模的
数据增长数据安全可靠,支持数据的实时备份
通过Cypher语句,使得图数据的操作与展示更加直观
构建Neo4j支持格式的数据
一般数据导入至Neo4j有两种方式:
1、使用固定格式的csv进行数据加载
2、使用代码的方式将数据进行导入
两种方式各有优缺点,使用CS进行数据导入更加迅速,但相对固定:使用代码方式导入则更加灵活,相对处理速度有一定瓶颈。
使用Csv进行导入的话,一般需要两份数据,分别是entity.csv用来定义实体;relationship.csv用来描述关系,因此需要对于现有数据进行再处理。
此为entity.csv的样例

此为relationship.csv的样例
数据处理前的准备
import csv
from tqdm import tqdm
entity = open(‘entity.csv’,w’encoding=utf-8newline=“)
relationship =open(relationship.csv,wencoding='utf-8newline=”)
#开启2个记录器
entity writer = csv.writer(entity)
relationship writer = csv.writer(relationship)
#以下是neo4i所接受的两个csv,所需的列名
entity writer.writerow([:IDname:LABELT)relationship writer.writerow([:START IDname:ENDIDTYPET)
正式写数据
data = pdread csv(file name,chunksize=100000)
for ind,i in enumerate(data):
for d in tqdm(range(len(0)):
d = i.loc[d]
entity writer.writerow([hash(d.实体)d.实体ENTITY)
entity writer.writerow([hash(d.值)d值ENTITYT)
relationship writer.writerow([hash(d.实体)d.属性hash(d.值)RELATIONSHIPT)
break