点击上方“Python爬虫与数据挖掘”,进行关注
回复“书籍”即可获赠Python从入门到进阶共10本电子书
今
日
鸡
汤
空山新雨后,天气晚来秋。
大家好,我是皮皮。
一、前言
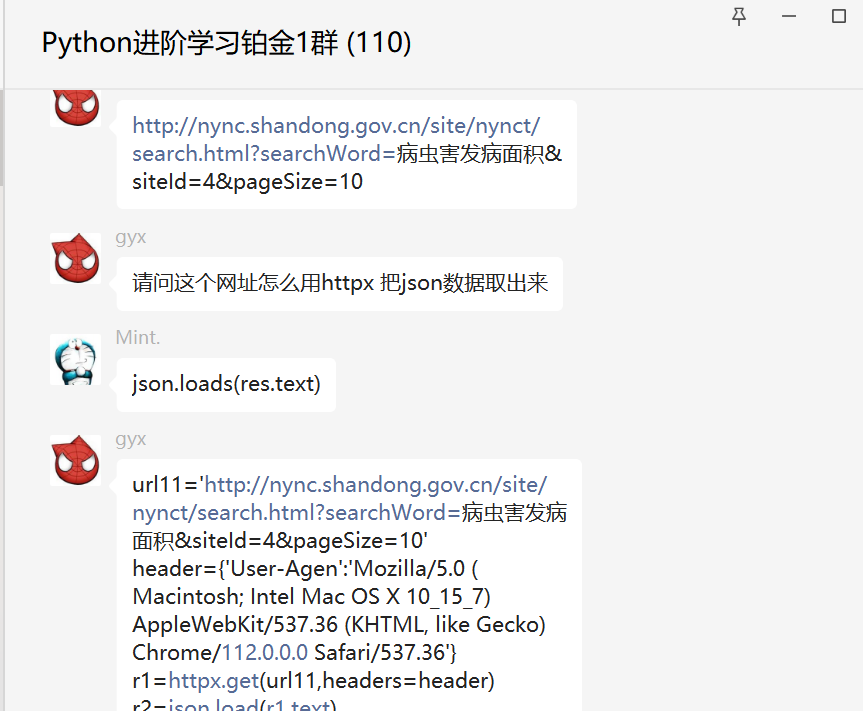
前几天在Python铂金群【gyx】问了一个Python网络爬虫处理的问题,这里拿出来给大家分享下。
二、实现过程
这里从返回的响应状态码来看是200,说明数据是拿到了,只不过在处理的 时候,可能出现了点问题。
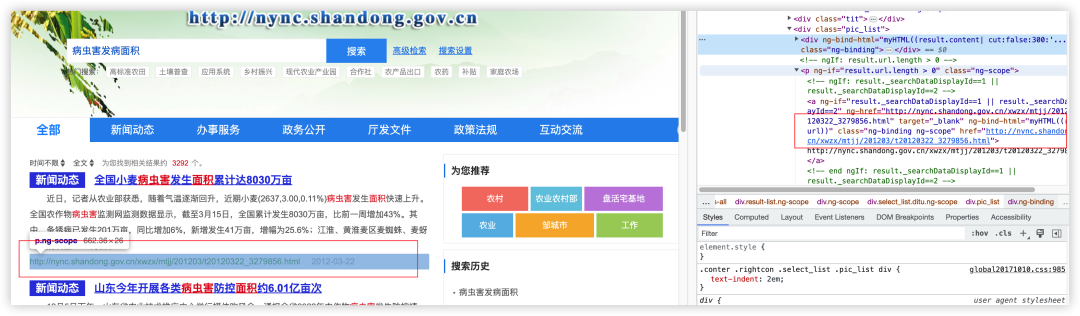
后来粉丝自己截图了网页的数据,如下图所示:
后来【瑜亮老师】给出了相对应的代码,如下所示:
import requests
headers = {
"Connection": "keep-alive",
"Pragma": "no-cache",
"Cache-Control": "no-cache",
"Accept": "application/json, text/plain, */*",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36",
"Referer": "http://nync.shandong.gov.cn/site/nynct/search.html?searchWord=%E7%97%85%E8%99%AB%E5%AE%B3%E5%8F%91%E7%97%85%E9%9D%A2%E7%A7%AF&siteId=4&pageSize=10",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8"
"Cookie": "这里放你的cookie"
}
url = "http://nync.shandong.gov.cn/igs/front/search.jhtml"
params = {
"code": "1e80abdd60da4e7d8afeacc2e6c5a79d",
"pageSize": "10",
"queryAll": "true",
"searchWord": "病虫害发病面积",
"siteId": "4"
}
response = requests.get(url, headers=headers, cookies=cookies, params=params, verify=False)
resp = json.loads(response.text.replace('<em>', '').replace('</em>', '').replace(' ', '').replace('\\n', '').replace('\u3000', ''))
results = resp["page"]["content"]
hrefs = [i['url'] for i in results]
print(hrefs)顺利的解决了粉丝问题。
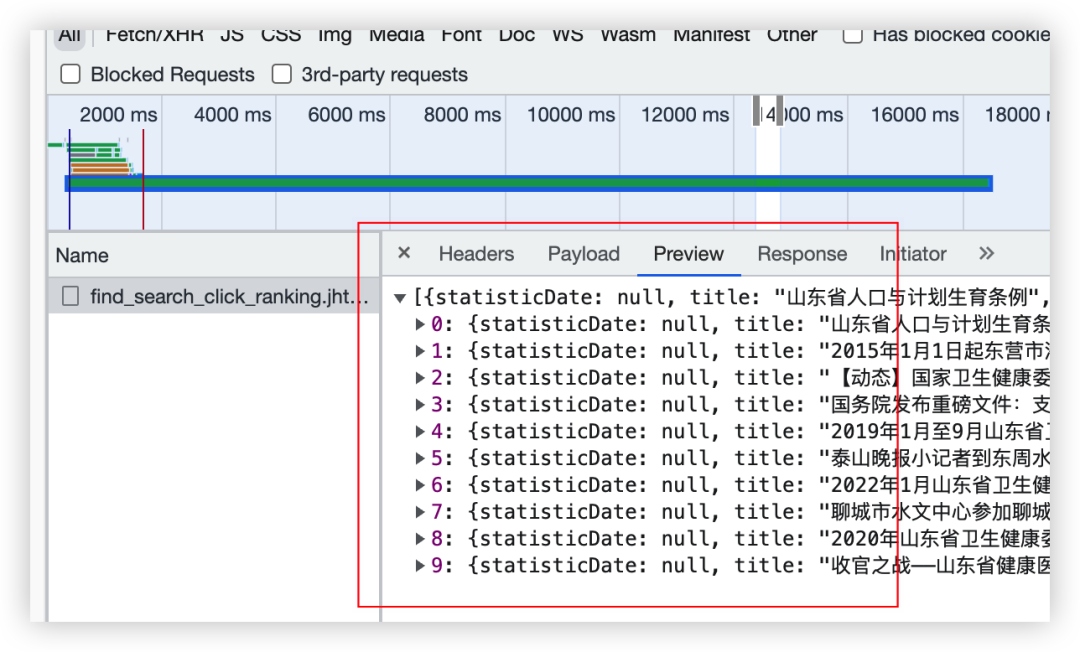
当然了,后来【eric】也给了一个代码,如下所示:
import requests
headers = {
"Accept": "application/json, text/plain, */*",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"Connection": "keep-alive",
"Referer": "http://nync.shandong.gov.cn/site/nynct/search.html?searchWord=%E7%97%85%E8%99%AB%E5%AE%B3%E5%8F%91%E7%97%85%E9%9D%A2%E7%A7%AF&siteId=4&pageSize=10",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 Edg/112.0.1722.48"
}
cookies = {
"JSESSIONID": "494022BEAC070E72F5F986E7E888ACAE",
"token": "3c8f42b3-2e8b-4b5d-8f41-34238d7f9d22",
"uuid": "3c8f42b3-2e8b-4b5d-8f41-34238d7f9d22"
}
url = "http://nync.shandong.gov.cn/igs/front/statistics/find_search_click_ranking.jhtml"
params = {
"siteId": "4"
}
response = requests.get(url, headers=headers, cookies=cookies, params=params, verify=False)
print(response.json())
# print(response)也是可以拿到对应数据的,如下所示:
三、总结
大家好,我是皮皮。这篇文章主要盘点了一个Python网络爬虫处理的问题,文中针对该问题,给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【gyx】提问,感谢【瑜亮老师】、【eric】给出的思路和代码解析,感谢【Mint】、【冫马讠成】等人参与学习交流。
【提问补充】温馨提示,大家在群里提问的时候。可以注意下面几点:如果涉及到大文件数据,可以数据脱敏后,发点demo数据来(小文件的意思),然后贴点代码(可以复制的那种),记得发报错截图(截全)。代码不多的话,直接发代码文字即可,代码超过50行这样的话,发个.py文件就行。

大家在学习过程中如果有遇到问题,欢迎随时联系我解决(我的微信:pdcfighting1),应粉丝要求,我创建了一些高质量的Python付费学习交流群和付费接单群,欢迎大家加入我的Python学习交流群和接单群!

小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。

------------------- End -------------------
往期精彩文章推荐:
if a and b and c and d:这种代码有优雅的写法吗?
Pycharm和Python到底啥关系?
都说chatGPT编程怎么怎么厉害,今天试了一下,有个静态网页,chatGPT居然没搞定?
站不住就准备加仓,这个pandas语句该咋写?

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~~