所谓集群就是通过高速网络将很多服务器集中起来一起提供一种服务,在客户端看起来就是只有一个服务器
任务调度是集群中的核心系统
HPC高性能计算集群
LB负载均衡
HA高可用
LVS工作模式
NAT 网络地址转换 -m
DR 路由模式 节点需要VIP -g
TUN 隧道模式 -i
调度算法
轮询rr
加权轮询wrb
最少连接lc
加权最少连接wlc
LVS-NAT模式
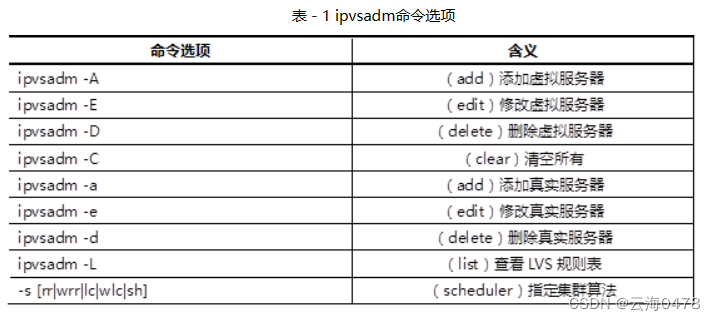

由调度器负责接受转发,访问量大会造成调度器瓶颈
安装ipvsadm创建LVS虚拟集群服务器
[root@proxy ~]# yum -y install ipvsadm
[root@proxy ~]# ipvsadm -A -t 192.168.88.5:80 -s wrr
[root@proxy ~]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.88.5:80 wrr为集群添加若干real server
开启路由转发
[root@proxy ~]# echo 1 > /proc/sys/net/ipv4/ip_forward #开启路由转发,临时有效
[root@proxy ~]# cat /proc/sys/net/ipv4/ip_forward #查看效果
1
[root@proxy ~]# echo "net.ipv4.ip_forward = 1" >> /etc/sysctl.confLVS-DR模式(地址欺骗)
DR配置与后端一样的IP地址,mac地址漂移实现
配置网卡
[root@web1 ~]# cd /etc/sysconfig/network-scripts/
[root@web1 ~]# cp ifcfg-lo ifcfg-lo:0
[root@web1 ~]# vim ifcfg-lo:0
DEVICE=lo:0
#设备名称
IPADDR=192.168.88.15
#IP地址
NETMASK=255.255.255.255
#子网掩码
NETWORK=192.168.88.15
#网络地址
BROADCAST=192.168.88.15
#广播地址
ONBOOT=yes
#开机是否激活本网卡
NAME=lo:0
#网卡名称ARP广播问题(默认肯定会出现地址冲突)
sysctl.conf文件写入这下面四行的主要目的就是访问192.168.88.X的数据包,只有调度器会响应,其他主机都不做任何响应,这样防止地址冲突的问题
#文件末尾手动写入如下4行内容,英语词汇:ignore(忽略、忽视),announce(宣告、广播通知)
net.ipv4.conf.all.arp_ignore = 1
net.ipv4.conf.lo.arp_ignore = 1
net.ipv4.conf.lo.arp_announce = 2
net.ipv4.conf.all.arp_announce = 2
#当有arp广播问谁是192.168.88.15时,本机忽略该ARP广播,不做任何回应(防止进站冲突)
#本机不要向外宣告自己的lo回环地址是192.168.88.15(防止出站冲突)
[root@web1 ~]# sysctl -pproxy调度器安装软件并部署LVS-DR模式调度器
[root@proxy ~]# yum -y install ipvsadm
[root@proxy ~]# ipvsadm -C #清空所有规则
[root@proxy ~]# ipvsadm -A -t 192.168.88.15:80 -s wrr
## -A(add)是创建添加虚拟服务器集群
# -t(tcp)后面指定集群VIP的地址和端口,协议是tcp协议
# -s后面指定调度算法,如rr(轮询)、wrr(加权轮询)、lc(最少连接)、wlc(加权最少连接)等等
[root@proxy ~]# ipvsadm -a -t 192.168.88.15:80 -r 192.168.88.100 -g -w 1
[root@proxy ~]# ipvsadm -a -t 192.168.88.15:80 -r 192.168.88.200 -g -w 1
#-a(add)往虚拟服务器集群中添加后端真实服务器IP,指定往-t 192.168.88.15:80这个集群中添加
#-r(real)后面跟后端真实服务器的IP和端口,这里不写端口默认是80端口
#-w(weight)指定服务器的权重,权重越大被访问的次数越多,英语词汇:weight(重量,分量)
#-m指定集群工作模式为NAT模式,如果是-g则代表使用DR模式,-i代表TUN模式
[root@proxy ~]# ipvsadm -Ln
TCP 192.168.88.15:80 wrr
-> 192.168.88.100:80 Route 1 0 0
-> 192.168.88.200:80 Route 1 0 0默认LVS不带健康检查功能,需要自己手动编写动态检测脚本,实现该功能
[root@proxy ~]# vim check.sh
#!/bin/bash
VIP=192.168.88.15:80
RIP1=192.168.88.100
RIP2=192.168.88.200
while :
do
for IP in $RIP1 $RIP2
do
curl -s http://$IP &>/dev/null
if [ $? -eq 0 ];then
ipvsadm -Ln |grep -q $IP || ipvsadm -a -t $VIP -r $IP
else
ipvsadm -Ln |grep -q $IP && ipvsadm -d -t $VIP -r $IP
fi
done
sleep 1
doneansible上部署NAT
[root@director mywork]# vim ~/mywork/lvs_nat.yml
---
#远程web1和web2安装httpd,启动服务,设置开机启动启动
#使用copy模块的content参数可以在没有文件的情况下,直接将文件内容拷贝到目标主机
#content指定文件内容,{{ansible_eth1.ipv4.address}}是fact变量,\n代表回车符
#dest指定拷贝内容到哪个文件中
- hosts: web
tasks:
- yum:
name: httpd
- service:
name: httpd
state: started
enabled: yes
- copy:
content: "{{ansible_eth1.ipv4.address}}\n"
dest: /var/www/html/index.html
- shell: nmcli con modify eth1 ipv4.method manual ipv4.gateway 192.168.99.8
- shell: nmcli con up eth1
#远程director主机安装ipvsadm软件包,使用命令创建lvs集群
#ipvsadm -C清理所有规则,-A创建虚拟服务器,-a添加真实后端服务器到虚拟服务器
- hosts: 192.168.99.8
tasks:
- yum:
name: ipvsadm
- shell: ipvsadm -C
- shell: ipvsadm -A -t 192.168.88.8:80 -s rr
- shell: ipvsadm -a -t 192.168.88.8:80 -r 192.168.99.11 -m
- shell: ipvsadm -a -t 192.168.88.8:80 -r 192.168.99.22 -mkeepalived(高可用VRRP)vip地址漂移
与路由交换vrrp一样
运行原理
当keepalived检测每个服务节点状态,有问题将故障节点剔除,恢复后自动加入,无需人工干预
yum install -y keepalived
[root@proxy ~]# vim /etc/keepalived/keepalived.conf
global_defs {
router_id lvs1 #12行,设置路由ID号(实验需要修改)
vrrp_iptables #13行,清除防火墙的拦截规则(实验需要修改,手动添加)
}
vrrp_instance VI_1 {
state MASTER #21行,主服务器为MASTER
interface eth0 #22行,定义网络接口(不能照抄网卡名)
virtual_router_id 51 #23行,主辅VRID号必须一致
priority 100 #24行,服务器优先级
advert_int 1
authentication {
auth_type pass
auth_pass 1111
}
virtual_ipaddress { #30~32行,配置VIP(实验需要修改)
192.168.88.15/24
}
}
virtual_server 192.168.88.15 80 { #设置ipvsadm的VIP规则(实验需要修改)
delay_loop 6 #默认健康检查延迟6秒
lb_algo rr #设置LVS调度算法为RR
lb_kind DR #设置LVS的模式为DR(实验需要修改)
#persistence_timeout 50 #(实验需要删除)
#注意persistence_timeout的作用是保持连接
#开启后,客户端在一定时间内(50秒)始终访问相同服务器
protocol TCP #TCP协议
real_server 192.168.88.100 80 { #设置后端web服务器真实IP(实验需要修改)
weight 1 #设置权重为1
TCP_CHECK { #对后台real_server做健康检查(实验需要修改)
connect_timeout 3 #健康检查的超时时间3秒
nb_get_retry 3 #健康检查的重试次数3次
delay_before_retry 3 #健康检查的间隔时间3秒
}
}
real_server 192.168.88.200 80 { #设置后端web服务器真实IP(实验需要修改)
weight 2 #设置权重为2
TCP_CHECK { #对后台real_server做健康检查(实验需要修改)
connect_timeout 3 #健康检查的超时时间3秒
nb_get_retry 3 #健康检查的重试次数3次
delay_before_retry 3 #健康检查的间隔时间3秒
}
}
}HAProxy
http(7层) tcp(4层) health三种工作模式
[root@proxy ~]# yum -y install haproxy
[root@proxy ~]# vim /etc/haproxy/haproxy.cfg
global
log 127.0.0.1 local2 ##[err warning info debug]
pidfile /var/run/haproxy.pid ##haproxy的pid存放路径
user haproxy
group haproxy
daemon ##以后台进程的方式启动服务
defaults
mode http ##默认的模式mode { tcp|http|health }
option dontlognull ##不记录健康检查的日志信息
option httpclose ##每次请求完毕后主动关闭http通道
option httplog ##日志类别http日志格式
option redispatch ##当某个服务器挂掉后强制定向到其他健康服务器
timeout client 300000 ##客户端连接超时,默认毫秒,也可以加时间单位
timeout server 300000 ##服务器连接超时
maxconn 3000 ##最大连接数
retries 3 ##3次连接失败就认为服务不可用,也可以通过后面设置
listen websrv-rewrite 0.0.0.0:80
balance roundrobin
server web1 192.168.99.100:80 check inter 2000 rise 2 fall 5
server web2 192.168.99.200:80 check inter 2000 rise 2 fall 5
#定义集群,listen后面的名称任意,端口为80
#balance指定调度算法为轮询(不能用简写的rr)
#server指定后端真实服务器,web1和web2的名称可以任意
#check代表健康检查,inter设定健康检查的时间间隔,rise定义成功次数,fall定义失败次数
listen stats *:1080 #监听端口
stats refresh 30s #统计页面自动刷新时间
stats uri /stats #统计页面url
stats realm Haproxy Manager #进入管理解面查看状态信息
stats auth admin:admin #统计页面用户名和密码设置Queue队列数据的信息(当前队列数量,最大值,队列限制数量);
Session rate每秒会话率(当前值,最大值,限制数量);
Sessions总会话量(当前值,最大值,总量,Lbtot: total number of times a server was selected选中一台服务器所用的总时间);
Bytes(入站、出站流量);
Denied(拒绝请求、拒绝回应);
Errors(错误请求、错误连接、错误回应);
Warnings(重新尝试警告retry、重新连接redispatches);
Server(状态、最后检查的时间(多久前执行的最后一次检查)、权重、备份服务器数量、down机服务器数量、down机时长)
集群调度软件对比
nginx
工作在7层,可以对http做分流策略
1.9版本开始支持4层代理
zh正则表达式比HAProxy强大
并发量几万次
7层代理仅支持http https mail 协议应用面小
监控检查仅通过端口,无法使用url检查
LVS
负载能力强,工作在4层,对内存cpu消耗低
pe配置性低,减少人为错误
应用面广
不支持正则表达式,不能实现动静分离
如果网站架构庞大,lvs-dr配置繁琐
HAProxy
支持session、cookie功能
ke可以用通过url健康检查
效率负载,高于nginx 低于LVS
支持TCP,可以对mysql进行负载均衡
dia调度算法丰富
正则弱于nginx
日志依赖于syslog
Ceph
分布式是一种独特的系统架构,由一组网络进行通信,完成共同的任务协调工作计算机节点组成
分布式系统是为了用廉价的,普通的机器,完成单个计算机无法完成的计算,存储任务
目的就是利用更多的机器,处理更多的数据
ceph就是一个分布式存储系统,具有高扩展,高可用,高性能支持EB级别的存储,,软件定义存储
Ceph组件
OSD 存储设备E
Monitors 集群监控组件
RGW 对象存储网关
MDS 存放文件系统的元数据
Client 客户端
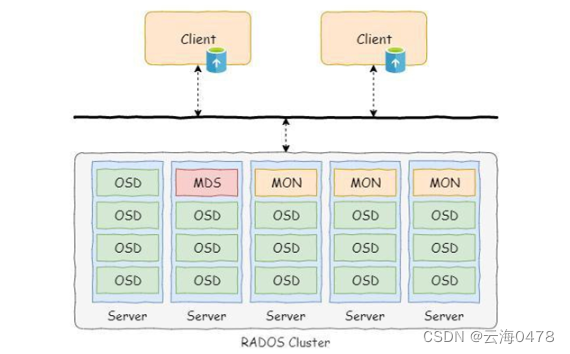
默认3副本 基于软件实现 EB级别存储 每个组件都可扩展
ceph组件对数据进行切割
添加ceph yum源
添加硬盘
配置免密连接
[root@node1 ~]# ssh-keygen -f /root/.ssh/id_rsa -N ''
#-f后面跟密钥的文件名称(希望创建密钥到哪个文件)
#-N ''代表不给密钥配置密钥(不能给密钥配置密码)
[root@node1 ~]# for i in 10 11 12 13
do
ssh-copy-id 192.168.88.$i
done修改/etc/hosts并同步到所有主机
NTP同步
部署
yum -y install ceph-deploy
[root@node1 ~]# mkdir ceph-cluster
[root@node1 ~]# cd ceph-cluster/
[root@node1 ceph-cluster]# ceph-deploy new node1 node2 node3
[root@node1 ceph-cluster]# vim ceph.conf #不要修改原始内容,在文件末尾添加一行
rbd_default_features = 1
#默认开启COW分层快照的功能
[root@node1 ceph-cluster]# ceph-deploy mon create-initial
#配置文件ceph.conf中有三个mon的IP,ceph-deploy脚本知道自己应该远程谁
[root@node1 ceph-cluster]# systemctl status ceph-mon@node1
[root@node2 ~]# systemctl status ceph-mon@node2
[root@node3 ~]# systemctl status ceph-mon@node3
#备注:管理员可以自己启动(start)、重启(restart)、关闭(stop),查看状态(status).
#提醒:这些服务在30分钟只能启动3次,超过就报错.
#StartLimitInterval=30min
#StartLimitBurst=3
#在这个文件中有定义/usr/lib/systemd/system/ceph-mon@.service
#如果修改该文件,需要执行命令# systemctl daemon-reload重新加载配置
[root@node1 ceph-cluster]# ceph -s
[root@node1 ceph-cluster]# ceph-deploy disk zap node1:vdb node1:vdc
[root@node1 ceph-cluster]# ceph-deploy disk zap node2:vdb node2:vdc
[root@node1 ceph-cluster]# ceph-deploy disk zap node3:vdb node3:vdc
#相当于ssh 远程node1,在node1执行parted /dev/vdb mktable gpt
#其他主机都是一样的操作
#ceph-deploy是个脚本,这个脚本会自动ssh远程自动创建gpt分区CephFS
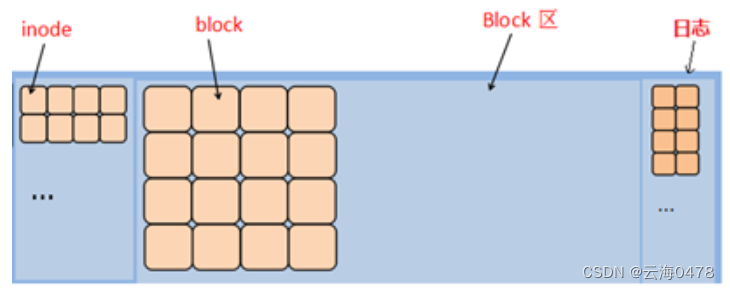
MDS存放文件系统的元数据所以必须有MDS
一个文件系统是由inode和block两部分组成,inode存储文件的描述信息(metadata元数据),block中存储真正的数据
PG是一个逻辑概念,没有对应的物质形态,是为了方便管理OSD而设计的概念,可以把PG想象成为是目录,可以创建32个目录来存放OSD,也可以创建64个目录来存放OSD
直接mount到本地
[root@node3 ~]# yum -y install ceph-mds
[root@node1 ~]# cd /root/ceph-cluster
#该目录,是最早部署ceph集群时,创建的目录
[root@node1 ceph-cluster]# ceph-deploy mds create node3
#远程nod3,拷贝集群配置文件,启动mds服务
[root@node3 ~]# ceph osd pool create cephfs_data 64
#创建存储池,共享池的名称为cephfs_data,对应有64个PG
#共享池名称可以任意
[root@node3 ~]# ceph osd pool create cephfs_metadata 64
#创建存储池,共享池的名称为cephfs_metadata,对应有64个PG
[root@node3 ~]# ceph fs new myfs1 cephfs_metadata cephfs_data
#myfs1是名称,名称可以任意,注意,先写metadata池,再写data池
#fs是filesystem的缩写,filesystem中文是文件系统
#默认,只能创建1个文件系统,多余的会报错
[root@node3 ~]# ceph fs ls
name: myfs1, metadata pool: cephfs_metadata, data pools: [cephfs_data ]
[root@client ~]# mount -t ceph 192.168.88.11:6789:/ /mnt \
-o name=admin,secret=AQBTsdRapUxBKRAANXtteNUyoEmQHveb75bISg==
#注意:-t(type)指定文件系统类型,文件系统类型为ceph
#-o(option)指定mount挂载命令的选项,选项包括name账户名和secret密码
#192.168.88.11为MON节点的IP(不是MDS节点),6789是MON服务的端口号
#admin是用户名,secret后面是密钥
#密钥可以在/etc/ceph/ceph.client.admin.keyring中找到










![[架构之路-158]-《软考-系统分析师》-13-系统设计 - 高内聚低耦合详解、图解以及技术手段](https://img-blog.csdnimg.cn/img_convert/1b5eb161416b6c7a9e0917256b5f6f17.png)
