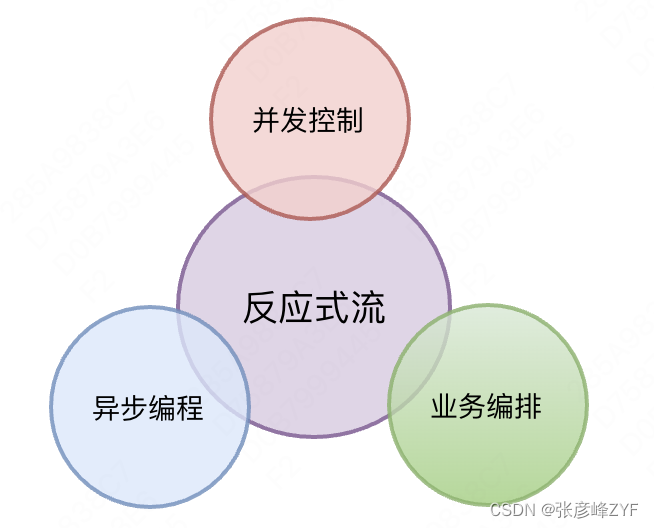
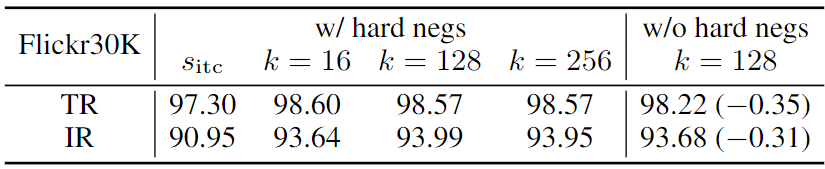目录
一、Reactive Streams基本知识
(一)基本介绍
(二)反应式流的特点
基本特性1:事件驱动&变化传递
基本特性2:数据流
基本特性3:声明式
高级特性1:流量控制(回压)
高级特性2:异步边界
(三)反应式流接口
二、业务应用举例代码展示
(一) 具体框架引入介绍
(二) 业务应用代码举例展示
举例一:用于读取文件内容并将其输出到控制台
举例二:从 Twitter 实时数据流中读取推文并将其输出到控制台
举例三:获取商品信息并将其按照指定条件进行排序并输出到控制台
三、Reactor原理分析
调用关系
执行过程
回压
异步边界
四、业务应用中的建议
参考文献、书籍及链接
一、Reactive Streams基本知识
(一)基本介绍
Reactive Streams是一种基于异步流处理的标准化规范,旨在使流处理更加可靠、高效和响应式。
Reactive Streams的核心思想是让发布者(Publisher)和订阅者(Subscriber)之间进行异步流处理,以实现非阻塞的响应式应用程序。发布者可以产生任意数量的元素并将其发送到订阅者,而订阅者则可以以异步方式处理这些元素。Reactive Streams还定义了一些接口和协议,以确保流处理的正确性和可靠性,例如:
- Publisher:定义了生产元素并将其发送给订阅者的方法。
- Subscriber:定义了接收元素并进行处理的方法。
- Subscription:定义了订阅者和发布者之间的协议,包括请求元素和取消订阅等。
- Processor:定义了同时实现Publisher和Subscriber接口的中间件,它可以对元素进行转换或者过滤等操作。
Reactive Streams的应用场景非常广泛,可以应用于任何需要处理大量数据流的场景,例如网络通信、数据库访问、图像处理等。它也是许多流处理框架和库的基础,例如Spring Reactor、Akka Streams等。
(二)反应式流的特点
反应式流的特点简单来说就是:基本特性(变化传递 + 数据流 + 声明式) + 高级特性(非阻塞回压 + 异步边界)
基本特性1:事件驱动&变化传递
反应式流的核心就是事件驱动和变化传递,当发布者生产一个数据后,数据会被push到接下来的组件当中,不断的在组件中进行传递,最后到达最终的消费者。
什么是事件驱动和变化传递呢?先举个经典的案例

如图所示,在单元格C1中输入公式“=SUM(A1:B1)”,那么无论单元格A1或B1中的数据如何变化,都会马上导致它们的和C1发生变化。具体来讲,数据变化时,我们无需去控制C1进行数据和计算(不用调用”C1 = SUM(A1:B1)“这样的程序),A1和B1的变化,马上会体现到C1上,说明求和这个动作是事件驱动的,事件驱动能够使组件具有时间维度上的解耦能力,使开发者更容易进行并发编程。
那么什么是变化传递呢?将Excel的例子扩展一下,如下图行3,将D1设置为SUM(B1:C1),E1设置为SUM(C1:D1)...依此类推,每个值都依赖其前两个值的大小,那么一个斐波那契数列就产生了,当A1或B1发生变化时,会像多米诺骨牌一样,导致直接和间接引用它的数据发生变化,这就是变化传递。
基本特性2:数据流
变化传递等信息是基于数据流进行的。
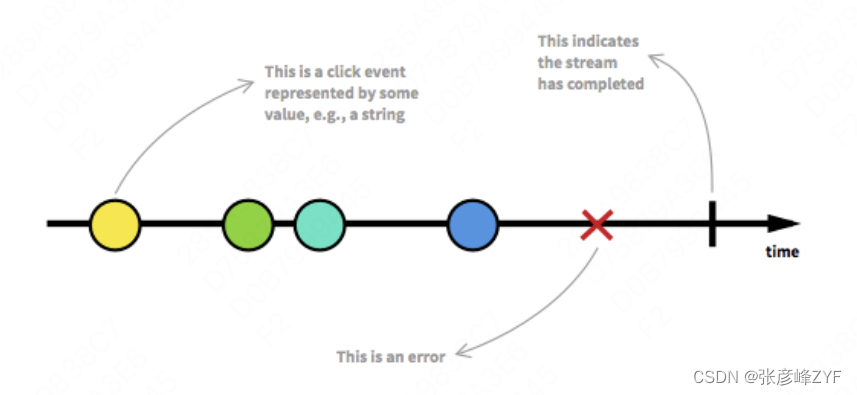
如图所示,一个数据流是一个按时间排序的即将发生的事件(Ongoing events ordered in time)的序列。这个序列上包含了开始事件、数据处理事件、错误事件和结束事件。
当一个click事件产生时,我们只需要观察这个数据流上的事件,就能根据这些事件的发生触发一定的函数,这个过程就像是观察者模式。在数据流上,每个事件都会作为生产者生产数据,对应这些事件都会存在一个或多个观察者。
再回到Excel的例子中,在行3中定义了一个简单的斐波那契数列,包含了开始事件、数据处理事件和一个简单的结束事件(G3),当A1或B1发生变化,相应的观察者C1发生变化,并引起C1的观察者D1发生变化,依此类推。A1和B1只有一个观察者,而B1、C1...则有多个观察者。
反应式流确实是对观察者模式的拓展,反应式流能够更轻松的定义这种发布订阅关系,而且,反应式流的订阅目标更加细致,通常观察者模式的发布者和订阅者都是具体的类,而反应式流则可以是具体的属性。
基本特性3:声明式
反应式流中,变化传递依是基于数据流进行的,那么数据流是如何定义的呢?在反应式流中,生产者只负责生产信息,开发者要做的就是为消费者预先定义的一些计算逻辑,来传递变化。我们可以使用声明式编程的方式进行数据处理过程(processing pipelines)的定义,如下面代码所示。
data.stream()
.map(o -> o * o)
.map(Math::sqrt)
.map(...)
...这些pipeline一旦定义好,无论到来的数据是什么样的,都会经过它进行数据处理,不需要额外定义控制流程。
在命令式编程中,如下代码所示,a的第二次赋值并不会影响b的值,如果要更新b的值,必须重复执行b = a + 1。然而在反应式流中,对b = a + 1进行声明之后,b保存的不是某次计算的结果,而是计算逻辑,b能够随时根据a的值的变化而变化。
a = 1;
b = a + 1; //在命令式编程中,b保存的是计算的结果。在反应式编程中,b保存的是计算逻辑
a = 2; //在反应式编程中,a的变化会直接引起b的变化。在命令式编程中,需要重复执行代码,才回改变b的值。这也是为什么反应式流能够帮助我们抽象过程管理的原因,反应式流可以构建和存储业务之间的逻辑关系。
高级特性1:流量控制(回压)
在反应式流中,数据流的生产者叫做Publisher,消费者叫做Subscriber。假如Publisher和Subscriber的数据处理速度不一致,会出现如下问题
- Publisher生产速率大于Subscriber处理速率:Subscriber被数据淹没、被压垮
- Subscriber消费速率大于Publisher处理速率:资源利用不充分
那么有没有一种手段能够“恰好”保持生产速率和消费速率的平衡,并把这种临界状态一直持续下去?为了解决这个问题,数据流的速度需要被控制,所以Subscriber应该可以向Publisher反馈其消费能力,这种机制就叫做"backpressure",即“回压”,回压是一种协调组件间通讯速度的手段。

如图,在反应式流中,真正代表数据处理中间阶段(stage)的是operator,operator既是生产者也是消费者,将它们连接在一起就组成了一条pipeline,在pipeline中,存在一条以Subscriber为起始点的向上的调用链,这就是反应式流中的回压手段,通过这条回压链路,消费者能够将消费能力传递给上游生产者。
高级特性2:异步边界
反应式流规定,数据在组件之间的传递是异步的,不可以阻塞发布者。为什么会这样规定呢?因为异步能提高吞吐量,一些高性能的技术手段诸如Node、OpenResty等,都是基于异步模型的。
反应式流对于阻塞问题的解决也是基于异步化的,但反应式流做了以下约束,解决了“经典”的 JVM 异步方式(回调和Futures)所带来的不足,提高了程序的可编排性和可读性:
首先,反应式流强制规定,回压必须是非阻塞的。如果回压是同步的,那么会导致异步处理无效。
其次,反应式流规定,数据在组件之间的传递是异步的,不可以阻塞发布者。

如图所示,nioSelectorThreadOrigin和toNioSelectorOutput代表异步的生产者和消费者,管道符号“|”代表组件间的异步边界(先不关心边界使用的技术手段),R#代表线程资源,R2,R3,R4都是异步执行的,它们可能基于某个事件模型调度的,也可能是基于多线程调度的。
最后,反应式流对资源的管理和调度更加灵活。组件内可以包含一些同步处理逻辑,只需要保证组件之间的数据传递是异步的。

如图所示,第一个示例中,R1组件可以在原始线程上同步处理map和filter,第二个示例中,R2要同步处理map和filter。
具体案列优势举例:Reactor官网提供了一个简单的getFavorites的业务场景,具体业务逻辑是这样的,获取某用户喜爱的东西列表,如果空则建议三个,如果非空则获取详情,最后展现在UI。

采用“经典”的JVM是如何解决异步化问题Callback+CompletableFuture,但在进行较复杂的业务流程编排时,它们的问题就暴漏出来了:Callback虽然能够解决问题,但是很容易陷入回调地狱;CompletableFuture也无法避免代码可读性问题。下面是使用Callback方式解决上述getFavorites业务场景的代码示例,仅仅是双层回调逻辑就让人感觉有些心累,具体代码如下:
userService.getFavorites(userId, new Callback<List<String>>() {
public void onSuccess(List<String> list) {
if (list.isEmpty()) {
suggestionService.getSuggestions(new Callback<List<Favorite>>() {
public void onSuccess(List<Favorite> list) {
UiUtils.submitOnUiThread(() -> {
list.stream()
.limit(5)
.forEach(uiList::show);
});
}
public void onError(Throwable error) {
UiUtils.errorPopup(error);
}
});
} else {
list.stream()
.limit(5)
.forEach(favId -> favoriteService.getDetails(favId,
new Callback<Favorite>() {
public void onSuccess(Favorite details) {
UiUtils.submitOnUiThread(() -> uiList.show(details));
}
public void onError(Throwable error) {
UiUtils.errorPopup(error);
}
}
));
}
}
public void onError(Throwable error) {
UiUtils.errorPopup(error);
}
});使用反应式流,可以轻松解决的异步和可读性难以兼得的问题,代码如下:
userService.getFavorites(userId) // R1
.flatMap(favoriteService::getDetails) // R1
.switchIfEmpty(suggestionService.getSuggestions()) // R1
.take(5) // R1
.publishOn(UiUtils.uiThreadScheduler()) // 异步边界
.subscribe(uiList::show, UiUtils::errorPopup); // R2(三)反应式流接口
反应式流规范定义了四个接口七个方法,并且对于每个接口的实现方式都做了一些约束。
// 发布者接口
public interface Publisher<T> {
public void subscribe(Subscriber<? super T> s);
}
// 订阅者接口
public interface Subscriber<T> {
public void onSubscribe(Subscription s);
public void onNext(T t);
public void onError(Throwable t);
public void onComplete();
}
// 订阅关系接口
public interface Subscription {
public void request(long n);
public void cancel();
}
// 执行者接口:用于转换发布者到订阅者之间管道中的元素。它既是一个订阅者又是一个发布者。
public interface Processor<T, R> extends Subscriber<T>, Publisher<R> {
}可以从下面的接口定义看出来,为了实现异步化,所有的接口方法都是没有返回值的。具体源码分析不进行展述分析。
二、业务应用举例代码展示
(一) 具体框架引入介绍
可以直接使用一些流处理框架和相关库,以下是两个常用的框架引用举例。
- 对于第一个 Akka Streams 应用,你需要引入以下 Maven 依赖项:
<dependencies>
<dependency>
<groupId>com.typesafe.akka</groupId>
<artifactId>akka-stream_2.12</artifactId>
<version>2.6.16</version>
</dependency>
<dependency>
<groupId>com.typesafe.akka</groupId>
<artifactId>akka-stream-testkit_2.12</artifactId>
<version>2.6.16</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>com.typesafe.akka</groupId>
<artifactId>akka-stream-kafka_2.12</artifactId>
<version>2.1.1</version>
</dependency>
</dependencies>- 对于第二个 Reactor 应用,你需要引入以下 Maven 依赖项:
<dependencies>
<dependency>
<groupId>io.projectreactor</groupId>
<artifactId>reactor-core</artifactId>
<version>3.4.8</version>
</dependency>
</dependencies>(二) 业务应用代码举例展示
举例一:用于读取文件内容并将其输出到控制台
package org.zyf.javabasic.reactivestreams;
import reactor.core.publisher.Flux;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
/**
* @author yanfengzhang
* @description 使用 Reactor 框架实现的反应式流应用举例代码,用于读取文件内容并将其输出到控制台
* @date 2023/5/1 19:43
*/
public class FileContentPrint {
public static void main(String[] args) throws Exception {
Path path = Paths.get("test.txt");
// 创建 Flux 对象并读取文件内容
Flux<String> fileContent = Flux.using(
() -> Files.lines(path),
Flux::fromStream,
stream -> {
try {
stream.close();
} catch (Exception e) {
e.printStackTrace();
}
}
);
// 订阅 Flux 对象并输出文件内容
fileContent.subscribe(System.out::println);
}
}
上述代码中,使用 Flux.using() 方法创建了一个 Flux 对象,该对象通过读取指定路径下的文件内容生成数据流。然后使用 subscribe() 方法订阅 Flux 对象,并通过 lambda 表达式将每个元素输出到控制台。由于使用了 Reactor 框架,因此这个应用是一个完全的反应式流应用程序,其读取文件和输出元素的过程都是异步和非阻塞的,能够更好地利用计算机资源。
举例二:从 Twitter 实时数据流中读取推文并将其输出到控制台
package org.zyf.javabasic.reactivestreams;
import akka.Done;
import akka.NotUsed;
import akka.actor.ActorSystem;
import akka.stream.ActorMaterializer;
import akka.stream.Materializer;
import akka.stream.javadsl.Source;
import akka.stream.javadsl.Sink;
import akka.stream.javadsl.TwitterSource;
import com.typesafe.config.ConfigFactory;
import java.util.concurrent.CompletionStage;
/**
* @author yanfengzhang
* @description 使用 Akka Streams 实现的反应式流应用举例代码,用于从 Twitter 实时数据流中读取推文并将其输出到控制台
* @date 2023/5/1 19:47
*/
public class TweetsPrint {
public static void main(String[] args) throws Exception {
// 创建 Actor 系统和 Materializer
ActorSystem system = ActorSystem.create("reactive-streams-example", ConfigFactory.load());
Materializer materializer = ActorMaterializer.create(system);
// 创建 TwitterSource 对象并订阅推文数据流
Source<String, NotUsed> tweets = TwitterSource.create(
"Consumer Key",
"Consumer Secret",
"Access Token",
"Access Token Secret"
).map(status -> status.getText());
// 创建 Sink 对象并将推文输出到控制台
Sink<String, CompletionStage<Done>> consoleSink = Sink.foreach(System.out::println);
// 将 Source 和 Sink 连接起来,并运行流处理程序
tweets.runWith(consoleSink, materializer);
}
}
上述代码中,使用 TwitterSource.create() 方法创建了一个 Source 对象,该对象从 Twitter 实时数据流中读取推文数据并生成数据流。然后创建了一个 Sink 对象,将每个推文输出到控制台。最后将 Source 和 Sink 连接起来,并使用 runWith() 方法运行流处理程序。由于使用了 Akka Streams 框架,因此这个应用是一个完全的反应式流应用程序,其读取推文和输出元素的过程都是异步和非阻塞的,能够更好地利用计算机资源。
举例三:获取商品信息并将其按照指定条件进行排序并输出到控制台
package org.zyf.javabasic.reactivestreams;
import reactor.core.publisher.Flux;
import reactor.core.publisher.Mono;
import java.math.BigDecimal;
import java.util.Arrays;
import java.util.Comparator;
import java.util.List;
/**
* @author yanfengzhang
* @description 使用 Reactor 框架实现的电商场景应用举例代码,用于获取商品信息并将其按照指定条件进行排序并输出到控制台
* @date 2023/5/1 19:50
*/
public class ProductPrint {
public static void main(String[] args) throws Exception {
// 创建商品对象列表
List<Product> productList = Arrays.asList(
new Product("A001", "商品A", new BigDecimal("100.00")),
new Product("A002", "商品B", new BigDecimal("200.00")),
new Product("A003", "商品C", new BigDecimal("300.00")),
new Product("A004", "商品D", new BigDecimal("400.00")),
new Product("A005", "商品E", new BigDecimal("500.00"))
);
// 创建 Flux 对象并按照价格排序
Flux<Product> productFlux = Flux.fromIterable(productList)
.sort(Comparator.comparing(Product::getPrice));
// 订阅 Flux 对象并输出商品信息
productFlux.subscribe(product -> System.out.println(product.getId() + " - " + product.getName() + " - " + product.getPrice()));
}
// 商品对象类
static class Product {
private String id;
private String name;
private BigDecimal price;
public Product(String id, String name, BigDecimal price) {
this.id = id;
this.name = name;
this.price = price;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public BigDecimal getPrice() {
return price;
}
public void setPrice(BigDecimal price) {
this.price = price;
}
}
}
上述代码中,创建了一个商品对象列表,并使用 Flux.fromIterable() 方法将其转换为 Flux 对象。然后使用 sort() 方法按照商品价格排序,并使用 lambda 表达式将每个商品的 id、name 和 price 输出到控制台。由于使用了 Reactor 框架,因此这个应用是一个完全的反应式流应用程序,其获取商品信息和输出元素的过程都是异步和非阻塞的,能够更好地利用计算机资源。
三、Reactor原理分析
以Reactor中的Flux为例,说明其执行原理。
Reactor类库中,数据的发布者有两种,一种是Flux,它代表0或N个元素的异步队列,另一种Mono,它代表0或1个元素的异步队列。
// log 函数可以打印Flux的调用过程
Flux.just(1, 2, 3)
.log()
.map(o -> {
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
return o * o;
})
.log()
.filter(o -> o > 0)
.log()
.subscribe();调用关系
以Flux.just(1, 2, 3).subscribe()为例,说明Publisher、Subscriber、Subscription之间的调用关系。
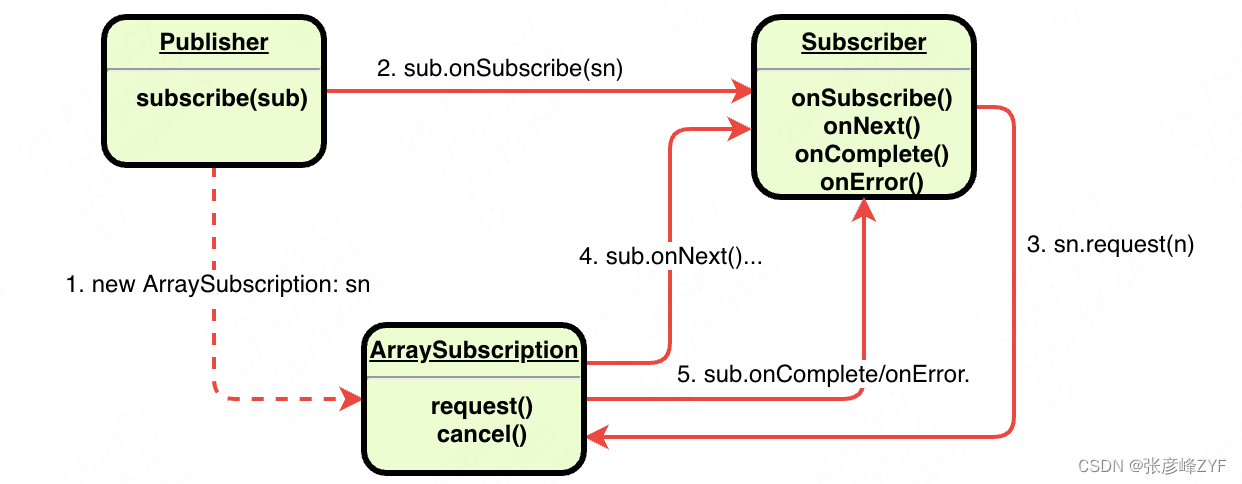
以上是不存在Operator时,Publisher、Subscriber、Subscription之间的调用关系。在subscribe函数执行后依此执行事情:
- 发起订阅;
- 发布者Publisher新建了ArraySubscription sn;
- 通过订阅者的回调onSubscribe函数,将sn传递给订阅者sub;
- 订阅者sub通过sn发起request(n)请求;
- 发布者通过sn发起sub.onNext()调用
- 发布者的序列结束或错误,则通过订阅者的onComplete/onError传递信息
执行过程
对以上代码执行可以看到,执行过程可以分为三个阶段:onSubscribe阶段、request阶段、onNext阶段,再加上订阅subscribe过程和计算逻辑pipeline的声明过程,一共是五个阶段——声明阶段、subscribe阶段、onSubscribe阶段、request阶段和onNext阶段。
// 执行结果, 此时整个数据链路不存在异步边界,完全同步执行
// onSubscribe
[ INFO] (main) | onSubscribe([Synchronous Fuseable] FluxArray.ArrayConditionalSubscription)
[ INFO] (main) | onSubscribe([Fuseable] FluxMapFuseable.MapFuseableConditionalSubscriber)
[ INFO] (main) | onSubscribe([Fuseable] FluxFilterFuseable.FilterFuseableSubscriber)
// request
[ INFO] (main) | request(unbounded)
[ INFO] (main) | request(unbounded)
[ INFO] (main) | request(unbounded)
// onNext 消费数据
[ INFO] (main) | onNext(1)
[ INFO] (main) | onNext(1)
[ INFO] (main) | onNext(1)
[ INFO] (main) | onNext(2)
[ INFO] (main) | onNext(4)
[ INFO] (main) | onNext(4)
[ INFO] (main) | onNext(3)
[ INFO] (main) | onNext(9)
[ INFO] (main) | onNext(9)
// onComplete 没数据了
[ INFO] (main) | onComplete()
[ INFO] (main) | onComplete()
[ INFO] (main) | onComplete()声明阶段
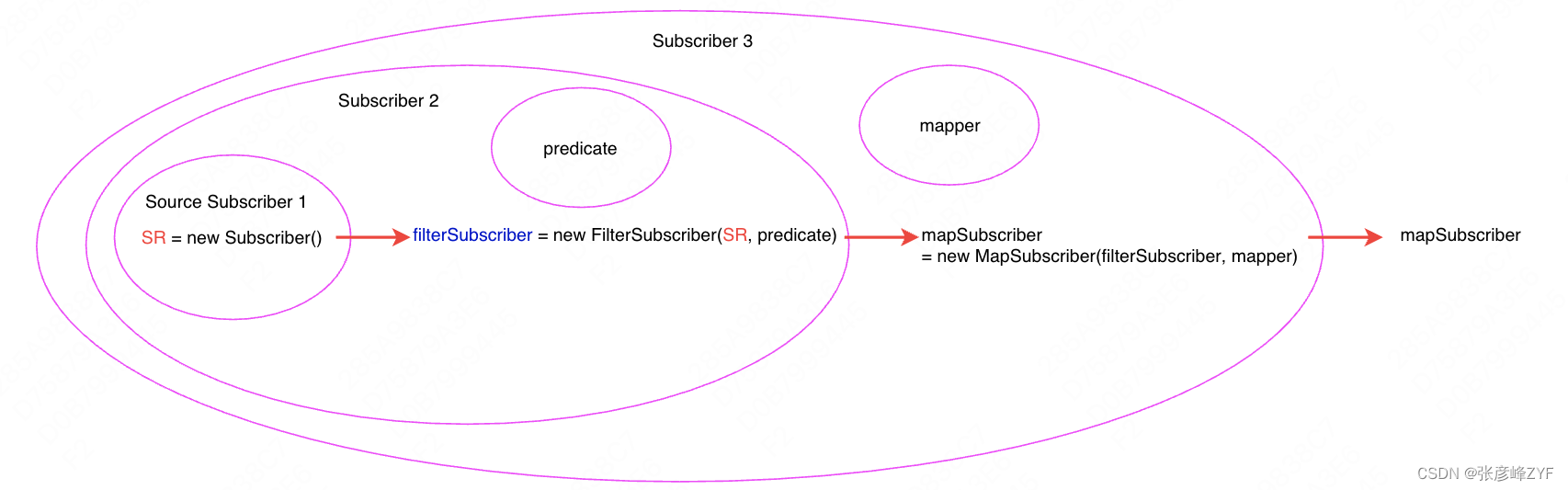
在订阅者真的发起订阅之前,需要首先声明数据处理管道。在管道上,每一个Operator其实都是对上游发布者的封装,所以从整体上来看,管道类似于一个洋葱,是由Publisher一层一层包起来的。以本章开头的Flux.just(1, 2, 3).map().filter()为例,下图是其对发布者的逐步封装过程,初始Publisher仅有数据,后续每一个operator都是对前一个发布者对象的封装,同时也包含了对数据的处理逻辑,最后形成一个最终发布者fluxFilter。
subscribe阶段

执行管道pipeline类似于一个洋葱,订阅过程也类似一个洋葱,唯一不同的是,pipeline是从上游至下游的包装过程,而订阅过程则是从下游至上游的包装过程,如上图所示,在进行subscribe操作的时候,反应式流会从最外层的源Subscriber一层一层的包装,根据包裹的Operator创建各种Subscriber。
onSubscribe阶段
onSubscribe调用使得所有的组件像一个链条一样关联起来,传递的过程是由上游至下游的,具体的过程就是调用下游的(Enhanced)Subscriber.onSubscribe方法,并把自身作为入参;
request阶段
订阅者向上请求数据,直到回到数据源,入参n代表了请求数据的数量;
调用阶段
数据元素就像水管中的水一样,依此经过(Enhanced)Subscriber.Subscriber的onNext(),直至最终的订阅者Subscriber。
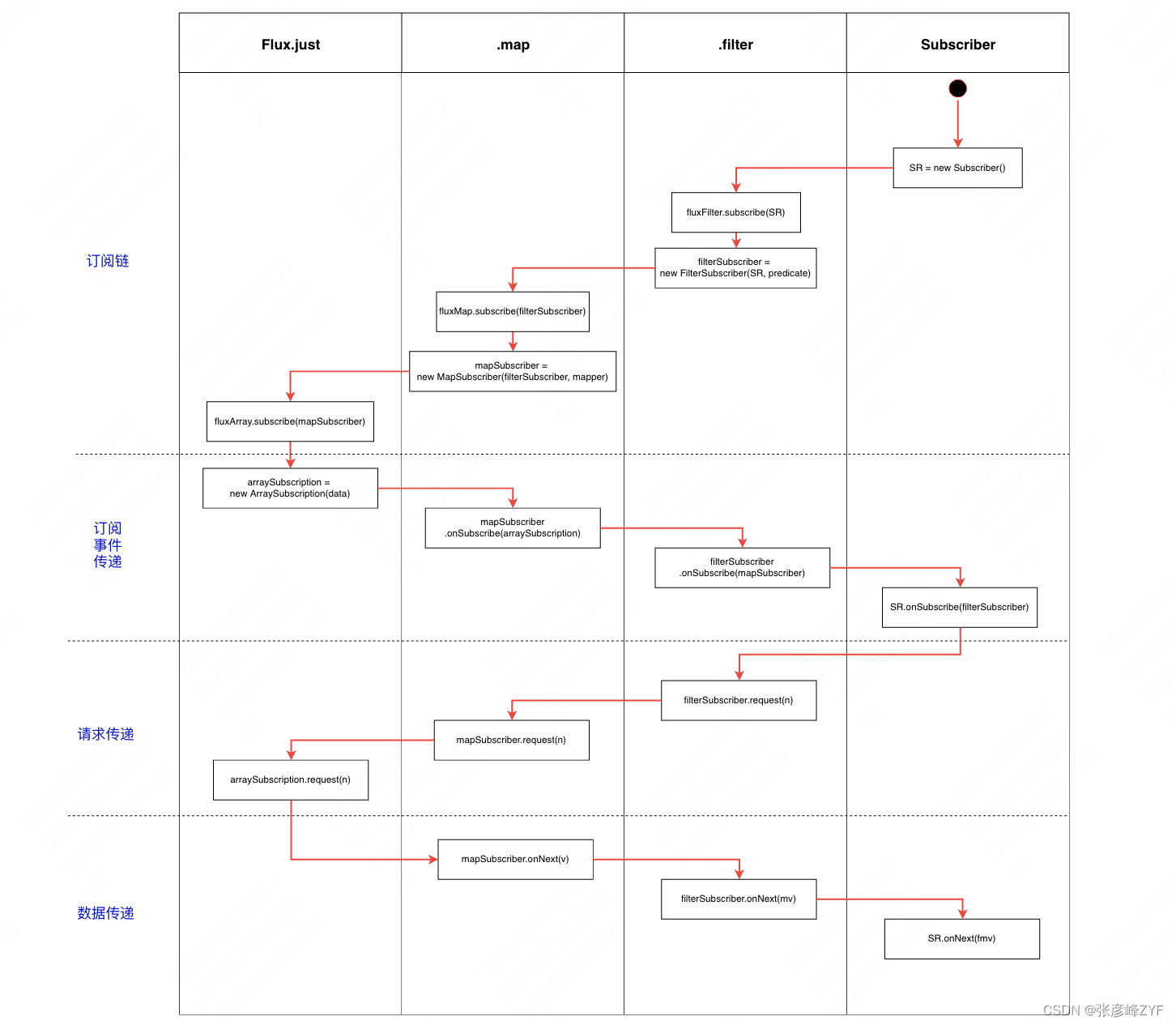
pipeline被订阅之后的流程图如下所示
回压
非阻塞回压是反应式流的最主要特征。Reactor管道内部存在一条自下而上的订阅链,该链路可以传递request(n)请求,request函数入参n代表了下游对上游数据的请求数量,这是回压实现的基础。

而实际上在Reactor中,”回压“是通过回压组件的来实现的,每种组件具有不同的策略。Reactor支持五种类型的回压策略,它们分别是:
- Error:抛出IllegalStateException异常。
- Drop:丢弃。
- Latest:返回最近的值
- Buffer:缓存,缓存大小可设定,缓存过多会产生OOM异常
- Ignore:完全无视下游的request请求,可能会打爆下游队列,产生IllegalStateException异常
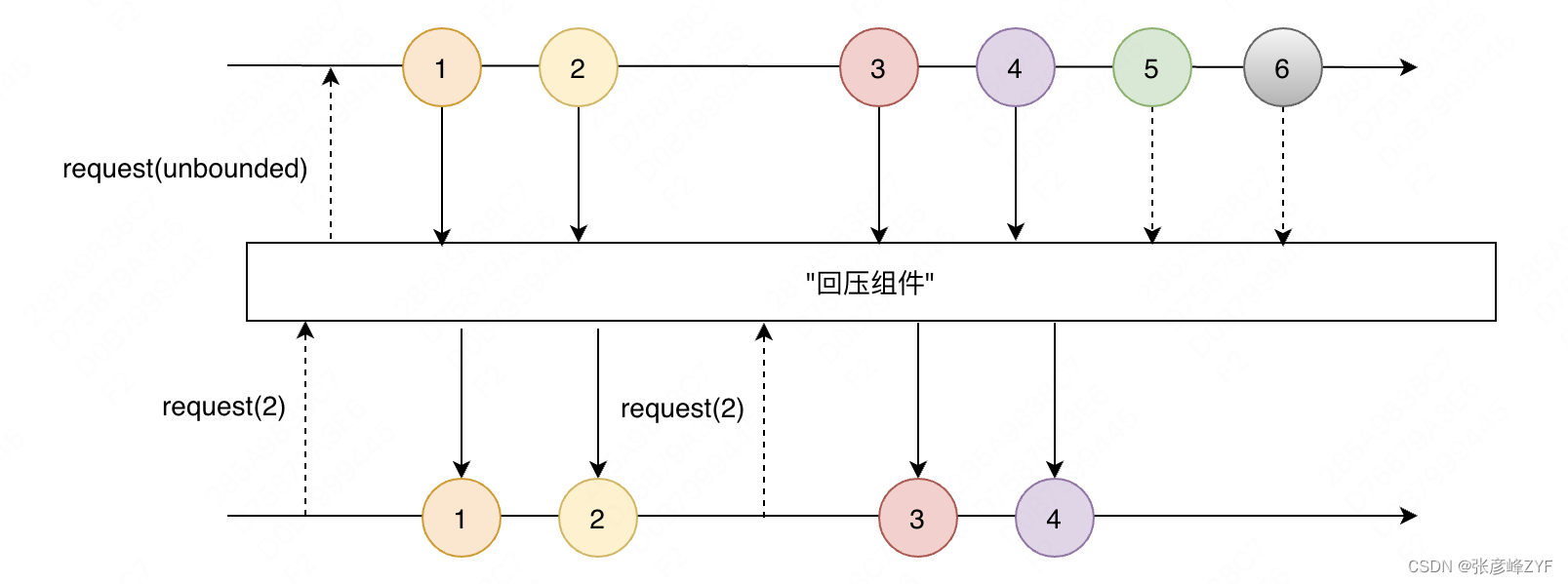
如下图是回压的示意图,回压组件源源不断的接收上游推送的消息,回压下游的组件发起request(2)请求,然后接收到两个数据元素,然后不断重复这个过程。那么当下游组件没有继续发起request(2)请求,如何处理数据元素5和数据元素6呢?
对于Error策略来讲,就是抛出异常;对于Drop策略,那就是丢弃该元素,直到再次发起request(2)请求;对于Latest策略来讲,会将最近一个数据元素缓存起来(图中的6号元素),等待交给下游;对于Buffer策略,就是将后续元素缓存起来直到下一次request(2)请求。
异步边界
反应式流标准中提出,数据应支持在组件间的异步传输,从而实现组件间的隔离。如下所示,Reactor中的异步边界是通过调度器和切换方法实现的,更具体的,是通过线程实现的。
Flux.just(1, 2, 3)
.log()
.publishOn(Schedulers.parallel()) // 异步边界的产生
.log()
.map(o -> {
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
return o * o;
})
.log()
.filter(o -> o > 0)
.log()
.subscribe();
while (true) {} //防止主进程结束,看不到执行结果。
// 执行结果 此时数据处理是异步进行的
[ INFO] (main) | onSubscribe([Synchronous Fuseable] FluxArray.ArraySubscription)
[ INFO] (main) | onSubscribe([Fuseable] FluxPublishOn.PublishOnConditionalSubscriber)
[ INFO] (main) | onSubscribe([Fuseable] FluxMapFuseable.MapFuseableConditionalSubscriber)
[ INFO] (main) | onSubscribe([Fuseable] FluxFilterFuseable.FilterFuseableSubscriber)
[ INFO] (main) | request(unbounded)
[ INFO] (main) | request(unbounded)
[ INFO] (main) | request(unbounded)
[ INFO] (main) | request(256)
[ INFO] (main) | onNext(1)
[ INFO] (main) | onNext(2)
[ INFO] (parallel-1) | onNext(1)
[ INFO] (main) | onNext(3)
[ INFO] (main) | onComplete() // 主进程结束数据发布
[ INFO] (parallel-1) | onNext(1)
[ INFO] (parallel-1) | onNext(1)
[ INFO] (parallel-1) | onNext(2)
[ INFO] (parallel-1) | onNext(4)
[ INFO] (parallel-1) | onNext(4)
[ INFO] (parallel-1) | onNext(3)
[ INFO] (parallel-1) | onNext(9)
[ INFO] (parallel-1) | onNext(9)
[ INFO] (parallel-1) | onComplete()
[ INFO] (parallel-1) | onComplete()
[ INFO] (parallel-1) | onComplete()四、业务应用中的建议
当应用反应式编程时,需要注意以下几个方面:
- 异步非阻塞操作:反应式编程的核心是异步和非阻塞操作,这可以提高应用的并发能力和性能。在具体业务中,需要使用异步的 API 和非阻塞的操作来处理数据流,如异步 IO、异步 HTTP 客户端等。
- 可靠性和容错性:反应式编程中,需要考虑到一些错误和异常情况的处理,如网络错误、连接错误、超时等。因此,需要使用合适的错误处理机制,如异常处理、重试机制等。
- 反压机制:反压机制是保证数据流稳定性的重要机制。数据流的生产者速度不能太快,否则会导致消费者被压垮。反压机制可以限制生产者速度,防止消费者被压垮。可以使用诸如 Reactive Streams 中的 backpressure 或者基于 Flowable 或 Observable 的反压框架。
- 最佳实践:在应用反应式编程时,需要遵循一些最佳实践。这包括避免副作用、避免状态共享、使用不可变数据结构等。此外,需要注意的是,在反应式编程中不应该使用像 Thread.sleep() 等会阻塞线程的操作。
- 选择合适的框架和库:在具体应用中,需要选择合适的反应式编程框架和库。当前,主流的反应式编程框架和库有很多,如 Reactor、Akka、RxJava 等。选择合适的框架和库能够帮助我们更好地进行反应式编程。
综上所述,在应用反应式编程时,需要充分了解反应式编程的核心原则和编程模型,并结合具体业务进行实践。需要注意的是,反应式编程不是一种万能的编程模型,而是一种针对特定应用场景的编程模型,应用时需要合理评估场景和需求。
参考文献、书籍及链接
1.郑德伟《认识Reactive Streams》
2.由表及里学 ProjectReactor | Yanick's Blog
3.https://gist.github.com/staltz/868e7e9bc2a7b8c1f754
4.解构反应式编程——Java 8, RxJava, Reactor之比较 - 掘金
5.软件开发|响应式编程与响应式系统
6.(11)照虎画猫深入理解响应式流规范——响应式Spring的道法术器_享学IT的博客-CSDN博客