慢SQL的定位
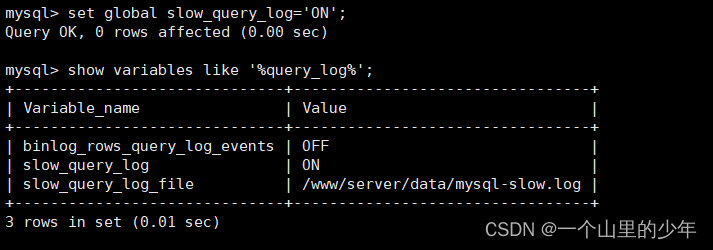
在MySQL当中,我们有时候写的SQL执行效率太慢此时我们需要将其优化。但是SQL可能非常的多,难道我们一条一条的进行查看吗?在MySQL当当中我们可以查看慢查询日志,看看那些SQL这么慢。但是这个默认情况下这个慢查询日志是关闭的,我们可以通过一下命令进行查看
show variables like '%query_log%';
执行结果如下:
mysql> show variables like '%query_log%';
+------------------------------+---------------------------------+
| Variable_name | Value |
+------------------------------+---------------------------------+
| binlog_rows_query_log_events | OFF |
| slow_query_log | ON |
| slow_query_log_file | /www/server/data/mysql-slow.log |
+------------------------------+---------------------------------+
3 rows in set (0.01 sec)
我们可以将其开启
set global slow_query_log='ON';
并且通过上面我们也可以看到慢查询日志在那个路径下。然后了我们可以设置一个业务可以接受的时间,执行时间超过这个值的SQL都将被记录在慢查询日志里面
show variables like '%long_query_time%';

这里如果我们想把时间缩短,比如设置为 1 秒,可以这样设置:
set global long_query_time = 1;//设置为全局
show global variables like '%long_query_time%';

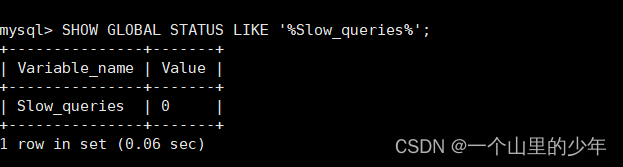
同时我们也可以查看一下这个系统当中有多少条这个慢查询日志。
SHOW GLOBAL STATUS LIKE '%Slow_queries%';
下面我们来建一张表
CREATE TABLE `student` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`stuno` INT NOT NULL ,
`name` VARCHAR(20) DEFAULT NULL,
`age` INT(3) DEFAULT NULL,
`classId` INT(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
现在我们往表里面插入大量的数据,首先:命令开启:允许创建函数设置:
set global log_bin_trust_function_creators=1; # 不加global只是当前窗口有效。
2.创建函数
DELIMITER //
CREATE FUNCTION rand_string(n INT)
RETURNS VARCHAR(255) #该函数会返回一个字符串
BEGIN
DECLARE chars_str VARCHAR(100) DEFAULT
'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
DECLARE return_str VARCHAR(255) DEFAULT '';
DECLARE i INT DEFAULT 0;
WHILE i < n DO
SET return_str =CONCAT(return_str,SUBSTRING(chars_str,FLOOR(1+RAND()*52),1));
SET i = i + 1;
END WHILE;
RETURN return_str;
END //
DELIMITER ;
#测试
SELECT rand_string(10)
产生随机数值:
DELIMITER //
CREATE FUNCTION rand_num (from_num INT ,to_num INT) RETURNS INT(11)
BEGIN
DECLARE i INT DEFAULT 0;
SET i = FLOOR(from_num +RAND()*(to_num - from_num+1)) ;
RETURN i;
END //
DELIMITER ;
#测试:
SELECT rand_num(10,100);
创建存储过程
DELIMITER //
CREATE PROCEDURE insert_stu1( START INT , max_num INT )
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0; #设置手动提交事务
REPEAT #循环
SET i = i + 1; #赋值
INSERT INTO student (stuno, NAME ,age ,classId ) VALUES
((START+i),rand_string(6),rand_num(10,100),rand_num(10,1000));
UNTIL i = max_num
END REPEAT;
COMMIT; #提交事务
END //
DELIMITER ;
最后我们调用存储过程
CALL insert_stu1(100001,4000000);
现在我们的这个数据库里面有大量的数据,下面我们执行一条sql看看这个是否会记录了
SELECT * FROM student WHERE stuno = 3455655;
执行结果如下:
mysql> SELECT * FROM student WHERE stuno = 3455655;
+---------+---------+--------+------+---------+
| id | stuno | name | age | classId |
+---------+---------+--------+------+---------+
| 3355654 | 3455655 | UyIUzM | 33 | 53 |
+---------+---------+--------+------+---------+
1 row in set (2.38 sec)
mysql> SHOW GLOBAL STATUS LIKE '%Slow_queries%';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| Slow_queries | 1 |
+---------------+-------+
1 row in set (0.00 sec)
获取我们去这个慢查询日志里面看看也可以。
explain SQL执行计划
explain是什么?explain是这个SQL执行官网.使用EXPLAIN关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的SQL语句的。分析你的查询语句或是表结构的性能瓶颈。
explain的使用方法非常的简单,explain+sql就可以了。下面我们来简单的执行一条
mysql> explain select * from student where id=1000;
+----+-------------+---------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| 1 | SIMPLE | student | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | NULL |
+----+-------------+---------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.04 sec)
下面稍微解释一下上面这些字段的含义
- id:在一个大的查询语句中每个SELECT关键字都对应一个 唯一的id
- select_type:SELECT关键字对应的那个查询的类型
- table :表名
- partitions :匹配的分区信息
- type :针对单表的访问方法
- possible_keys: 可能用到的索引
- key :实际上使用的索引
- key_len: 实际使用到的索引长度
- ref :当使用索引列等值查询时,与索引列进行等值匹配的对象信息
- rows: 预估的需要读取的记录条数
- filtered:某个表经过搜索条件过滤后剩余记录条数的百分比
- Extra: 一些额外的信息
在这里一些不太重要的字段,在这里简单说一下这个id和selec_type。每一个select 都会有一个全局的id.select_type表示的查询的类型。
下面我们重点看一下这个type字段。这个字段非常的重要一般常用的基本是这样的
const>eq_ref>ref>range>index>all.性能从高到低。一般我们查询条件一般需要达到range级别。
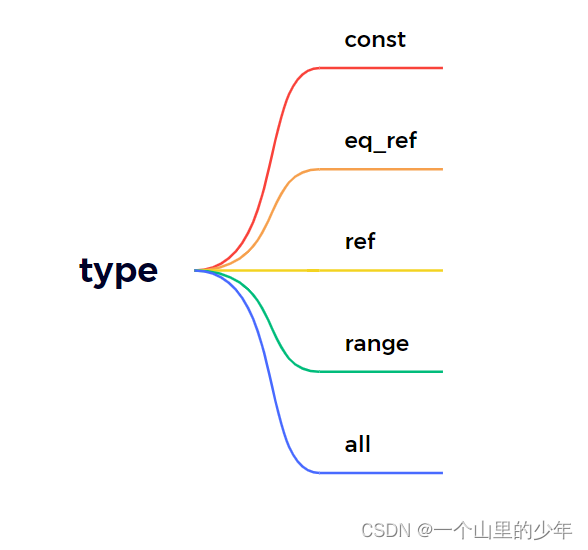
下面我们一个一个来解释首先是这个const.这个级别一般很难达到。
const表示通过索引一次就可以找到,const用于比较primary key 或者unique索引。因为只匹配一行,所以很快。如将主键置于where列表当中,MySQL就能将该查询转换为一个常量。
下面我们给个列子表是这样的
mysql> desc student;
+---------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+---------+-------------+------+-----+---------+----------------+
| id | int | NO | PRI | NULL | auto_increment |
| stuno | int | NO | | NULL | |
| name | varchar(20) | YES | | NULL | |
| age | int | YES | | NULL | |
| classId | int | YES | | NULL | |
+---------+-------------+------+-----+---------+----------------+
5 rows in set (0.06 sec)
下面我们执行一下这条SQL
mysql> explain select * from student where id=1000;
+----+-------------+---------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| 1 | SIMPLE | student | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | NULL |
+----+-------------+---------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.04 sec)
我们发现他这个type就是const.
下面是这个eq_ref,这个主要用于这个多表查询。其含义主要是唯一索引扫描对于每个索引列表中只有一条记录与之匹配。常用于主键或者唯一索引扫描。下面我们来执行一下sql
mysql> explain select * from student a,student b where a.id=b.id;
+----+-------------+-------+------------+--------+---------------+---------+---------+----------+---------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+--------+---------------+---------+---------+----------+---------+----------+-------+
| 1 | SIMPLE | a | NULL | ALL | PRIMARY | NULL | NULL | NULL | 3981978 | 100.00 | NULL |
| 1 | SIMPLE | b | NULL | eq_ref | PRIMARY | PRIMARY | 4 | ksy.a.id | 1 | 100.00 | NULL |
+----+-------------+-------+------------+--------+---------------+---------+---------+----------+---------+----------+-------+
2 rows in set, 1 warning (0.01 sec)
我们发现这个第二个出现这个eq_ref,其实这个也比较好理解。eq_ref - 想象你有两张桌子。表A包含列(id,text),其中id是主键。表B具有相同的列(id,text),其中id是主键。表A包含以下数据:
1, Hello
2, How are
表B有以下数据:
1, world!
2, you?
想象一下eq_ref为A和B之间的JOIN:
select A.text, B.text where A.ID = B.ID
这个JOIN非常快,因为对于表A中扫描的每一行,表B中只能有一行满足JOIN条件。一个,不超过一个。那是因为B.id是独一无二的。
下面我们在来看看这个ref。在这之前我们需要给上面那张表添加一个索引字段
create index age on student(age);
ref指的是这个非唯一键索引扫描,返回匹配某个值的所有行本质上也是一张索引访问,它返回所有匹配某个单独值的行,可能会找到多个符合条件的行。
mysql> explain select * from student where age=100;
+----+-------------+---------+------------+------+---------------+------+---------+-------+-------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+------+---------+-------+-------+----------+-------+
| 1 | SIMPLE | student | NULL | ref | age | age | 5 | const | 82828 | 100.00 | NULL |
+----+-------------+---------+------------+------+---------------+------+---------+-------+-------+----------+-------+
1 row in set, 1 warning (0.03 sec)
下面我们在来看看这个range 只检索给定返回的行,使用一个索引来选择行。key列显示了那个索引一般就是你的where语句当中出现了between,<,>,in等查询语句。下面我们来看看这个案例
mysql> explain select * from student where id>1100;
+----+-------------+---------+------------+-------+---------------+---------+---------+------+---------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+---------------+---------+---------+------+---------+----------+-------------+
| 1 | SIMPLE | student | NULL | range | PRIMARY | PRIMARY | 4 | NULL | 1990989 | 100.00 | Using where |
+----+-------------+---------+------------+-------+---------------+---------+---------+------+---------+----------+-------------+
1 row in set, 1 warning (0.01 sec)
下面我们在来看看这个index,这个比all要好,他也叫做这个full index all,index和all的区别为index类型只遍历这个索引树,通过比all快因为索引文件通常比数据文件要小也就是说虽然all和index都是读全表但是index是从索引当中读取,all是从硬盘当中读取。所有全索引扫描比全表扫描要快。下面我们看一下例子
mysql> explain select id from student ;
+----+-------------+---------+------------+-------+---------------+------+---------+------+---------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+---------------+------+---------+------+---------+----------+-------------+
| 1 | SIMPLE | student | NULL | index | NULL | age | 5 | NULL | 3981978 | 100.00 | Using index |
+----+-------------+---------+------------+-------+---------------+------+---------+------+---------+----------+-------------+
最后一个就是这个全表扫描,这个效率最差的一个。在这里就不演示了。
下面我们在来看看这个key_len,和这个rows.这个key_len代表的是使用索引的字节数,在不损失精度的情况下越短越好。这个rows表示大致估算找到所需的记录所要读取的行数。
下面我们重点来看看这个extra字段这个字段很重要。
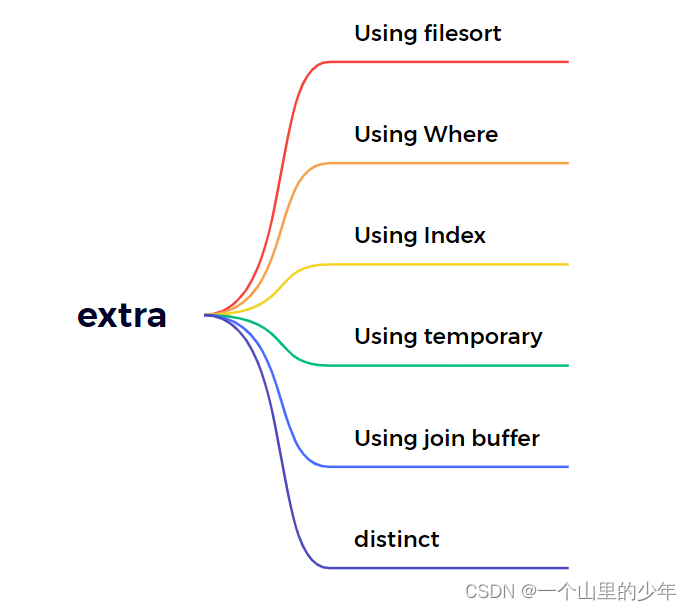
下面我们重点看一下上面这些字段,首先我们来看第一个using filesort. 如果出现了这一个字段说明mysql会对数据使用一个外部的索引排序,而不是按照从表内索引的顺序进行读取。MySQL无法利用索引完成的排序操我们叫做文件排序。下面我们通过一个案例来说明一下
mysql> explain select * from student where id>10 order by age;
+----+-------------+---------+------------+-------+---------------+---------+---------+------+---------+----------+-----------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+---------------+---------+---------+------+---------+----------+-----------------------------+
| 1 | SIMPLE | student | NULL | range | PRIMARY | PRIMARY | 4 | NULL | 1990989 | 100.00 | Using where; Using filesort |
+----+-------------+---------+------------+-------+---------------+---------+---------+------+---------+----------+-----------------------------+
1 row in set, 1 warning (0.01 sec)
这这里id是主键索引,age是二级索引。为啥会出现要给using filesort 这个外部排序了?这是因为索引只能被使用一次。这个在日常当中是不能被接受的。我们可以通过简历复合索引来将其优化掉建立一个id和age的联合索引。在这里就不修改这个表来演示
下面一个我们看看这个using temporary 产生了这个临时表这个更加不能接受。使用了这个临时表保存中间结果,MySQL在对查询结果排序时使用临时表常见与排序order by 和分组查询group by。
下面我们来看一个列子
mysql> explain select age from student where id<1000 group by age;
+----+-------------+---------+------------+-------+---------------+--------+---------+------+------+----------+-------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+---------------+--------+---------+------+------+----------+-------------------------------------------+
| 1 | SIMPLE | student | NULL | range | age,id_age | id_age | 4 | NULL | 999 | 100.00 | Using where; Using index; Using temporary |
+----+-------------+---------+------------+-------+---------------+--------+---------+------+------+----------+-------------------------------------------+
1 row in set, 1 warning (0.00 sec)
我们在看Using index这个索引覆盖,什么意思就是在二级索引就能找到不需要再去主键索引找一次
mysql> explain select id,age from student where id<1000;
+----+-------------+---------+------------+-------+---------------+--------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+---------------+--------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | student | NULL | range | id_age | id_age | 4 | NULL | 999 | 100.00 | Using where; Using index |
+----+-------------+---------+------------+-------+---------------+--------+---------+------+------+----------+--------------------------+
1 row in set, 1 warning (0.00 sec)