文章目录
- 本地集群Windiows
- 创建 elasticsearch-cluster 文件夹,在内部复制三个 elasticsearch 服务
- 修改集群文件目录中每个节点的 config/elasticsearch.yml 配置文件
- 启动集群
- 测试集群-查看集群状态
- 本地开启集群Linux
- 软件下载
- 软件安装
- 创建用户
- 修改配置文件
- 启动软件
- 测试集群
- Docker开启集群
本着生产ES基本上都部署在Linux系统上,本文主要介绍如何在Linux上部署ES集群,分两个部分:非docker版与docker版
本地集群Windiows
创建 elasticsearch-cluster 文件夹,在内部复制三个 elasticsearch 服务

修改集群文件目录中每个节点的 config/elasticsearch.yml 配置文件
-
node-1001节点
#节点 1 的配置信息: #集群名称,节点之间要保持一致 cluster.name: my-elasticsearch #节点名称,集群内要唯一 node.name: node-1001 node.master: true node.data: true #ip 地址 network.host: localhost #http 端口 http.port: 1001 #tcp 监听端口 transport.tcp.port: 9301 #discovery.seed_hosts: ["localhost:9301", "localhost:9302","localhost:9303"] #discovery.zen.fd.ping_timeout: 1m #discovery.zen.fd.ping_retries: 5 #集群内的可以被选为主节点的节点列表 #cluster.initial_master_nodes: ["node-1", "node-2","node-3"] #跨域配置 #action.destructive_requires_name: true http.cors.enabled: true http.cors.allow-origin: "*" -
node-1002 节点
#节点 2 的配置信息: #集群名称,节点之间要保持一致 cluster.name: my-elasticsearch #节点名称,集群内要唯一 node.name: node-1002 node.master: true node.data: true #ip 地址 network.host: localhost #http 端口 http.port: 1002 #tcp 监听端口 transport.tcp.port: 9302 discovery.seed_hosts: ["localhost:9301"] discovery.zen.fd.ping_timeout: 1m discovery.zen.fd.ping_retries: 5 #集群内的可以被选为主节点的节点列表 #cluster.initial_master_nodes: ["node-1", "node-2","node-3"] #跨域配置 #action.destructive_requires_name: true http.cors.enabled: true http.cors.allow-origin: "*" -
node-1003 节点
#节点 3 的配置信息: #集群名称,节点之间要保持一致 cluster.name: my-elasticsearch #节点名称,集群内要唯一 node.name: node-1003 node.master: true node.data: true #ip 地址 network.host: localhost #http 端口 http.port: 1003 #tcp 监听端口 transport.tcp.port: 9303 #候选主节点的地址,在开启服务后可以被选为主节点 discovery.seed_hosts: ["localhost:9301", "localhost:9302"] discovery.zen.fd.ping_timeout: 1m discovery.zen.fd.ping_retries: 5 #集群内的可以被选为主节点的节点列表 #cluster.initial_master_nodes: ["node-1", "node-2","node-3"] #跨域配置 #action.destructive_requires_name: true http.cors.enabled: true http.cors.allow-origin: "*"
启动集群
-
启动前先删除每个节点中的 data 目录中所有内容(如果存在)

-
分别双击执行 bin/elasticsearch.bat, 启动节点服务器,启动后,会自动加入指定名称的集群

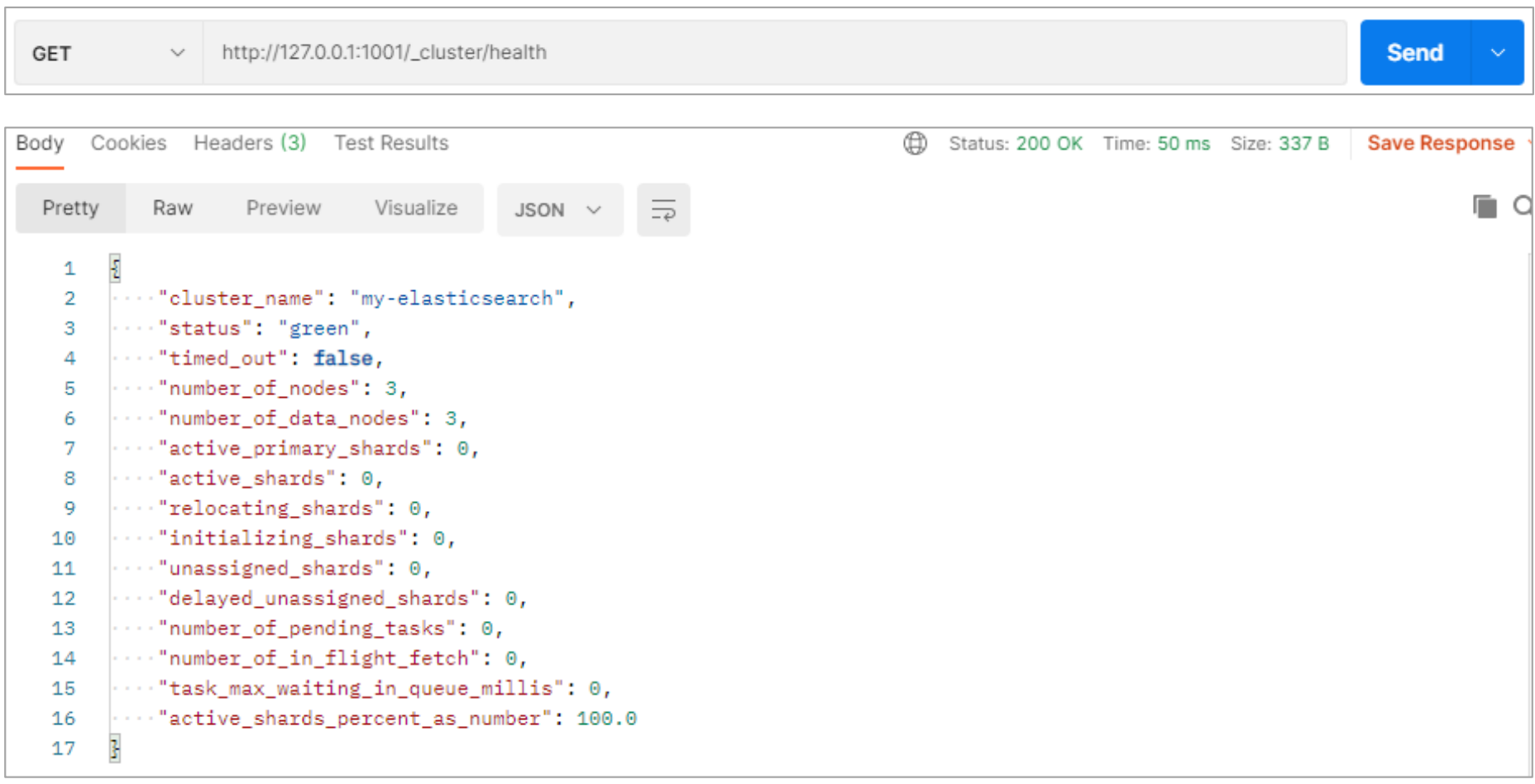
测试集群-查看集群状态
-
node-1001 节点
本地开启集群Linux
软件下载
官网下载地址:https://www.elastic.co/cn/downloads/past-releases/elasticsearch-7-8-0
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.8.0-linux-x86_64.tar.gz

软件安装
# 解压缩
tar -zxvf elasticsearch-7.8.0-linux-x86_64.tar.gz -C /opt/module
# 改名
mv elasticsearch-7.8.0 es-cluster
创建用户
ES不允许root用户直接运行,所以每一个节点中要创建新用户
useradd es #新增 es 用户
passwd es #为 es 用户设置密码
userdel -r es #如果错了,可以删除再加
chown -R es:es /opt/module/es-cluster #文件夹所有者
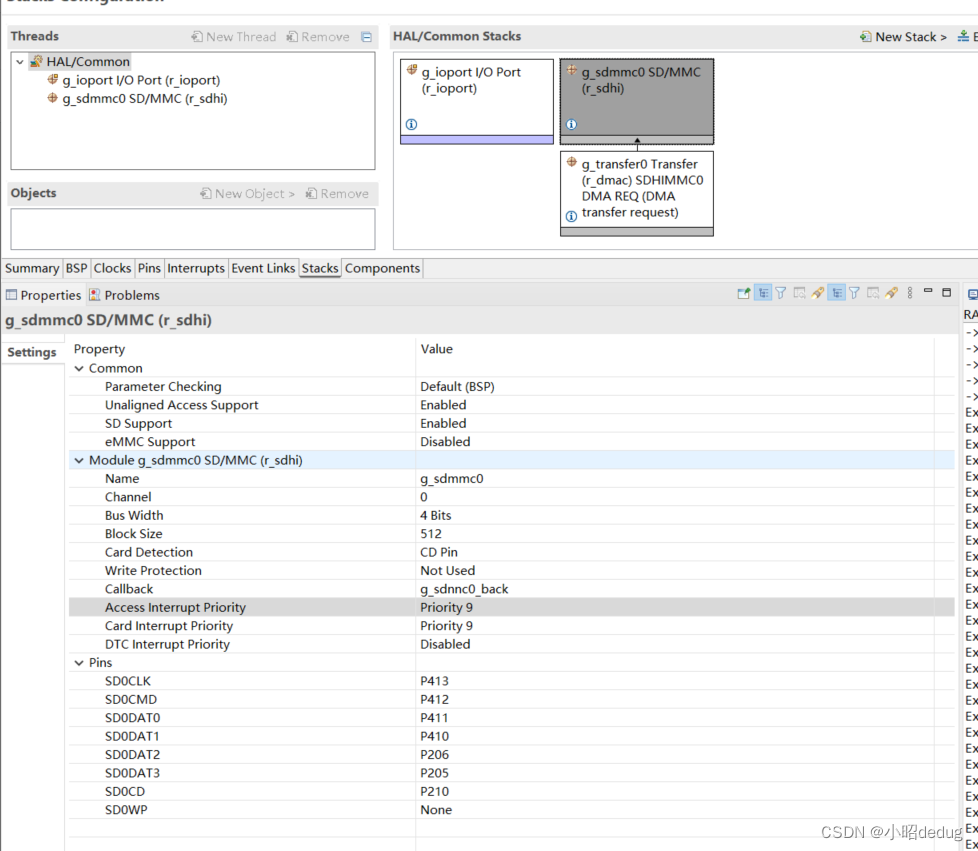
修改配置文件
-
修改/opt/module/es/config/elasticsearch.yml 文件
# 加入如下配置 #集群名称 cluster.name: cluster-es #节点名称,每个节点的名称不能重复 node.name: node-1 #ip 地址,每个节点的地址不能重复 network.host: linux1 #是不是有资格主节点 node.master: true node.data: true http.port: 9200 # head 插件需要这打开这两个配置 http.cors.allow-origin: "*" http.cors.enabled: true http.max_content_length: 200mb #es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举 master cluster.initial_master_nodes: ["node-1"] #es7.x 之后新增的配置,节点发现 discovery.seed_hosts: ["linux1:9300","linux2:9300","linux3:9300"] gateway.recover_after_nodes: 2 network.tcp.keep_alive: true network.tcp.no_delay: true transport.tcp.compress: true #集群内同时启动的数据任务个数,默认是 2 个 cluster.routing.allocation.cluster_concurrent_rebalance: 16 #添加或删除节点及负载均衡时并发恢复的线程个数,默认 4 个 cluster.routing.allocation.node_concurrent_recoveries: 16 #初始化数据恢复时,并发恢复线程的个数,默认 4 个 cluster.routing.allocation.node_initial_primaries_recoveries: 16 -
修改/etc/security/limits.conf
# 在文件末尾中增加下面内容 es soft nofile 65536 es hard nofile 65536 -
修改/etc/security/limits.d/20-nproc.conf
# 在文件末尾中增加下面内容 es soft nofile 65536 es hard nofile 65536 * hard nproc 4096 # 注:* 代表 Linux 所有用户名称 -
修改/etc/sysctl.conf
# 在文件中增加下面内容 vm.max_map_count=655360 -
重新加载
sysctl -p
启动软件
分别在不同节点上启动 ES 软件
cd /opt/module/es
#启动
bin/elasticsearch
#后台启动
bin/elasticsearch -d
测试集群

Docker开启集群
docker-compose.yml文件编写
version: '3'
services:
es01:
image: elasticsearch:7.9.3 # 使用elasticsearch:7.9.3镜像
container_name: es01 # 容器名称
environment:
- node.name=es01 # 设置节点名称
- cluster.name=mycluster # 设置集群名称
- discovery.seed_hosts=es02,es03 # 设置发现种子主机列表
- cluster.initial_master_nodes=es01,es02,es03 # 设置初始主节点列表
networks:
esnet: # 将服务放置在esnet网络中
ipv4_address: 172.20.0.2 # 分配静态IP地址
volumes:
- /path/to/data1:/usr/share/elasticsearch/data # 将数据目录映射到主机上的/path/to/data1
ports:
- "9200:9200" # 将Elasticsearch的9200端口映射到主机的9200端口
- "9300:9300" # 将Elasticsearch的9300端口映射到主机的9300端口
es02:
image: elasticsearch:7.9.3 # 使用elasticsearch:7.9.3镜像
container_name: es02 # 容器名称
environment:
- node.name=es02 # 设置节点名称
- cluster.name=mycluster # 设置集群名称
- discovery.seed_hosts=es01,es03 # 设置发现种子主机列表
- cluster.initial_master_nodes=es01,es02,es03 # 设置初始主节点列表
networks:
esnet: # 将服务放置在esnet网络中
ipv4_address: 172.20.0.3 # 分配静态IP地址
volumes:
- /path/to/data2:/usr/share/elasticsearch/data # 将数据目录映射到主机上的/path/to/data2
es03:
image: elasticsearch:7.9.3 # 使用elasticsearch:7.9.3镜像
container_name: es03 # 容器名称
environment:
- node.name=es03 # 设置节点名称
- cluster.name=mycluster # 设置集群名称
- discovery.seed_hosts=es01,es02 # 设置发现种子主机列表
- cluster.initial_master_nodes=es01,es02,es03 # 设置初始主节点列表
networks:
esnet: # 将服务放置在esnet网络中
ipv4_address: 172.20.0.4 # 分配静态IP地址
volumes:
- /path/to/data3:/usr/share/elasticsearch/data # 将数据目录映射到主机上的/path/to/data3
kibana:
image: kibana:7.9.3 # 使用kibana:7.9.3镜像
container_name: kibana # 容器名称
environment:
- ELASTICSEARCH_HOSTS=http://es01:9200 # 设置Kibana使用的Elasticsearch URL
ports:
- "5601:5601" # 将Kibana的5601端口映射到主机的5601端口
es-head:
image: mobz/elasticsearch-head:5 # 使用mobz/elasticsearch-head:5镜像
container_name: es-head # 容器名称
ports:
- "9100:9100" # 将ES-head的9100端口映射到主机的9100端口
environment:
- "ES_CONNECT=http://es01:9200" # 设置ES-head使用的Elasticsearch URL
networks:
esnet: # 将服务放置在esnet网络中
ipv4_address: 172.20.0.5 # 分配静态IP地址
networks:
esnet: # 创建名为esnet的网络
driver: bridge
ipam:
driver: default
config:
- subnet: 172.20.0.0/16 # 指定子网
gateway: 172.20.0.1 # 指定网关
启动集群
docker-compose up
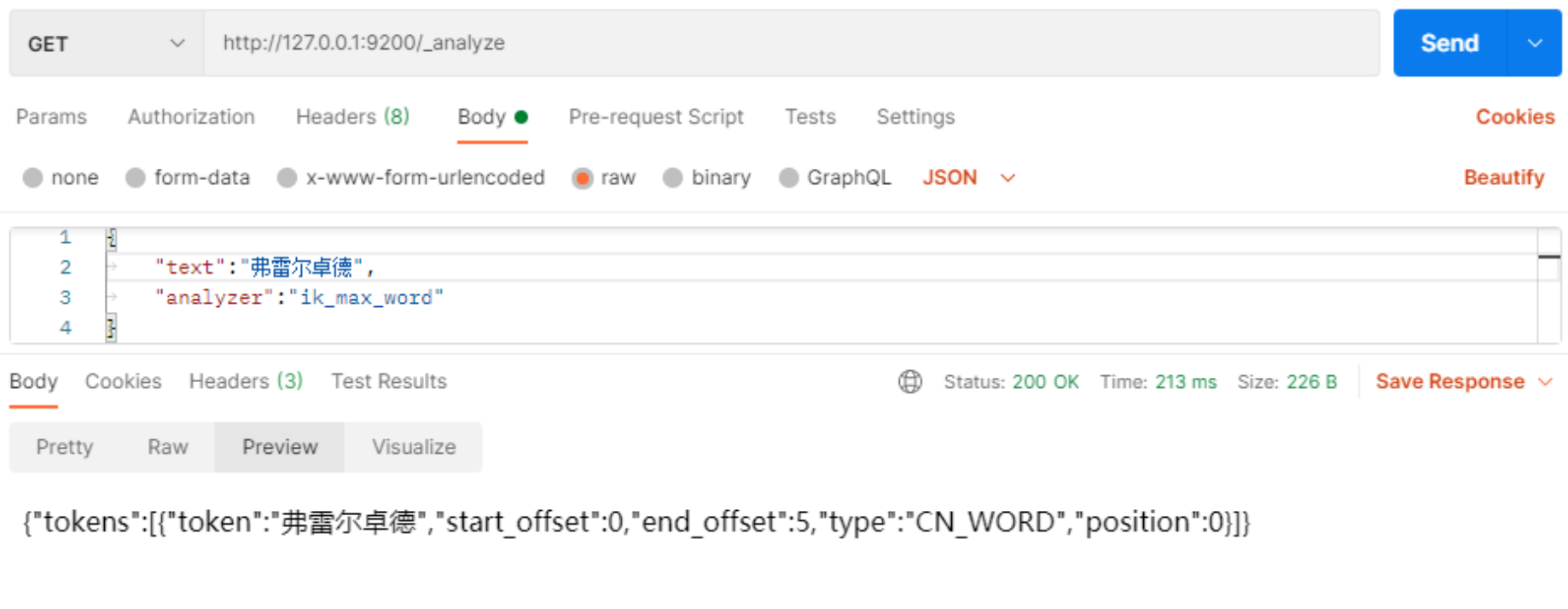
ik中文分词器->插件