目录
- Dataloader取数据过程
- 使用
- 报错:默认collate_fn处理不同长度的数据
- 自定义collate_fn伪代码示例
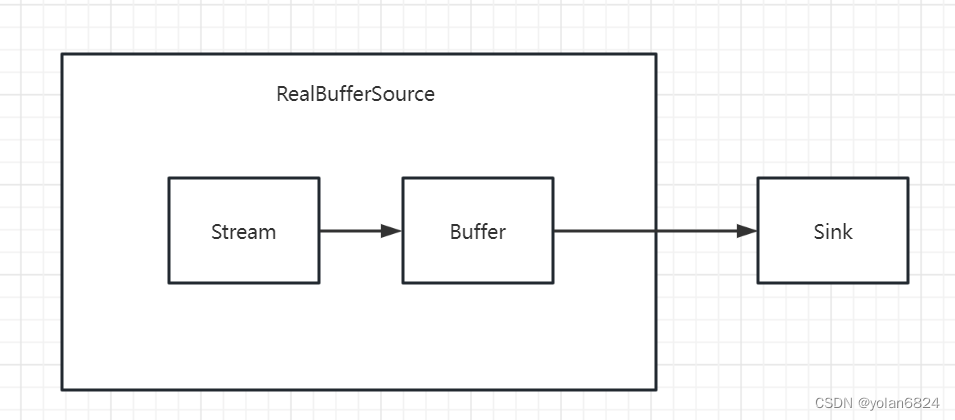
Dataloader取数据过程
- 取出大小等同于batch size的index列表;
- 将列表列表中的index输入到dataset的getitem()函数中,取出该index对应的数据;
- 对每个index对应的数据进行堆叠, 就形成了一个batch的数据.(此时可使用collate_fn进行自定义处理)
https://mp.weixin.qq.com/s/Uc2LYM6tIOY8KyxB7aQrOw
这种过程大致等效于

使用
报错:默认collate_fn处理不同长度的数据
import torch
from torch.utils.data import DataLoader, Dataset
class MyDataset(Dataset):
def __init__(self, seqs):
self.seqs = seqs
def __getitem__(self, index):
return self.seqs[index]
def __len__(self):
return len(self.seqs)
seqs = [torch.tensor([1, 2]), torch.tensor([3, 4, 5]), torch.tensor([6]), torch.tensor([7])]
batch_size = 2
# 创建数据集
dataset = MyDataset(seqs)
# 创建数据加载器
dataloader = DataLoader(dataset, batch_size=batch_size)
# 从数据加载器中取出一批数据
x = next(iter(dataloader))
print(x)
错误信息
RuntimeError: stack expects each tensor to be equal size, but got [2] at entry 0 and [3] at entry 1
错误原因:堆叠时数据长度不一致
自定义collate_fn伪代码示例
重写collate-fn函数就是手动将抽取出的样本进行自定义堆叠处理,返回自定义格式。
编写方法:
def collate_fn(batch):
# 补齐操作
def padding(indice, max_length, pad_idx=0):
pad_indice = [item + [pad_idx] * max(0, max_length - len(item)) for item in indice]
return torch.tensor(pad_indice)
data_batch = sort_batch_by_len(batch)
x = data_batch['x']
x_max_length = max([len(t) for t in x])
x_padded = padding(x, x_max_length)
x_len = torch.tensor(data_batch['x_len'])
y = data_batch['y']
y_max_length = max([len(t) for t in y])
y_padded = padding(y, y_max_length)
y_len = torch.tensor(data_batch['y_len'])
OOV = data_batch['OOV']
len_OOV = torch.tensor(data_batch['len_OOV'])
return x_padded, y_padded, x_len, y_len, OOV, len_OOV
调用方法:
DataLoader(dataset=val_data, # 原数据
batch_size=config.batch_size,
shuffle=True,
pin_memory=True,
drop_last=True,
collate_fn=collate_fn)
心得:
刚用到了collate_fn,查阅了一下资料,对于collate_fn的理解或许有偏差,如果有偏差在后续学习中将继续补充修正。
当只有不断深入理解,才有一通百通的可能。
参考
https://pytorch.org/docs/stable/data.html#dataloader-collate-fn
https://blog.csdn.net/dong_liuqi/article/details/114521240





![[已成功]在mac上安装FFmpeg,详细全过程](https://img-blog.csdnimg.cn/6f41f99ecddf4c18903b7692b8a93f13.png#pic_left)


![[EDA]AMP®-Parkinson‘s Disease Progression Prediction](https://img-blog.csdnimg.cn/1e6e6eacf50044989bd76841b3ca5bf1.png)