代码相当复杂,操作很繁琐,自己都要研究半天T_T
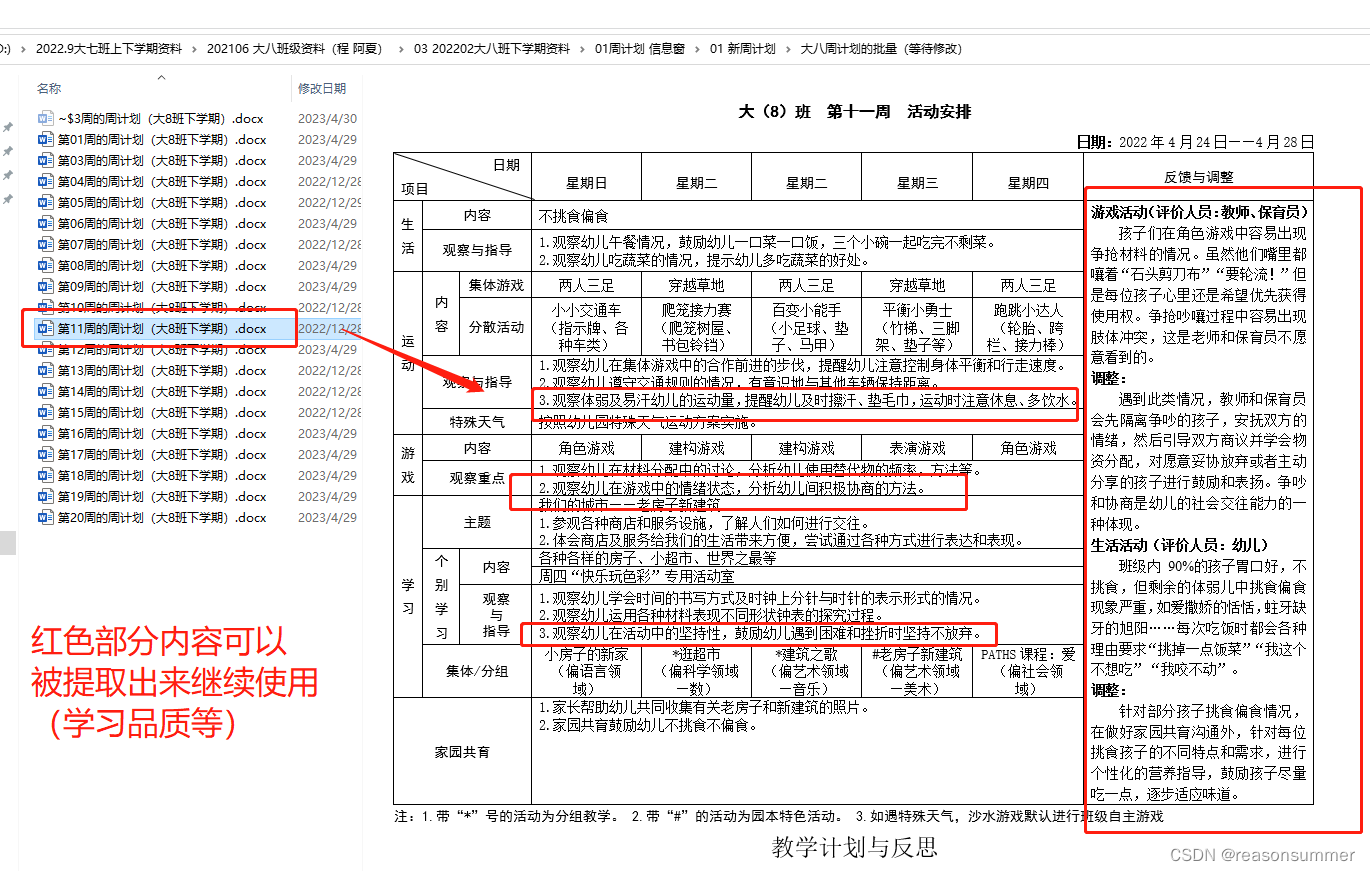
文件夹展示
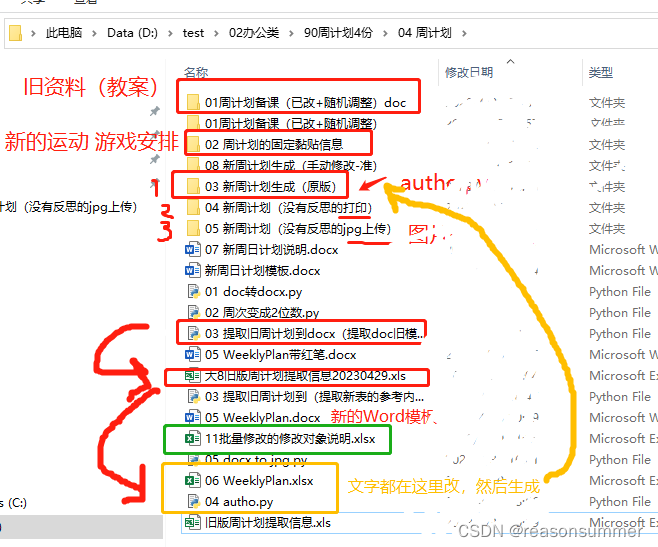
01提取提取新表的已有内容(提取大8班、大7班的新版本里面的额内容)
(需要里面的一些反思,用来占位)
这里有一份根据新模板用Python批量做过的“完整”的教案集合
一些内容可以被继续套用(手写修改的,提取出来做公共素材)
from docx import Document
import os
pathall=[]
path =r'D:\2022.9大七班上下学期资料\202106 大八班级资料(程 阿夏)\03 202202大八班下学期资料\01周计划 信息窗\01 新周计划\大八周计划的批量(等待修改)'
for file_name in os.listdir(path):
print(path+'\\'+file_name)
pathall.append(path+'\\'+file_name)
print(pathall)
print(len(pathall))# 19
# 新建EXCEL
import xlwt
f = xlwt.Workbook('encoding = utf-8')#设置工作簿编码
sheet1 = f.add_sheet('sheet1',cell_overwrite_ok=True)#创建sheet工作表
n=1
for h in range(len(pathall)): # 19份19行
path=pathall[h]
doc = Document(path)
# 获取所有表格对象
tables = doc.tables
# 获取word中第一个表格(周计划表)
table = tables[0]
print('-----提取第1张表格(周计划表)里面的内容----------')
list=[]
# 生活名称
l = table.cell(1,4).text
print(l)
# 吃点心
list.append(l)
# 生活说明(1格2行,分开) (导入做参考,实际是自己写)
ll=table.cell(2,4).text.split('\n')
print(ll)
# ['1、观察幼儿在吃点心时是否能熟练地使用夹子夹取饼干。', '2、提醒个别幼儿喝完牛奶擦嘴巴。']
# 不要“1、”、“2、”
L=[]
for lll in range(2): # 一共2条
L.append(ll[lll][2:]) # # 不要“1、”、“2、”
list.append(ll[lll][2:])
print(L)
# ['观察幼儿在吃点心时是否能熟练地使用夹子夹取饼干。', '提醒个别幼儿喝完牛奶擦嘴巴。']
# 运动=集体游戏+分散游戏 不导入,每年都在更换
# 运动观察与指导(导入做参考,实际是自己写)
s=table.cell(5,4).text.split('\n')
print(s)
# ['观察幼儿是否能双手握住曲棍杆将皮球打出一定距离。', '观察幼儿是否能寻找皮球的多种玩法。', '3、提醒幼儿注意打曲棍干的安全。']
# 有些序号是自动编号,不占字数。
S=[]
for sss in range(3): # 一共3条
S.append(s[sss][2:]) # 不要“1、”、“2、”、“3、”
list.append(s[sss][2:])
print(S)
# ['幼儿是否能双手握住曲棍杆将皮球打出一定距离。', '幼儿是否能寻找皮球的多种玩法。', '提醒幼儿注意打曲棍干的安全。']
# 游戏内容 不导入,每年都在更换
# 游戏观察与指导(导入做参考,实际是自己写)
g=table.cell(8,4).text.split('\n')
print(g)
# ['1、观察娃娃家的幼儿是否会照顾娃娃,与娃娃互动。', '2、重点观察医生在小医院游戏中,与病人的互动时能否加上一些肢体动作。', '3、观察幼儿角色游戏结束后,能否帮助其他伙伴一同整理材料。']
# 有些序号是自动编号,不占字数。
G=[]
for ggg in range(2): # 一共3条
G.append(g[ggg][2:]) # 不要“1、”、“2、”、“3、”
list.append(g[ggg][2:])
print(G)
# ['观察娃娃家的幼儿是否会照顾娃娃,与娃娃互动。', '重点观察医生在小医院游戏中,与病人的互动时能否加上一些肢体动作。', '观察幼儿角色游戏结束后,能否帮助其他伙伴一同整理材料。']
# 主题和主题说明
ti=table.cell(9,4).text.split('\n')
print(ti)
# ['春天来了', '1、了解春天是个万物生长的季节,关注自然环境的不断变化。', '2、感受大自然美丽的景像,以各种方式表达自己的情感与体验。']
# 有些序号是自动编号,不占字数。
T=[]# 第1个春天来了,不需要删除序号,直接添加
T.append(ti[0])
list.append(ti[0])
for ttt in range(1,3): # 一共2条主题说明
T.append(ti[ttt][2:]) # 不要“1、”、“2、”、
list.append(ti[ttt][2:])
print(T)
# ['春天来了', '了解春天是个万物生长的季节,关注自然环境的不断变化。', '感受大自然美丽的景像,以各种方式表达自己的情感与体验。']
# 个别化内容(3-5项) 一行多个,全部写入
iiii=table.cell(10,4).text.split('\n')
print(iiii)
list.append(iiii)
# ['三只蝴蝶、找蝴蝶、柳树姑娘的头发、春雨沙沙等']
# 个别化观察与指导(导入做参考,实际是自己写)
ii=table.cell(12,4).text.split('\n')
print(ii)
# ['1、观察幼儿是否能通过协商分配角色表演故事《三只蝴蝶》。', '2、观察幼儿是否能看懂图谱,跟着音乐打节奏。']
# 有些序号是自动编号,不占字数。
I=[]
for iii in range(3): # 一共3条
I.append(ii[iii][2:]) # 不要“1、”、“2、”、“3、”
list.append(ii[iii][2:])
print(I)
# ['观察幼儿是否能通过协商分配角色表演故事《三只蝴蝶》。', '观察幼儿是否能看懂图谱,跟着音乐打节奏。']
# 集体学习 横向五个格子
K =[]
for e in range(4,9):
k = table.cell(12,e).text
K.append(k)
list.append(k)
print(K)
# ['空中小屋\n(偏语言领域)', '花园里有什么\n(偏科学领域-探究)', '*猴子看猴子做\n(偏艺术领域-音乐)', '*借形想象\n(偏艺术领域-美术)', 'PATHS课程--赞美1(偏社会领域)']
# 家园共育(导入做参考,实际是自己写)
yy=table.cell(13,4).text.split('\n')
print(yy)
# ['1、为春游活动做准备。', '2、在家长的帮助下学习折一些纸花。', '3、天气转暖,适当地为孩子减少衣服。']
# 有些序号是自动编号,不占字数。删除2字符后,可能会少前面几个字
Y=[]
for yyy in range(2): # 一共3条
Y.append(yy[yyy][2:]) # 不要“1、”、“2、”、“3、”
list.append(yy[yyy][2:])
print(Y)
# ['为春游活动做准备。', '在家长的帮助下学习折一些纸花。', '天气转暖,适当地为孩子减少衣服。']
# # 反馈与调整(变化很大)不导入
ff=table.cell(1,8).text.split('\n')
print(ff)
for j in range(2):
# 提取活动1
list.append(ff[j*4][0:2])
# 提取身份1
list.append(ff[j*4][10:-1])
print(list)
# 提取反思1
list.append(ff[j*4+1])
print(list)
# 提取调整1
list.append(ff[j*4+3])
# print(list)
# ['1、观察幼儿是否能通过协商分配角色表演故事《三只蝴蝶》。', '2、观察幼儿是否能看懂图谱,跟着音乐打节奏。']
# 有些序号是自动编号,不占字数。
I=[]
for iii in range(3): # 一共3条
I.append(ii[iii][2:]) # 不要“1、”、“2、”、“3、”
list.append(ii[iii][2:])
print(I)
print('-----提取第2-5张表格(教案)里面的内容----------')
# 第1周、第20周,或国庆周会出现格子表格不满的情况,需要手动调整
for a in range(1,3): # 先提取2张表( 共有3张表,其中第1、2张表提取00和01,第3表提取00)
for b in range(2): # 表1有两个格子00 01 表2有两个格子00 01
table = tables[a] # 表1 表2
# 有两张表
all=table.cell(0,b).text.split('\n')
print(all)
# 提取活动名称(删除后面的执教人员)
title=all[0][5:][:-6]
list.append(title)
print(title)
# 空中小屋
# 提取活动目标(2行)删除前面的序号
topic=[]
for to in range(2,4): # 行数
topic.append(all[to][2:])
list.append(all[to][2:])
print(topic)
# ['理解故事,知道春天是竹笋快速生长的季节。', '乐意想办法帮助小狐狸解决问题,并能大胆表达自己的想法。']
# 提取活动准备(第二种准备,第一种准备需要自己写)
pre=all[4][5:]
list.append(pre)
print(pre)
# ppt、故事录音
# 提取活动过程
pro=all[6:]
print(pro)
# # 这是列表样式
# ['一、我家住几楼---导入主题,激起幼儿兴趣', '1、你们的家住在哪里?住在几楼?为什么买这么高?', '小结:是呀,住这么高的房子可以看到远远的风景。', '2、小狐狸也想住楼房,楼上的房间高高的,远远望去
# ,可以看见一片美景,那该多开心。', '二、房
# 合并列表
PRO='\n'.join(pro)
print(PRO)
list.append(PRO)
# 一、我家住几楼---导入主题,激起幼儿兴趣
# 1、你们的家住在哪里?住在几楼?为什么买这么高?
# 小结:是呀,住这么高的房子可以看到远远的风景。
# 2、小狐狸也想住楼房,楼上的房间高高的,远远望去,可以看见一片美景,那该多开心。
# 二、房子造在哪?---分段欣赏
for a in range(3,4): # 最后提取第3张表的00部分
for b in range(1): # 表1有两个格子00 01 表2有两个格子00 01
table = tables[a] # 表1 表2
# 有两张表
all=table.cell(0,b).text.split('\n')
print(all)
# 提取活动名称(删除后面的执教人员)
title=all[0][5:][:-6]
list.append(title)
print(title)
# 空中小屋
# 提取活动目标(2行)删除前面的序号
topic=[]
for t in range(2,4): # 行数
topic.append(all[t][2:])
list.append(all[t][2:])
print(topic)
# ['理解故事,知道春天是竹笋快速生长的季节。', '乐意想办法帮助小狐狸解决问题,并能大胆表达自己的想法。']
# 提取活动准备(第二种准备,第一种准备需要自己写)
pre=all[4][5:]
list.append(pre)
print(pre)
# ppt、故事录音
# 提取活动过程
pro=all[6:]
print(pro)
# # 这是列表样式
# ['一、我家住几楼---导入主题,激起幼儿兴趣', '1、你们的家住在哪里?住在几楼?为什么买这么高?', '小结:是呀,住这么高的房子可以看到远远的风景。', '2、小狐狸也想住楼房,楼上的房间高高的,远远望去
# ,可以看见一片美景,那该多开心。', '二、房
# 合并列表
PRO='\n'.join(pro)
print(PRO)
list.append(PRO)
# 一、我家住几楼---导入主题,激起幼儿兴趣
# 1、你们的家住在哪里?住在几楼?为什么买这么高?
# 小结:是呀,住这么高的房子可以看到远远的风景。
# 2、小狐狸也想住楼房,楼上的房间高高的,远远望去,可以看见一片美景,那该多开心。
# 二、房子造在哪?---分段欣赏
for c in range(2): # 表3的01有两个上下格子 表2有两个格子00 01
table = tables[3] # 表3
# 有两张表
fs=table.cell(c,1).text.split('\n')
print(fs)
# 提取反思的课程名字
# 提取活动名称(删除后面的执教人员)
fstitle=fs[1][4:][:-6]
list.append(fstitle)
# 纯反思部分(第三行开始)
fs1=fs[2:]
print(fs1)
fs3=[]
for i in range(len(fs1)):
fs4=' '+fs1[i] # 主动添加缩进2字符
print(fs4)
fs3.append(fs4)
# 合并列表
fs2='\n'.join(fs3)
print(fs2)
list.append(fs2)
print(list)
for g in range(len(list)):
# K =[1,3,4,6,8,10]#要写入的列表的值
sheet1.write(n,g,list[g])#写入数据参数对应 行,列,值
n+=1
f.save(r'D:\test\02办公类\90周计划4份\04 周计划\大8旧版周计划提取信息.xls')#保存.x1s到当前工作目录
doc.save(path)
二、提取旧模板(doc旧模板,内容要补充)
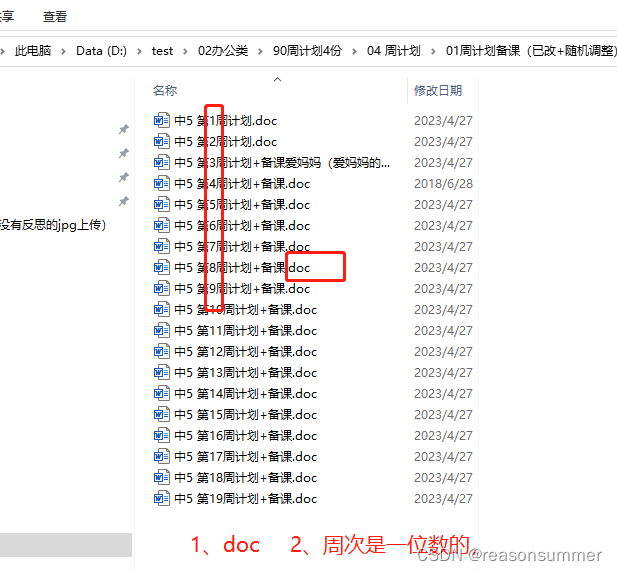
过去做的都是大班一套上下学期,这次我是中班,就要重新找中班以前的教案集合进行修改
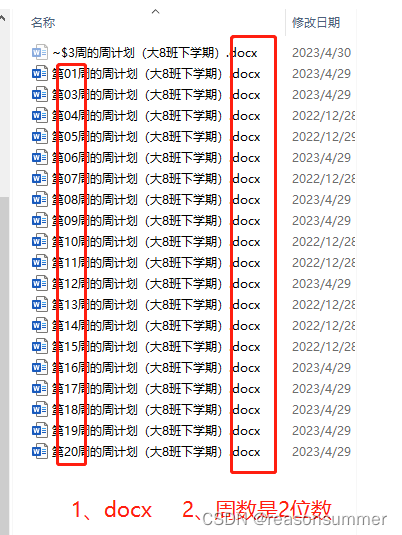
(以前的教案基本都是doc格式、而且周数是一位数)
旧样式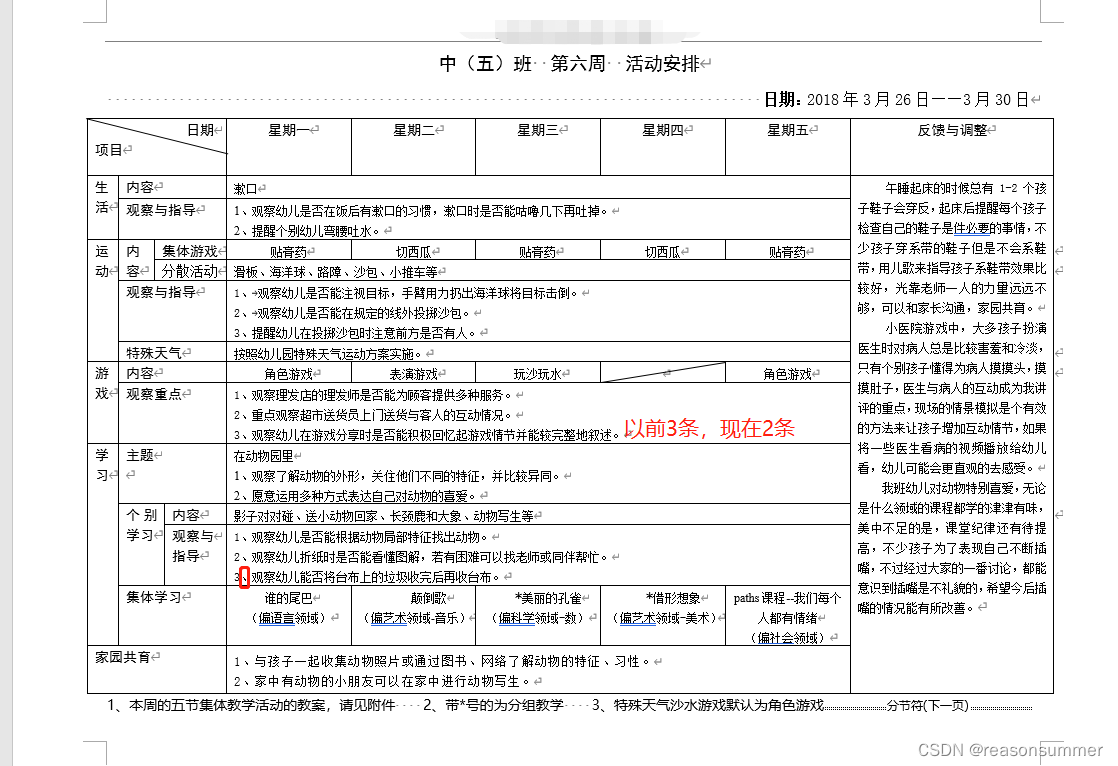
新样式
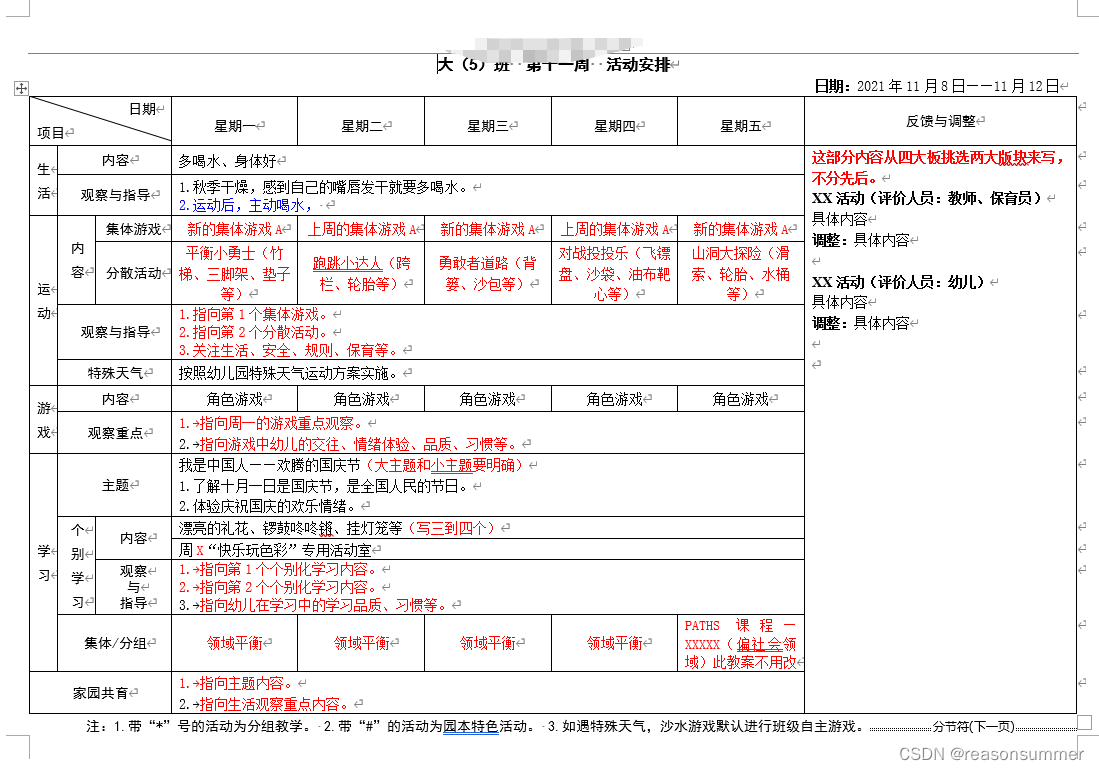
(新模板框架变化不大,但是里面填写内容很细碎、人工书写一定有很多的遗漏,用Python批量做可以批量统一处理这些细节——如字体、段落、居中、缩进等等。大大减少遗漏率
from docx import Document
import os
pathall=[]
path =r'D:\test\02办公类\90周计划4份\04 周计划\01周计划备课(已改+随机调整)'
for file_name in os.listdir(path):
print(path+'\\'+file_name)
pathall.append(path+'\\'+file_name)
print(pathall)
print(len(pathall))# 19
# 新建EXCEL
import xlwt
f = xlwt.Workbook('encoding = utf-8')#设置工作簿编码
sheet1 = f.add_sheet('sheet1',cell_overwrite_ok=True)#创建sheet工作表
n=1
for t in range(len(pathall)): # 19份19行
path=pathall[t]
doc = Document(path)
# 获取所有表格对象
tables = doc.tables
# 获取word中第一个表格(周计划表)
table = tables[0]
print('-----提取第1张表格(周计划表)里面的内容----------')
list=[]
# 生活名称
l = table.cell(1,4).text
print(l)
# 吃点心
list.append(l)
# 生活说明(1格2行,分开) (导入做参考,实际是自己写)
ll=table.cell(2,4).text.split('\n')
print(ll)
# ['1、观察幼儿在吃点心时是否能熟练地使用夹子夹取饼干。', '2、提醒个别幼儿喝完牛奶擦嘴巴。']
# 不要“1、”、“2、”
L=[]
for lll in range(2): # 一共2条
L.append(ll[lll][2:]) # # 不要“1、”、“2、”
list.append(ll[lll][2:])
print(L)
# ['观察幼儿在吃点心时是否能熟练地使用夹子夹取饼干。', '提醒个别幼儿喝完牛奶擦嘴巴。']
# 运动=集体游戏+分散游戏 不导入,每年都在更换
# 运动观察与指导(导入做参考,实际是自己写)
s=table.cell(5,4).text.split('\n')
print(s)
# ['观察幼儿是否能双手握住曲棍杆将皮球打出一定距离。', '观察幼儿是否能寻找皮球的多种玩法。', '3、提醒幼儿注意打曲棍干的安全。']
# 有些序号是自动编号,不占字数。
S=[]
for sss in range(3): # 一共3条
S.append(s[sss][2:]) # 不要“1、”、“2、”、“3、”
list.append(s[sss][2:])
print(S)
# ['幼儿是否能双手握住曲棍杆将皮球打出一定距离。', '幼儿是否能寻找皮球的多种玩法。', '提醒幼儿注意打曲棍干的安全。']
# 游戏内容 不导入,每年都在更换
# 游戏观察与指导(导入做参考,实际是自己写)
g=table.cell(8,4).text.split('\n')
print(g)
# ['1、观察娃娃家的幼儿是否会照顾娃娃,与娃娃互动。', '2、重点观察医生在小医院游戏中,与病人的互动时能否加上一些肢体动作。', '3、观察幼儿角色游戏结束后,能否帮助其他伙伴一同整理材料。']
# 有些序号是自动编号,不占字数。
G=[]
for ggg in range(3): # 一共3条
G.append(g[ggg][2:]) # 不要“1、”、“2、”、“3、”
list.append(g[ggg][2:])
print(G)
# ['观察娃娃家的幼儿是否会照顾娃娃,与娃娃互动。', '重点观察医生在小医院游戏中,与病人的互动时能否加上一些肢体动作。', '观察幼儿角色游戏结束后,能否帮助其他伙伴一同整理材料。']
# 主题和主题说明
t=table.cell(9,4).text.split('\n')
print(t)
# ['春天来了', '1、了解春天是个万物生长的季节,关注自然环境的不断变化。', '2、感受大自然美丽的景像,以各种方式表达自己的情感与体验。']
# 有些序号是自动编号,不占字数。
T=[]# 第1个春天来了,不需要删除序号,直接添加
T.append(t[0])
list.append(t[0])
for ttt in range(1,3): # 一共2条主题说明
T.append(t[ttt][2:]) # 不要“1、”、“2、”、
list.append(t[ttt][2:])
print(T)
# ['春天来了', '了解春天是个万物生长的季节,关注自然环境的不断变化。', '感受大自然美丽的景像,以各种方式表达自己的情感与体验。']
# 个别化内容(3-5项) 一行多个,全部写入
iiii=table.cell(10,4).text.split('\n')
print(iiii)
list.append(iiii)
# ['三只蝴蝶、找蝴蝶、柳树姑娘的头发、春雨沙沙等']
# 个别化观察与指导(导入做参考,实际是自己写)
ii=table.cell(11,4).text.split('\n')
print(ii)
# ['1、观察幼儿是否能通过协商分配角色表演故事《三只蝴蝶》。', '2、观察幼儿是否能看懂图谱,跟着音乐打节奏。']
# 有些序号是自动编号,不占字数。
I=[]
for iii in range(2): # 一共3条
I.append(ii[iii][2:]) # 不要“1、”、“2、”、“3、”
list.append(ii[iii][2:])
print(I)
# ['观察幼儿是否能通过协商分配角色表演故事《三只蝴蝶》。', '观察幼儿是否能看懂图谱,跟着音乐打节奏。']
# 集体学习 横向五个格子
K =[]
for e in range(4,9):
k = table.cell(12,e).text
K.append(k)
list.append(k)
print(K)
['空中小屋\n(偏语言领域)', '花园里有什么\n(偏科学领域-探究)', '*猴子看猴子做\n(偏艺术领域-音乐)', '*借形想象\n(偏艺术领域-美术)', 'PATHS课程--赞美1(偏社会领域)']
# 家园共育(导入做参考,实际是自己写)
# 个别化观察与指导(导入做参考,实际是自己写)
yy=table.cell(13,4).text.split('\n')
print(yy)
# ['1、为春游活动做准备。', '2、在家长的帮助下学习折一些纸花。', '3、天气转暖,适当地为孩子减少衣服。']
# 有些序号是自动编号,不占字数。删除2字符后,可能会少前面几个字
Y=[]
for yyy in range(2): # 一共3条
Y.append(yy[yyy][2:]) # 不要“1、”、“2、”、“3、”
list.append(yy[yyy][2:])
print(Y)
# ['为春游活动做准备。', '在家长的帮助下学习折一些纸花。', '天气转暖,适当地为孩子减少衣服。']
# 反馈与调整(变化很大)不导入
print('-----提取第2-5张表格(教案)里面的内容----------')
# 第1周、第20周,或国庆周会出现格子表格不满的情况,需要手动调整
for a in range(1,3): # 先提取2张表( 共有3张表,其中第1、2张表提取00和01,第3表提取00)
for b in range(2): # 表1有两个格子00 01 表2有两个格子00 01
table = tables[a] # 表1 表2
# 有两张表
all=table.cell(0,b).text.split('\n')
print(all)
# 提取活动名称(删除后面的执教人员)
title=all[0][5:][:-6]
list.append(title)
print(title)
# 空中小屋
# 提取活动目标(2行)删除前面的序号
topic=[]
for t in range(2,4): # 行数
topic.append(all[t][2:])
list.append(all[t][2:])
print(topic)
# ['理解故事,知道春天是竹笋快速生长的季节。', '乐意想办法帮助小狐狸解决问题,并能大胆表达自己的想法。']
# 提取活动准备(第二种准备,第一种准备需要自己写)
pre=all[4][5:]
list.append(pre)
print(pre)
# ppt、故事录音
# 提取活动过程
pro=all[6:]
print(pro)
# # 这是列表样式
# ['一、我家住几楼---导入主题,激起幼儿兴趣', '1、你们的家住在哪里?住在几楼?为什么买这么高?', '小结:是呀,住这么高的房子可以看到远远的风景。', '2、小狐狸也想住楼房,楼上的房间高高的,远远望去
# ,可以看见一片美景,那该多开心。', '二、房
# 合并列表
PRO='\n'.join(pro)
print(PRO)
list.append(PRO)
# 一、我家住几楼---导入主题,激起幼儿兴趣
# 1、你们的家住在哪里?住在几楼?为什么买这么高?
# 小结:是呀,住这么高的房子可以看到远远的风景。
# 2、小狐狸也想住楼房,楼上的房间高高的,远远望去,可以看见一片美景,那该多开心。
# 二、房子造在哪?---分段欣赏
for a in range(3,4): # 最后提取第3张表的00部分
for b in range(1): # 表1有两个格子00 01 表2有两个格子00 01
table = tables[a] # 表1 表2
# 有两张表
all=table.cell(0,b).text.split('\n')
print(all)
# 提取活动名称(删除后面的执教人员)
title=all[0][5:][:-6]
list.append(title)
print(title)
# 空中小屋
# 提取活动目标(2行)删除前面的序号
topic=[]
for t in range(2,4): # 行数
topic.append(all[t][2:])
list.append(all[t][2:])
print(topic)
# ['理解故事,知道春天是竹笋快速生长的季节。', '乐意想办法帮助小狐狸解决问题,并能大胆表达自己的想法。']
# 提取活动准备(第二种准备,第一种准备需要自己写)
pre=all[4][5:]
list.append(pre)
print(pre)
# ppt、故事录音
# 提取活动过程
pro=all[6:]
print(pro)
# # 这是列表样式
# ['一、我家住几楼---导入主题,激起幼儿兴趣', '1、你们的家住在哪里?住在几楼?为什么买这么高?', '小结:是呀,住这么高的房子可以看到远远的风景。', '2、小狐狸也想住楼房,楼上的房间高高的,远远望去
# ,可以看见一片美景,那该多开心。', '二、房
# 合并列表
PRO='\n'.join(pro)
print(PRO)
list.append(PRO)
# 一、我家住几楼---导入主题,激起幼儿兴趣
# 1、你们的家住在哪里?住在几楼?为什么买这么高?
# 小结:是呀,住这么高的房子可以看到远远的风景。
# 2、小狐狸也想住楼房,楼上的房间高高的,远远望去,可以看见一片美景,那该多开心。
# 二、房子造在哪?---分段欣赏
for c in range(2): # 表3的01有两个上下格子 表2有两个格子00 01
table = tables[3] # 表3
# 有两张表
fs=table.cell(c,1).text.split('\n')
print(fs)
# 提取反思的课程名字
# 提取活动名称(删除后面的执教人员)
fstitle=fs[1][4:][:-6]
list.append(fstitle)
# 纯反思部分(第三行开始)
fs1=fs[2:]
print(fs1)
fs3=[]
for i in range(len(fs1)):
fs4=' '+fs1[i] # 主动添加缩进2字符
print(fs4)
fs3.append(fs4)
# 合并列表
fs2='\n'.join(fs3)
print(fs2)
list.append(fs2)
print(list)
for g in range(len(list)):
# K =[1,3,4,6,8,10]#要写入的列表的值
sheet1.write(n,g,list[g])#写入数据参数对应 行,列,值
n+=1
f.save(r'D:\test\02办公类\90周计划4份\04 周计划\旧版周计划提取信息.xls')#保存.x1s到当前工作目录
doc.save(path)
三、生成本学期本班用周计划20份
# 一、导入相关模块,设定excel所在文件夹和生成word保存的文件夹
from docxtpl import DocxTemplate
import pandas as pd
import os
zpath=os.getcwd()+'\\'
zpath=r'D:\test\02办公类\90周计划4份\04 周计划'+'\\'
# zpath=r'D:\test\05批量改名字程序\00周计划批量'+'\\'
# 生成的新周计划所在文件夹
file_path=zpath+r'\03 新周计划生成(原版)'
# 二、遍历excel,逐个生成word(WeeklyPlan.docx.docx是前面的模板)
try:
os.mkdir(file_path)
except:
pass
tpl = DocxTemplate(zpath+'05 WeeklyPlan.docx')
WeeklyPlan = pd.read_excel(zpath+'06 WeeklyPlan.xlsx')
grade = WeeklyPlan["grade"].str.rstrip()
classnum =WeeklyPlan["classnum"] # 没有str.rstrip()是数字格式
weekhan =WeeklyPlan["weekhan"].str.rstrip() # str.rstrip()都是文字格式
# day=WeeklyPlan["day"].str.rstrip()
sc =WeeklyPlan["sc"].str.rstrip()
datelong =WeeklyPlan["datelong"].str.rstrip()
dateshort=WeeklyPlan["dateshort"].str.rstrip()
weekshu=WeeklyPlan["weekshu"]# 没有str.rstrip()是数字格式
day1 = WeeklyPlan["day1"].str.rstrip()
day2 = WeeklyPlan["day3"].str.rstrip()
day3 = WeeklyPlan["day3"].str.rstrip()
day4 = WeeklyPlan["day4"].str.rstrip()
day5 = WeeklyPlan["day5"].str.rstrip()
T1 = WeeklyPlan["T1"].str.rstrip()
T2 = WeeklyPlan["T2"].str.rstrip()
life = WeeklyPlan["life"].str.rstrip()
life1 = WeeklyPlan["life1"].str.rstrip()
life2 = WeeklyPlan["life2"].str.rstrip()
sportcon1 = WeeklyPlan["sportcon1"].str.rstrip()
sportcon2 = WeeklyPlan["sportcon2"].str.rstrip()
sportcon3 = WeeklyPlan["sportcon3"].str.rstrip()
sportcon4 = WeeklyPlan["sportcon4"].str.rstrip()
sportcon5 = WeeklyPlan["sportcon5"].str.rstrip()
sport1 = WeeklyPlan["sport1"].str.rstrip()
sport2 = WeeklyPlan["sport2"].str.rstrip()
sport3 = WeeklyPlan["sport3"].str.rstrip()
sport4 = WeeklyPlan["sport4"].str.rstrip()
sport5 = WeeklyPlan["sport5"].str.rstrip()
sportzd1 = WeeklyPlan["sportzd1"].str.rstrip()
sportzd2 = WeeklyPlan["sportzd2"].str.rstrip()
sportzd3 = WeeklyPlan["sportzd3"].str.rstrip()
game1 = WeeklyPlan["game1"].str.rstrip()
game2 = WeeklyPlan["game2"].str.rstrip()
game3 = WeeklyPlan["game3"].str.rstrip()
game4 = WeeklyPlan["game4"].str.rstrip()
game5 = WeeklyPlan["game5"].str.rstrip()
gamezd1 = WeeklyPlan["gamezd1"].str.rstrip()
gamezd2 = WeeklyPlan["gamezd2"].str.rstrip()
theme= WeeklyPlan["theme"].str.rstrip()
theme1= WeeklyPlan["theme1"].str.rstrip()
theme2= WeeklyPlan["theme2"].str.rstrip()
gbstudy = WeeklyPlan["gbstudy"].str.rstrip()
art = WeeklyPlan["art"].str.rstrip()
gbstudy1 = WeeklyPlan["gbstudy1"].str.rstrip()
gbstudy2 = WeeklyPlan["gbstudy2"].str.rstrip()
gbstudy3 = WeeklyPlan["gbstudy3"].str.rstrip()
jtstudy1 = WeeklyPlan["jtstudy1"].str.rstrip()
jtstudy2 = WeeklyPlan["jtstudy2"].str.rstrip()
jtstudy3 = WeeklyPlan["jtstudy3"].str.rstrip()
jtstudy4 = WeeklyPlan["jtstudy4"].str.rstrip()
jtstudy5 = WeeklyPlan["jtstudy5"].str.rstrip()
gy1 = WeeklyPlan["gy1"].str.rstrip()
gy2 = WeeklyPlan["gy2"].str.rstrip()
fk1 = WeeklyPlan["fk1"].str.rstrip()
pj11 = WeeklyPlan["pj11"].str.rstrip()
fk1nr = WeeklyPlan["fk1nr"].str.rstrip()
fk1tz = WeeklyPlan["fk1tz"].str.rstrip()
fk2 = WeeklyPlan["fk2"].str.rstrip()
pj21= WeeklyPlan["pj21"].str.rstrip()
fk2nr = WeeklyPlan["fk2nr"].str.rstrip()
fk2tz = WeeklyPlan["fk2tz"].str.rstrip()
title1 = WeeklyPlan["title1"].str.rstrip()
topic11 = WeeklyPlan["topic11"].str.rstrip()
topic12 = WeeklyPlan["topic12"].str.rstrip()
pre1 = WeeklyPlan["pre1"].str.rstrip()
j1gc= WeeklyPlan["j1gc"].str.rstrip()
title2 = WeeklyPlan["title2"].str.rstrip()
topic21 = WeeklyPlan["topic21"].str.rstrip()
topic22 = WeeklyPlan["topic22"].str.rstrip()
pre2 = WeeklyPlan["pre2"].str.rstrip()
j2gc= WeeklyPlan["j2gc"].str.rstrip()
title3 = WeeklyPlan["title3"].str.rstrip()
topic31 = WeeklyPlan["topic31"].str.rstrip()
topic32 = WeeklyPlan["topic32"].str.rstrip()
pre3 = WeeklyPlan["pre3"].str.rstrip()
j3gc= WeeklyPlan["j3gc"].str.rstrip()
title4 = WeeklyPlan["title4"].str.rstrip()
topic41 = WeeklyPlan["topic41"].str.rstrip()
topic42 = WeeklyPlan["topic42"].str.rstrip()
pre4 = WeeklyPlan["pre4"].str.rstrip()
j4gc= WeeklyPlan["j4gc"].str.rstrip()
title5 = WeeklyPlan["title5"].str.rstrip()
topic51 = WeeklyPlan["topic51"].str.rstrip()
topic52 = WeeklyPlan["topic52"].str.rstrip()
pre5 = WeeklyPlan["pre5"].str.rstrip()
j5gc= WeeklyPlan["j5gc"].str.rstrip()
fs1 = WeeklyPlan["fs1"].str.rstrip()
fs11= WeeklyPlan["fs11"].str.rstrip()
fs2= WeeklyPlan["fs2"].str.rstrip()
fs21= WeeklyPlan["fs21"].str.rstrip()
# 遍历excel行,逐个生成
num = WeeklyPlan.shape[0]
for i in range(num):
context = {
"grade": grade[i],
"classnum": classnum[i],
"weekhan": weekhan[i],
# "day": day[i],
"sc": sc[i],
"datelong": datelong[i],
"dateshort": dateshort[i],
"weekshu": weekshu[i],
"day1": day1[i],
"day2": day2[i],
"day3": day3[i],
"day4": day4[i],
"day5": day5[i],
"T1": T1[i],
"T2": T2[i],
"life": life[i],
"life1": life1[i],
"life2": life2[i],
"sportcon1": sportcon1[i],
"sportcon2": sportcon2[i],
"sportcon3": sportcon3[i],
"sportcon4": sportcon4[i],
"sportcon5": sportcon5[i],
"weekshu": weekshu[i],
"sport1": sport1[i],
"sport2": sport2[i],
"sport3": sport3[i],
"sport4": sport4[i],
"sport5": sport5[i],
"sportzd1": sportzd1[i],
"sportzd2": sportzd2[i],
"sportzd3": sportzd3[i],
"game1": game1[i],
"game2": game2[i],
"game3": game3[i],
"game4": game4[i],
"game5": game5[i],
"gamezd1": gamezd1[i],
"gamezd2": gamezd2[i],
"theme": theme[i],
"theme1": theme1[i],
"theme2": theme2[i],
"gbstudy": gbstudy[i],
"art": art[i],
"gbstudy1": gbstudy1[i],
"gbstudy2": gbstudy2[i],
"gbstudy3": gbstudy3[i],
"jtstudy1": jtstudy1[i],
"jtstudy2": jtstudy2[i],
"jtstudy3": jtstudy3[i],
"jtstudy4": jtstudy4[i],
"jtstudy5": jtstudy5[i],
"gy1": gy1[i],
"gy2": gy2[i],
"fk1": fk1[i],
"pj11": pj11[i],
"fk1nr": fk1nr[i],
"fk1tz": fk1tz[i],
"fk2": fk2[i],
"pj21": pj21[i],
"fk2nr": fk2nr[i],
"fk2tz":fk2tz[i],
"title1":title1[i],
"topic11":topic11[i],
"topic12":topic12[i],
"pre1":pre1[i],
"j1gc": j1gc[i],
"title2":title2[i],
"topic21":topic21[i],
"topic22":topic22[i],
"pre2":pre2[i],
"j2gc": j2gc[i],
"title3":title3[i],
"topic31":topic31[i],
"topic32":topic32[i],
"pre3":pre3[i],
"j3gc": j3gc[i],
"title4":title4[i],
"topic41":topic41[i],
"topic42":topic42[i],
"pre4":pre4[i],
"j4gc": j4gc[i],
"title5":title5[i],
"topic51":topic51[i],
"topic52":topic52[i],
"pre5":pre5[i],
"j5gc": j5gc[i],
"fs1": fs1[i],
"fs11": fs11[i],
"fs2": fs2[i],
"fs21": fs21[i]
}
tpl = DocxTemplate(zpath+'05 WeeklyPlan.docx')
tpl.render(context)
tpl.save(file_path+r"\{} 第{}周 周计划({})({}{}班下学期).docx".format('%02d'%weekshu[i],weekhan[i],sc[i],grade[i],classnum[i]))
四、把周计划第一页(周计划部分)变成图片(上传园园通)

'''
作者:毛毛
性质:转载
原网址 https://zhuanlan.zhihu.com/p/367985422
安装python,确保以下模块已经安装:win32com,fitz,re
在桌面新建文件夹,命名为:word2pdf2png
将需要转换的word(只能docx格式,可以多个)放入文件夹word2pdf2png
复制以下代码并运行。
本代码只生成png 文件夹内只有一级,子文件不生成
说明:
1、
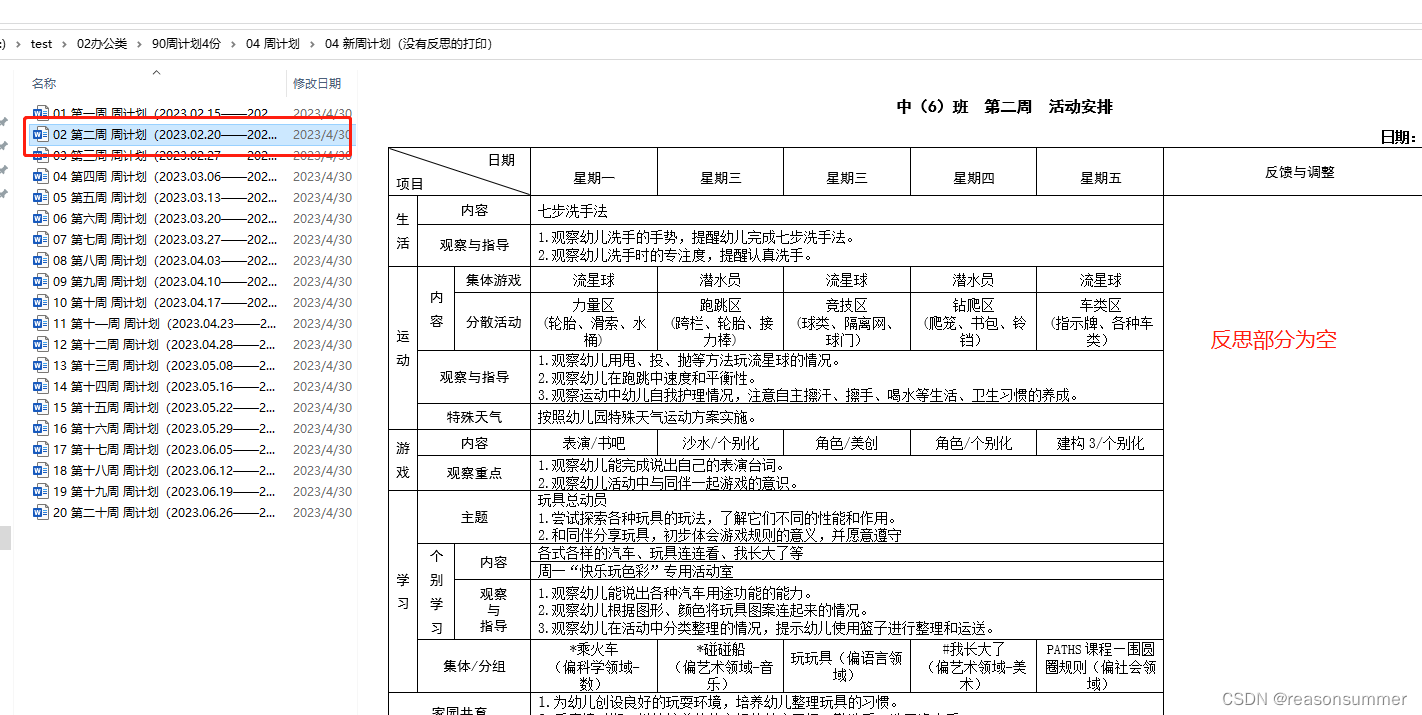
2、把“03 新周计划生成(原版)”的内容复制到“04 新周计划(没有反思的打印)”
3、把“04 新周计划(没有反思的打印)”内容复制到“05 新周计划(没有反思的jpg上传)”
4、然后“05 新周计划(没有反思的jpg上传)”文件夹删除并生成第一张无反思的图片20份
5、空余时间。把““03 新周计划生成(原版)”文件夹的内容复制到“08 新周计划生成(手动修改-准)”文件夹,手动修改
(1)周计划第一页反思(限定在一页内)
(2)教案等
'''
#coding=utf-8
from win32com.client import Dispatch
import os
import re
import fitz
wdFormatPDF = 17 #转换的类型
zoom_x=2 #尺寸大小,越大图片越清晰 5超大,这里改成2
zoom_y=2 #尺寸大小,越大图片越清晰,长宽保持一致
rotation_angle=0#旋转的角度,0为不旋转
# import os
# #导入os模块
# save_path=r"D:\test\02办公类\90周计划4份\04 周计划\03 docx to jpg"
# #在桌面上创建文件夹
# if os.path.exists(save_path):#判断文件夹是否存在
# print(f'文件夹{save_path}已存在!')
# else:
# print(f'文件夹{save_path}不存在,可以创建')
# os.mkdir(save_path)#创建文件夹
# 把(原版)文件夹里的资料复制到(没有反思的打印)
#coding=utf-8
import os
import shutil
old_path = r'D:\test\02办公类\90周计划4份\04 周计划\03 新周计划生成(原版)' # 要复制的文件所在目录
new_path = r'D:\test\02办公类\90周计划4份\04 周计划\04 新周计划(没有反思的打印)' #新路径
def FindFile(path):
for ipath in os.listdir(path):
fulldir = os.path.join(path, ipath) # 拼接成绝对路径
print(fulldir) #打印相关后缀的文件路径及名称
if os.path.isfile(fulldir): # 文件,匹配->打印
shutil.copy(fulldir,new_path)
if os.path.isdir(fulldir): # 目录,递归
FindFile(fulldir)
FindFile(old_path)
# 把(没有反思的打印)文件夹里面所有的文档中的1,8格子里面的内容全部删除(不要反思)
from docx import Document
import os
pathall=[]
path =r'D:\test\02办公类\90周计划4份\04 周计划\04 新周计划(没有反思的打印)'
for file_name in os.listdir(path):
print(path+'\\'+file_name)
pathall.append(path+'\\'+file_name)
print(pathall)
print(len(pathall))# 19
for h in range(len(pathall)): # 19份19行
path=pathall[h]
doc = Document(path)
# 获取所有表格对象
tables = doc.tables
# 获取word中第一个表格(周计划表)
table = tables[0]
# # 反馈与调整(变化很大)不导入
table.cell(1,8).text=' '
doc.save(path) # 重新保存docx(此时没有反思)
# 把“没有反思的docx”复制到“JPG上传”文件夹里
import os
import shutil
old_path2 = r'D:\test\02办公类\90周计划4份\04 周计划\04 新周计划(没有反思的打印)' # 要复制的文件所在目录
new_path2 = r'D:\test\02办公类\90周计划4份\04 周计划\05 新周计划(没有反思的jpg上传)' #新路径
def FindFile2(path2):
for ipath2 in os.listdir(path2):
fulldir2 = os.path.join(path2, ipath2) # 拼接成绝对路径
print(fulldir2) #打印相关后缀的文件路径及名称
if os.path.isfile(fulldir2): # 文件,匹配->打印
shutil.copy(fulldir2,new_path2)
if os.path.isdir(fulldir2): # 目录,递归
FindFile(fulldir2)
FindFile2(old_path2)
#生成PDF和图片
def doc2pdf2png(input_file):
for root, dirs, files in os.walk(input_file):
for file in files:
if re.search('\.(docx|doc)$', file):
filename = os.path.abspath(root + "\\" + file)
print('filename', filename)
word = Dispatch('Word.Application')
doc = word.Documents.Open(filename)
doc.SaveAs(filename.replace(".docx", ".pdf"), FileFormat=wdFormatPDF)
doc.Close()
word.Quit()
for root, dirs, files in os.walk(input_file):
for file in files:
if re.search('\.pdf$', file):
filename = os.path.abspath(root + "\\" + file)
print('filename', filename)
# 打开PDF文件
pdf = fitz.open(filename)
# 逐页读取PDF
for pg in range(0, pdf.pageCount):
page = pdf[pg]
# 设置缩放和旋转系数
trans = fitz.Matrix(zoom_x, zoom_y).preRotate(rotation_angle)
pm = page.getPixmap(matrix=trans, alpha=False)
# 开始写图像
pm.writePNG(filename.replace('.pdf', '') + str(pg+1) + ".png")
pdf.close()
doc2pdf2png(r'D:\test\02办公类\90周计划4份\04 周计划\05 新周计划(没有反思的jpg上传)')
# 删除生成文件PDF 和 生成文件docx
for parent, dirnames, filenames in os.walk('D:/test/02办公类/90周计划4份/04 周计划/05 新周计划(没有反思的jpg上传)'):
for fn in filenames:
if fn.lower().endswith('.pdf'):
os.remove(os.path.join(parent, fn))
if fn.lower().endswith('.docx'):# 删除原始文件docx 正则[pdf|docx]套不上,只能分成两条了
os.remove(os.path.join(parent, fn))
# 删除png中,尾号是2-8的png(Word只要第一页,后面生成的第二页图片不要
for parent, dirnames, filenames in os.walk('D:/test/02办公类/90周计划4份/04 周计划/05 新周计划(没有反思的jpg上传)'):
for fn in filenames:
for k in range(2,9): # png文件名的尾数是2,3,4,5,6,7,8 不确定共有几页,可以把9这个数字写大一点)
if fn.lower().endswith(f'{k}.png'): # 删除尾号为2,3,4,5,6,7,8的png图片 f{k}='{}'.formart(k)
os.remove(os.path.join(parent, fn))








![[已成功]在mac上安装FFmpeg,详细全过程](https://img-blog.csdnimg.cn/6f41f99ecddf4c18903b7692b8a93f13.png#pic_left)


![[EDA]AMP®-Parkinson‘s Disease Progression Prediction](https://img-blog.csdnimg.cn/1e6e6eacf50044989bd76841b3ca5bf1.png)