数据库设计三范式
范式是数据库设计时遵循的一种规范,不同的规范需要遵循不同的范式,只有充分遵循了数据库设计的范式,才能设计开发出冗余较小、高效、结构合理的数据库。
通常,我们在设计数据库的时候会要求遵循三范式。
第一范式(1NF)
如果数据库表中的所有字段值都是不可分解的原子值,就说明该数据库表满足了第一范式(1NF)。
在关系型数据库的设计中,满足第一范式(1NF)是数据库设计的基本要求,也就是说只有满足了第一范式(1NF)的数据库才能叫做关系数据库。
满足第一范式的目的就是确保每列保持原子性。
例子1:
设计一张“员工”表,设计如下:
| empId | empName | age | sex | address |
|---|---|---|---|---|
| 1 | 小明 | 26 | m | 浙江省杭州市 |
| 2 | 小李 | 28 | f | 安徽省合肥市 |
| 3 | 小黄 | 31 | f | 江苏省扬州市 |
这张表的设计就不符合第一范式(1NF),因为“地址”这个属性可以继续拆分成“省份”和“城市”两个属性,假设有一天公司需要统计来自某个省份或者某个城市的所有员工信息的话,这样分类就非常方便了。
满足第一范式(1NF)的员工表重新设计如下:
| empId | empName | age | sex | province | city |
|---|---|---|---|---|---|
| 1 | 小明 | 26 | m | 浙江省 | 杭州市 |
| 2 | 小李 | 28 | f | 安徽省 | 合肥市 |
| 3 | 小黄 | 31 | f | 江苏省 | 扬州市 |
第二范式(2NF)
第二范式(2NF)是在第一范式(1NF)的基础之上更进一步。第二范式需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)。也就是说在一个数据库表中,一个表中只能保存一种数据,不可以把多种数据保存在同一张数据库表中。
比如有一张“学生课程成绩”表:
| stuId | stuName | age | sex | courseId | courseName | score | credit |
|---|---|---|---|---|---|---|---|
| 1 | 小王 | 16 | m | 1 | 数学 | 89 | 2 |
| 1 | 小王 | 16 | m | 2 | 语文 | 99 | 3 |
| 2 | 小李 | 16 | f | 2 | 语文 | 78 | 3 |
| 3 | 小刚 | 16 | f | 1 | 数学 | 88 | 2 |
如果我们想从上面这张表中获取某个学生的某门成绩,只靠 stuId 或者 courseId 是没有办法唯一确定某个学生的某门课程成绩的,因此需要将 stdId 和 courseId 作为“学生课程成绩表”的联合主键,通过联合主键才能唯一确定某个学生的某门课程成绩。
在应用中使用以上关系模式会存在以下问题:
- 数据冗余:同一门课程的“学分(credit)”是和课程相关的,如果在一张表里记录了30条学生成绩,学分(credit)”也就重复了30次,造成数据冗余。
- 更新异常:如果某一门课程的学分调整了,那么需要调整“学生课程成绩”表里涉及到的所有数据,容易造成数据的漏改、错改。
- 插入异常:如果这时候新开了一门课程,但是由于这门课程还没有人选,学生信息只能等到有人选修的时候再插入了,会导致数据的插入异常。
- 删除异常:如果某个学生已经结业,需要删除该学生的成绩记录,同时会删除课程信息以及该课程的学分信息,这时候如果该门课还没有新生选修就会导致课程信息丢失,造成数据保存失败。
再仔细观察这张表的信息,stuName、age、sex 只与 stuId 相关,courseName 只与 courseId 相关,和第二范式(2NF)中规定的需要确保数据库表中的每一列都和主键相关这个规则相违背,所以上述这张表的设计不符合第二范式(2NF)。
那么如何调整才能让其符合第二范式(2NF)呢?
可以将上述“学生课程成绩表”拆分成“学生”表、“课程”表和“学生课程成绩”表。
“学生”表:
| stuId | stuName | age | sex |
|---|---|---|---|
| 1 | 小王 | 16 | m |
| 1 | 小王 | 16 | m |
| 2 | 小李 | 16 | f |
| 3 | 小刚 | 16 | f |
“课程”表:
| courseId | courseName | credit |
|---|---|---|
| 1 | 数学 | 2 |
| 2 | 语文 | 3 |
| 2 | 语文 | 3 |
| 1 | 数学 | 2 |
“学生课程成绩”表:
| stuId | courseId | score |
|---|---|---|
| 1 | 1 | 89 |
| 1 | 2 | 99 |
| 2 | 2 | 78 |
| 3 | 1 | 88 |
调整后的模型如下:
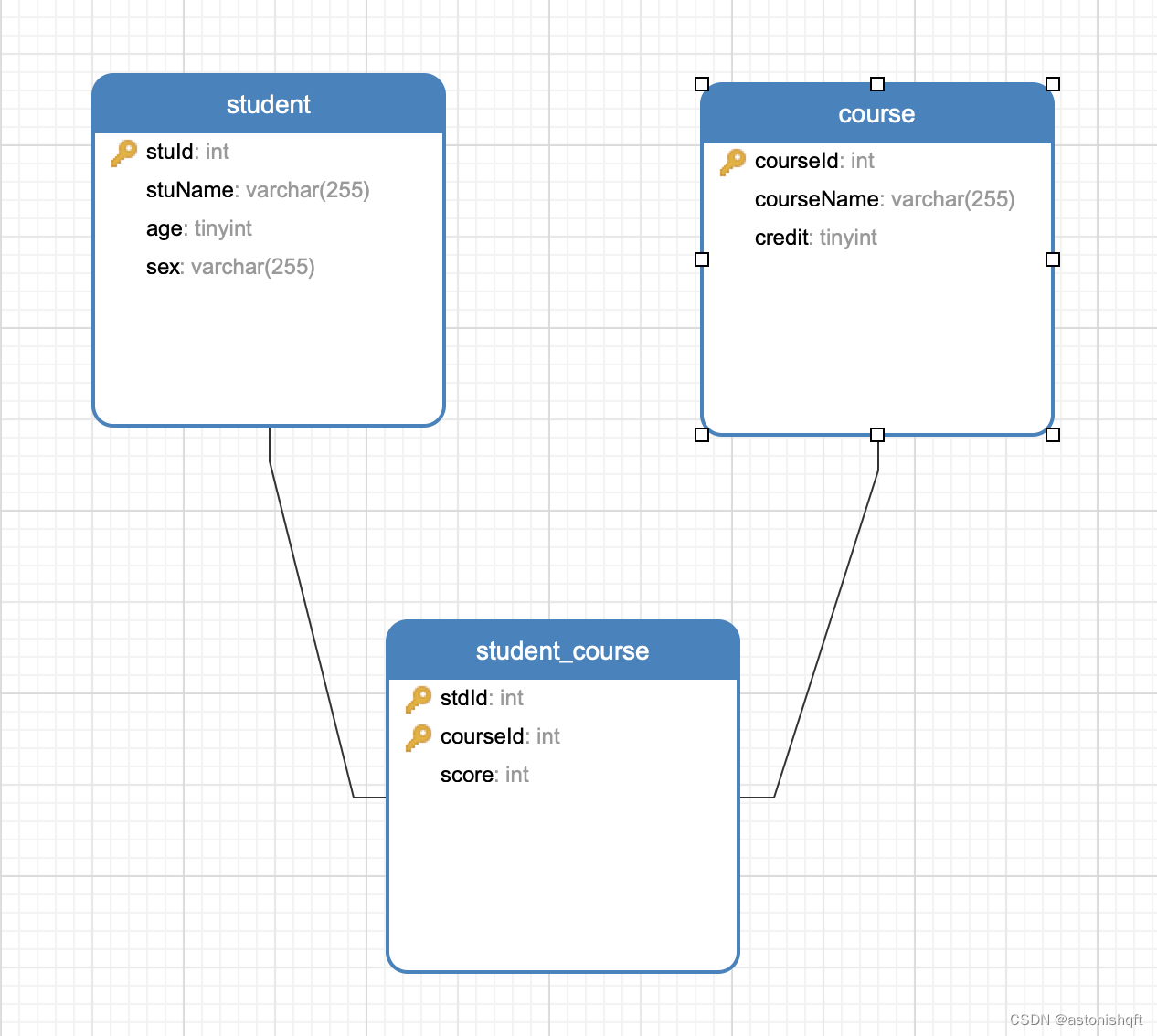
通过上述将一张表拆分成多张表的方式就实现了确保表中的每列都和主键相关,一张表只保存一种数据的目的。
第三范式(3NF)
第三范式(3NF)需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。
通过数学推导公式来表达:
用 A、B、C、D 来表示表中的四个列,其中 A 为主键,其中 B → A(B依赖A), C → A,D → A,如果还有 B → C, C → D 从这两个还可以推导出 B → D, 此时虽然满足第二范式(2NF),但是不满足第三范式。
以“学生”表为例:
| stdId | stdName | age | sex | classId | className | classInfo |
|---|---|---|---|---|---|---|
| 1 | 小王 | 18 | m | 4 | 四班 | 45 |
| 2 | 小李 | 16 | m | 4 | 四班 | 45 |
| 3 | 小蔡 | 15 | f | 2 | 二班 | 46 |
| 4 | 小余 | 17 | m | 5 | 五班 | 48 |
这张表的主键是 stdId,因为这个属性能够确定这张表的其他属性,通过 stdId 就可以知道学生姓名、年龄、性别、班级编号、班级名称、班级人数信息。但是仔细观察可以发现,班级名称、班级人数还可以通过 classId 确定,而 classId 是非主属性,这样就存在了一个传递依赖,并且造成数据的冗余。
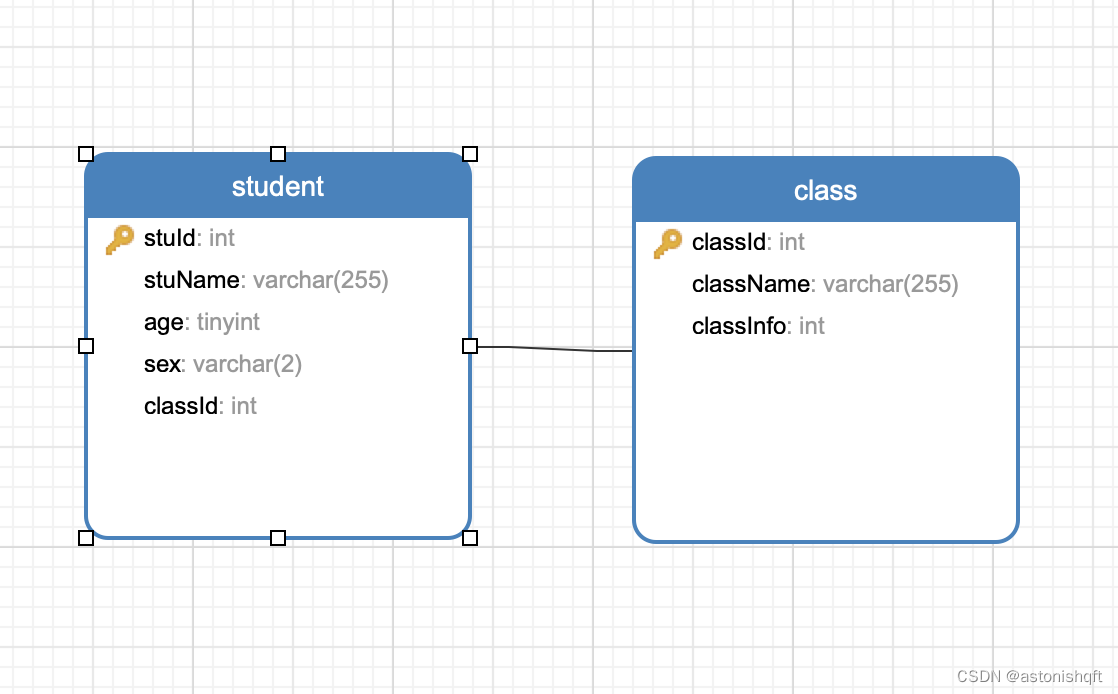
解决这个问题就需要将上述表拆成“学生”表和“班级”表,一张表记录学生信息,另一张表记录班级信息,两张表通过外键进行关联:
学生表:
| stdId | stdName | age | sex | classId |
|---|---|---|---|---|
| 1 | 小王 | 18 | m | 4 |
| 2 | 小李 | 16 | m | 4 |
| 3 | 小蔡 | 15 | f | 2 |
| 4 | 小余 | 17 | m | 5 |
班级表:
| classId | className | classInfo |
|---|---|---|
| 2 | 二班 | 46 |
| 4 | 四班 | 45 |
| 5 | 五班 | 48 |
调整后的模型如下:
总结
数据库连接会带来一部分的性能损失,并不是数据库范式越高越高,有时会在数据冗余与范式之间做出权衡,在实际的数据库开发过程中,往往会允许一部分的数据冗余来减少数据库连接。
参考链接
- 数据库三范式详解
- 数据库设计三个范式