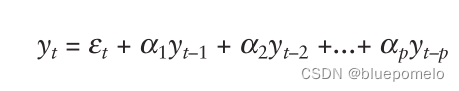1 摘要
传统的基于文本行的文档去扭曲方法在处理复杂布局和/或非常少的文本行时会出现问题。当图像中没有对齐的文本行时,这通常意味着照片、图形和/或表格占据了输入的大部分。因此,对于健壮的文档去扭曲变形,我们建议除了对齐的文本行之外,还使用图像中的线段。基于图像中的许多线段在校正良好的图像中水平或垂直对齐的假设和观察,我们将此属性编码到代价函数中,以及文本行对齐代价。通过最小化该代价函数,我们可以获得用于文档校正的相机姿态、页面曲线等的变换参数。考虑到在某些情况下线段方向上存在许多异常值和丢失的文本行,整个算法以迭代的方式设计。在每个步骤中,我们都会删除未对齐的文本组件和线段,然后使用更新的信息最小化成本函数。实验结果表明,该方法对各种页面布局具有鲁棒性。
2 引言
文档图像处理(如布局分析和光学字符识别(OCR))是文档理解的重要步骤,已经提出了许多用于扫描文档图像处理的方法(使用平板扫描仪将打印文档转换为数字图像,并应用文档图像处理算法)[16]–[17],[20],[23]。然而,随着具有高分辨率数码相机的智能手机的最近发展,需要文档图像处理算法来处理相机捕获的图像以及扫描的文档[5],[9]。
与扫描图像处理相比,由于相机视图和页面曲线导致的几何失真,相机捕获图像的处理被认为是一项具有挑战性的任务。尽管深度测量硬件允许我们消除一系列几何失真[2],但这种方法不适用于普通用户。因此,几十年来,开发易于使用的矫正方法受到了许多关注。例如,针对基于单个图像的校正,提出了许多基于文本行的方法。然而,它们专注于文本行(和文本块),在处理复杂的布局和/或非常少的文本行方面存在局限性。在本文中,为了减轻这些限制,我们提出了一种鲁棒的去扭曲变形方法,该方法通过考虑线段和文本行,适用于一系列文档(非常规布局和非常少的文本行)。
3 相关工作
3.1 使用附加信息的扭曲矫正方法
对于文档图像校正,通过使用深度测量硬件(例如,结构光或激光扫描仪)开发了许多方法[2],[15],[18],[28]。这种方法能够非常有效地估计弯曲页面的表面,但是,特殊硬件的要求限制了其应用领域。在[10],[24],[26]中,根据从不同视点拍摄的多幅图像来估计弯曲页面。虽然它们可以在没有额外硬件的情况下进行校正,但对普通用户来说,拍摄多张图像是一件很麻烦的事,而且它们的计算复杂度也很高。在[4],[27]中,提出了利用照明条件的阴影形状方法。尽管这些方法可以应用于单个文档图像,但它们对照明的假设在许多情况下可能不成立。
3.2 基于文本行的扭曲矫正方法
对于单个文档图像校正(没有附加信息),已经提出了许多使用文本行的方法。由于文本行是常见的,并且在文档图像中显示规则的结构,因此它们被认为是文档校正中非常有用的特征。
在[22]中,通过许多水平线(由文本线构成)和垂直线(由换行构成)来估计两个消失点。该方法有效地消除了透视失真,但不适用于曲面的几何失真。在大多数基于文本线的方法中,曲面是用广义柱面(GCS)[24]建模的,形状是根据文本线的属性来估计的。在[6],[21]中,通过将顶部和底部文本线拟合到平面文档区域来估计弯曲的页面表面。在[8]中,文本行(在未失真的文档中)的属性被编码为成本函数,并且通过最小化该函数来估计相机姿态和弯曲的页面表面。尽管这些基于文本行的方法能够在没有附加信息的情况下减少几何失真,但它们专注于文本区域,有时会对非文本区域(例如照片、图形或表格)产生严重失真,如图1所示。总之,基于文本行方法利用了文本行和文本块的规则结构,它们基本上适用于文本丰富的案例。

图1:所提出的方法与传统的基于文本行的方法的比较[8]:(a)输入图像,(b)[8]的结果。文本区域上的失真在很大程度上被消除,然而,在其他区域中引入了新的失真。(c) 建议方法的结果。我们利用(红色)线段和(绿色)文本线的特性,可以消除整体失真。
3.3 本文的方法
为了缓解基于文本行的方法的局限性,我们提出了一种利用文本和非文本区域属性的展开方法:我们的方法使用线段和文本行。由于文档中的非文本区域通常具有许多线段(例如,表格和图像的边界),这些线段在经过良好校正的图像中水平或垂直对齐,因此我们将此特性编码到所提出的成本函数中,以及文本行的常规特性中。通过Levenberg-Marquardt算法[11],[13]最小化了成本函数,我们可以获得消除文本和非文本区域失真的校正变换,如图1所示。
实验结果表明,所提出的方法在文本区域上产生了最先进的校正性能(根据字符识别率评估),并在非文本区域上生成了视觉上令人愉悦的校正结果。此外,我们还使用几个定量度量(例如正交性)评估了非文本区域的校正性能。
4 本文建议的方法
为了实现鲁棒的展开,我们提出了一种考虑文本线和线段对齐特性的新算法。在本节中,我们首先介绍了校正变换的参数模型,并提出了反映对齐特性的代价函数。然后,我们讨论了代价函数的优化方法。尽管传统方法是通过假设文本行检测步骤中没有(显著)异常值来开发的[8],但少数异常值会显著降低性能,我们在所提出的优化步骤中处理异常值。
4.1 扭曲矫正过程的参数化模型
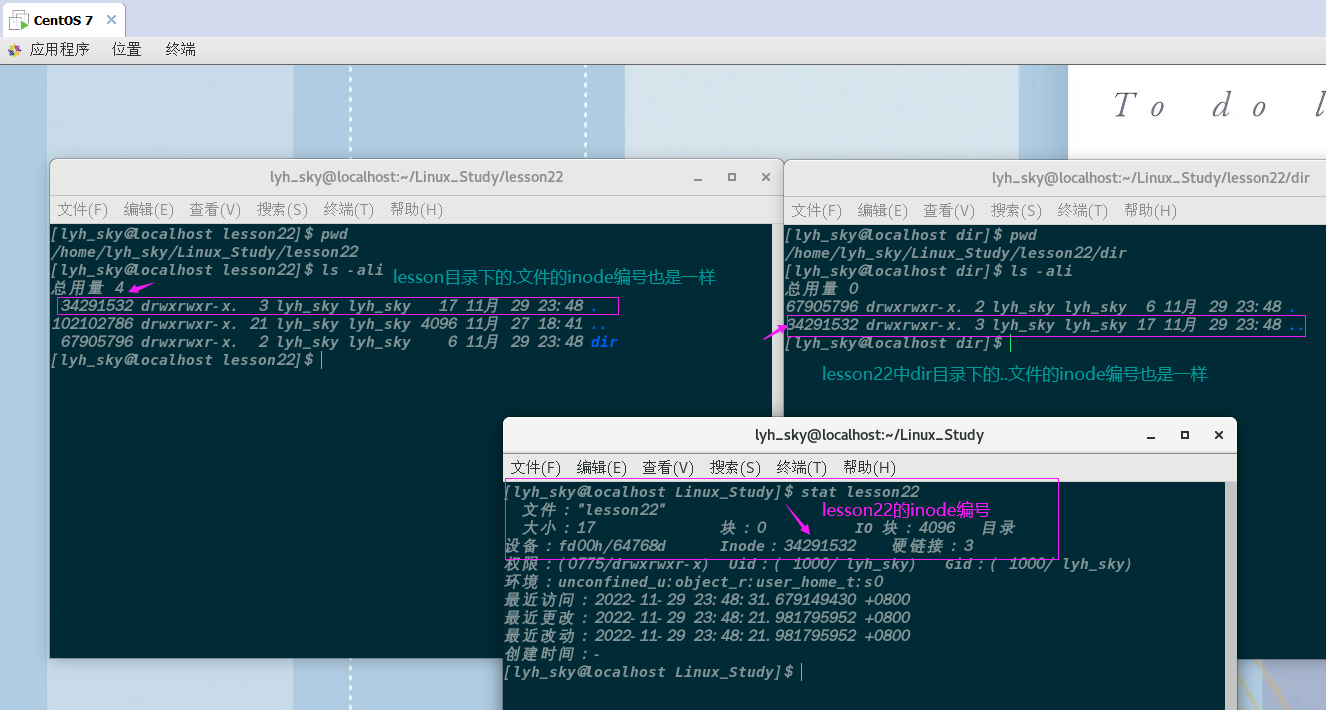
图2:扭曲矫正模型:(a)用相机查看的曲线文档,(b)曲线文档坐标,(c)平面文档坐标。
对于扭曲矫正过程的参数化建模,我们采用[8]中的模型。给定如图2-(a)所示的文档表面。图像域上的点
(
α
,
β
)
(α,β)
(α,β)对应于曲线文档表面上的点
(
x
,
y
,
z
)
(x,y,z)
(x,y,z):
(
α
β
1
)
=
(
f
0
c
x
0
f
c
y
0
0
1
)
(
s
R
⊤
(
x
y
z
)
+
t
)
(1)
\left(\begin{array}{c} \alpha \\ \beta \\ 1 \end{array}\right)=\left(\begin{array}{ccc} f & 0 & c_{x} \\ 0 & f & c_{y} \\ 0 & 0 & 1 \end{array}\right)\left(s \mathbf{R}^{\top}\left(\begin{array}{c} x \\ y \\ z \end{array}\right)+t\right) \tag1
⎝⎛αβ1⎠⎞=⎝⎛f000f0cxcy1⎠⎞⎝⎛sR⊤⎝⎛xyz⎠⎞+t⎠⎞(1)
其中
f
f
f是相机的焦距,
(
c
x
,
c
y
)
(c_x,c_y)
(cx,cy)是图像中心,
(
s
,
R
,
t
)
(s,R,t)
(s,R,t)分别是两帧之间的缩放、旋转和平移。由于参数
s
s
s和
t
t
t与校正无关,而是与图像比例和分辨率有关,因此我们在矫正过程中设置
s
=
1
s=1
s=1,
t
=
[
0
,
0
,
f
]
⊤
t=[0,0,f]^⊤
t=[0,0,f]⊤ 。
对于图2(b)和(c)所示的GCS模型,曲面上的一个点可以转换为矫正文档上的对应点
(
u
,
v
)
(u,v)
(u,v)
u
=
∫
0
x
1
+
g
′
(
t
)
2
d
t
v
=
y
(2)
\begin{array}{l} u=\int_{0}^{x} \sqrt{1+g^{\prime}(t)^{2}} d t \\ v=y \end{array} \tag2
u=∫0x1+g′(t)2dtv=y(2)
其中
g
(
x
)
g(x)
g(x)是用多项式表示的文档表面方程:
z
=
g
(
x
)
=
∑
m
=
0
M
a
m
x
m
(3)
z=g(x)=\sum_{m=0}^{M} a_{m} x^{m} \tag3
z=g(x)=m=0∑Mamxm(3)
其中M是多项式阶。小的M不能很好地描述实际的页面卷曲,大的M容易过度拟合。基于广泛的实验,我们发现四阶(
M
=
4
M=4
M=4)多项式方程能很好地表示页面卷曲。
通过组合(1)、(2)和(3),可以将图像域上的点转换为校正文档图像上的对应点。
总之,捕获的图像域和校正的文档域之间的几何关系可以用多项式参数
{
a
m
}
m
=
0
M
\left\{a_{m}\right\}_{m=0}^{M}
{am}m=0M和相机姿态
R
\mathrm{R}
R(我们假设相机焦距
f
f
f是已知的)来参数化。因此,文档图像校正过程可以公式化为多项式参数和相机姿态的估计问题。
4.2 建议的代价函数
为了估计扭曲矫正参数
Θ
=
(
R
,
{
a
m
}
m
=
0
M
)
\Theta=\left(\mathbf{R},\left\{a_{m}\right\}_{m=0}^{M}\right)
Θ=(R,{am}m=0M),我们开发了一个成本函数:
f
cost
(
Θ
)
=
f
text
(
Θ
)
+
λ
f
line
(
Θ
)
(4)
f_{\text {cost }}(\Theta)=f_{\text {text }}(\Theta)+\lambda f_{\text {line }}(\Theta) \tag4
fcost (Θ)=ftext (Θ)+λfline (Θ)(4)
其中
f
text
(
Θ
)
f_{\text {text }}(\Theta)
ftext (Θ)反映校正图像中文本行属性的术语[8]。准确地说,当转换的文本行对齐良好时,
f
text
(
Θ
)
f_{\text {text }}(\Theta)
ftext (Θ)变小:水平直线,两个相邻文本行之间的行距是规则的,文本块要么左对齐,要么右对齐,要么对齐。然而,
f
text
(
Θ
)
f_{\text {text }}(\Theta)
ftext (Θ)的优化有时会在非文本区域上产生严重失真(如图1-(b)所示),我们还通过引入
f
line
(
Θ
)
f_{\text {line }}(\Theta)
fline (Θ)来利用文档图像中的线段。
4.3 线段对齐和代价函数
对于
f
line
(
Θ
)
f_{\text {line }}(\Theta)
fline (Θ)的设计,我们首先使用[25]中的线段检测器(LSD)提取给定图像中的线段。然后,根据在校正图像中大部分线段水平或垂直对齐的观察结果,我们将该术语定义为
f
line
(
Θ
)
=
∑
i
min
(
cos
2
θ
i
,
sin
2
θ
i
)
(5)
f_{\text {line }}(\Theta)=\sum_{i} \min \left(\cos ^{2} \theta_{i}, \sin ^{2} \theta_{i}\right) \tag5
fline (Θ)=i∑min(cos2θi,sin2θi)(5)
其中
θ
i
\theta_i
θi是变换后的第
i
i
i条线段的角度(当使用当前参数
Θ
\Theta
Θ进行校正时),如图3所示,并且通过扭曲矫正过程(使用
Θ
\Theta
Θ)将它们的变换点定义为
p
i
′
p_{i}^{\prime}
pi′和
q
i
′
q_{i}^{\prime}
qi′。然后将
θ
i
\theta_i
θi定义为连接
p
i
′
p_{i}^{\prime}
pi′与
q
i
′
q_{i}^{\prime}
qi′的线段的方向。

图3:线段及其角度图示。

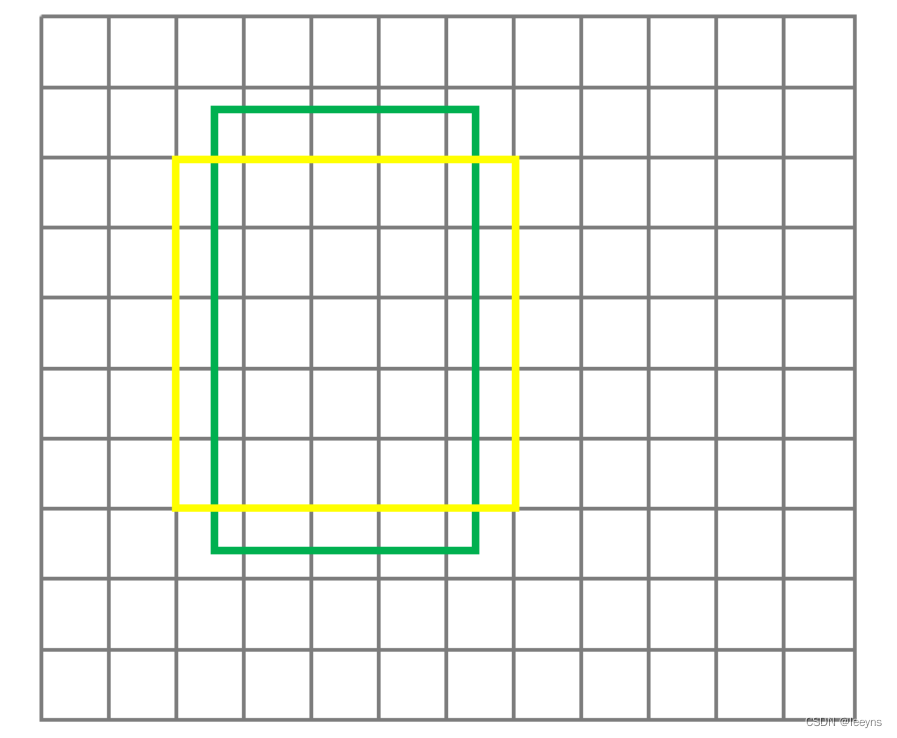
图4:相机捕获图像和校正图像中的文本线和线段。文本组件表示为(绿色)椭圆,线段表示为(红色)线。线段对齐项(5)分别为16.282和0.04。
由于线段在垂直或水平方向上对齐,如图4所示,该项变小。尽管存在异常值(具有任意方向的线段),公式(5)通过使用有界惩罚函数( cos 2 θ i ≤ 1 , sin 2 θ i ≤ 1 \cos ^{2} \theta_{i} \leq 1, \quad \sin ^{2} \theta_{i} \leq 1 cos2θi≤1,sin2θi≤1). 此外,我们还开发了一个优化步骤,以缓解异常值问题。
4.4 异常值删除和优化
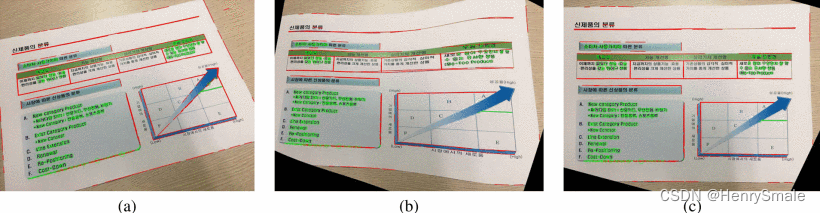
图5:我们的迭代方案:(a)输入图像,(b)第一次迭代后的结果,(c)第二次迭代之后的结果。
尽管[8]中使用的优化方法假设没有异常值(或它们的影响不是关键的),但由于异常值,
f
cost
(
Θ
)
f_{\text {cost }}(\Theta)
fcost (Θ)的直接优化可能会产生如图5-(b)所示的不良校正结果。我们处理两种异常值类型,即缺失的文本行和具有任意方向(非水平/垂直)的线段。对于离群值的去除,我们设计了一种迭代方法。在每一步中,我们都通过删除异常值来细化特征(文本组件和线段),并使用更新的inliers最小化代价函数。准确地说,在第
(
j
+
1
)
(j+1)
(j+1)次迭代时,一组更新的直线段被定义为
L
j
+
1
=
{
l
∣
l
∈
L
j
,
f
l
i
n
e
(
l
)
<
τ
j
}
(6)
L_{j+1} = \{l\vert l\in L_{j},\ f_{line}(l) < \tau_{j}\} \tag{6}
Lj+1={l∣l∈Lj, fline(l)<τj}(6)
其中,
L
j
L_j
Lj是第
j
j
j次迭代时的内集。如果变换后的线段(在每个步骤)不是垂直/水平对齐的,我们将这些线段确定为异常值。文本的异常值删除也有类似的定义。如果转换后的文本行未对齐(不是水平行),我们将这些不在水平行上的文本组件确定为异常值。由于成本项反映了文本行和线段的对齐,我们通过计算成本项来检测异常值。重复此迭代,直到inlier的数量变得稳定。经过大量实验,我们将最大迭代次数设置为3。成本函数由平方项组成,Levenberg-Marquardt(LM)算法用于成本函数优化[11],[13]。
6 引用该论文的文献
[1] Document rectification and illumination correction using a patch-based CNN
https://dl.acm.org/doi/abs/10.1145/3355089.3356563
[2] Can you read me now? content aware rectification using angle supervision
https://link.springer.com/chapter/10.1007/978-3-030-58610-2_13
[3] Light-Weight Document Image Cleanup Using Perceptual Loss
https://link.springer.com/chapter/10.1007/978-3-030-86334-0_16
[4] Dewarping document image by displacement flow estimation with fully convolutional network
https://link.springer.com/chapter/10.1007/978-3-030-57058-3_10
[5] A Novel Adaptive Deskewing Algorithm for Document Images
https://www.mdpi.com/1424-8220/22/20/7944
参考文献
[1] 论文:Robust Document Image Dewarping Method Using Text-Lines and Line Segments
[2] 代码:https://github.com/taeho-kil/Document-Image-Dewarping