目录
(一)前言
(二)正文
1. 表结构/索引展示
(1)表结构
(2)各表索引情况
2. 存在性能问题的SQL语句
3. 解决思路
(1)执行计划思路调优
(2)字符集匹配调优
(三)总结
1. 关于执行计划中TYPE的性能比较
2. 关于left join优化
3. 其他注意点
(一)前言
这几天供应商在测试环境上使用MYSQL数据库做开发时遇到一个SQL性能问题,即在他开发环境本地跑SQL速度很快就一两秒时间,但是同样的SQL放在测试环境上死活跑了很久一直出不了结果。最后求助到我这边,以下正文是我解决这次问题的一个过程浅谈,供大家参考。
(二)正文
本文使用NAVICAT试用版作为基础工具来说明,需要永久激活的可以在网上找到相关介绍走正式途径。

其次附上一篇文章,解释说明如果在NAVICAT中运行一条长时间的SQL想关闭终止它,图形化点击失败时候所应该采取的方式,文章链接如下:
在Navicat上如何停止正在运行的MYSQL语句_zyypjc的博客-CSDN博客
1. 表结构/索引展示
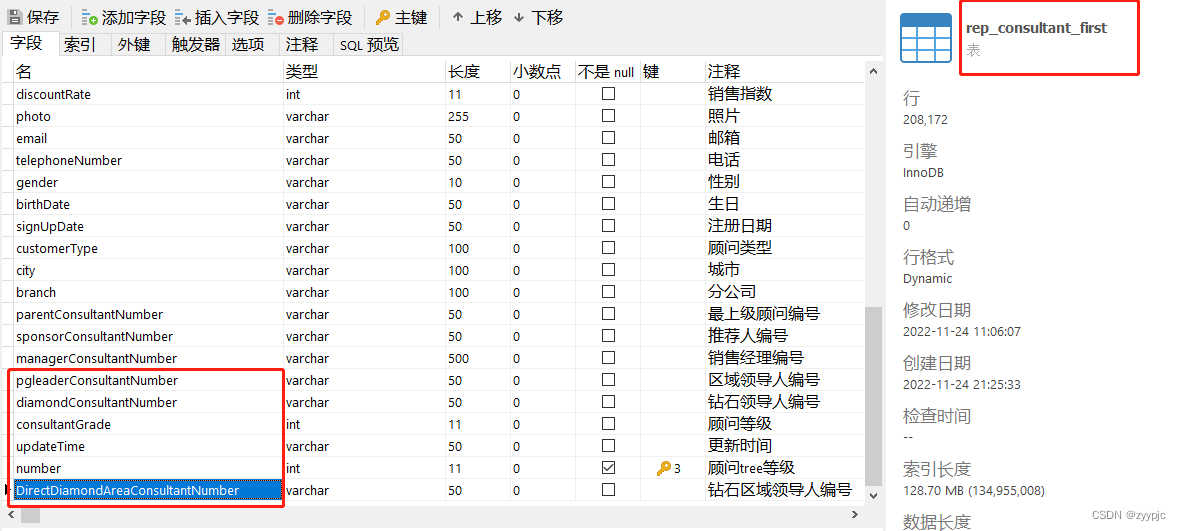
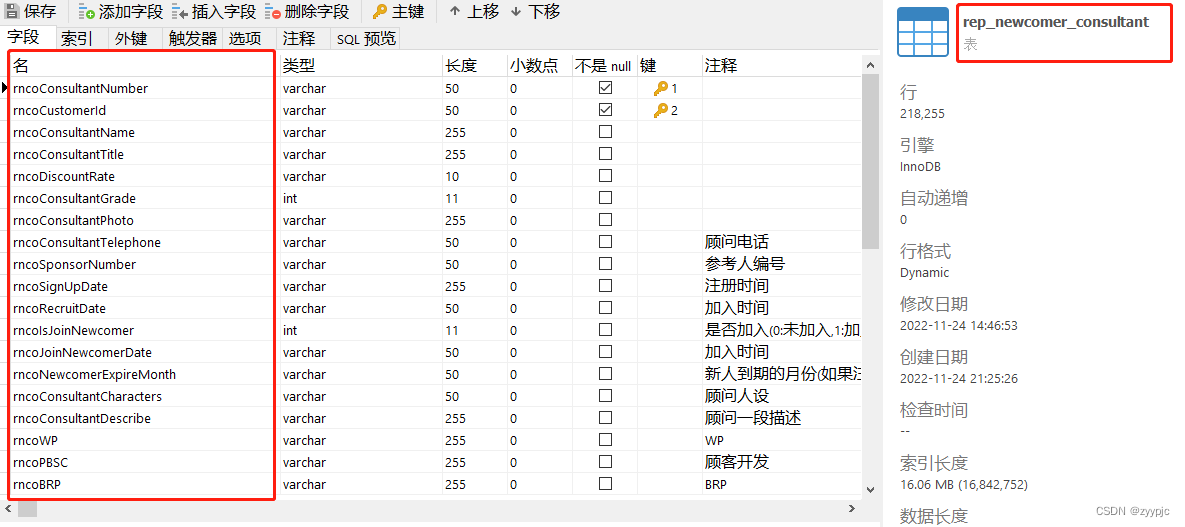
以下将大致描述下本次遇到性能问题涉及的两张表(rep_consultant_first和rep_newcomer_consultant)的表结构和索引。
(1)表结构
a. rep_consultant_first

b. rep_newcomer_consultant

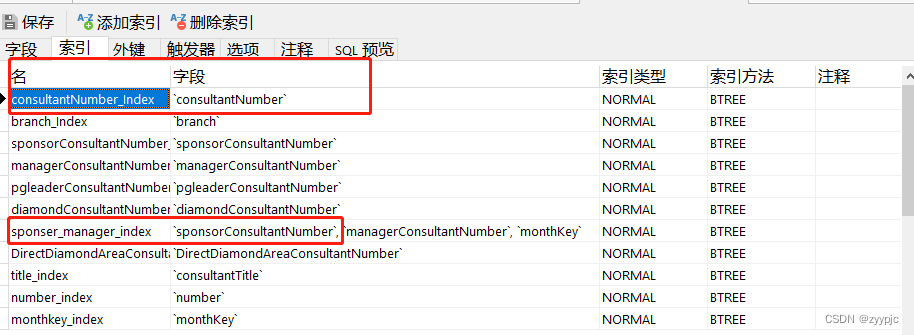
(2)各表索引情况
a. rep_consultant_first

b. rep_newcomer_consultant

2. 存在性能问题的SQL语句
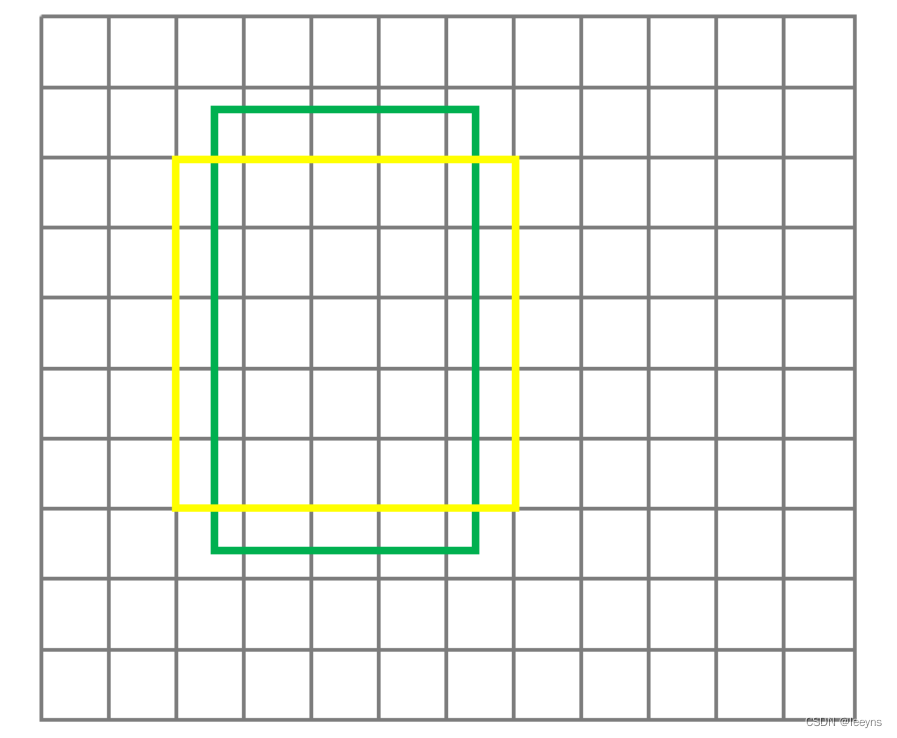
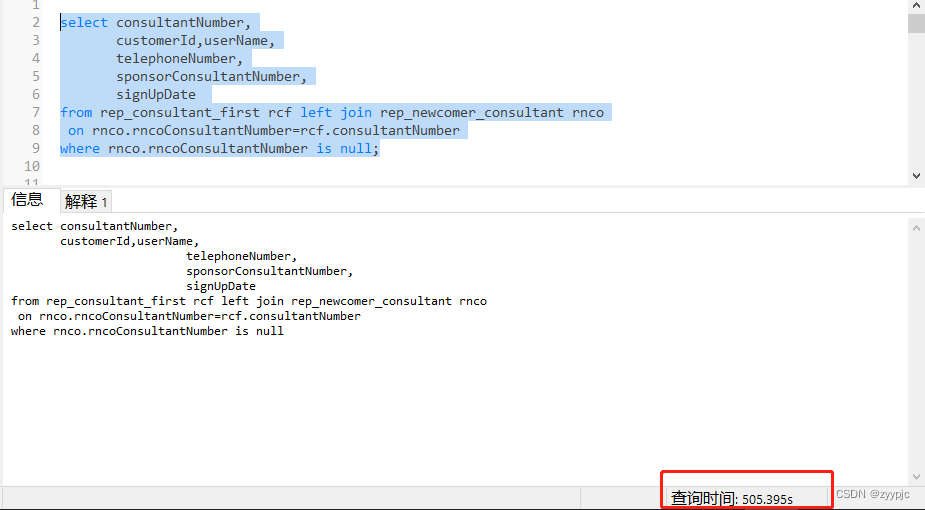
这条SQL语句的意图在于找出rep_newcomer_consultant表中缺失的存在于rep_consultant_first表中的数据,即可求这两张表的差集(rep_consultant_first - rep_newcomer_consultant),简单说就是下图里的红色填充区域。

select consultantNumber,
customerId,userName,
telephoneNumber,
sponsorConsultantNumber,
signUpDate
from rep_consultant_first rcf left join rep_newcomer_consultant rnco
on rnco.rncoConsultantNumber=rcf.consultantNumber
where rnco.rncoConsultantNumber is null;直接运行后我们发现这条语句运行了好几十分钟依旧没有结果,假如只是稍微慢一点那可能勉强说得过去,但是目前这种情况实在是到无法接受的情况了!!!
3. 解决思路
(1)执行计划思路调优
一般SQL慢了,第一个想的一定是查一下执行计划是不是哪个环节没有走索引,走了全表扫描,让我们选中SQL部分,点击“解释已选择的”来看下这条SQL的执行计划详情:
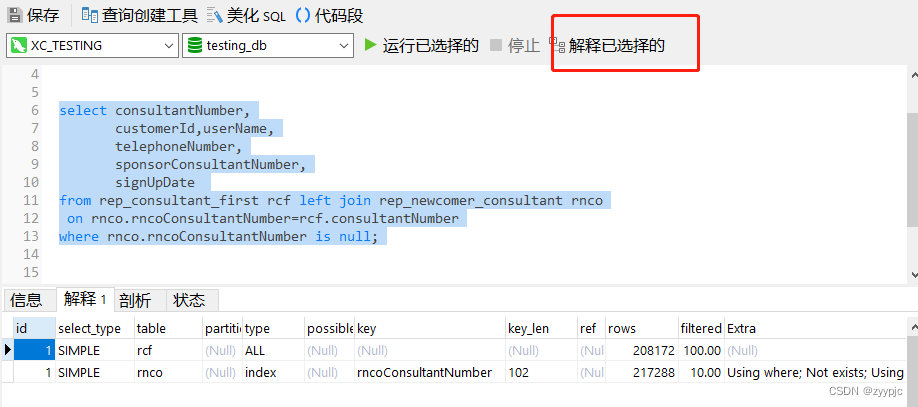
从执行计划中我们看到别名为rcf(即rep_consultant_first表)的type方式走了ALL,即全表扫描,那自然而然我们会先想从这里去优化。

回到rep_consultant_first表的索引位置,我们看到在select后筛出来的字段里只有consultant number和sponsorConsultantNumber字段上有索引而其他并没有,所以不可避免走了全表扫描
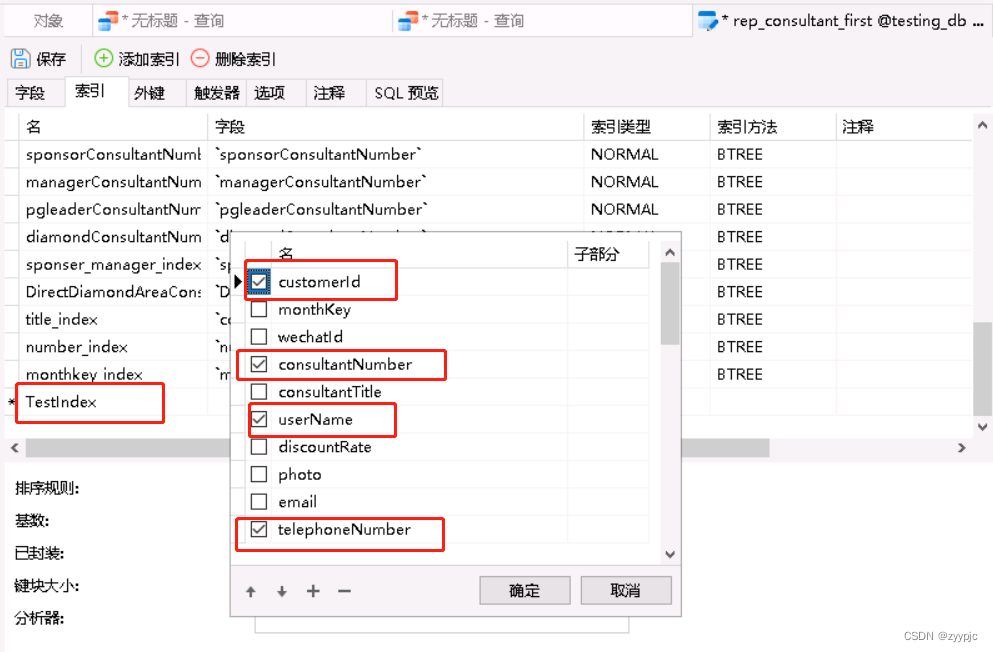
那我们先尝试下给未加索引的字段加上一组索引,大致流程如下:
a. 找到所要加索引字段所在的表(rep_consultant_first),右键点击后选择"设计表"

b. 找到索引选项卡,添加索引TestIndex,最后点击保存。

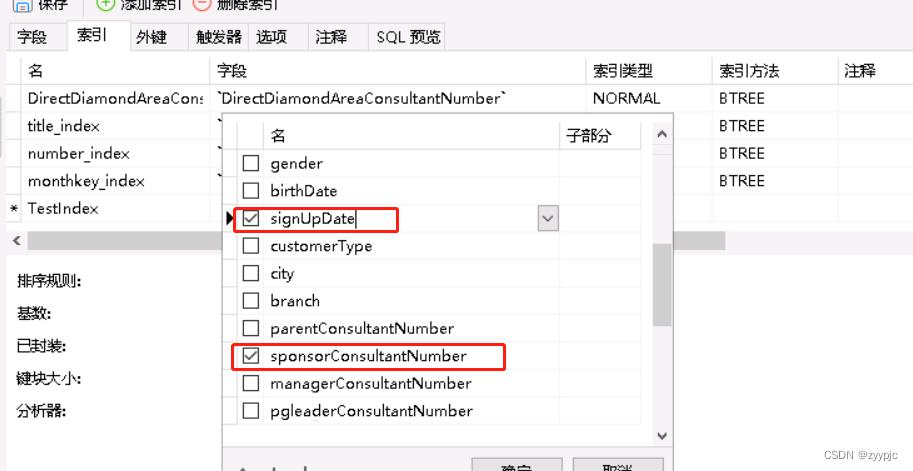
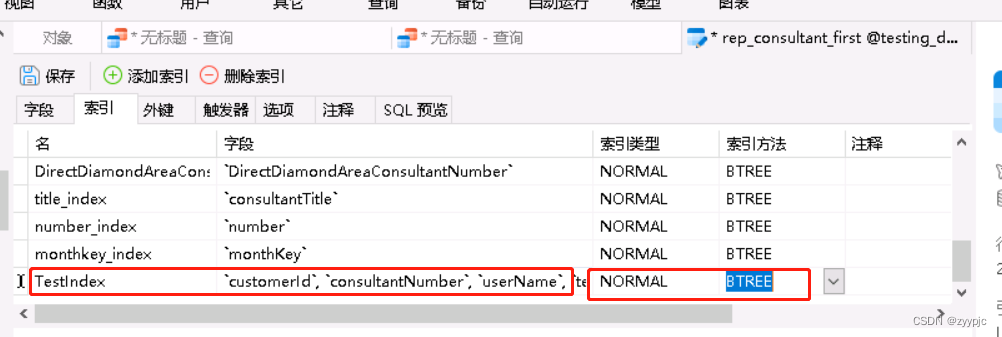

让我们重新回到一开始的SQL,看一下加完索引后是否执行计划有优化:
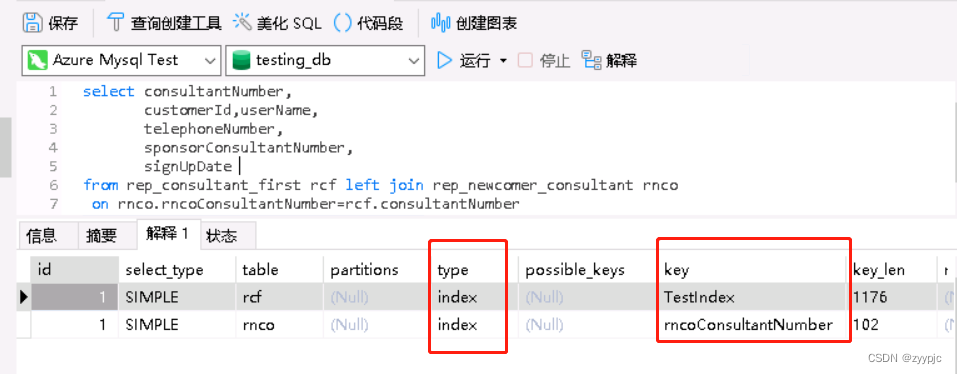
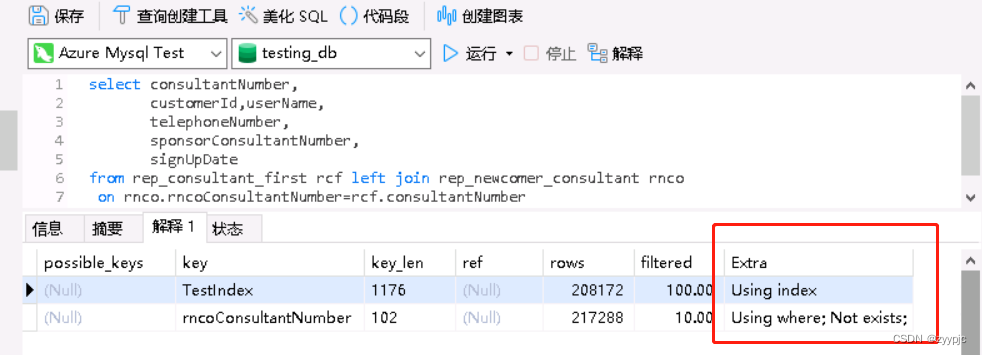
可以看出,执行计划的TYPE从ALL变成了INDEX且EXTRA列明确说明了Using index了,那说明执行计划确实改变了,没有扫全表,不过遗憾的是。。。SQL依旧跑不出来。。。

(2)字符集匹配调优
此时真的黔驴技穷了么??还真没有 !足球篮球世界里我们经常看到最后时刻逆袭的致命一击取得胜利,在SQL优化里我们同样有这样的机会! 仔细回想了下,似乎在MYSQL相关手册资料中的优化TIPS里除了添加相关字段索引之外,那left join中关联两表的字段,字符集是否需要统一???
有了这个思路,我们立马着手再看下这条问题SQL语句,我们重点关注rep_consultant_first表上的consultantNumber字段以及rep_newcomer_consultant表上的rncoConsultantNumber字段:
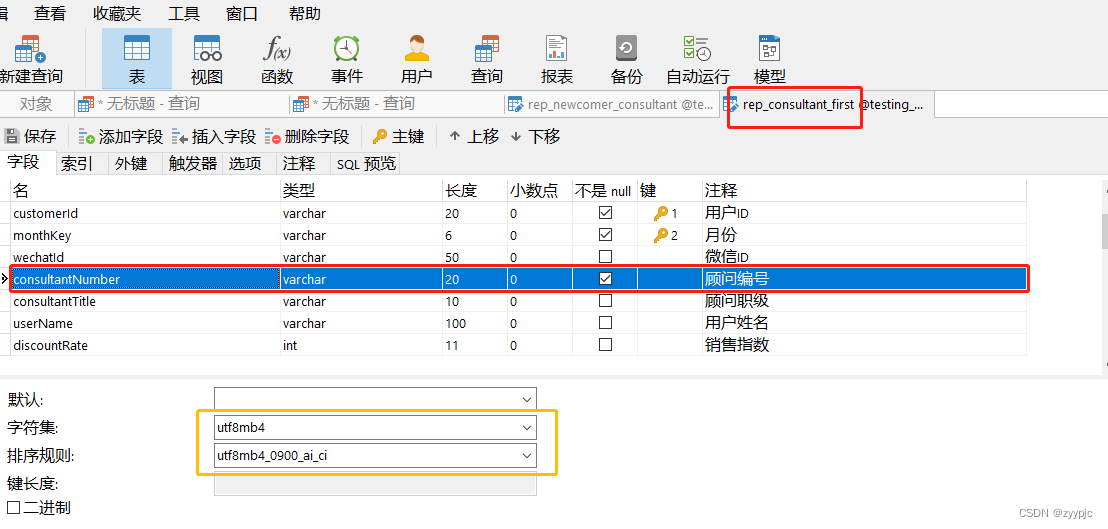

对比之下,立马看出了区别!在rep_consultant_first上字段consultantNumber的字符集为utf8mb4,而rep_newcomer_consultant上字段rncoConsultantNumber的字符集为gbk。在官方相关文档中提到过关联字段除了需要有索引外,拥有相同的字符集以及数据类型相当重用,这会极大影响查询速度!
接下来我们来具体操作下,可以将rep_newcomer_consultant上字段rncoConsultantNumber的字符集改从gbk改为utf8mb4,排序方式也改为和rep_consultant_first表一样的utf8mb4_0900_ai_ci试一试,点击保存按钮:

保存成功后,我们立马再运行下慢SQL:
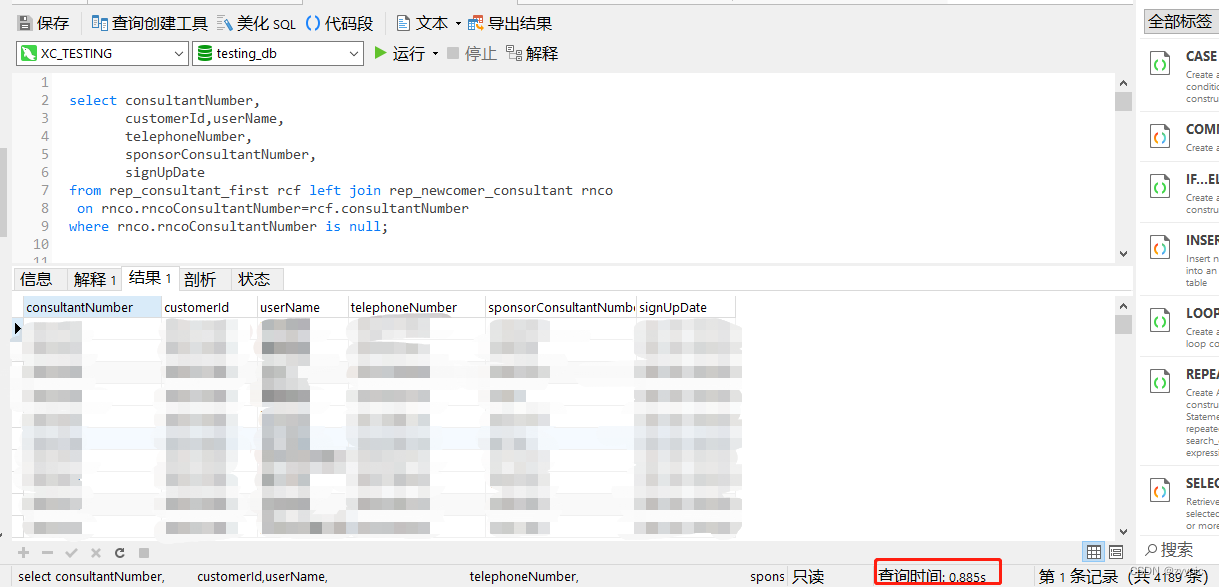
一下子只有0.885秒了!!速度飙升到无法言喻的速度!至此我们基本算优化成功了。
(三)总结
经过这个案例后,我搜罗总结了下本例涉及到一些优化注意点:
1. 关于执行计划中TYPE的性能比较

2. 关于left join优化
1、left join选择小表作为驱动表(这部分基本是大家的共识)
2、如果左表比较大,并且业务要求驱动表必须是左表,那么我们可以通过where条件语句,使得左表被过滤的小一些,主要原理和第一条类似
3、关联字段给索引,因为在mysql的嵌套循环算法中,是通过关联字段进行关联,并查询的,所以给关联字段索引很必要
4、如果sql里面有排序,请给排序字段加上索引,不然会造成排序使用全表扫描
参考:https://www.oschina.net/question/930697_2190172
5、如果where条件中含有右表的非空条件(除开is null),则left join语句等同于join语句,可直接改写成join语句。6、根据文档,MySQL能更高效地在声明具有相同类型和尺寸的列上使用索引。所以把表与表之间的关联字段给上encoding和collation(决定字符比较的规则)全部改成统一的类型
7、右表的条件列一定要加上索引(主键、唯一索引、前缀索引等),最好能够使type达到range及以上(ref,eq_ref,const,system)
3. 其他注意点