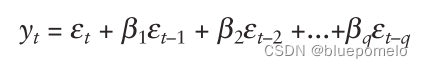Efficient Large-Scale Language Model Training on GPU ClustersUsing Megatron-LM
1 INTRODUCTION
-
在这篇文章中展示了 如何将 tensor ,pipeline, data 并行组合,扩展到数千个GPU上。
-
提出了一个新的交错流水线调度,可以提升10%的吞吐量。propose a novel interleaved pipelining schedule that can improve throughput by 10+% with memory foot-print comparable to existing approaches
-
训练transformer 语言模型等这类模型,模型规模超大,挑战:
- 不能将模型直接放入GPU内存中训练,既是GPU内存非常大:
- 即使可以将模型装入GPU,太多次数的操作也会导致难以忍受的训练时间
-
利用数据并行进行规模化,通常表现很好但是存在两方面的限制:
a) 除了一个节点的情况,每个GPU的batch size 太小会将带GPU的利用率,增加通信的损耗
b) 可用设备的最大数是batch的size,限制了加速器的数量。 -
一些模型被提出来解决这两个挑战
tensor (intra-layer) model parallelism,层内并行模型。transformer每一层内的矩阵乘被切分到多态GPU上。在更大的模型上表现不好;
更大的模型被被割到多个· 多GPU的服务器上,导致两个问题:
- allreduce实现tensor并行,需要经过 服务器间的链路( inter-server links ),要比在 一个多GPU服务器内的 高带宽 NVLink 慢得多。
- 高程度得模型并行,会造成小矩阵相乘,可能会降低GPU利用率 (为什么??) (GEMMs?小矩阵的运算没有大矩阵高效,降低了GPU利用率?)
流水线模型并行,将模型的各层分不到CPU上。 将一个batch 分成多个更小的 microbatches,通过流水线执行。
为了达到高效,需要更大的batch size
本文中介绍了一种新的流水线调度方式,可以提升小的batch size的效率。
本文解决如下问题:
在保证严格的优化器语义的同时,如何 结合并行化技术来最大化给定 batch size的大模型训练吞吐效率。(strict optimizer semantics???)
How should parallelism techniques be combined to maximize the training throughput of large models given a batch size while retaining strict optimizer semantics?
PTD-P:将 pipeline,tensor,data parallesim 进行结合的技术。
研究了不同组件之间相互作用对吞吐量的影响。
在这些研究的基础上,我们提供了如何配置分布式训练的指导原则:
-
Different forms of parallelism interact in non-trivial ways:不同方式的并行以非平凡的方式交互。 tensor并行最好在 多GPU的sever内部使用,才更高效。
-
不同的并行化策略会影响: 通信量、 kernel的计算效率、worker的空闲时间、 pipeline 气泡。提出交错式的流水线调度,寄生吞吐量,限制内存占用。
-
超参数,例如micro batch的大小会影响内存占用、计算效率、流水线气泡大小
-
分布式训练是通信密集型的,如果 inter-node 通信慢,或者在通信密集处分区隔断,将严重影响效率
2 并行化模型
PTD-P : 我们将管道模型并行性和张量模型并行性(组合如图2所示)与数据并行性相结合,并称之为 PTD-P
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-neZO7MOh-1669727514425)(assets/markdown-img-paste-20220712113741693.png)]
2.1 数据并行化
每个工作节点都有完整的模型,输入的数据被切分,worker 定期聚合梯度,保证所有worker 看到版本一致的权重。
对于太大的模型,无法适配到单个工作节点上。
2.2 流水线并行模型
模型的层被分割到多个设备上。
当应用到有相同的transformer模块重复的模型时,每个设备分得相同数量得transformer 层。 我们不考虑更多非对称得模型结构,分配策略会更难。
一个batch 被分成更小得 microbatches, 然后在 microbatches 上执行流水线。
流水线模式需要保证:流水线方案需要确保输入在前向和后向传递中看到一致的权重版本,保证是严格优化的。
为准确保留严格优化器语义(strict optimizer semantics),我们引入了流水线周期性刷新,以便优化步骤跨设备同步。
在设备空闲时,空闲时间被称为流水线气泡(pipeline bubble),要使得它足够小。
Asychromous (异步) 和 bounded-staleness (边界陈旧)的方式比如:PipeMare,PipeDream 和 PipeDram-2BW 完全消除了 flushes ,但是松弛了权重更新语义。
有几种可能的 microbatch 跨设备前推和后推调度策略。对 bubble size, 通信,内存占用进行 trade off
2.2.1 Default Schedule
GPipe 第一次执行将一个batch的所有 microbatches 向前传递,然后再将所有的 microbatches 向后传递。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-80mfGana-1669727514427)(https://raw.githubusercontent.com/novaCoder-zrk/Picture-Bed/master/img[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YyQKcTFF-1669727514773)(…assetsmarkdown-img-paste-20220709213408346.png)]].png)
- 每个decive可以运行多个 层的集合,称为 model chunck
对一个设备,气泡时间
t p b = ( p − 1 ) ∗ ( t f + t b ) t_{pb} = (p-1)*(t_f + t_b) tpb=(p−1)∗(tf+tb)
理想的处理时间(不包含气泡的时间)
t
i
d
=
m
∗
(
t
f
+
t
b
)
t_{id} = m*(t_f + t_b)
tid=m∗(tf+tb)
m 是一个batch 分成的 microbatch 的数量
B u b b l e t i m e f r a c t i o n ( p i p e l i n e b u b b l e s i z e ) = t p b t i d = p − 1 m Bubble \,time \, fraction(pipeline \,bubble\, size) = \frac{t_{pb}}{t_{id}} = \frac{p-1}{m} Bubbletimefraction(pipelinebubblesize)=tidtpb=mp−1
要使的气泡时间分数小,使得 m 远大于 p,对于 大的m会导致 搞得内存占用率,因为需要将中间激活值保存在内存中,在 m microbatch的生命中周期中,都需要保存
PipeDream-Flush

因为,在处理一个batch时,如果让所用的microbatch 都处于处理中的状态(in-flight microbatches),内存占用会很大,因此需要限制管道中还没处理完的microbatch的数量。
PipeDream-Flush 调度,首先进入热身步骤,worker进行一定次数的向前传递,没有一下子将所有的forward都进行完,等有microbtach可以进行backward的时候立刻进行backward,

这个调度限制了处理中的 microbatch的数量,限制在了管道深度depth,而不是batch中microbatch数。
在经过了热身阶段后,每个worker进入了一种稳定状态,向前和向后传递交替进行(1F1B)。

这个新的调度的气泡时间是相同的,但是需要更少的激活被存储,不需要保存 m 个中间激活,只需要depth个。
当m远大于p的时候,PipeDream-Flush 比 Gpipe 内存效率更优。
2.2.2 带交错阶段的调度Schedule with Interleaved Stages
本文提出的新方法
为了减少流水线的气泡,设备可以为层的多个子集进行计算(model chunk),而不是计算一组连续的层。也就是说一个设备可以执行多股效地chunk,而不是一整个连续的chunk,相当于流水线的细分。
例如,一个机器可以计算4层,设备1 计算1,2,9,10;设备2 计算3,4,11,12;每个设备计算两个模型块,每个模型块有2层。
每个设备承担更多计算阶段,每个阶段的计算任务却更少。
使用1F1B 和 交错阶段调度;
要求microbatch的数量,是流水线并行度的整数倍。
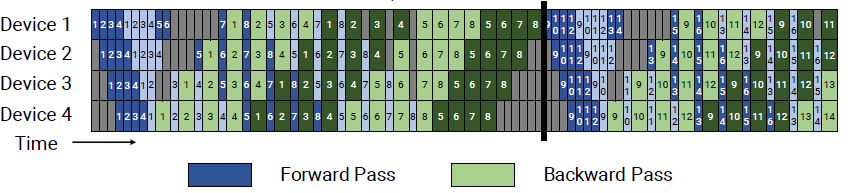
将流水线的每个阶段减小,气泡就小了。但是数据之间的传输通信速度又会造成代价。
以前每个device只有一个stage(或者说 model chunk),如今每个device都有 v 个model chunk
因此气泡的时间减少为 t p b i n t . = ( p − 1 ) ( t f + t b ) v t_{pb}^{int.} = \frac{(p-1)(t_f + t_b)}{v} tpbint.=v(p−1)(tf+tb)
B u b b l e t i m e f r a c t i o n ( p i p e l i n e b u b b l e s i z e ) = t p b i n t . t i d = 1 v ⋅ p − 1 m Bubble \,time \, fraction(pipeline \,bubble\, size) = \frac{t_{pb}^{int.}}{t_{id}} = \frac{1}{v}\cdot\frac{p-1}{m} Bubbletimefraction(pipelinebubblesize)=tidtpbint.=v1⋅mp−1
将流水线细分,可以提高流水线的并行度,会减少流水线气泡的大小,但代价是增加了机器之间的通信量
2.3 Tensor Model Parallesim
Tensor Model 会将单独的层,划分到多个机器上
Megatron 划分策略:
- 用于transformer模型层的划分
- 一个transformer层 由一个self-attention块,后跟一个两层的多层感知器(MLP)组成。
多层感知机的划分策略
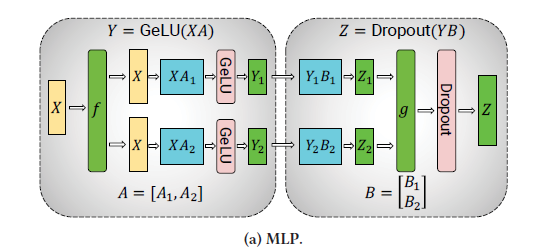
- split A= [A1,A2]
- Y = [Y1,Y2] = [GeLU(X A1), GeLU(X A2)]
- B矩阵按行划分
multi-head attention 的划分策略
- 在multi-head attention中,因为固有的并行性,每个GPU可以只负责一个头的attention的计算
3 PERFORMANCE ANALYSIS OF PARALLELIZATION CONFIGURATIONS
并行化配置的性能分析
不同维度的并行化都进行了内存占用,设备利用率和通信量的tradeoff
- 讨论tradeoff
- 提出了有关流水线气泡大小的的分析模型
- 定量描述通信时间行为 (communication time behaves),并且提出了通信代价量的模型,但没有提出 直接通信时间代价模型,分层通信建模比较困难
- 据目前所知,这是第一个分析 不同维度并行化交互性能的工作。
3.1 符号
- (p,t,d) :p 流水线模型并行大小,t tensor模型并行大小,d 数据并行大小
- n GPU的数量 p·t·d = n
- B: 全局batch size ,input的大小
- b: microbatch 的大小
- m = 1 b ⋅ B d m = \frac{1}{b} ·\frac{B}{d} m=b1⋅dB
3.2 Tensor and Pipeline Model Parallelism
- 流水线模型,有更廉价的点对点通信; Tensor并行模型使用all-reduce 通信
- 有n个GPU, 不考虑data 并行,data 并行度设为1,d = 1. t ⋅ p = n t\cdot p = n t⋅p=n
流水线气泡大小:
p
−
1
m
=
n
/
t
−
1
m
\frac{p-1}{m} =\frac{n/t-1}{m}
mp−1=mn/t−1
m 是确定的,当t增加,流水线的气泡减少。
- 流水线模型,在每对连续设备间需要进行通信,为每个 microbatch 的通信总量为为 bsh。
s 是序列长度 (sequence length),s怎么理解?每个样本序列的长度? h是 (hidden size)
-
大小为 bsh的tensor需要在t个设备之间进行all-reduce,forward和backward个进行一次,每个设备每层的总传输量为 8 b s h ( t − 1 t ) 8bsh(\frac{t-1}{t}) 8bsh(tt−1)
-
每个设备有 l s t a g e l^{stage} lstage层,每个设备总的传输量为 l s t a g e ⋅ ( 8 b s h ( t − 1 t ) ) l^{stage}\cdot(8bsh(\frac{t-1}{t})) lstage⋅(8bsh(tt−1))
tensor 并行增加了设备之间的通信量。
当t大于单个接单的GPU数量时,需要节点之间进行通信。更慢的节点之间的链路的影响是很大的。
要点#1
当使用 g-GPUS服务器时,将tensor 并行度控制在g之内,使用pipeline 并行来跨服务器扩展模型
3.3 Data and Model Parallelism
3.3.1 流水线模型并行
- m = B / ( d b ) = b ′ / d m = B/(db) = b'/d m=B/(db)=b′/d
- 其中, b ′ = B b b' = \frac{B}{b} b′=bB p = n / ( t ⋅ d ) = n / d p = n/(t·d) = n/d p=n/(t⋅d)=n/d
B u b b l e t i m e f r a c t i o n ( p i p e l i n e b u b b l e s i z e ) = p − 1 m = n / d − 1 b ′ / d = n − d b ′ Bubble \,time \, fraction(pipeline \,bubble\, size) = \frac{p-1}{m} = \frac{n/d - 1}{b'/d} = \frac{n-d}{b'} Bubbletimefraction(pipelinebubblesize)=mp−1=b′/dn/d−1=b′n−d
- 当 d 变大,流水线气泡变小。
- 虽然将 d增加,会减少气泡,但是将 d增加到 n 是不太现实的,因为 一个模型的大小会超出 单个GPU的内存
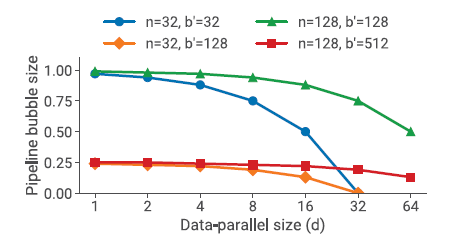
- 如果 数据并行all-reduce 通信,不会随着 d的升高而剧烈增加,比如 ring方法的实现,总的吞吐量会增加
- 分析 B batch size 增加的影响。 B增加,b’增加, (n - d)/ b’ 减少,因此吞吐量增加。
- B增大,data 并行的all-reduece 频率降低,更提高了吞吐率
3.3.2 Data and Tensor Model Parallelism
-
因为 tensor 模型并行, 每个microbatch 都需要执行 all-reduce 通信。
-
因为数据并行,每个batch 都要进行代价较大的 all-reduce 通信。
-
GPU负责计算一个层的一部分,如果模型的层不够大划分给一个GPU的矩阵计算太小,GPU的利用率会不高
-
tensor 的通信代价比 data并行的通信代价大得多。
要点#2
data 并行,只需要在 batch 层面进行 all-reduce。 但是tensor 并行,需要在 每个micro batch 层面进行all-reduce。
总的模型并行度 M = tp,tensor 和 pipeline 主要是为了 将大模型切分以适应GPU的主存,但是数据并行,主要是为了将训练扩展至更多的GPU。
3.4 Microbatch Size
microbatch 的大小 b 同样也可以影响模型训练的吞吐率。
- 想在给定(p,t,d) 和 batch size B的情况下,确定 最优的 microbatch 的大小 b
- 无论microbatch的大小如何,数据并行的通信量是不变的
- 给定 t f ( b ) t b ( b ) t_f(b) \quad t_b(b) tf(b)tb(b) ,分别表示了单个microbatch 的大小 与向前 、 向后的传递计算时间。不考虑通信的损耗,用于计算一个 batch的时间为
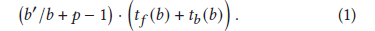
- microbatch的大小,影响计算操作 forward backward的强度,也影响气泡的大小。batch确定,d 确定,b 越大,microbatch的数量越少。 b 越大,forward,backward 计算量更大
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BHdRNdP8-1669727514434)(https://raw.githubusercontent.com/novaCoder-zrk/Picture-Bed/master/img[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2lmtSckd-1669727514735)(…assetsmarkdown-img-paste-20220710215139274.png)]].png)
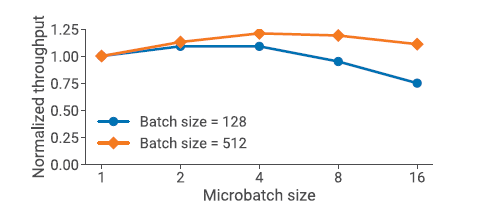
要点#3
对于 microbatch size b的优化,要考虑吞吐率,内存占用,pipeline深度 ,data 并行度 d,batch大小B
3.5 Activation Recomputation
-
激活值的重新计算是计算量和内存占用的 tradeoff
-
只存给定流水线阶段输入的激活值, 而不是保存整个集合上的大得多的激活值
-
在训练相当大的模型时,重新计算激活值,保证内存占用在一个较低的可接受的水平。
-
激活值检查点的数量不影响吞吐率,但是影响内存占用。
-
大多数情况下,每一到两 transformer层设置一个检查点最优
-
其他技术,比如 (激活分区)activation partitioning 可与和 tensor model 并行一起使用以降低 激活值得内存占用
4 IMPLEMENTATION
- 实现了PTD-P,作为 Megatron-LM 的代码库
- 使用PyTorch 构建
- 使用NCCL 作为设备间的通信
- 以优化通信和计算为目的
4.1 Communication Optimizations 通信优化
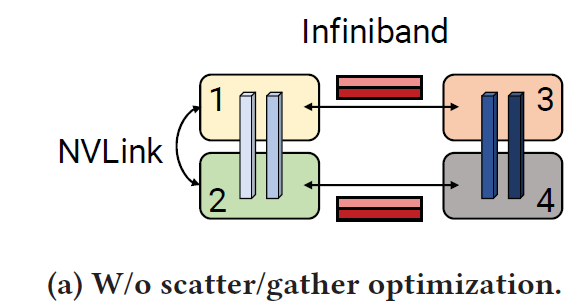
使用A100时,配备了8 个IB网卡,但是在两个sever之间,只能进行一对GPU之间的通信,这就很难充分利用8个卡。
- 使用 tensor模型 和 流水线模型,来降低跨界节点通信的额外开销。
- 每个transformer 层的输出是重复的,因为经过 all-reduce后(如 MLP block 中的g)每个GPU上的参数是一样的,如果8个卡,每一对之间发送的数据是相同的,并且sever之间的传输速度慢,会导致效率降低。
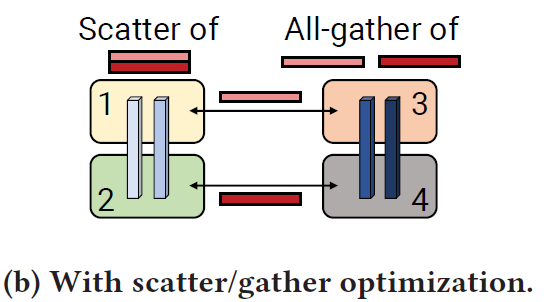
scatter/gather communication optimization
-
每个卡只需要发送 output的一部分,每个卡发送的数据量相等,在接收端通过NVLink 执行all-gather
-
将发送端的tensor1 划分成大小相等的块,每个rank 只发送一块到下个设备,通过 InfiniBand card
-
有 8 个tensor 并行,每个块是原先的 1/8大。 在接受端,使用 NVLink 上的 all-gather 来得到完整的tensor。
-
通过 scatter-gather 通信优化,在两个阶段之间的总的通信量减少到了 b s h t \frac{bsh}{t} tbsh, t 是tensor模型并行的大小, s是序列长度, h 是隐藏层大小
4.2 计算优化
三种特定模型的优化
-
首先 : 更改transformer 层的数据布局,来避免内存占用较多的转置操作(transpose) , 并且可以使用 strided batched GEMM ,将数据布局从[b,s,a,h] 和修改为[s,b,a,h] 。
-
其中 b,a,s,h, 分别为 batch 大小,序列长度, attention-head ,hidden-size 的维度??为什么原先的数据布局是这样??
-
其次,使用 PyTorCH JIT 为一系列元素级操作生成融合核 ,将几个kernel 融合在一起
-
第三, 创建了两个自定义核,来实现 scale, mask, and softmax (reduction) 的融合。 一个用来支持一般的mask ,另一个用于 隐含式因果mask (implicit causal masking)
5 EVALUATION
回答如下问题:
- PTD-P 表现如何,它是否会导致实际的端到端的训练时间?
- 在给定模型 和 batch大小时,流水线并行的扩展程度如何? 交错调度(interleaved schedule)如何影响性能?
- 不同维度的并行化如何联系? 超参数有什么影响?
- scatter-gather 通信优化的影响是什么? 在进行大规模训练的时候,我们对硬件做出了那些限制?
实验使用的是适当大小的GPT模型
5.1 End-to-End Performance
- 考虑使用GPT 模型,进行 end-to-end 训练的性能
- 随着模型增大,GPU的利用率提高,但是和计算时间相比,通信时间并没有显著的增加。
5.2 Comparison to ZeRo-3
- 使用标准的 GPT-3 模型结构
5.3 流水线并行
- 单独评估 流水线并行的 弱扩展性能(weak-scaling) ,比较非交错和交错调度的性能
5.3.1 Weak Scaling 弱扩展性能
pipeline 并行度从 1 变化到8,在增加pipeline 并行度的同时,改变模型的大小。比如 p = 1,使用3层transformer的模型,15 billion 个参数;p = 8,使24层transformer的模型,121 billion 个参数
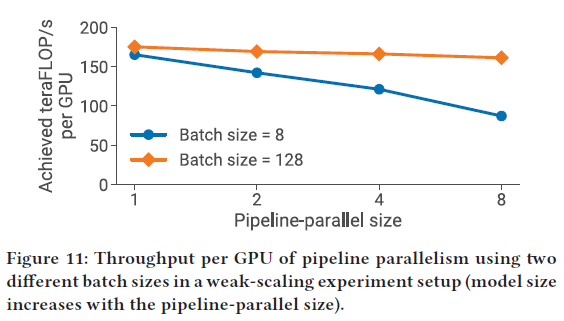
batch 越大,将 pipeline bubble摊到更多得到 microbatch中;batch越大,pipeline 并行度增加对计算雄安绿的影响越小。
5.3.2 Interleaved versus Non-Interleaved Schedule 交错v.s. 非交错流水线调度
交错流水线调度 和非交错流水线调度之间的 差距 gap 会随着batch增大而减小,主要有两个原因:
- a) batch增大,bubble size减小。
- b) batch 增大,通信量增加,给了非交错流水线 catch up的机会。 交错式流水线需要更多的通信。

5.4 Comparison of Parallel Configurations
讨论了不同为维度的并行度结合的tradeoff和性能
5.4.1 Tensor v.s. Pipeline 并行
- tensor 并行最好还是在同一个的sever内部
- 流水线气泡花得时间也很多,因此也不宜使得流水线阶段过多。
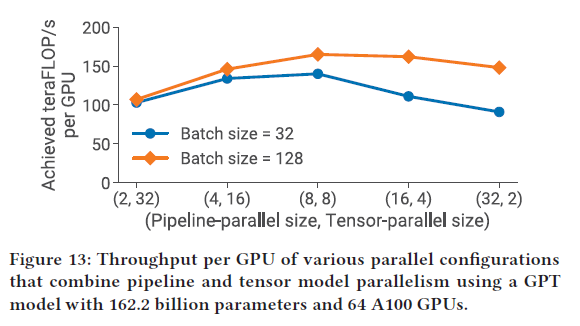
5.4.2 Pipeline v.s. Data 并行
流水线模型主要用来切分模型,数据并行主要用来扩大训练规模
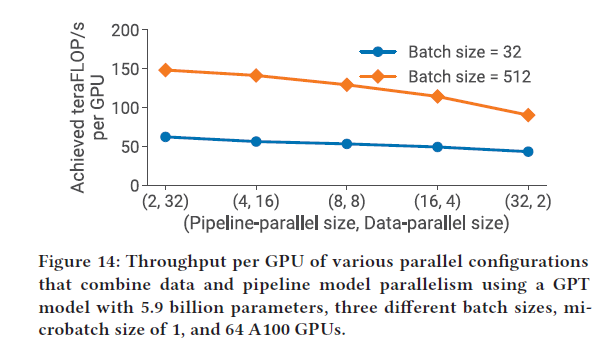
data 并行度越高,性能越高。
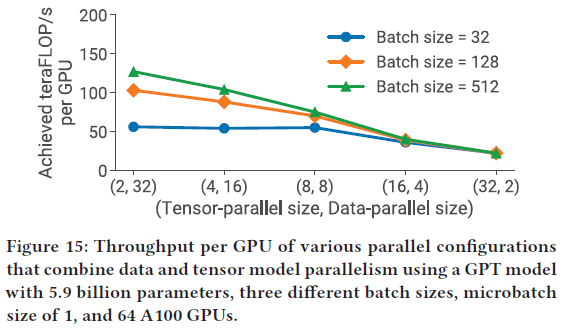
5.4.3 Tensor v.s. data 并行
- 相对于tensor 并行,data 并行的通信量更少
- tensor 并行度增加,使得每个GPU上的矩阵乘的规模更小,降低了GPU的利用率,同时又增加了 all-to-all 的通信量
data 并行无法总是应用
- a)GPU 内存限制,一个GPU无法装下一整个模型
- b) batch 大小1536,只是用data 并行只用1536GPU,但是可以使用10000个GPU
5.5 Microbatch Size
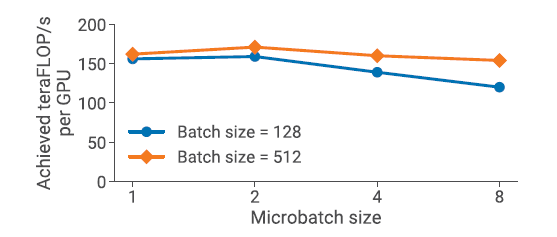
batch 大小固定,microbatch大小增加,m减小,气泡变大。但是 microbatch增大,GPU利用率提升了
5.6 Activation Recomputation
激活值重计算,可以减少内存占用,因此可以增加训练时batch的大小,来减小流水线中的气泡,会随着batch增大,提高效率
7 DISCUSSION AND CONCLUSION
这篇文章中,展示了PTD-P 可以组合在一起,来实现更高效的吞吐量