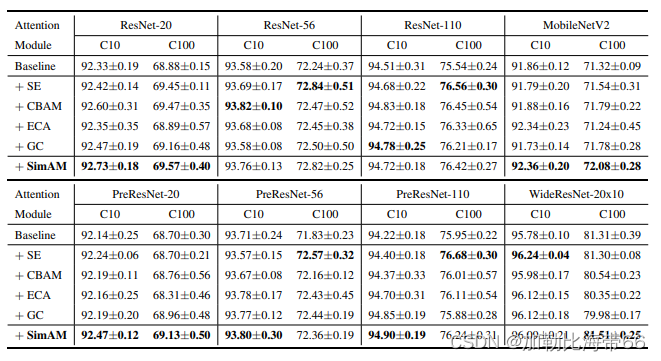
论文地址:Gaussian Prototypical Networks for Few-Shot Learning on Omniglot
文章目录
- 摘要
- 1 引言
- 1.1 Few-shot learning
- 1.2 高斯原型网络
- 2 相关工作
- 3 方法
- 3.1 编码器
- 3.2 偶发性训练
- 3.3 定义一个类
- 3.4 评估模型
- 4 数据集
- 5 实验
- 5.1 协方差估计的用法
- 6 结论
摘要
我们为Omniglot数据集的K-shot分类提出了一个新的架构。在原型网络的基础上,我们将其架构扩展到我们称之为高斯原型网络。原型网络学习图像和嵌入向量之间的映射,并使用其聚类进行分类。在我们的模型中,编码器输出的一部分被解释为关于嵌入点的置信区估计,并表示为高斯协方差矩阵。然后,我们的网络在嵌入空间上构建一个方向和类别相关的距离度量,使用单个数据点的不确定性作为权重。我们表明,高斯原型网络是一个优于具有同等数量参数的vanilla原型网络的架构。我们报告了Omniglot数据集在5-way和20-way制度下的1-shot和5-shot分类的最新性能(对于5-shot 5-way,我们与以前的最先进水平相当)。我们探索在训练集中人为地降低一部分图像的采样率,从而进一步提高我们的性能。因此,我们假设高斯原型网络在不太均匀、噪音较大的数据集中可能表现得更好,而这在现实世界的应用中是很常见的。
1 引言
1.1 Few-shot learning
人类能够在单一或少量的例子中学习识别新的物体类别。这已经在广泛的活动中得到证明,从手写字符识别[1],运动控制[2],到获得高水平的概念[3]。在机器中复制这种行为是研究少量学习的动机。
参数化的深度学习在有大量数据的环境中表现良好。一般来说,深度学习模型具有非常高的功能表现力和能力,并依赖于在监督制度下缓慢、迭代地训练。因此,训练集中的某个特定例子的影响很小,因为训练的目的是捕捉数据集的一般结构。这就防止了训练后迅速引入新的类别。[4]
与此相反,少数次学习需要非常快速地适应新数据。特别是,k-shot分类指的是一种制度,在训练期间未见的类必须使用k个标记的例子来学习。非参数模型,如k-近邻(kNN)不会过度拟合,然而,它们的性能在很大程度上取决于距离指标的选择。[5] 结合参数和非参数模型的架构,以及匹配的训练和测试条件,最近在k-shot分类上表现良好。
1.2 高斯原型网络
在本文中,我们在[6]中使用的原型网络的基础上开发了一个新的架构,并在Omniglot数据集[3]上对其进行训练和测试。Vanilla原型网络将图像映射成嵌入向量,并使用其聚类进行分类。他们将一批图像分为支持和查询图像,并使用支持集的嵌入向量来定义一个类别原型–一个给定类别的典型嵌入向量。然后用与这些的接近度来进行分类。
我们的模型,我们称之为高斯原型网络,将一幅图像映射成一个嵌入向量,以及对图像质量的估计。与嵌入向量一起,它周围的置信区域被预测出来,其特征是高斯协方差矩阵。高斯原型网络学习在嵌入空间上构建一个方向和类别相关的距离度量。我们表明,与vanilla原型网络相比,我们的模型是使用额外可训练参数的首选方式。
我们的目标是表明,通过允许我们的模型在单个数据点上表达其信心,我们达到了更好的结果。我们还试验了故意破坏部分数据集的做法,以探索我们的方法在嘈杂、不均匀的现实世界数据集中的可扩展性,其中单个数据点的加权可能对性能至关重要。
据我们所知,在Omniglot数据集上,我们报告了在5-way和20-way制度下1-shot和5-shot分类的最先进性能(对于5-shot 5-way,我们与以前的最先进性能相当)。[3] 通过研究我们的模型对下采样数据的反应,我们假设它在低质量、不均匀的数据集中的优势可能会更大。
本文的结构如下。我们在第2节中描述了相关工作。然后,我们在第3节中介绍我们的方法。这里还介绍了偶发训练方案。我们在第4节讨论了Omniglot数据集,并在第5节讨论了我们的实验。最后,我们的结论将在第6节中提出。
2 相关工作
非参数模型,如k-最近的邻居(kNN),是少量分类器的理想候选者,因为它们允许纳入以前未见过的类别。然而,它们对距离度量的选择非常敏感。[5] 直接使用输入空间中的距离(如原始像素值)并不能产生高精确度,因为图像类别和其像素之间的联系是非常非线性的。
正如[7]、[8]、[9]和[10]所证明的那样,一个直接的修改,即学习一个度量嵌入,然后用于kNN分类,产生了良好的结果。在[11]中提出了一种使用匹配网络的方法,实际上是在成对的图像之间学习一种距离度量。该方法的一个值得注意的特点是它的训练方案,其中每个小批(称为一集)试图通过对类的数量以及每个类中的例子的数量进行子抽样,来模仿数据贫乏的测试条件。事实证明,这样的方法可以提高少量分类的性能。[11] 因此,我们也采用了这种方法。
最近有人提出[12],不直接在数据集上学习,而是训练一个LSTM[13],以预测给定一个情节作为其输入的几率分类器的更新。这种方法被称为元学习(meta-learning)。如[14]和[15]所示,元学习在Omniglot[3]上已经达到了很高的精度。在[16]中提出了一个基于时间卷积的任务诊断性元学习器。参数方法和非参数方法的结合是最近在少量学习中最成功的。[6][17][18]
我们的方法是专门针对图像分类的,并不试图通过元学习来解决这个问题。我们建立在[6]中提出的模型上,该模型将图像映射为嵌入向量,并使用其聚类进行分类。我们模型的新特点是,它通过学习的、与图像相关的协方差矩阵来预测其对单个数据点的信心。这使得它能够构建一个更丰富的嵌入空间,将图像投射到其中。然后,在一个方向和类别相关的距离度量下,它们的聚类被用于分类。
3 方法
在本文中,我们首先探讨了[6]中描述的原型网络。我们将该架构扩展到我们所说的高斯原型网络,允许模型通过预测它们的嵌入向量以及它们周围的置信区域来反映单个数据点(图像)的质量,其特征是高斯协方差矩阵。
一个虚构的原型网络包括一个编码器,它将图像映射成一个嵌入向量。一个批次包含一个可用的训练类的子集。在每次迭代中,每个类别的图像都被随机分成支持图像和查询图像。支持图像的嵌入被用来定义类的原型–该类的典型嵌入向量。查询图像的嵌入与类原型的接近程度被用于分类。
vanilla原型网络和高斯原型网络的编码器架构并无不同。关键的区别在于编码器输出的解释和使用方式,以及嵌入空间的度量是如何构建的。在高斯网络中,编码器输出的一部分被用来构建关于嵌入向量的协方差矩阵,这使得我们的模型能够反映预测能力,以及单个数据点的质量。
3.1 编码器
我们使用一个没有明确的最后全连接层的多层卷积神经网络将图像编码为高维欧几里得向量。对于[6]中描述的虚无的原型网络,编码器是一个函数,取一个图像I并将其转换为一个向量~x,即
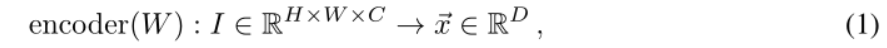
其中H和W是输入图像的高度和宽度,C是其通道的数量。D是我们向量空间的嵌入维度,是模型的超参数。W是编码器的可训练权重。
对于高斯原型网络,编码器的输出是嵌入向量~x∈RD和协方差矩阵Σ∈RD×D 的相关分量的连接。因此
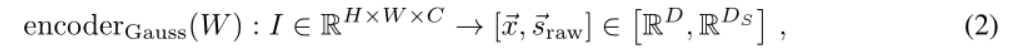
其中DS是协方差矩阵预测分量的维数。
我们探讨了高斯原型网络的三种变体。
- 半径协方差估计。DS=1,每幅图像只生成一个实数sraw∈R1,以描述其嵌入向量周围的置信区间的大小。因此,协方差矩阵的形式为Σ=diag(σ,σ,…,σ),其中σ是从原始编码器输出sraw 中计算出来的。因此,置信度估计是不具有方向性的。在Omniglot数据集上,这种方法被证明是对额外参数最有效的使用[3]。我们怀疑这种偏好可能是针对数据集的,不太同质的数据集可能更喜欢更复杂的协方差估计。
- 对角线协方差估计。DS=D,协方差估计的维度与嵌入空间的维度相同。→sraw∈RD在每个图像上生成,以描述嵌入向量周围的置信区间的大小。因此,协方差矩阵的形式是Σ = diag (→σ),其中→σ是由原始编码器输出→sraw计算出来的。这使得网络可以表达对数据点的方向性信心,尽管信心椭圆体总是与嵌入空间轴保持轴对齐。
- 完全协方差估计。每个数据点都会输出一个完整的协方差矩阵。事实证明,这种方法对于所给的任务来说是不必要的复杂,因此没有进一步探讨。
我们使用下采样的维度为28×28×1的灰度Omniglot图像作为输入。一个4层的CNN架构与2×2的最大集合结果是一个形状为1×1×(D+DS)的体积,其中嵌入维度D加上协方差矩阵DS的相关部分等于最后的过滤器数量。我们使用的是TensorFlow的SAME padding和stride 1。我们的过滤器在空间范围内是3×3。最后一层相当于一个全连接的层。
我们正在使用2个编码器架构。1)一个小型架构,和2)一个大型架构。小型架构对应于[6]中使用的架构,我们用它来验证我们自己的实验与之前的最先进的结果。大架构被用来观察增加模型容量对准确性的影响。作为一个基本构件,我们使用公式3中的层序列。
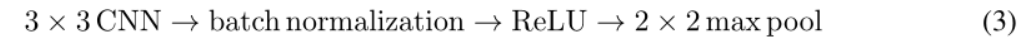
两种架构都是由4个这样的块状物堆叠在一起组成的。架构的细节如下。
- 小结构。3×3过滤器,过滤器的数量[64,64,64,D]([64,64,64,D+1]为半径高斯模型,[64,64,64,2D]为对角高斯模型)。探索的嵌入空间尺寸为D=32、64、128。
- 大架构。3×3过滤器,过滤器的数量[128,256,512,D](半径高斯模型为[128,256,512,D+1],对角线高斯模型为[128,256,512,2D])。探索的嵌入空间尺寸为D=128,256,512。
我们探索了4种不同的方法,将编码器的原始协方差矩阵输出转化为实际的协方差矩阵。由于我们主要处理协方差矩阵S=Σ-1的逆值,所以我们是直接预测它。让原始编码器输出的相关部分为Sraw。方法如下。
- S = 1 + softplus(Sraw),其中softplus(x) = log (1 + ex),它是分量级应用的。由于softplus(x)>0,这就保证了S>1,编码器只能使数据点不那么重要。S的值也不受上述限制。这两种方法都被证明有利于训练。我们最好的模型使用这种制度进行初始训练。
- S = 1 + sigmoid (Sraw),其中sigmoid(x) = 1/ (1 + e-x),它是分量级应用的。由于sigmoid(x)>0,这就保证了S>1,编码器只能使数据点不那么重要。S的值从上面看是有界限的,因为S<2,因此编码器受到的约束更大。
- S = 1 + 4 sigmoid (Sraw),因此,1 < S < 5。我们用它来探索协方差估计域的大小对性能的影响。
- S = offset + scale × softplus (Sraw/div),其中offset、scale和div被初始化为1.0,并且是可训练的。我们最好的模型在后期训练中使用了这个制度,因为它比第一种方法更灵活,更有数据驱动力。
3.2 偶发性训练
原型模型的一个关键组成部分是[6]中描述的偶发性训练制度。在训练过程中,从训练集的总类数中选择一个Nc类的子集(不替换)。对于这些类中的每一个,随机选择Ns个支持实例,以及Nq个查询实例。支持例子的编码嵌入被用来定义一个特定的类原型在嵌入空间中的位置。查询实例与类原型位置之间的距离被用来对查询实例进行分类并计算损失。对于高斯原型网络,每个嵌入点的协方差也被估计。该过程的示意图见图1。
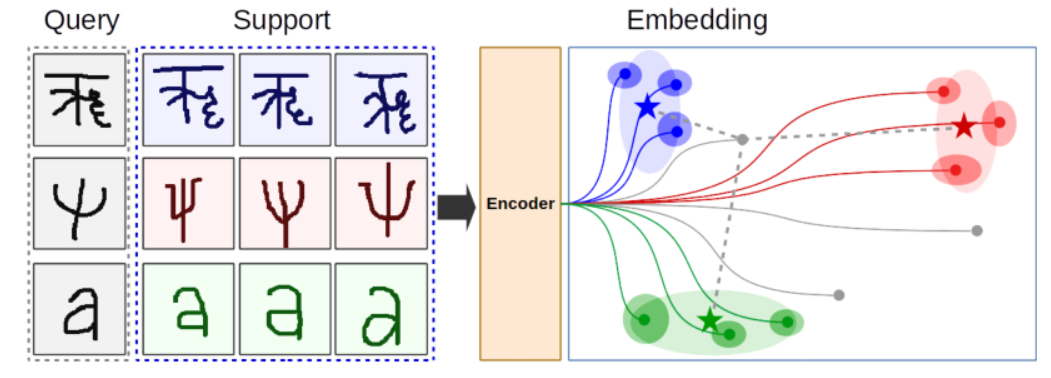
图1:高斯原型网络的功能示意图。编码器将图像映射为嵌入空间中的一个矢量(深色圆圈)。每幅图像也会输出一个协方差矩阵(暗椭圆)。支持图像被用来定义特定类别的原型(星星),和协方差矩阵(浅色椭圆)。中心点和编码的查询图像之间的距离,由一个类别的总协方差修正,用于对查询图像进行分类。距离显示为特定查询点的灰色虚线。
对于高斯原型网络,协方差矩阵的半径或对角线与嵌入向量(更准确地说,其原始形式是,详见第3.1节)一起输出。然后,这些都被用来加权对应于某一特定类别支持点的嵌入向量,以及计算该类别的总协方差矩阵。然后,从一个类的原型c到一个查询点i的距离dc(i)被计算为
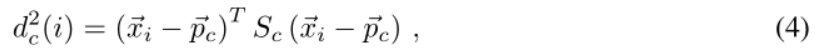
其中→pc 是类c的中心点,或原型,Sc = Σ-1c 是其协方差矩阵的逆。因此,高斯原型网络能够在嵌入空间中学习类和方向相关的距离度量。我们发现,训练的速度和其准确性在很大程度上取决于如何使用距离来构建损失。我们得出结论,最好的选择是使用线性欧氏距离,即dc(i)。所用损失函数的具体形式在算法1中提出。图2显示了高斯原型网络的嵌入空间图。附录中的图10和图11显示了训练期间嵌入空间的一个样本。它说明了用于分类的类似字符的聚类。
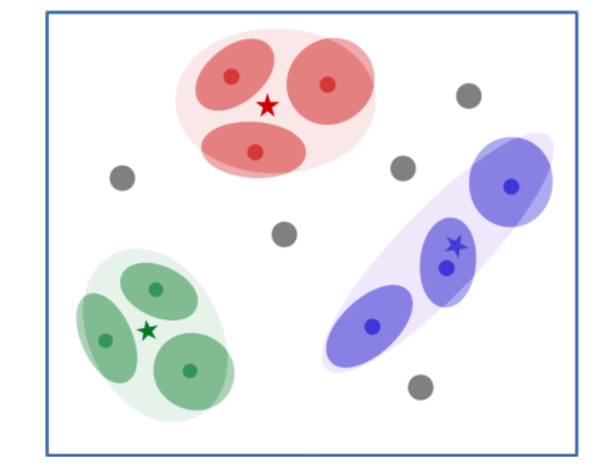
图2:显示高斯原型网络的嵌入空间的图。一幅图像被编码器映射到它的嵌入向量(暗点)。它的协方差矩阵(暗椭圆)也由编码器输出。然后,每个类别的总体协方差矩阵被计算出来(大的浅色椭圆),以及类别的原型(星星)。一个类别的协方差矩阵被用来局部修改查询点的距离指标(灰色显示)。
我们研究的是协方差矩阵是对角线的设置,如第3.1节中所总结的。对于半径情况,S = sI,其中I是身份矩阵,s∈R1是从每个图像的原始编码器输出中计算出来的。对于对角线的情况,S = diag (→s),其中→s同样是从每个图像的原始编码器输出中计算出来的。
3.3 定义一个类
原型网络的一个关键部分是从特定类别的可用支持点中创建一个类别原型。我们提出用单个支持实例的嵌入向量的方差加权线性组合作为我们的解决方案。让类c有支持图像 Ii,这些图像被编码为嵌入向量→xci,以及协方差矩阵Sci的倒数,其对角线为→sci。原型,即该类的中心点,被定义为

其中 ◦ 表示分量上的乘法,除法也是分量上的。然后,类协方差矩阵的对角线被计算为

这相当于将以各个点为中心的高斯优化组合成一个整体的类高斯,因此网络的名字就叫高斯。s的元素实际上是1/σ2。因此,方程5和6对应于用1/σ2对例子进行加权。这使得网络可以降低对定义类别不太重要的例子的权重,因此使我们的架构更适合于嘈杂、不均匀或其他不完善的数据集。
对于一个一次性的制度,也就是我们的网络被训练的方式,有一个单一的标记向量→xc来定义每个类别。这意味着该向量本身成为类的原型,其协方差矩阵也被类所继承。然后,协方差在修改与查询点的距离中发挥作用。算法1中描述了完整的算法。
3.4 评估模型
为了估计模型在测试集上的准确性,我们在k∈[1, …19]的范围内对每一个支持点的数量Ns=k对整个测试集进行分类。因此,特定k的查询点的数量是Nq = 20 - Ns,因为Omniglot提供了每个类别的20个例子。然后,准确率被汇总,对于模型训练的一个特定阶段,确定了作为k函数的k-shot分类准确率。由于我们没有使用指定的验证集,我们通过考虑5个最高训练精度的测试结果来确保我们的公正性,并计算其平均值和标准差。通过这样做,我们防止了对测试集的优化结果,并进一步获得了对所产生的准确度的误差界限。我们在5路和20路测试分类中评估我们的模型,以直接与现有文献进行比较。
4 数据集
我们使用了Omniglot数据集。[3] Omniglot包含来自50个字母(真实的和虚构的)的1623个字符类和每个字符类的20个手写的、灰度的、105×105像素的例子。我们将它们下采样为28×28×1,减去它们的平均值,并将它们倒置。我们使用了推荐的分割方法,即30个训练字母和20个测试字母,这是由[3]建议的,并被[6]使用。训练集包括964个独特的字符类,而测试集包括659个。训练和测试数据集之间没有类别重叠。我们没有使用单独的验证集,因为我们没有对超参数进行微调,只根据训练准确率选择了性能最好的模型(见第3.4节)。
为了扩大类的数量,我们通过将每个字符旋转90◦、180◦和270◦ 来增加数据集,并将每次旋转都定义为一个新的字符类本身。同样的方法在[11]和[6]中也有使用。图3中显示了一个增强的字符的例子。这使类的数量增加了4倍。因此,训练集总共包括77,120张图像,测试集包括52,720张图像。由于旋转增强,具有旋转对称性的字符还是被定义为多个类别。由于即使是假设的完美分类器也无法区分 "O "和旋转的 "O "等字符,因此无法达到100%的准确率。

图3:一个通过旋转增加类数的例子。一个原始字符(在左边)被旋转了90◦、180◦和270◦。每个旋转都被定义为一个新的类。这增加了类的数量,但也为对称字符引入了退化现象。
为了改善训练,并利用高斯网络预测字符协方差的能力,我们在一些实验中特意对部分训练集进行了下采样。详细情况见第5节。我们的结果表明,Omniglot数据集过于简单,无法充分利用高斯网络估计协方差矩阵的能力。我们假设,我们的方法在单个数据点质量不同的非均质数据集上会显示出更大的优势,这在现实世界的应用中是很常见的情况。
5 实验
我们在Omniglot数据集上进行了大量的几次学习实验。对于高斯原型网络,我们探索了不同的嵌入空间维度、生成协方差矩阵的方式和编码器的能力(详见3.1节)。我们还将它们与vanilla原型网络进行了比较,结果表明,我们的高斯变体是有利的,特别是使用额外参数的最有效方式是预测每个嵌入点的单一数字(第3.1节中的半径法)。一般来说,我们探索了编码器的大小(小,和大,如第3节所述),高斯/vanilla原型网络的比较,距离度量(cosine,√L2,L2和L22),高斯网络中协方差矩阵的自由度数(半径,和对角线估计,见第3.1节),以及嵌入空间的维度。我们还探索了通过对输入数据集的一个子集进行下采样以鼓励网络使用协方差估计,并发现这提高了(k>1)次的性能。
我们使用的是Adam优化器,初始学习率为2×10-3。我们每隔2000个事件≈30个epochs将学习率减半。我们所有的模型都是用TensorFlow实现的,并在谷歌云的单个NVidia K80 GPU上运行。每个模型的训练时间都少于一天。
我们在训练时用Nc=60类(60路分类)训练我们的模型,并对Nct=20类(20路)分类进行测试。对于我们表现最好的模型,我们还进行了最后的Nct=5(5-way)分类测试,将我们的结果与文献进行比较。在训练过程中,小批量中存在的每个类都由Ns=1个支持点组成,因为我们发现限制支持点的数量会导致更好的分类精度。这可以直观地理解为训练制度与测试制度的匹配。每个类别剩下的Nq = 20 - Ns = 19张图像被用作查询点。
我们实验的详细结果总结在表1中。我们探索了4种从编码器的原始协方差输出估计协方差矩阵的方法,详见3.1节。
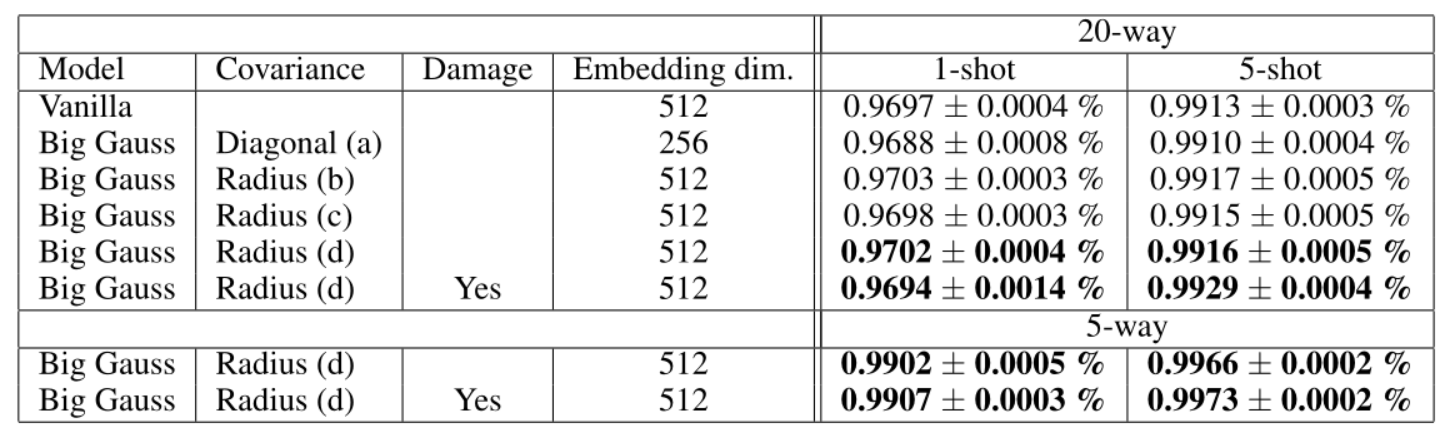
表1:大编码器结构(3×3过滤器,4层,过滤器数量=128,256,512,-)的测试结果,比较协方差矩阵的维度以及嵌入空间对最终精度的影响。(a, b, c, d)涉及到将原始编码器输出转换为协方差矩阵的不同方法。协方差的半径估计为编码器的输出增加了一个维度。对角线估计使编码器输出的数量增加一倍。因此,具有256个嵌入维度和对角线协方差的大高斯网络的参数数量与512个的虚构网络相同。半径估计增加了1个维度,因此可与相同嵌入维度的虚构模型相媲美。损坏一栏表示训练集在训练过程中特意进行了部分下采样。
我们还验证了,只要协方差估计不是不必要的复杂,使用编码器输出作为协方差估计比使用相同数量的参数作为额外的嵌入维度更有利。这对于半径估计(即每个嵌入向量有一个实数)是成立的,然而,对角线估计似乎对性能没有帮助(保持参数数量相等)。这种影响显示在图4和表1中。表现最好的模型最初是在未损坏的数据集上训练了220个epochs。然后继续训练,将1.5%的图像下采样为24×24,1.0%下采样为20×20,0.5%下采样为16×16,进行100个历时。然后用1.5%下采样到23×23,1.0%下采样到17×17,持续20个历时,1.0%下采样到23×23,持续10个历时。这些选择是很随意的,没有经过优化。对数据集有目的的破坏鼓励了协方差估计的使用,并增加了(k>1)次的结果,如表1和图5所示。这部分表明Omniglot数据集对我们的方法来说是一个质量太高、太简单的测试平台。训练损失曲线见图6。训练和测试准确率作为迭代的函数也显示在图7中。
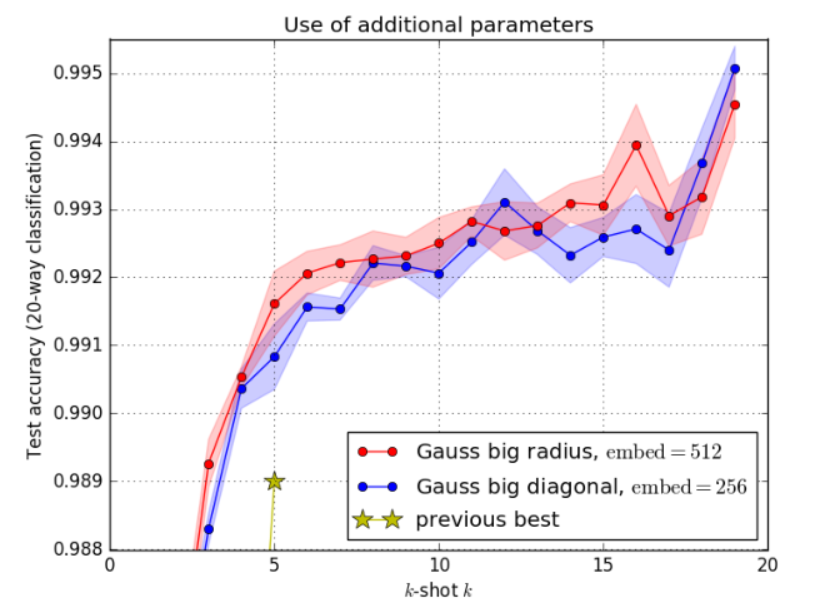
图4:两种分配额外参数的方法的比较。分配额外的参数来增加嵌入空间的维度(半径),或者做一个更精确的协方差估计(对角线)。半径估计(每个嵌入向量有1个额外的实数)优于对角线估计,以及具有相同参数数量的虚构原型网络。
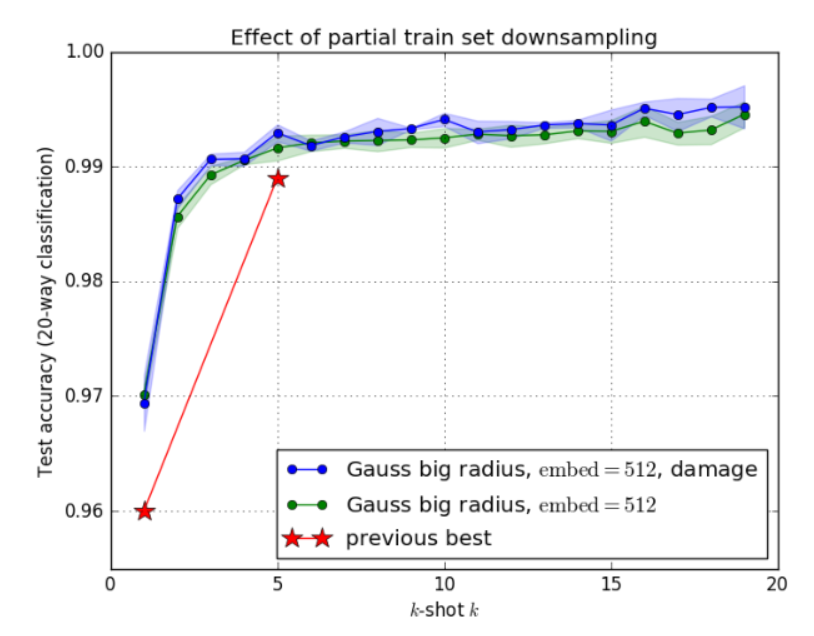
图5:对训练集的一部分进行下采样对k-shot测试精度的影响。在特意损坏的数据上训练的版本优于在未修改的数据上训练的版本,因为它学会了更好地利用协方差估计。
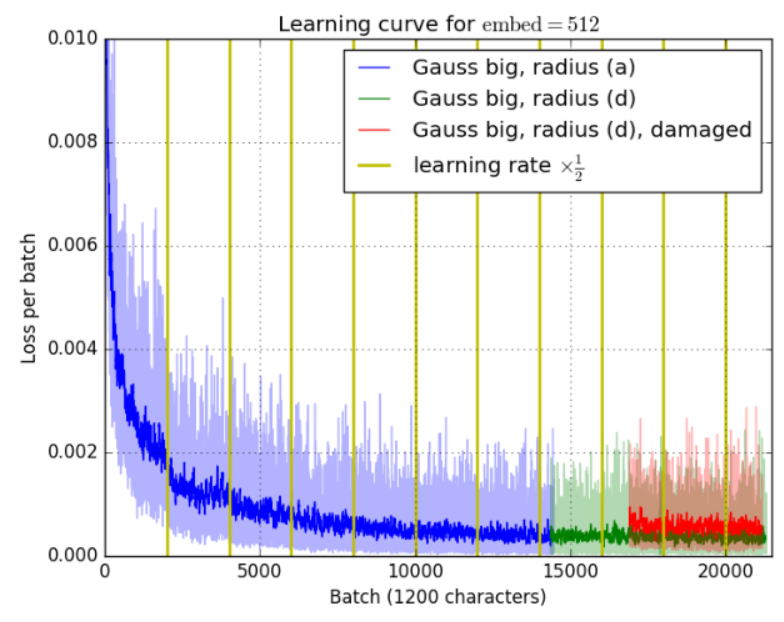
图6:损失是迭代的一个函数。黄色的垂直线表示学习率减半的地方。学习率减半的有利影响在开始时就可以看到。红色部分对应的是在部分下采样训练集上的训练,因此有较高的损失。
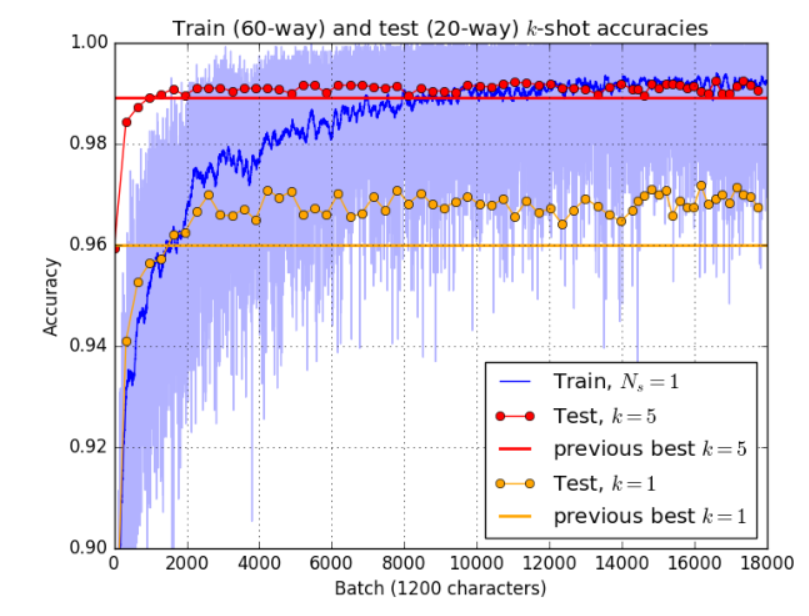
图7:训练精度与测试精度的比较。该图显示了一个大型高斯原型网络(半径协方差估计)的训练精度(60路分类),并将其与1次和5次测试性能(20路分类)进行比较。它还将结果与当前最先进的技术进行了比较。[6]
我们用小型架构进行了验证实验,得出了与[6]相当的结果,如表2所总结的。该表还显示,在Ns>1的制度下进行训练,即用更多的数据点定义一个类别,会导致更差的性能。图8显示了大模型的较高容量的效果。我们的模型与文献中的结果的比较见表3。据我们所知,我们的模型在Omniglot上的5-way和20-way测试时间分类中都超过了最先进的1-shot和5-shot结果。特别是在5-way 5-shot分类中,我们达到了非常接近完美的性能(99.73 ± 0.02 %),因此得出结论,需要一个更复杂的数据集来进一步开发少量学习算法。
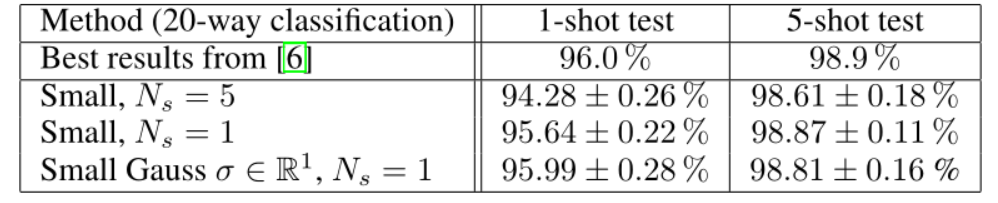
表2: 我们用小型架构进行验证实验的结果。20路分类的技术水平1-shot为96.0 %,5-shot为98.9 %。Ns是训练期间每类支持点的数量。所有的训练都是在Nc=60(60路分类)制度下进行的。对于高斯原型模型,σ∈S表示估计协方差矩阵的维度。
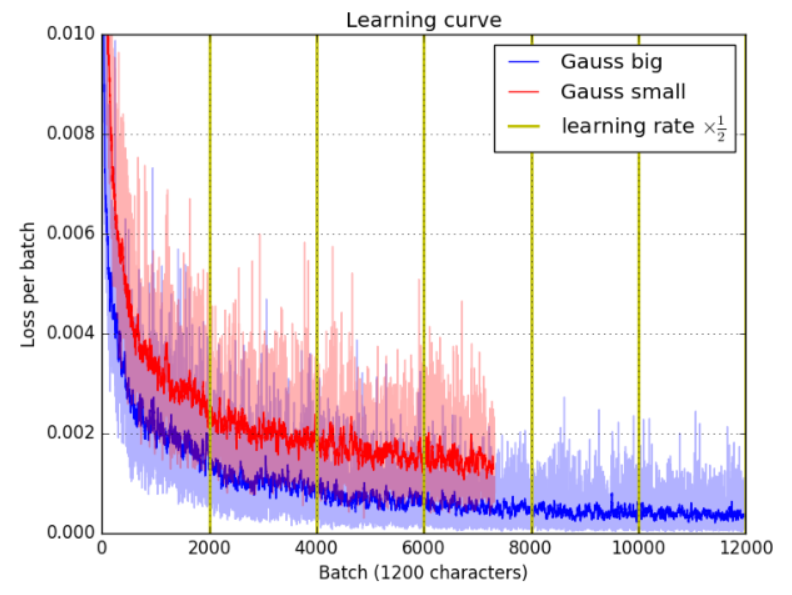
图8:模型容量对损失的影响。更大的模型训练得更快,总体上达到更小的损失。黄色的垂直线表示学习率减半的地方。
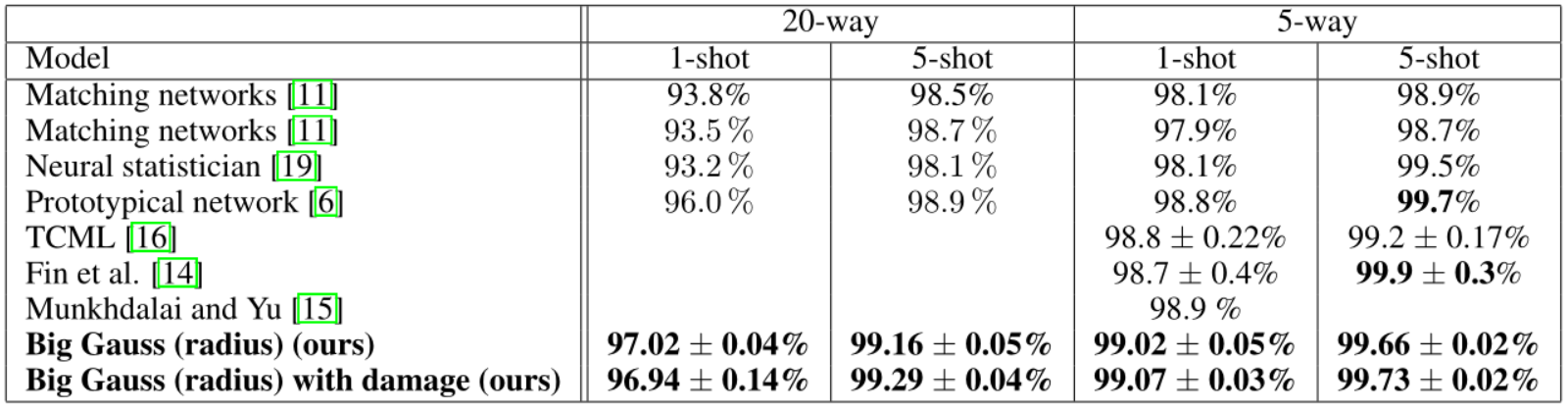
表3:与其他论文相比,我们实验的最佳结果。所有的训练都是在Nc=60(60路分类)制度下进行的。据我们所知,我们的模型在1-shot和5-shot 20-way分类以及1-shot 5-way分类中都有统计学意义上的最先进性能。在5次5路的情况下,我们的表现与目前最先进的水平相当。
5.1 协方差估计的用法
为了验证我们的假设,即高斯原型网络由于能够预测单个嵌入图像的协方差并因此有可能降低它们的权重而优于vanilla版本,我们研究了在部分下采样训练集上训练的最佳性能网络的预测值s的分布。我们特意对部分数据进行了下采样,并研究了由此产生的协方差分布。
下采样的图像会改变其平均值和方差。由于我们的编码器在每个区块中都有一个批量归一化层(详见方程3),原始输出的特定值的意义会根据当前的批次而改变。由于我们的模型是用批量归一化训练的,所以关闭它来研究协方差会导致不相关的结果。
对于未受损害的数据集,绝大部分协方差估计值都是相同的。即使在通过下采样人为地引入损伤时,这一点也保持不变。然而,由于最后一层中批量归一化的影响,分布发生了偏移。为了更好地表示单个反协方差的含义,我们将直方图对齐,使最频繁的值相互匹配。这种方法很有用,因为最主要的值对应于0的原始输出,而只有与之不同的值才会影响分类。结果显示在图9中。
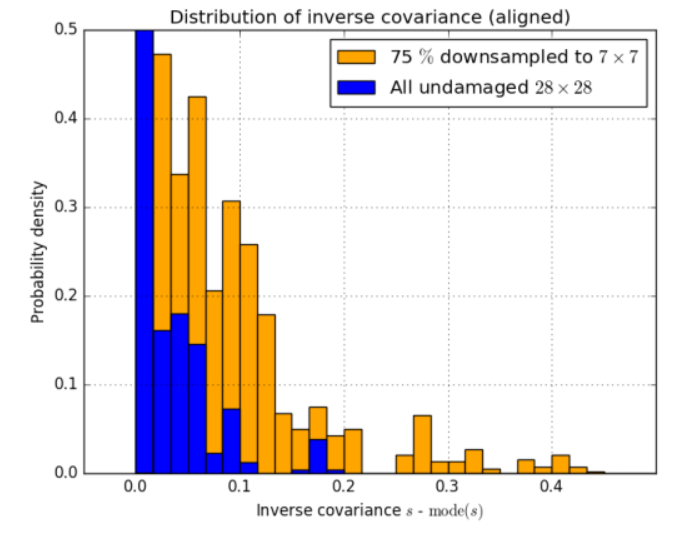
图9:原始数据集和部分下采样版本的预测协方差。高斯网络学会了通过预测更高的S来降低受损例子的权重,从黄色分布的更重的尾部可以看出。分布被排列在一起,因为只有前缘和一个值之间的差异影响分类。
6 结论
在本文中,我们提出了用于少数照片分类的高斯原型网络–一种基于原型网络的改进架构[6]。我们在Omniglot数据集上测试了我们的模型,并探索了生成协方差矩阵估计值和嵌入向量的不同方法。我们表明,在参数数量相当的情况下,高斯原型网络优于vanilla原型网络,因此,我们的架构选择是有益的。我们发现,在嵌入向量之上估计一个单一的实数比估计一个对角线或全协方差矩阵效果更好。我们猜想,质量较低、同质性较差的数据集可能更喜欢更复杂的协方差矩阵估计。与[6]相反,我们发现,如果在1-shot制度下训练网络,可以获得最佳结果。然后,我们扩大了模型的规模,并设法在5-way和20-way测试体系中的1-shot和5-shot分类中达到了最先进的性能(对于5-shot 5-way,我们与以前的最先进水平相当)。我们通过人为地降低训练数据集的取样率,鼓励网络充分利用协方差估计值,设法获得更好的准确性(特别是对于(k>1)-shot分类)。特别是对于5-way分类,我们的结果非常接近完美的性能,因此我们得出结论,在少数照片分类方面的进一步发展应该集中在比Omniglot更复杂的数据集上。我们假设,学习嵌入及其不确定性的能力对于质量较差的数据集会更加有利,而这在现实世界的应用中是很常见的。在那里,降低一些数据点的权重可能是忠实分类的关键。我们对Omniglot进行的下采样实验证明了这一点。