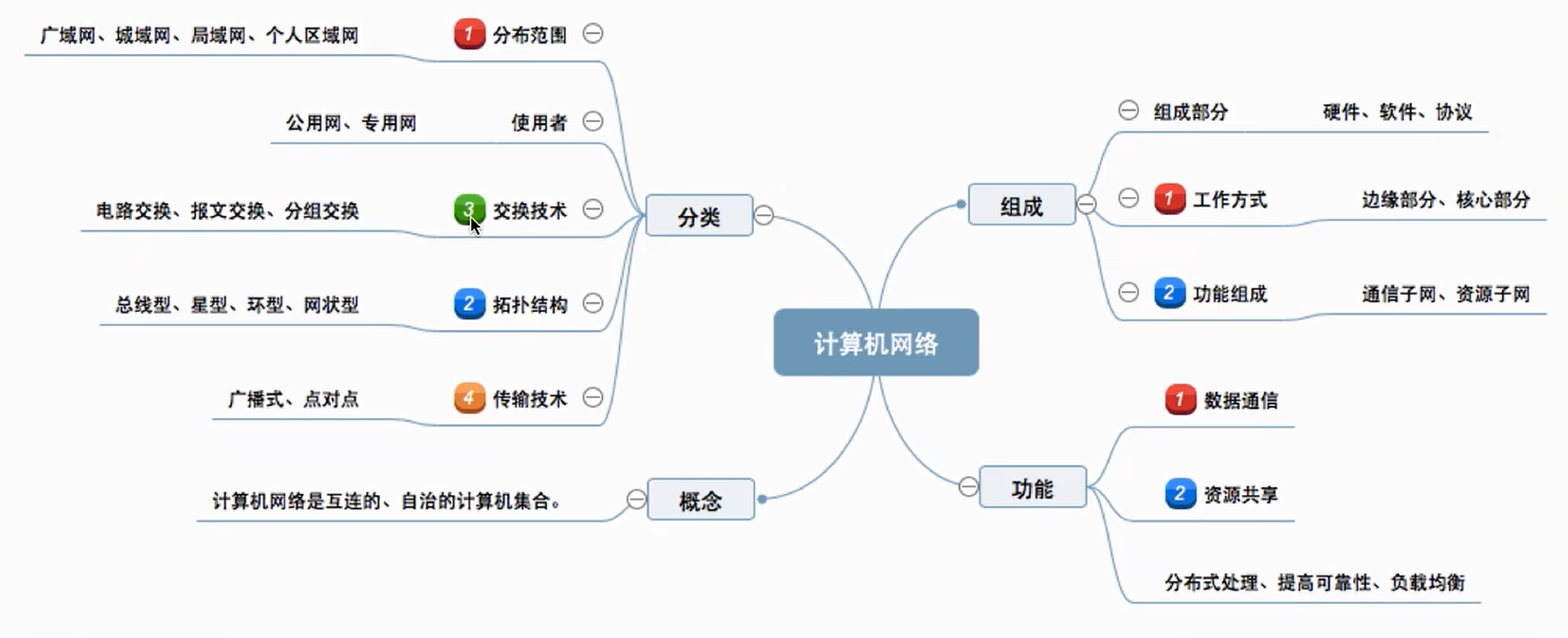
目录
(一)前言介绍
1.摘要
2.不同注意力步骤比较
(二)相关实验
(三)YOLOv5结合无参注意力SimAM
1.配置.yaml文件
2.配置common.py
3.修改yolo.py
SimAM:无参数Attention助力分类/检测/分割涨点!!!
(一)前言介绍
论文题目:SimAM: A Simple, Parameter-Free Attention Module for Convolutional Neural Networks
论文地址:http://proceedings.mlr.press/v139/yang21o/yang21o.pdf
源代码:https://github.com/ZjjConan/SimAM
1.摘要
本文提出一种概念简单且非常有效的注意力模块。不同于现有的通道/空域注意力模块,该模块无需额外参数为特征图推导出3D注意力权值。具体来说,基于著名的神经科学理论提出优化能量函数以挖掘神经元的重要性。进一步针对该能量函数推导出一种快速解析解并表明:该解析解仅需不超过10行代码即可实现。该模块的另一个优势在于:大部分操作均基于所定义的能量函数选择,避免了过多的结构调整。最后在不同的任务上对所提注意力模块的有效性、灵活性进行验证。
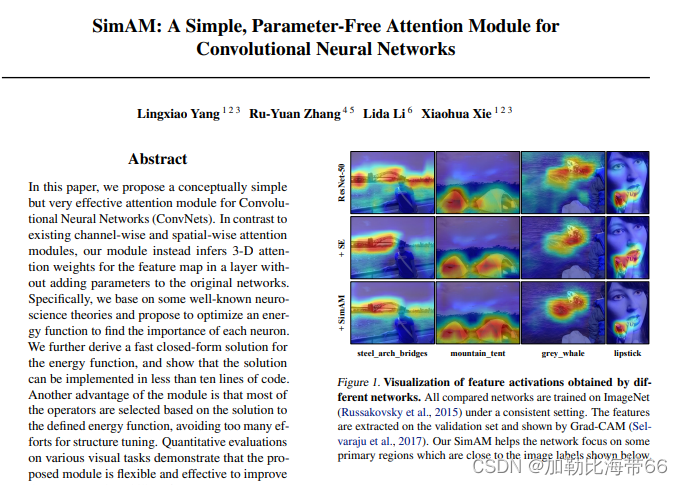
2.不同注意力步骤比较
(二)相关实验
对比其他注意力模型,+SimAM注意力后均表现出优秀的检测效果!!!
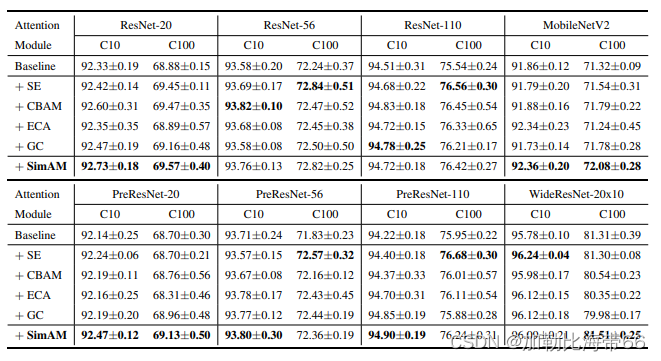
上表给出了ImageNet数据集上不同注意力机制的性能对比,从中可以看到:
1.所有注意力模块均可以提升基线模型的性能;
2.所提SimAM在ResNet18与ResNet101基线上取得了最佳性能提升;
3.对于ResNet34、ResNet50、ResNeXt50、MobileNetV2,所提SimAM仍可取得与其他注意力相当性能;
4.值得一提的是,所提SimAM并不会引入额外的参数;
5.在推理速度方面,所提SimAM与SE、ECA相当,优于CBAM、SRM。
(三)YOLOv5结合无参注意力SimAM
1.配置.yaml文件
添加方法灵活多变,和CBAM等注意力一样,Backbone或者Neck都可。
2.配置common.py
复制粘贴SimAM相关代码
class SimAM_Moudle(torch.nn.Module):
def __init__(self, channels = None, e_lambda = 1e-4):
super(SimAM_Moudle, self).__init__()
self.activaton = nn.Sigmoid()
self.e_lambda = e_lambda
def __repr__(self):
s = self.__class__.__name__ + '('
s += ('lambda=%f)' % self.e_lambda)
return s
@staticmethod
def get_module_name():
return "simam"
def forward(self, x):
b, c, h, w = x.size()
n = w * h - 1
x_minus_mu_square = (x - x.mean(dim=[2,3], keepdim=True)).pow(2)
y = x_minus_mu_square / (4 * (x_minus_mu_square.sum(dim=[2,3], keepdim=True) / n + self.e_lambda)) + 0.5
return x * self.activaton(y)
3.修改yolo.py
找到parse_model函数,加入SimAM_Moudle模块即可。具体可参考CBAM注意力方法。











![[附源码]计算机毕业设计JAVAjsp心理测评系统](https://img-blog.csdnimg.cn/cb033dfc706b44f6954173a3b53694e2.png)