CUDA从入门到放弃系列包含内容
- 异构并行计算
- CUDA编程模型
- CUDA执行模型
- CUDA内存
- CUDA流和并发
- CUDA指令级原语
- GPU加速库
- 多GPU编程
本文你将了解到
- 异构并行计算
- CUDA编程模型
温馨提示: 本文可能引发C/C++零基础的读者不适,请谨慎观看.
一、聊聊异构并行计算
异构并行计算的本质是把任务分发给不同架构的硬件计算单元(比方说CPU、GPU、FPGA等),让他们各司其职。
同步工作。如同平时工作,把业务中不同类型的任务分给不同的计算资源运行。
从软件的角度来讲
异构并行计算框架是让软件开发人员高效地开发异构并行的程序。充分使用计算平台资源。
从硬件角度来讲
一方面,多种不同类型的计算单元通过很多其它时钟频率和内核数量提高计算能力
另一方面,各种计算单元通过技术优化(如GPU从底层架构支持通用计算,通过分支预測、原子运算、动态并行、统一寻址、NIC直接訪问显存等能力)提高运行效率。
异构计算(Heterogeneous Computing) 在80年代中期就已产生。其定义更加宽泛。
异构计算主要是指使用不同类型指令集和体系架构的计算单元组成系统的计算方式。
常见的计算单元类别包含CPU、GPU等协处理器、DSP、ASIC、FPGA等。
一个异构计算平台往往包含使用不同指令集架构(ISA)的处理器。
在HPC异构并行计算架构应用技术中,通常分为通用架构并行和专用架构并行
通用架构并行分为:
- 同构多核并行(X86 CPU多核并行计算和非X86 CPU多核并行计算)
- 异构众核并行(CPU+GPU异构协同计算和CPU+MIC异构协同计算)
专用架构并行: 主要是指CPU+FPGA异构协同计算
从更广义的角度来讲,不同计算平台的各个层次上都存在异构现象
除硬件层的指令集、互联、内存层次之外。软件层中应用二进制接口、API、语言特性底层实现等的不同。
对于上层应用和服务而言,都是异构的。
异构并行计算框架有个很重要的特征就是可以帮助开发人员屏蔽底层硬件差异,能让软件平台自适应未来硬件的演进。
概括来说,理想的异构计算具有例如以下的一些要素
- 它所使用的计算资源具有多种类型的计算能力。如SIMD、MIMD、向量、标量、专用等
- 它须要识别计算任务中各子任务的并行性需求类型。
- 它须要使具有不同计算类型的计算资源能相互协调运行。
- 它既要开发应用问题中的并行性,更要开发应用问题中的异构性
- 它追求的终于目标是使计算任务的运行具有最短时间。
异构计算技术是一种使计算任务的并行性类型(代码类型)与机器能有效支持的计算类型(即机器能力)最匹配、最能充分利用各种计算资源的并行和分布计算技术。
异构计算处理过程本质上可分为三个阶段:
- 并行性检測阶段。并行性检測不是异构计算特有的。同构计算也须要经历这一阶段。可用并行和分布计算中的常规方法加以处理。
- 并行性特征(类型)析取阶段。并行性特征析取阶段是异构计算特有的,这一阶段的主要工作是预计应用中每一个任务的计算类型參数,包含映射及对任务间通信代价的考虑。
- 任务映射和调度阶段,也称为资源分配阶段。主要确定每一个任务(或子任务)应该映射到哪台机器上运行以及何时开始运行。
从用户来看,上述的异步计算处理过程可用两种方法来实现:
第一种是用户指导法,即由用户用显式的编译器命令指导编译器完毕相应用代码类型分析及有关任务的分解等工作,这是一种显式开发异构性和并行性方法,较易于实现。
但对用户有一定要求,需将异构计算思想融入用户程序中。
这是当前主流採用的方法,我们所知的CUDA(Computing Unified Device Architecture) 、OpenCL都是採用用户指导法。
还有一种是编译器指导法,需将异构思想融入编译器中,然后由具有“异构智能”的编译器自己主动完毕应用代码类型分析、任务分解、任务映射及调度等工作,即实现自己主动异构计算。
这是一种隐式开发异构性和并行性方法,是异构计算追求的终极目标。但难度很大,对编译器要求很高。
NVIDIA已经開始部分尝试编译器指导法。当然,基于CUDA Core的同构特征,也可以觉得其做的是同构自己主动调度。
异构计算按提供计算类型多样性的形式来看。
可分为系统异构计算SHC (System Heterogeneous Computing) 和网络异构计算NHC (Network Heterogeneous Computing) 两大类。
SHC以单机多处理器形式提供多种计算类型
NHC则以网络连接的多计算机形式提供多种计算类型
用于HPC的计算系统(如IBM RoadRunner等)属于NHC;当前热门的CUDA、OpenCL都属于SHC的范畴。
深度学习应用领域应用对异构并行计算领域很关注
二、聊聊CUDA
CUDA平台不是单单指软件或者硬件,而是建立在Nvidia GPU上的一整套平台,并扩展出多语言支持
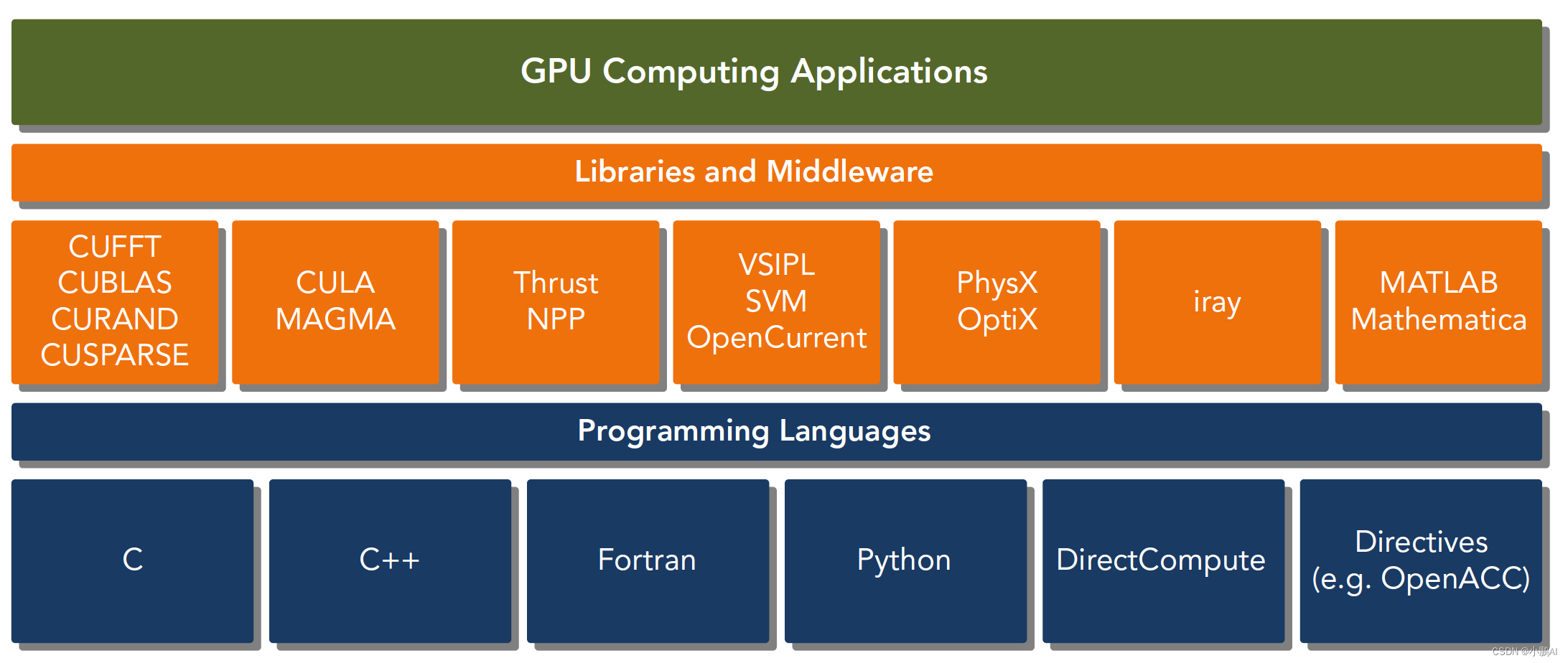
CUDA C 是标准ANSI C语言的扩展,扩展出一些语法和关键字来编写设备端代码,而且CUDA库本身提供了大量API来操作设备完成计算。
对于API也有两种不同的层次,一种相对底层,CUDA驱动API,一种相对交高层,CUDA运行时API
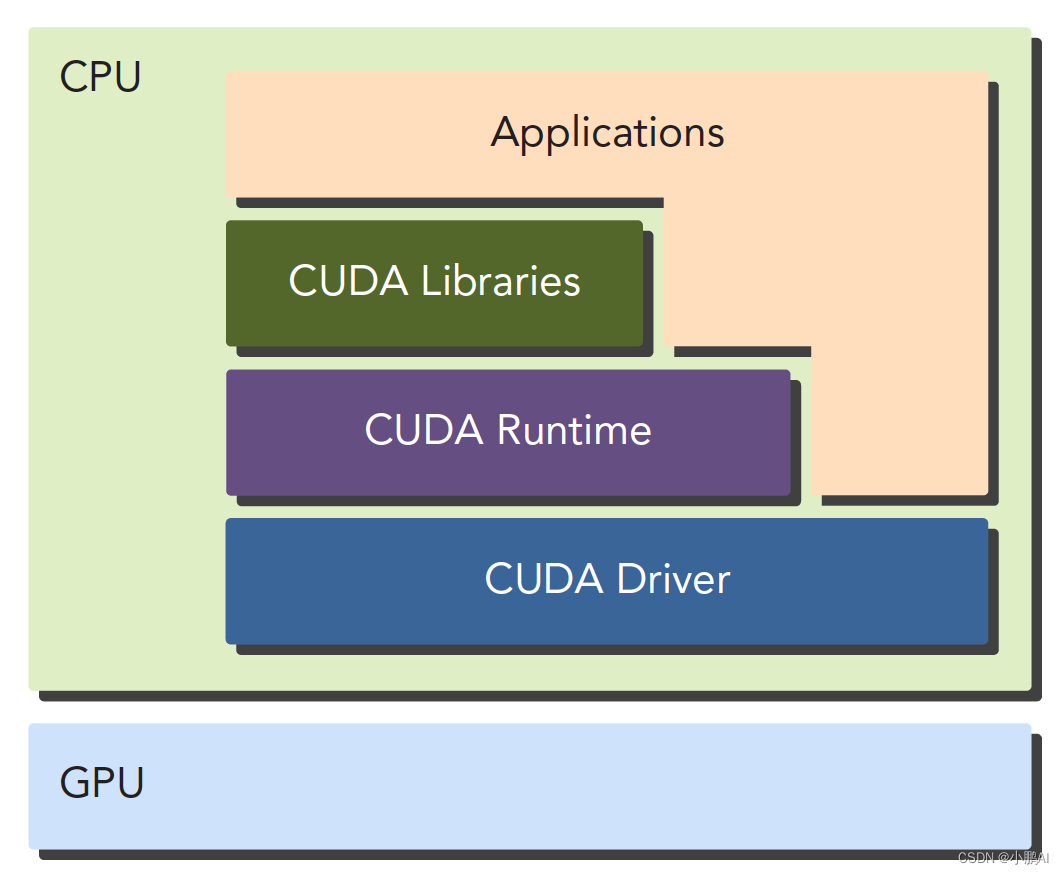
驱动API是低级的API,使用相对困难,运行时API是高级API使用简单,其实现基于驱动API。
两种API是互斥的,两者之间的函数不可以混合调用,只能用其中的一个库。
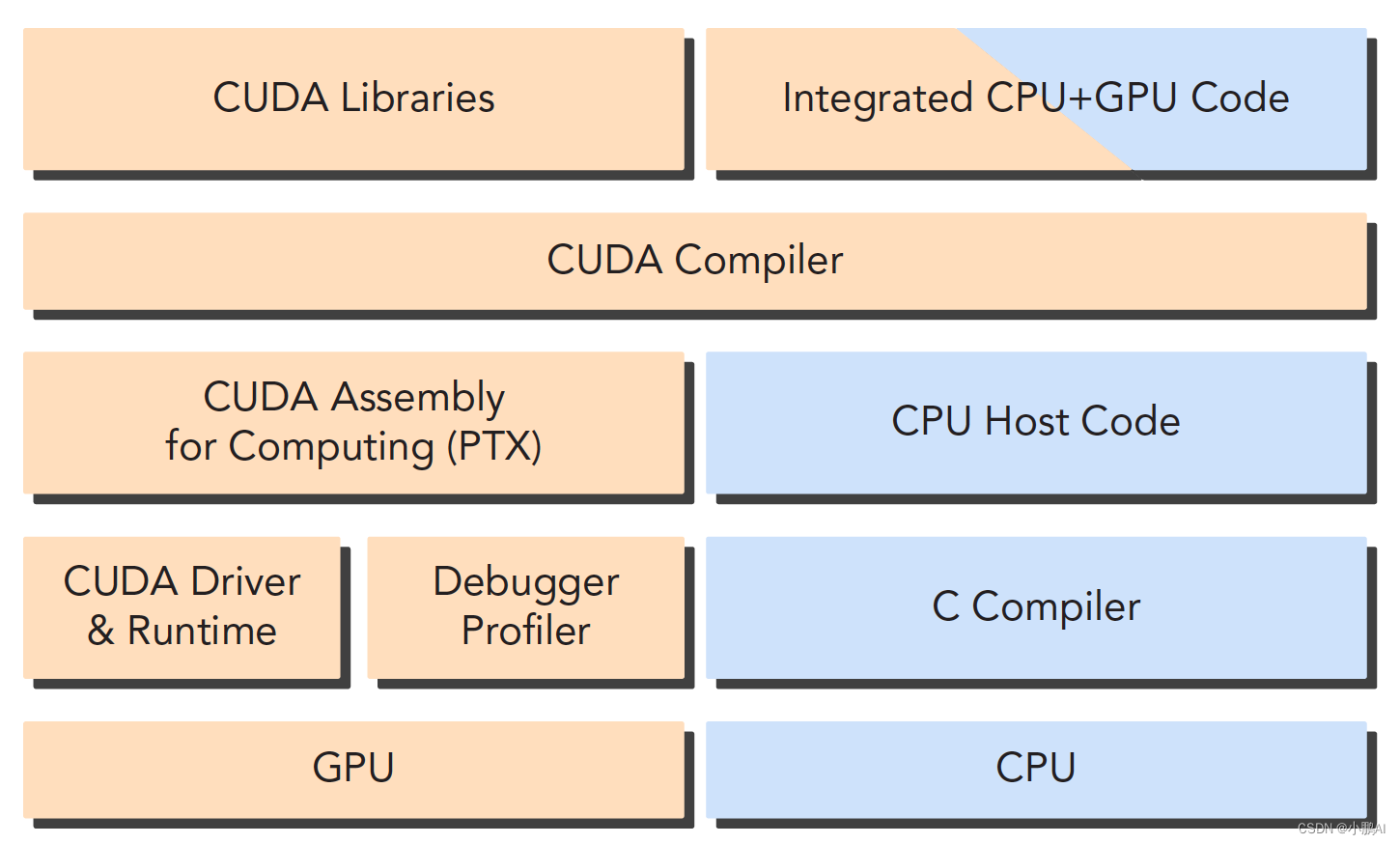
一个CUDA应用通常可以分解为两部分:CPU 主机端代码、GPU 设备端代码
CUDA nvcc编译器会自动分离你代码里面的不同部分
如下图中主机代码用C写成,使用本地的C语言编译器编译,设备端代码,也就是核函数
用CUDA C编写,通过nvcc编译,链接阶段,在内核程序调用或者明显的GPU设备操作时,添加运行时库。
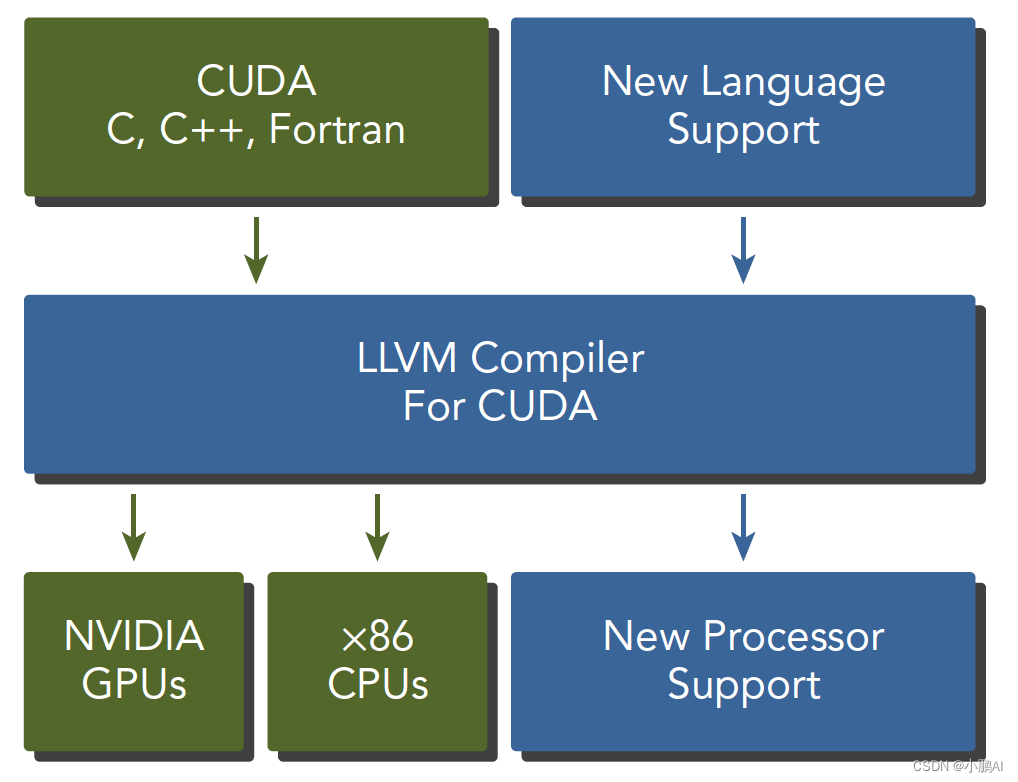
nvcc 是从LLVM开源编译系统为基础开发的。
使用cuda打印Hello World试一试
/*
*hello_world.cu
*/
#include<stdio.h>
__global__ void hello_world(void)
{
printf("GPU: Hello world!\n");
}
int main(int argc,char **argv)
{
printf("CPU: Hello world!\n");
hello_world<<<1,10>>>();
cudaDeviceReset();//if no this line ,it can not output hello world from gpu
return 0;
}
__global__:告诉编译器这个是个可以在设备上执行的核函数hello_world<<<1,10>>>();:C语言中没有’<<<>>>’是对设备进行配置的参数(CUDA扩展出来的部分)cudaDeviceReset();: 隐式同步:CPU等待GPU运行完成后,退出主线程
三、聊聊CUDA编程模型
CUDA是一种通用的并行计算平台和编程模型,是在C语言基础上扩展的。
CUDA编程模型假设系统是由一个主机(CPU)和一个设备(GPU)组成的,而且各自拥有独立的内存。
对于用户,需要做的就是编写运行在主机和设备上的代码,并且根据代码的需要为主机和设备分配内存空间以及拷贝数据。
运行在设备上的代码,我们一般称之为核函数(Kernel),核函数将会由大量硬件线程并行执行。
一个典型的CUDA程序是按这样的步骤执行的:
- 把数据从CPU内存拷贝到GPU内存。
- 调用核函数对存储在GPU内存中的数据进行操作的。
- 将数据从GPU内存传送回CPU内存。
CUDA编程模型有两个特色功能
(1)通过一种层次结构来组织线程
一般CPU一个核只支持一到两个硬件线程,而GPU往往在硬件层面上就支持同时成百上千个并发线程。
不过这也要求我们在GPU编程中更加高效地管理这些线程,以达到更高的运行效率。
在CUDA编程中,线程是通过线程网格(Grid)、线程块(Block)、线程束(Warp)、线程(Thread)这几个层次进行管理的
(2)通过层次结构来组织内存的访问
为了达到更高的效率,在CUDA编程中我们需要格外关注内存的使用。
与CPU编程不同,GPU中的各级缓存以及各种内存是可以软件控制的,在编程时我们可以手动指定变量存储的位置。
具体而言,这些内存包括寄存器、共享内存、常量内存、全局内存等。
这就造成了CUDA编程中有很多内存使用的小技巧,比如我们要尽量使用寄存器,尽量将数据声明为局部变量。
而当存在着数据的重复利用时,可以把数据存放在共享内存里。
而对于全局内存,我们需要注意用一种合理的方式来进行数据的合并访问,以尽量减少设备对内存子系统再次发出访问操作的次数。
CUDA的线程管理
首先我们需要了解线程是如何组织的,下面这幅图比较清晰地表示出了线程的组织结构。
当核函数在主机端启动时,其执行会移动到设备上,此时设备中会产生大量的线程并且每个线程都执行由核函数指定的语句。
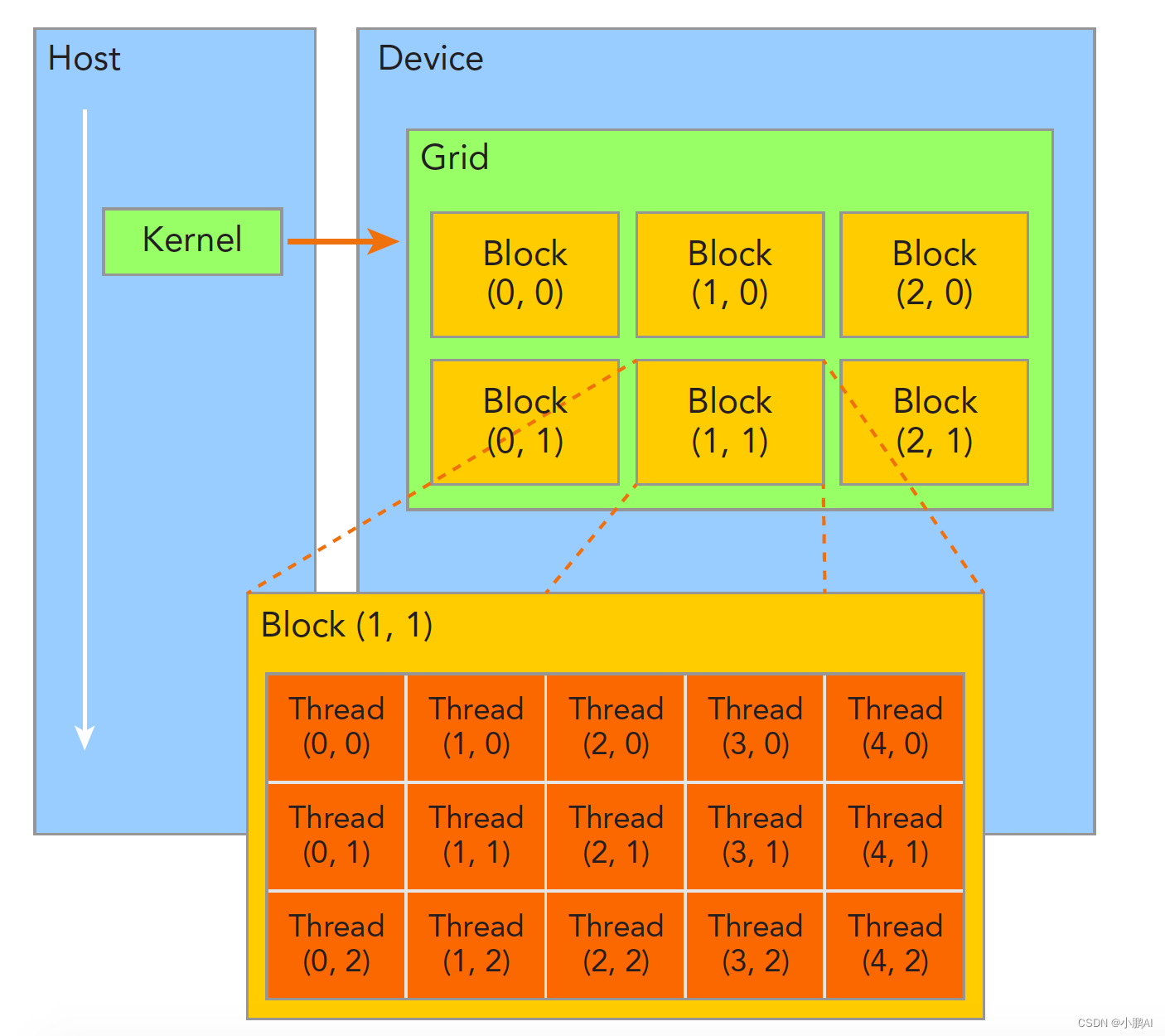
由一个内核启动所产生的所有线程统称一个网格(Grid),同一网格中的所有线程共享相同的全局内存空间。
向下一级,一个网格由多个线程块(Block)构成。
再下一级,一个线程块由一组线程(Thread)构成。
线程网格和线程块从逻辑上代表了一个核函数的线程层次结构,这种组织方式可以帮助我们有效地利用资源,优化性能。
CUDA编程中,我们可以组织三维的线程网格和线程块,具体如何组织,一般是和我们需要处理的数据有关。
上面这个示意图展示的是一个包含二维线程块的二维线程网格。
如果使用了合适的线程网格和线程块大小来正确地组织线程,内核的性能可以得到大大地提高。
通常给定一个需求,我们会有多种选择来实现核函数,并且我们会有多种不同的配置来执行该核函数。
而学习如何组织线程就是其中的重点之一,后面我们通过编程例子来学习具体如何合理组织。
下面有一段代码,块的索引和维度
/*
*1_check_dimension
*/
#include <cuda_runtime.h>
#include <stdio.h>
__global__ void checkIndex(void)
{
printf("threadIdx:(%d,%d,%d) blockIdx:(%d,%d,%d) blockDim:(%d,%d,%d)\
gridDim(%d,%d,%d)\n",threadIdx.x,threadIdx.y,threadIdx.z,
blockIdx.x,blockIdx.y,blockIdx.z,blockDim.x,blockDim.y,blockDim.z,
gridDim.x,gridDim.y,gridDim.z);
}
int main(int argc,char **argv)
{
int nElem=6;
dim3 block(3);
dim3 grid((nElem+block.x-1)/block.x);
printf("grid.x %d grid.y %d grid.z %d\n",grid.x,grid.y,grid.z);
printf("block.x %d block.y %d block.z %d\n",block.x,block.y,block.z);
checkIndex<<<grid,block>>>();
cudaDeviceReset();
return 0;
}
检查网格和块的大小
/*
*2_grid_block
*/
#include <cuda_runtime.h>
#include <stdio.h>
int main(int argc,char ** argv)
{
int nElem=1024;
dim3 block(1024);
dim3 grid((nElem-1)/block.x+1);
printf("grid.x %d block.x %d\n",grid.x,block.x);
block.x=512;
grid.x=(nElem-1)/block.x+1;
printf("grid.x %d block.x %d\n",grid.x,block.x);
block.x=256;
grid.x=(nElem-1)/block.x+1;
printf("grid.x %d block.x %d\n",grid.x,block.x);
block.x=128;
grid.x=(nElem-1)/block.x+1;
printf("grid.x %d block.x %d\n",grid.x,block.x);
cudaDeviceReset();
return 0;
}
CUDA的内存管理
CUDA编程另一个显著的特点就是解释了内存层次结构,每一个GPU设备都会有用于不同用途的存储类型。
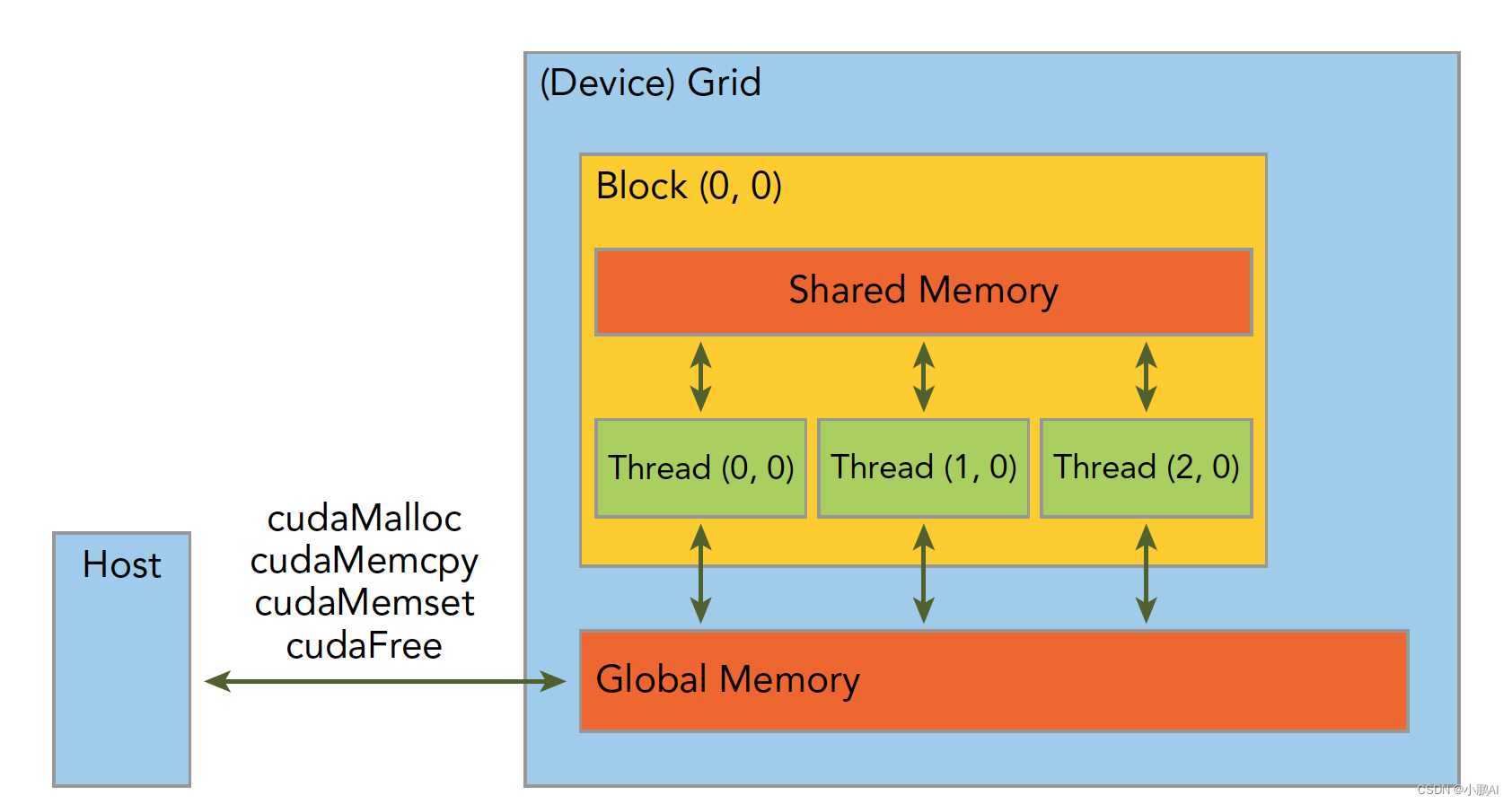
对于上图:我们只关注寄存器(Registers)、共享内存(Shared Memory)和全局内存(Global Memory)。
寄存器是GPU上运行速度最快的内存空间,通常其带宽为8TB/s左右,延迟为1个时钟周期。
核函数中声明的一个没有其他修饰符的自变量,通常就存储在寄存器中。
最快速也最受偏爱的存储器就是设备中的寄存器,属于具有重要价值有极度缺乏的资源。
共享内存是GPU上可受用户控制的一级缓存。
共享内存类似于CPU的缓存,不过与CPU的缓存不同,GPU的共享内存可以有CUDA内核直接编程控制。
由于共享内存是片上内存,所以与全局内存相比,它具有更高的带宽与更低的延迟,通常其带宽为1.5TB/s左右,延迟为1~32个时钟周期。
对于共享内存的使用,主要考虑数据的重用性。
当存在着数据的重复利用时,使用共享内存是比较合适的。
如果数据不被重用,则直接将数据从全局内存或常量内存读入寄存器即可。
全局内存是GPU中最大、延迟最高并且最常使用的内存。
全局内存类似于CPU的系统内存。在编程中对全局内存访问的优化以最大化程度提高全局内存的数据吞吐量是十分重要的。
这里我们来个例子,两个向量的加法
/*
* https://github.com/Tony-Tan/CUDA_Freshman
* 3_sum_arrays
*/
#include <cuda_runtime.h>
#include <stdio.h>
#include "freshman.h"
void sumArrays(float * a,float * b,float * res,const int size)
{
for(int i=0;i<size;i+=4)
{
res[i]=a[i]+b[i];
res[i+1]=a[i+1]+b[i+1];
res[i+2]=a[i+2]+b[i+2];
res[i+3]=a[i+3]+b[i+3];
}
}
__global__ void sumArraysGPU(float*a,float*b,float*res)
{
int i=threadIdx.x;
res[i]=a[i]+b[i];
}
int main(int argc,char **argv)
{
int dev = 0;
cudaSetDevice(dev);
int nElem=32;
printf("Vector size:%d\n",nElem);
int nByte=sizeof(float)*nElem;
float *a_h=(float*)malloc(nByte);
float *b_h=(float*)malloc(nByte);
float *res_h=(float*)malloc(nByte);
float *res_from_gpu_h=(float*)malloc(nByte);
memset(res_h,0,nByte);
memset(res_from_gpu_h,0,nByte);
float *a_d,*b_d,*res_d;
CHECK(cudaMalloc((float**)&a_d,nByte));
CHECK(cudaMalloc((float**)&b_d,nByte));
CHECK(cudaMalloc((float**)&res_d,nByte));
initialData(a_h,nElem);
initialData(b_h,nElem);
CHECK(cudaMemcpy(a_d,a_h,nByte,cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(b_d,b_h,nByte,cudaMemcpyHostToDevice));
dim3 block(nElem);
dim3 grid(nElem/block.x);
sumArraysGPU<<<grid,block>>>(a_d,b_d,res_d);
printf("Execution configuration<<<%d,%d>>>\n",block.x,grid.x);
CHECK(cudaMemcpy(res_from_gpu_h,res_d,nByte,cudaMemcpyDeviceToHost));
sumArrays(a_h,b_h,res_h,nElem);
checkResult(res_h,res_from_gpu_h,nElem);
cudaFree(a_d);
cudaFree(b_d);
cudaFree(res_d);
free(a_h);
free(b_h);
free(res_h);
free(res_from_gpu_h);
return 0;
}
使用CUDA核函数
核函数就是在CUDA模型上诸多线程中运行的那段串行代码,这段代码在设备上运行,用NVCC编译
产生的机器码是GPU的机器码,所以我们写CUDA程序就是写核函数
第一步我们要确保核函数能正确的运行产生正切的结果
第二步优化CUDA程序的部分,无论是优化算法,还是调整内存结构,线程结构都是要调整核函数内的代码,来完成这些优化的。
启动核函数,通过的以下的ANSI C 扩展出的CUDA C指令:
kernel_name<<<grid,block>>>(argument list);
其标准C的原型就是C语言函数调用
function_name(argument list);
通过指定grid和block的维度,我们可以配置:内核中线程的数目、内核中使用的线程布局
可以使用dim3类型的grid维度和block维度配置内核,也可以使用int类型的变量,或者常量直接初始化:
kernel_name<<<4,8>>>(argument list);
指令的线程布局是:

核函数是同时复制到多个线程执行的
多个计算执行在一个数据,肯定是浪费时间,所以为了让多线程按照我们的意愿对应到不同的数据,就要给线程一个唯一的标识
由于设备内存是线性的(基本市面上的内存硬件都是线性形式存储数据的)我们观察上图,可以用threadIdx.x 和blockIdx.x 来组合获得对应的线程的唯一标识
改变核函数的配置,产生运行出结果一样,但效率不同的代码:
kernel_name<<<1,32>>>(argument list); // 一个块
kernel_name<<<32,1>>>(argument list); // 32个块
上述代码如果没有特殊结构在核函数中,执行结果应该一致,但是有些效率会一直比较低。
上面这些是启动部分,当主机启动了核函数,控制权马上回到主机,而不是主机等待设备完成核函数的运行
想要主机等待设备端执行可以用下面这个指令:
cudaError_t cudaDeviceSynchronize(void);
这是一个显示的方法,对应的也有隐式方法,隐式方法就是不明确
说明主机要等待设备端,而是设备端不执行完,主机没办法进行,比如内存拷贝函数:
cudaError_t cudaMemcpy(void* dst,const void * src, size_t count,cudaMemcpyKind kind);
当核函数启动后的下一条指令就是从设备复制数据回主机端,那么主机端必须要等待设备端计算完成。
编写CUDA核函数
核函数也是一个函数,但是声明核函数有一个比较模板化的方法
__global__ void kernel_name(argument list);
注意:声明和定义是不同的,这点CUDA与C语言是一致的
在C语言函数前没有的限定符global ,CUDA C中还有一些其他我们在C中没有的限定符,如下:
- global:设备端执行,可以从主机调用也可以从计算能力3以上的设备调用,必须有一个void的返回类型
- device: 设备端执行, 设备端调用
- host: 主机端执行,主机调用,可以省略
这里有个特殊的情况就是有些函数可以同时定义为 device 和 host
这种函数可以同时被设备和主机端的代码调用,主机端代码调用函数很正常
设备端调用函数与C语言一致,但是要声明成设备端代码,告诉nvcc编译成设备机器码,
同时声明主机端设备端函数,那么就要告诉编译器,生成两份不同设备的机器码。
Kernel核函数编写有以下限制
- 只能访问设备内存
- 必须有void返回类型
- 不支持可变数量的参数
- 不支持静态变量
- 显示异步行为
并行程序中经常的一种现象:把串行代码并行化时对串行代码块for的操作,也就是把for并行化。
// 串行
void sumArraysOnHost(float *A, float *B, float *C, const int N) {
for (int i = 0; i < N; i++)
C[i] = A[i] + B[i];
}
//并行
__global__ void sumArraysOnGPU(float *A, float *B, float *C) {
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
验证CUDA核函数
验证核函数就是验证其正确性,下面这段代码上文出现过,但是同样包含验证核函数的方法:
/*
* https://github.com/Tony-Tan/CUDA_Freshman
* 3_sum_arrays
*/
#include <cuda_runtime.h>
#include <stdio.h>
#include "freshman.h"
void sumArrays(float * a,float * b,float * res,const int size)
{
for(int i=0;i<size;i+=4)
{
res[i]=a[i]+b[i];
res[i+1]=a[i+1]+b[i+1];
res[i+2]=a[i+2]+b[i+2];
res[i+3]=a[i+3]+b[i+3];
}
}
__global__ void sumArraysGPU(float*a,float*b,float*res)
{
int i=threadIdx.x;
res[i]=a[i]+b[i];
}
int main(int argc,char **argv)
{
int dev = 0;
cudaSetDevice(dev);
int nElem=32;
printf("Vector size:%d\n",nElem);
int nByte=sizeof(float)*nElem;
float *a_h=(float*)malloc(nByte);
float *b_h=(float*)malloc(nByte);
float *res_h=(float*)malloc(nByte);
float *res_from_gpu_h=(float*)malloc(nByte);
memset(res_h,0,nByte);
memset(res_from_gpu_h,0,nByte);
float *a_d,*b_d,*res_d;
CHECK(cudaMalloc((float**)&a_d,nByte));
CHECK(cudaMalloc((float**)&b_d,nByte));
CHECK(cudaMalloc((float**)&res_d,nByte));
initialData(a_h,nElem);
initialData(b_h,nElem);
CHECK(cudaMemcpy(a_d,a_h,nByte,cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(b_d,b_h,nByte,cudaMemcpyHostToDevice));
dim3 block(nElem);
dim3 grid(nElem/block.x);
sumArraysGPU<<<grid,block>>>(a_d,b_d,res_d);
printf("Execution configuration<<<%d,%d>>>\n",block.x,grid.x);
CHECK(cudaMemcpy(res_from_gpu_h,res_d,nByte,cudaMemcpyDeviceToHost));
sumArrays(a_h,b_h,res_h,nElem);
checkResult(res_h,res_from_gpu_h,nElem);
cudaFree(a_d);
cudaFree(b_d);
cudaFree(res_d);
free(a_h);
free(b_h);
free(res_h);
free(res_from_gpu_h);
return 0;
}
CUDA错误处理
获得每个函数执行后的返回结果,然后对不成功的信息加以处理,CUDA C 的API每个调用都会返回一个错误代码
#define CHECK(call)\
{\
const cudaError_t error=call;\
if(error!=cudaSuccess)\
{\
printf("ERROR: %s:%d,",__FILE__,__LINE__);\
printf("code:%d,reason:%s\n",error,cudaGetErrorString(error));\
exit(1);\
}\
}
CUDA编译执行
nvcc xxxx.cu -o xxxx
参考文献
- 《Professional CUDA C Programming》John Cheng
- https://www.cnblogs.com/ldxsuanfa/p/9913830.html
- https://zhuanlan.zhihu.com/p/97044592
- https://face2ai.com/








![[附源码]计算机毕业设计JAVAjsp心理测评系统](https://img-blog.csdnimg.cn/cb033dfc706b44f6954173a3b53694e2.png)