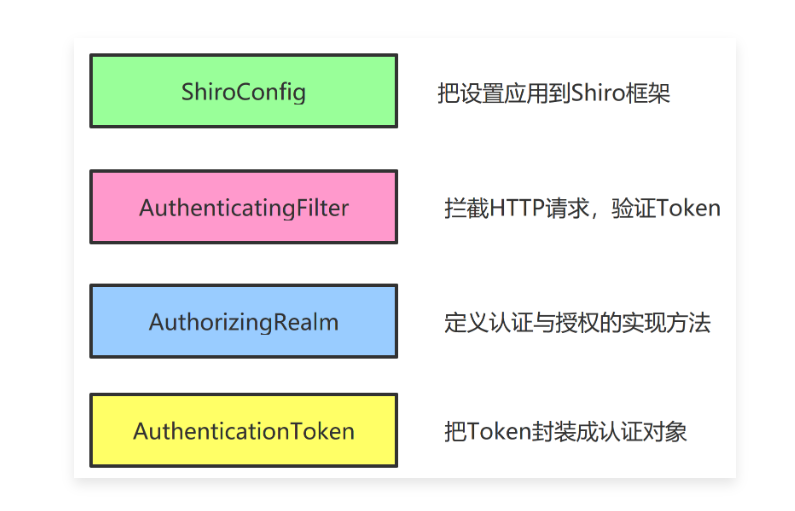
目录:导读
- 前言
- 一、Python编程入门到精通
- 二、接口自动化项目实战
- 三、Web自动化项目实战
- 四、App自动化项目实战
- 五、一线大厂简历
- 六、测试开发DevOps体系
- 七、常用自动化测试工具
- 八、JMeter性能测试
- 九、总结(尾部小惊喜)
前言
自动化测试:https://www.bilibili.com/video/BV1MS4y1W79K/
测试用例设计的基本原则包括:有效性、清晰性、可复用性、可维护性、完整性、兼容性、易操作性、可管理性、可评估性。
有效性
测试用例步骤必须描述清晰,不能出现模棱两可的以及重复的话语,测试用例应该按照一定的顺序进行编写,这样执行的时候效率比较高。
清晰性
用例的操作步骤要描述清晰,包含清晰的输入数据以及预期输出,验证点必须明确清晰,并能突出重点,对于流程性的用例建议按照流程顺序进行用例安排,从第一个验证点到最后一个验证点,组成流程的开始到结束,方便测试执行。测试用例包含前置条件的必须将前置条件描述清楚,包括入口等。
可复用性
可重复使用,并尽量将具有相似功能的测试用例抽象并归类。
…
测试用例编写要素:
用例编号:用例的唯一标识
测试模块:测试用例所属模块
用例标题:测试用例的简要说明
前提条件:用例执行的前提
测试步骤:执行用例步骤
预期结果:应该得到的结果
优先级:用例重要程度
XMind 和 Excel 是在日常测试工作中最常用的两种用例编写形式,两者也有各自的优缺点。
使用 XMind 编写测试用例更有利于测试思路的梳理,以及更加便捷高效,用例评审效率更高,但是由于每个人使用 XMind 的方式不同,设计思路也不一样,可能就不便于其他人执行和维护。
使用 Excel 编写测试用例由于有固定的模板,所以可能更加形式化和规范化,更利于用例管理和维护,以及让其他人更容易执行用例,但是最大的缺点就是需要花费更多的时间成本。
Python 编写实现 XMind 测试用例转 Excel 用例。
设计思路
Excel 测试用例模板样式如下图所示:

表头固定字段:序号、模块、功能点
为了让脚本更加灵活,后面的字段会根据 XMind 中每一个分支的长度自增,例如:测试点 / 用例标题、预期结果、实际结果、前置条件、操作步骤、优先级、编写人、执行人等
根据 Excel 模板编写对应的 XMind 测试用例:

实现:
将 XMind 中的每一条分支作为一条序号的用例,再将每个字段写入 Excel 中的每一个单元格中

修改一下表格:

完整代码
from typing import List, Any
import xlwt
from xmindparser import xmind_to_dict
def resolve_path(dict_, lists, title):
"""
通过递归取出每个主分支下的所有小分支并将其作为一个列表
:param dict_:
:param lists:
:param title:
:return:
"""
# 去除title首尾空格
title = title.strip()
# 若title为空,则直接取value
if len(title) == 0:
concat_title = dict_["title"].strip()
else:
concat_title = title + "\t" + dict_["title"].strip()
if not dict_.__contains__("topics"):
lists.append(concat_title)
else:
for d in dict_["topics"]:
resolve_path(d, lists, concat_title)
def xmind_to_excel(list_, excel_path):
f = xlwt.Workbook()
# 生成单sheet的Excel文件,sheet名自取
sheet = f.add_sheet("XX模块", cell_overwrite_ok=True)
# 第一行固定的表头标题
row_header = ["序号", "模块", "功能点"]
for i in range(0, len(row_header)):
sheet.write(0, i, row_header[i])
# 增量索引
index = 0
for h in range(0, len(list_)):
lists: List[Any] = []
resolve_path(list_[h], lists, "")
# print(lists)
# print('\n'.join(lists)) # 主分支下的小分支
for j in range(0, len(lists)):
# 将主分支下的小分支构成列表
lists[j] = lists[j].split('\t')
# print(lists[j])
for n in range(0, len(lists[j])):
# 生成第一列的序号
sheet.write(j + index + 1, 0, j + index + 1)
sheet.write(j + index + 1, n + 1, lists[j][n])
# 自定义内容,比如:测试点/用例标题、预期结果、实际结果、操作步骤、优先级……
# 这里为了更加灵活,除序号、模块、功能点的标题固定,其余以【自定义+序号】命名,如:自定义1,需生成Excel表格后手动修改
if n >= 2:
sheet.write(0, n + 1, "自定义" + str(n - 1))
# 遍历完lists并给增量索引赋值,跳出for j循环,开始for h循环
if j == len(lists) - 1:
index += len(lists)
f.save(excel_path)
def run(xmind_path):
# 将XMind转化成字典
xmind_dict = xmind_to_dict(xmind_path)
# print("将XMind中所有内容提取出来并转换成列表:", xmind_dict)
# Excel文件与XMind文件保存在同一目录下
excel_name = xmind_path.split('\\')[-1].split(".")[0] + '.xlsx'
excel_path = "\\".join(xmind_path.split('\\')[:-1]) + "\\" + excel_name
print(excel_path)
# print("通过切片得到所有分支的内容:", xmind_dict[0]['topic']['topics'])
xmind_to_excel(xmind_dict[0]['topic']['topics'], excel_path)
if __name__ == '__main__':
xmind_path_ = r"F:\Desktop\coder\python_operate_files\用例模板.xmind"
run(xmind_path_)
代码解析
1.调用 xmind_to_dict () 方法将 XMind 中所有内容取出并转成字典
xmind_dict = xmind_to_dict(xmind_path)
[{'title': '画布 1', 'topic': {'title': '需求名称', 'topics': [{'title': '模块', 'topics': [{'title': '功能点1', 'topics': [{'title': '测试点1', 'topics': [{'title': '预期结果', 'topics': [{'title': '实际结果'}]}]}, {'title': '测试点2', 'topics': [{'title': '预期结果', 'topics': [{'title': '实际结果'}]}]}, {'title': '测试点3'}]}, {'title': '功能点2', 'topics': [{'title': '测试点1'}, {'title': '测试点2', 'topics': [{'title': '预期结果', 'topics': [{'title': '实际结果'}]}]}]}, {'title': '功能点3'}]}]}, 'structure': 'org.xmind.ui.logic.right'}]
2.通过切片得到所有分支的内容
xmind_dict[0]['topic']['topics']
[{'title': '模块', 'topics': [{'title': '功能点1', 'topics': [{'title': '测试点1', 'topics': [{'title': '预期结果', 'topics': [{'title': '实际结果'}]}]}, {'title': '测试点2', 'topics': [{'title': '预期结果', 'topics': [{'title': '实际结果'}]}]}, {'title': '测试点3'}]}, {'title': '功能点2', 'topics': [{'title': '测试点1'}, {'title': '测试点2', 'topics': [{'title': '预期结果', 'topics': [{'title': '实际结果'}]}]}]}, {'title': '功能点3'}]}]
3.通过递归取出每个主分支下的所有小分支并将其作为一个列表
def resolve_path(dict_, lists, title):
"""
通过递归取出每个主分支下的所有小分支并将其作为一个列表
:param dict_:
:param lists:
:param title:
:return:
"""
# 去除title首尾空格
title = title.strip()
# 若title为空,则直接取value
if len(title) == 0:
concat_title = dict_["title"].strip()
else:
concat_title = title + "\t" + dict_["title"].strip()
if not dict_.__contains__("topics"):
lists.append(concat_title)
else:
for d in dict_["topics"]:
resolve_path(d, lists, concat_title)
for h in range(0, len(list_)):
lists: List[Any] = []
resolve_path(list_[h], lists, "")
print(lists)
print('\n'.join(lists)) # 主分支下的小分支
for j in range(0, len(lists)):
# 将主分支下的小分支构成列表
lists[j] = lists[j].split('\t')
print(lists[j])
lists:
[‘模块\t功能点1\t测试点1\t预期结果\t实际结果’, ‘模块\t功能点1\t测试点2\t预期结果\t实际结果’, ‘模块\t功能点1\t测试点3’, ‘模块\t功能点2\t测试点1’, ‘模块\t功能点2\t测试点2\t预期结果\t实际结果’, ‘模块\t功能点3’]
主分支下的小分支:
模块 功能点1 测试点1 预期结果 实际结果
模块 功能点1 测试点2 预期结果 实际结果
模块 功能点1 测试点3
模块 功能点2 测试点1
模块 功能点2 测试点2 预期结果 实际结果
模块 功能点3
将主分支下的小分支构成列表:
['模块', '功能点1', '测试点1', '预期结果', '实际结果']
['模块', '功能点1', '测试点2', '预期结果', '实际结果']
['模块', '功能点1', '测试点3']
['模块', '功能点2', '测试点1']
['模块', '功能点2', '测试点2', '预期结果', '实际结果']
['模块', '功能点3']
- 写入 Excel(生成单 sheet 的 Excel 文件、生成固定的表头标题、列序号取值、固定标题外的自定义标题)
f = xlwt.Workbook()
# 生成单sheet的Excel文件,sheet名自取
sheet = f.add_sheet("签署模块", cell_overwrite_ok=True)
# 第一行固定的表头标题
row_header = ["序号", "模块", "功能点"]
for i in range(0, len(row_header)):
sheet.write(0, i, row_header[i])
sheet.write(j + index + 1, n + 1, lists[j][n])
for n in range(0, len(lists[j])):
# 生成第一列的序号
sheet.write(j + index + 1, 0, j + index + 1)
# 自定义内容,比如:测试点/用例标题、预期结果、实际结果、操作步骤、优先级……
# 这里为了更加灵活,除序号、模块、功能点的标题固定,其余以【自定义+序号】命名,如:自定义1,需生成Excel表格后手动修改
if n >= 2:
sheet.write(0, n + 1, "自定义" + str(n - 1))
| 下面是我整理的2023年最全的软件测试工程师学习知识架构体系图 |
一、Python编程入门到精通

二、接口自动化项目实战

三、Web自动化项目实战

四、App自动化项目实战

五、一线大厂简历

六、测试开发DevOps体系

七、常用自动化测试工具

八、JMeter性能测试
九、总结(尾部小惊喜)
不管你现在身处何方,只要拥有向上的心,就能朝着目标奋斗不止。不要怕困难,勇敢面对挑战,把握机会,坚持努力,成功就会向你招手!
每一次的挫败都是成长的催化剂,每一份付出都会换来收获的喜悦。让梦想引领你的脚步,用行动诠释坚持,用努力迎接挑战,成功必将不期而至!
勇敢地面对未知的挑战,不断探索自己的潜能,无论前路多么艰辛,都要坚定走下去。有梦想就有实现的可能,因为你的努力,所以你的未来!