论文解读者:陈宇文,胡明杰,史铭伟,赵田田
许多实际问题都可以建模为凸优化问题。相比于直接求解原问题,将问题转化为鞍点问题往往会带来好处。求解鞍点问题的一种常用算法是原对偶混合梯度算法 (PDHG),它在各类问题问题当中均得到了广泛应用。然而,实际应用中遇到的大规模问题会面临较高的计算成本。本文[1]针对对偶变量可分离的鞍点问题提出了PDHG的随机扩展 (SPDHG)。在迭代过程中,可以通过不断积累来自以前迭代的信息来减小方差,进而减少随机性的负面影响。本文分析了一般的凸凹鞍点问题 (convex-concave saddle point problems) 和部分光滑/强凸或完全光滑/强凸问题。本文对任意采样 (arbitrary samplings) 的对偶变量进行分析,并获得已知的确定性结果作为特殊情况。在实验中,本文的多种随机方法在各种成像任务上显著优于确定性变体。
第一部分:问题模型和PDHG算法
1.1 问题形式
设
X
\mathbb{X}
X和
Y
i
(
i
=
1
,
…
,
n
)
\mathbb{Y}_i ~(i=1, \ldots, n)
Yi (i=1,…,n)是实希尔伯特空间,并定义
Y
:
=
∏
i
=
1
n
Y
i
\mathbb{Y}:=\prod_{i=1}^n \mathbb{Y}_i
Y:=∏i=1nYi。此时我们可以根据
Y
i
\mathbb{Y}_i
Yi的维数,将
y
∈
Y
y\in\mathbb{Y}
y∈Y对应写作
y
=
(
y
1
,
y
2
,
…
,
y
n
)
y=\left(y_1, y_2, \ldots, y_n\right)
y=(y1,y2,…,yn)。设
f
:
Y
→
R
∞
:
=
R
∪
{
+
∞
}
f: \mathbb{Y} \rightarrow \mathbb{R}_{\infty}:=\mathbb{R} \cup\{+\infty\}
f:Y→R∞:=R∪{+∞}和
g
:
X
→
R
∞
g: \mathbb{X} \rightarrow \mathbb{R}_{\infty}
g:X→R∞是凸函数,且
f
f
f是可分的,可写作
f
(
y
)
=
∑
i
=
1
n
f
i
(
y
i
)
f(y)=\sum_{i=1}^n f_i\left(y_i\right)
f(y)=∑i=1nfi(yi)。设
A
:
X
→
Y
\mathbf{A}: \mathbb{X} \rightarrow \mathbb{Y}
A:X→Y是有界线性算子,
A
x
=
(
A
1
x
,
⋯
,
A
n
x
)
\mathbf{A} x=(\mathbf{A}_1 x,\cdots,\mathbf{A}_n x)
Ax=(A1x,⋯,Anx)。问题可写为
min
x
∈
X
{
Φ
(
x
)
:
=
∑
i
=
1
n
f
i
(
A
i
x
)
+
g
(
x
)
}
.
\min _{x \in \mathbb{X}}\left\{\Phi(x):=\sum_{i=1}^n f_i\left(\mathbf{A}_i x\right)+g(x)\right\}.
x∈Xmin{Φ(x):=i=1∑nfi(Aix)+g(x)}.
如果
f
f
f满足适当的条件,则它相当于求解鞍点问题
min
x
∈
X
sup
y
∈
Y
{
Ψ
(
x
,
y
)
:
=
∑
i
=
1
n
⟨
A
i
x
,
y
i
⟩
−
f
i
∗
(
y
i
)
+
g
(
x
)
}
,
\min _{x \in \mathbb{X}}\sup _{y \in \mathbb{Y}}\left\{\Psi(x, y):=\sum_{i=1}^n\left\langle\mathbf{A}_i x, y_i\right\rangle-f_i^*\left(y_i\right)+g(x)\right\},
x∈Xminy∈Ysup{Ψ(x,y):=i=1∑n⟨Aix,yi⟩−fi∗(yi)+g(x)},
其中
f
i
∗
f_i^*
fi∗是
f
i
f_i
fi的Fenchel共轭函数,而
f
∗
(
y
)
=
∑
i
=
1
n
f
i
∗
(
y
i
)
f^*(y)=\sum_{i=1}^n f_i^*\left(y_i\right)
f∗(y)=∑i=1nfi∗(yi)是
f
f
f的共轭函数。设
W
:
=
X
×
Y
\mathbb{W}:=\mathbb{X} \times \mathbb{Y}
W:=X×Y,我们假设上述问题有最优解$w^{\sharp}\in\mathbb{W}
,并将其写作
,并将其写作
,并将其写作w{\sharp}=\left(x{\sharp}, y{\sharp}\right)=\left(x{\sharp}, y_1^{\sharp}, \ldots, y_n{\sharp}\right)$。鞍点$w{\sharp}$满足最优性条件
A
i
x
♯
∈
∂
f
i
∗
(
y
i
♯
)
,
i
=
1
,
…
,
n
,
−
A
∗
y
♯
∈
∂
g
(
x
♯
)
.
\mathbf{A}_i x^{\sharp} \in \partial f_i^*\left(y_i^{\sharp}\right), \quad i=1, \ldots, n, \quad-\mathbf{A}^* y^{\sharp} \in \partial g\left(x^{\sharp}\right).
Aix♯∈∂fi∗(yi♯),i=1,…,n,−A∗y♯∈∂g(x♯).
1.2 PDHG算法
对于正常数
τ
\tau
τ,可定义
W
\mathbb{W}
W上的带权范数
∥
x
∥
τ
−
1
2
=
⟨
τ
−
1
x
,
x
⟩
\|x\|_{\tau^{-1}}^2=\left\langle\tau^{-1} x, x\right\rangle
∥x∥τ−12=⟨τ−1x,x⟩。由此可给出邻近点算子的定义
prox
f
τ
(
y
)
:
=
arg
min
x
∈
X
{
1
2
∥
x
−
y
∥
τ
−
1
2
+
f
(
x
)
}
\operatorname{prox}_f^\tau(y):=\arg \min _{x \in \mathbb{X}}\left\{\frac{1}{2}\|x-y\|_{\tau^{-1}}^2+f(x)\right\}
proxfτ(y):=argx∈Xmin{21∥x−y∥τ−12+f(x)}
类似地,我们可将
τ
\tau
τ换成对称正定的矩阵。则PDHG算法可写作
x
(
k
+
1
)
=
prox
g
T
(
x
(
k
)
−
T
A
∗
y
ˉ
(
k
)
)
,
y
i
(
k
+
1
)
=
prox
f
i
∗
S
i
(
y
i
(
k
)
+
S
i
A
i
x
(
k
+
1
)
)
,
i
=
1
,
…
,
n
,
y
ˉ
(
k
+
1
)
=
y
(
k
+
1
)
+
θ
(
y
(
k
+
1
)
−
y
(
k
)
)
,
\begin{aligned} & x^{(k+1)}=\operatorname{prox}_g^{\mathbf{T}}\left(x^{(k)}-\mathbf{T A}^* \bar{y}^{(k)}\right), \\ & y_i^{(k+1)}=\operatorname{prox}_{f_i^*}^{\mathbf{S}_i}\left(y_i^{(k)}+\mathbf{S}_i \mathbf{A}_i x^{(k+1)}\right), \quad i=1, \ldots, n, \\ & \bar{y}^{(k+1)}=y^{(k+1)}+\theta\left(y^{(k+1)}-y^{(k)}\right) , \end{aligned}
x(k+1)=proxgT(x(k)−TA∗yˉ(k)),yi(k+1)=proxfi∗Si(yi(k)+SiAix(k+1)),i=1,…,n,yˉ(k+1)=y(k+1)+θ(y(k+1)−y(k)),
其中 S = diag ( S 1 , … , S n ) \mathbf{S}=\operatorname{diag}\left(\mathbf{S}_1, \ldots, \mathbf{S}_n\right) S=diag(S1,…,Sn), S 1 , … , S n \mathbf{S}_1, \ldots, \mathbf{S}_n S1,…,Sn和 T \mathbf{T} T都是对称正定的矩阵。
第二部分:Stochastic PDHG
2.1 随机PDHG算法
在PDHG算法中,每一次迭代都需要更新所有
y
i
(
i
=
1
,
⋯
,
n
)
y_i (i=1,\cdots,n)
yi(i=1,⋯,n)的值。我们现在考虑每次抽取
{
1
,
⋯
,
n
}
\{1,\cdots,n\}
{1,⋯,n}的一个子集
S
\mathbb{S}
S,然后只更新满足
i
∈
S
i\in\mathbb{S}
i∈S的
y
i
y_i
yi。其中
S
\mathbb{S}
S的选取满足:对于每次迭代,任意的指标
i
i
i都以
p
i
>
0
p_i>0
pi>0的概率被包含在
S
\mathbb{S}
S中(这样的条件不难满足,常见的选取方式包括:全采样,即
S
\mathbb{S}
S以1的概率取到
{
1
,
⋯
,
n
}
\{1,\cdots,n\}
{1,⋯,n}; 连续采样,即
S
\mathbb{S}
S以
p
i
p_i
pi的概率取到
{
i
}
\{i\}
{i})。设
Q
:
=
diag
(
p
1
−
1
I
,
…
,
p
n
−
1
I
)
\mathbf{Q}:=\operatorname{diag}\left(p_1^{-1} \mathbf{I}, \ldots, p_n^{-1} \mathbf{I}\right)
Q:=diag(p1−1I,…,pn−1I),则随机PDHG算法可写作

可以看出,SPDHG与PDHG的不同点在于 y i k + 1 , y ˉ k + 1 y_i^{k+1}, \bar{y}^{k+1} yik+1,yˉk+1的更新。SPDHG采用降采样对部分 y i k + 1 y_i^{k+1} yik+1进行更新,同时 y ˉ k + 1 \bar{y}^{k+1} yˉk+1的更新需要乘上新的系数矩阵 Q \mathbf{Q} Q。
2.2 ESO条件
在随机PDHG算法的收敛性分析中,经常用到ESO条件。
S
\mathbb{S}
S和
p
i
(
i
=
1
,
⋯
,
n
)
p_i (i=1,\cdots,n)
pi(i=1,⋯,n)如上文定义。设
C
:
X
→
Y
\mathbf{C}: \mathbb{X} \rightarrow \mathbb{Y}
C:X→Y是有界线性算子,
C
x
=
(
C
1
x
,
⋯
,
C
n
x
)
\mathbf{C} x=(\mathbf{C}_1 x,\cdots,\mathbf{C}_n x)
Cx=(C1x,⋯,Cnx)。我们说
{
v
i
}
⊂
R
n
\left\{v_i\right\} \subset \mathbb{R}^n
{vi}⊂Rn满足ESO条件,当且仅当对任意
z
∈
Y
z \in \mathbb{Y}
z∈Y有
E
S
∥
∑
i
∈
S
C
i
∗
z
i
∥
2
≤
∑
i
=
1
n
p
i
v
i
∥
z
i
∥
2
.
\mathbb{E}_{\mathbb{S}}\left\|\sum_{i \in \mathbb{S}} \mathbf{C}_i^* z_i\right\|^2 \leq \sum_{i=1}^n p_i v_i\left\|z_i\right\|^2.
ES
i∈S∑Ci∗zi
2≤i=1∑npivi∥zi∥2.
这样的条件也不难满足。对于全采样,我们可取 C i = S i 1 / 2 A i T 1 / 2 \mathbf{C}_i=\mathbf{S}_i^{1 / 2} \mathbf{A}_i \mathbf{T}^{1 / 2} Ci=Si1/2AiT1/2和 v i = ∥ C ∥ 2 v_i=\|\mathbf{C}\|^2 vi=∥C∥2;对于连续采样,我们可以取相同的 C i \mathbf{C}_i Ci以及 v i = ∥ C i ∥ 2 v_i=\left\|\mathbf{C}_i\right\|^2 vi=∥Ci∥2。
2.3 收敛速度
在考虑SPDHG收敛性之前,我们首先简单介绍一下Bregman距离 D h ( w , v ) D_h(w, v) Dh(w,v)和对偶间隙 G ( x , y ) G(x,y) G(x,y)(duality gap)。
1)Bregman距离 D h ( w , v ) D_h(w, v) Dh(w,v)的作用与范数 (norm) 类似:
D h ( w , v ) : = h ( w ) − h ( v ) − ⟨ ∇ h ( v ) , w − v ⟩ . \begin{equation}D_h(w,v) := h(w)-h(v)-\langle \nabla h(v), w-v \rangle. \end{equation} Dh(w,v):=h(w)−h(v)−⟨∇h(v),w−v⟩.
如果选取 h ( w ) = ∥ w ∥ 2 h(w) = \|w\|^2 h(w)=∥w∥2,那么此时有 D h ( w , v ) = ∥ w − v ∥ 2 D_h(w,v)=\|w-v\|^2 Dh(w,v)=∥w−v∥2,也就是2-范数。其中,对于本文的minimax问题,作者定义 w : = ( x , y ) w := (x,y) w:=(x,y),并选取 h ( w ) : = g ( x ) + ∑ i = 1 n f ∗ ( y i ) h(w):= g(x) + \sum_{i=1}^n f^*(y_i) h(w):=g(x)+∑i=1nf∗(yi)。
2)与此同时,对偶间隙 G ( x , y ) G(x,y) G(x,y)通常可用来进行收敛性分析,定义如下
G B 1 × B 2 ( x , y ) : = sup y ~ ∈ B 2 Ψ ( x , y ~ ) − inf x ~ ∈ B 1 Ψ ( x ~ , y ) . \begin{equation} G_{\mathbb{B}_1 \times \mathbb{B}_2}(x, y):=\sup _{\tilde{y} \in \mathbb{B}_2} \Psi(x, \tilde{y})-\inf _{\tilde{x} \in \mathbb{B}_1} \Psi(\tilde{x}, y). \end{equation} GB1×B2(x,y):=y~∈B2supΨ(x,y~)−x~∈B1infΨ(x~,y).
minmax问题最优解 ( x ∗ , y ∗ ) (x^*,y^*) (x∗,y∗)满足对偶间隙 G ( x ∗ , y ∗ ) = 0 G(x^*,y^*) = 0 G(x∗,y∗)=0。
对于收敛速度,文章中考虑了对应一般凸 (convex),半强凸 (semi-strongly convex) 和强凸 (strongly convex) 三类情况下Bregman距离 D h ( w k , w ∗ ) D_h(w^k, w^*) Dh(wk,w∗)与对偶间隙 G ( w ) G(w) G(w)的收敛速度。
一般凸问题
此时Bregman距离 D h ( w k , w ∗ ) D_h(w^k, w^*) Dh(wk,w∗)与对偶间隙 G ( w ) G(w) G(w)的收敛速度为 O ( 1 K ) O\left(\frac{1}{K}\right) O(K1)(见文中定理4.3)。需要注意的是,此时Bregman距离中 h ( w ) h(w) h(w)不是强凸,它的收敛性质和通常我们理解的范数是有区别的!!! (感兴趣的同学可以参考原论文中的Remark 4)
半强凸问题
半强凸问题被定义成
g
(
x
)
g(x)
g(x)或者
f
i
∗
(
y
)
f^*_i(y)
fi∗(y)中存在其中一个是强凸的。文章中假设
f
i
∗
(
y
)
f^*_i(y)
fi∗(y)是强凸的 (
g
(
x
)
g(x)
g(x)一般凸),那么对偶空间中的Bregman距离性质就会和正常的范数一致,对偶序列
{
y
k
}
\{y^k\}
{yk}最终能收敛到对偶最优解
y
∗
y^*
y∗。同时,当我们采用自适应的缩放矩阵 (adaptive scaling),那么序列速度将改进为
O
(
1
K
2
)
O\left(\frac{1}{K^2}\right)
O(K21)(见文中定理5.1)。改进后的Algorithm 3如下所示:

同理,如果假设 g ( x ) g(x) g(x)是强凸的 ( f i ∗ ( y ) f^*_i(y) fi∗(y)一般凸),那么原始空间中的Bregman距离性质就会和正常的范数一致,原始序列 { x k } \{x^k\} {xk}最终能收敛到对偶最优解 x ∗ x^* x∗。并且在论文中Algorithm 2下,序列速度将改进为 O ( 1 K 2 ) O\left(\frac{1}{K^2}\right) O(K21)。
强凸问题
如果问题中 g ( x ) g(x) g(x)和 f i ∗ ( y ) f^*_i(y) fi∗(y)都是强凸的,那么原始空间和对偶空间中的Bregman距离性质都会和正常的范数一致,序列 { ( x k , y k ) } \{(x^k,y^k)\} {(xk,yk)}最终能收敛到对偶最优解 ( x ∗ , y ∗ ) (x^*,y^*) (x∗,y∗)。并且对于Algorithm 1,序列 { ( x k , y k ) } \{(x^k,y^k)\} {(xk,yk)}将以线性速度收敛 (见文中定理6.1)。
另外的证明思路:
值得一提的是,最近研究人员又发现了另外一种基于随机算子理论 (stochastic operator) 来分析SPDHG收敛速度的方法。感兴趣的同学可以阅读这篇论文[2]。
第三部分:数值实验
本章有四个例子关于total variation,我们选取Huber-TV deblurring (对应Sec 7.3的Algorithm 3实验) 展开说明,剩下的三个例子原理类似。我们首先介绍一下TV operator的基本概念,方便读者理解。
对于 x ∈ R d 1 × d 2 x\in\mathbb{R}^{d_1 \times d_2} x∈Rd1×d2,TV算子定义如下:
R V β ( x ) = ∑ i , j ( ( x i , j + 1 − x i j ) 2 + ( x i + 1 , j − x i j ) 2 ) β 2 . \mathcal{R}_{V^\beta}(\mathbf{x})=\sum_{i, j}\left(\left(x_{i, j+1}-x_{i j}\right)^2+\left(x_{i+1, j}-x_{i j}\right)^2\right)^{\frac{\beta}{2}}. RVβ(x)=i,j∑((xi,j+1−xij)2+(xi+1,j−xij)2)2β.
上述方程的意思是: 计算每一个像素和横向下一个像素的差的平方,加上纵向下一个像素的差的平方; 然后开 β / 2 \beta/2 β/2次根。在这个例子中,我们考虑一个去模糊的卷积核,它有前向操作符 A 1 \mathbf{A}_1 A1类似于执行卷积 用一个移动的卷积核15*15像素的在长408,宽544像素的图片上。图片中的噪声用泊松方法在恒定的200像素的背景下,去估计数据的均值694.3。我们进一步假设有知道重建的图像应该是非负的和有上限的100倍。根据正向运算符的性质,只要 x ≥ 0 , A x ≥ 0 x \ge 0, \mathbf{A} x \geq 0 x≥0,Ax≥0。此时对偶问题下新的KL散度是
f i ∗ ( z ) = ∑ i = 1 N { r i 2 2 b i z i 2 + ( r i − r i 2 b i ) z i + r i 2 2 b i + 3 b i 2 − 2 r i − b i log ( b i r i ) , if z i < 1 − b i r i , − r i z i − b i log ( 1 − z i ) , if 1 − b i r i ≤ z i < 1 , ∞ , if z i ≥ 1. f_i^*(z)=\sum_{i=1}^N \begin{cases}\frac{r_i^2}{2 b_i} z_i^2+\left(r_i-\frac{r_i^2}{b_i}\right) z_i+\frac{r_i^2}{2 b_i}+\frac{3 b_i}{2}-2 r_i-b_i \log \left(\frac{b_i}{r_i}\right), & \text { if } z_i<1-\frac{b_i}{r_i}, \\ -r_i z_i-b_i \log \left(1-z_i\right), & \text { if } 1-\frac{b_i}{r_i} \leq z_i<1, \\ \infty, & \text { if } z_i \geq 1.\end{cases} fi∗(z)=i=1∑N⎩ ⎨ ⎧2biri2zi2+(ri−biri2)zi+2biri2+23bi−2ri−bilog(ribi),−rizi−bilog(1−zi),∞, if zi<1−ribi, if 1−ribi≤zi<1, if zi≥1.
之后,我们可以进行实验前的参数设计。在这个实验中,我们选择 γ = 0.99 \gamma =0.99 γ=0.99考虑均匀采样,即 p i = 1 / n p_i = 1/n pi=1/n。在确定性情况下,子集的数量为 n = 1 n=1 n=1或者在随机情况下 n = 3 n=3 n=3。初始步长参数被选择为
PDHG:
σ
i
=
τ
=
γ
/
∥
A
∥
≈
0.095
\sigma_i=\tau=\gamma /\|\mathbf{A}\| \approx 0.095
σi=τ=γ/∥A∥≈0.095;
DA-PDHG:
σ
~
i
(
0
)
=
μ
f
/
∥
A
∥
≈
0.096
,
τ
(
0
)
=
γ
/
∥
A
∥
≈
0.095
\tilde{\sigma}_i^{(0)}=\mu_f /\|\mathbf{A}\| \approx 0.096, \tau^{(0)}=\gamma /\|\mathbf{A}\| \approx 0.095
σ~i(0)=μf/∥A∥≈0.096,τ(0)=γ/∥A∥≈0.095;
DA-SPDHG:
σ
~
(
0
)
=
min
i
μ
i
p
i
2
τ
0
∥
A
i
∥
2
+
2
μ
i
p
i
(
1
−
p
i
)
≈
0.073
\tilde{\sigma}^{(0)}=\min _i \frac{\mu_i p_i^2}{\tau^0\left\|\mathbf{A}_i\right\|^2+2 \mu_i p_i\left(1-p_i\right)} \approx 0.073
σ~(0)=miniτ0∥Ai∥2+2μipi(1−pi)μipi2≈0.073,
τ
(
0
)
=
1
/
(
n
max
i
∥
A
i
∥
)
≈
0.032
\tau^{(0)}=1 /\left(n \max _i\left\|\mathbf{A}_i\right\|\right) \approx 0.032
τ(0)=1/(nmaxi∥Ai∥)≈0.032
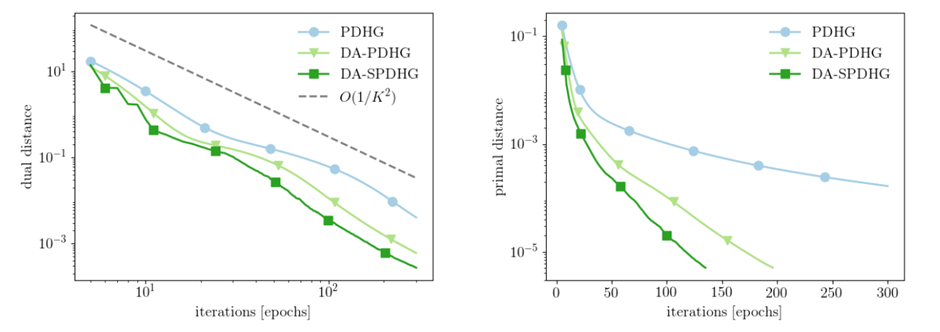
图1 Huber-TV 去模糊双加速 (左图是对偶变量
y
y
y,右图为原始变量
x
x
x)
图1的定量结果表明算法收敛确实有 O ( 1 K 2 ) O\left(\frac{1}{K^2}\right) O(K21)的比率,如定理 5.1 所证明的。此外,他们还表明随机化和加速可以结合使用以进一步加速。
在另外一篇论文中[3], 采用确定性PDHG的2000次迭代结果(近似)作为视觉和定量比较的鞍点。我们首先看从 3 中 100 次预期算子评估后的重建图像可以看出,SPDHG比确定性PDHG快得多 (下图2)。虽然使用 PDHG 的重建仍然存在伪影,但使用 SPDHG 重建的图像在 100 次迭代后在视觉上与鞍点非常相似。
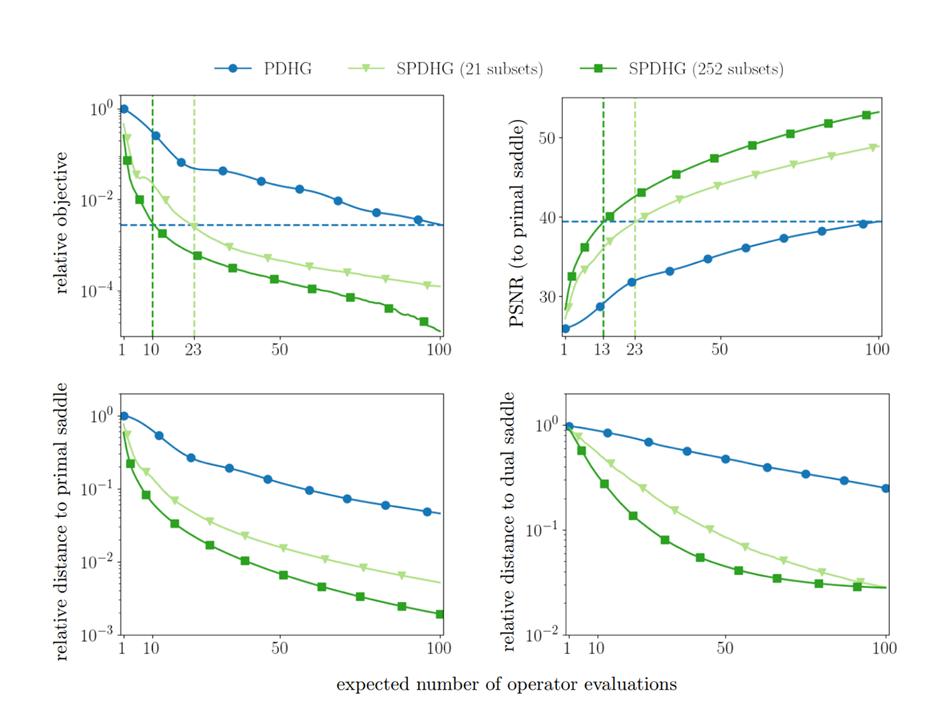
图2. 不同子集SPDGH 和PDGH比较 (横轴是不同数量操作符评估,纵轴是主要鞍点的相对距离)
另外,从图3中看,具有21和252个子集的SPDHG与仅经过 20 次预期操作员评估后的PDHG的比较。PDHG的结果在临床上无用,因为主要的解剖结构尚不可见。 另一方面,随着越来越多的子集,即使付出一点点努力,也可以重建一个合理的 (虽然不完美) 图像。与之相对的SPDHG,随着将像素点分割成越来越多的子集,即使付出⼀点点努力,也可以重建⼀个合理的 (虽然不完美) 图像 (如图3所示)。同时,还很容易看出,随着⼦集越多,伪影越少,这表明随着⼦集越多,算法收敛得越快。
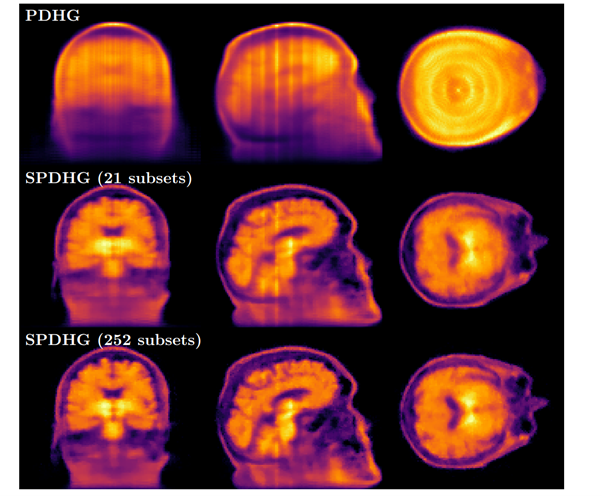
图3: TV先验PET重建, 20个迭代周期下的结果
参考文献:
[1] Chambolle, Ehrhardt, Richtárik & Schönlieb (2018). Stochastic Primal-Dual Hybrid Gradient Algorithm with Arbitrary Sampling and Imaging Applications. SIAM Journal on Optimization, 28(4), 2783–2808.
[2] Ahmet Alacaoglu, Olivier Fercoq, and Volkan Cevher (2022). On the Convergence of Stochastic Primal-Dual Hybrid Gradient. SIAM Journal on Optimization, 32(2), 1288-1318.
[3] Ehrhardt, Matthias & Markiewicz, Pawel & Richtárik, Peter & Schott, Jonathan & Chambolle, Antonin & Schönlieb, Carola-Bibiane. (2017). Faster PET reconstruction with a stochastic primal-dual hybrid gradient method. SPIE Proc (2017).