文章目录
- 4. 基于栈的字节码解释执行引擎
- 4.1 解释执行
- 4.2 基于栈的指令集与基于寄存器的指令集
- 4.3 基于栈的解释器执行过程
4. 基于栈的字节码解释执行引擎
关于虚拟机是如何调用方法已经讲解完毕,从本节开始,我们来探讨虚拟机是如何执行方法里面的字节码指令的。概述中提到过,许多Java虚拟机的执行引擎在执行Java代码的时候都有 解释执行(通过解释器执行)和 编译执行(通过即时编译器产生本地代码执行)两种选择,下面我们先来探讨一下在解释执行时虚拟机执行引擎是如何工作的。
4.1 解释执行
Java语言经常被人们定位为“解释执行”的语言,在Java初生的JDK1.0时代,这种定义还算是比较准确的,但当主流的虚拟机中都包含了 **即时编译器 **后,Class文件中的代码到底会被解释执行还是编译执行,就成了只有虚拟机自己才能准确判断的事。再后来,Java发展出了可以直接生成本地代码的编译器(如GCJ,GNU Compiler for the Java),而C/C+语言也出现了通过解释器执行的版本(如CINT),这时候再笼统地说“解释执行”对于整个Java语言来说几乎就是没有意义的概念了,只有确定了谈论对象是某种具体的Java实现版本和执行引擎运行模式时,谈解释执行还是编译执行才会比较确切。
不论是解释还是编译,也不论是物理机还是虚拟机,对于应用程序,机器都不可能如人那样阅读和理解,然后就获得了执行能力。大部分的程序代码到物理机的目标代码或虚拟机能执行的指令集之前,都需要经过下图中的各个步骤。如果对大学 编译原理 的相关课程还有印象的话,很容易就会发现图中下面的那条分支,就是传统编译原理中程序代码到目标机器代码的生成过程,而中间的那条分支自然就是解释执行的过程。
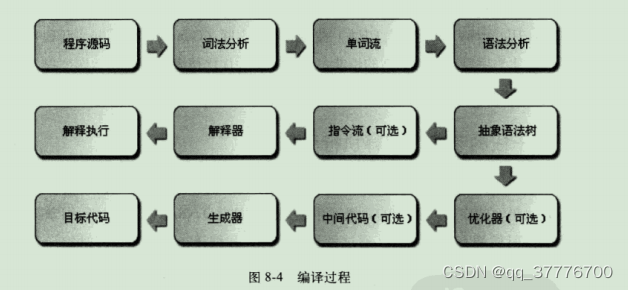
如今,基于物理机、Java虚拟机或者是非Java的其他高级语言虚似机(HLLVM)的语言,大多都遵循这种基于 现代经典编译原理 的思路,在执行前先对程序源码进行词法分析和语法分析处理,把源码转化为抽象语法树(Abstract Syntax Tree,AST)。对于一门具体语言的实现来说,词法和语法分析乃至后面的优化器和目标代码生成器都可以选择独立于执行引擎,形成一个完整意义的编译器去实现,这类代表是C/C++语言。也可以选择把其中一部分步骤(如生成抽象语法树之前的步骤)实现为一个半独立的编译
4.2 基于栈的指令集与基于寄存器的指令集
Java编译器输出的指令流,基本上"是一种基于栈的指令集架构(Instruction SetArchitecture,ISA),指令流里面的指令大部分都是零地址指令,它们依赖操作数栈进行工作。与之相对的另外一套常用的指令集架构是基于寄存器的指令集,最典型的就是x86的二地址指令集,更通俗一些,就是现在我们主流PC中直接支持的指令集架构,这些指令依赖寄存器进行工作。那么,基于栈的指令集与基于寄存器的指令集这两者之间有什么不同呢?
举个最简单的例子,分别使用这两种指令集去计算“1+1”的结果,基于栈的指令集会是这样子的:
iconst_1
iconst_1
iadd
istore_0
两条iconst_1指令连续地把两个常量1压入栈后,iadd指令把栈顶的两个值出栈并相加,然后把结果放回栈顶,最后istore_0把栈顶的值放到局部变量表的第0个Slot中。
如果是基于寄存器的指令集,那么程序可能会是这个样子的:
mov eax, 1
add eax, 1
mov指令把 EAX寄存器 的值设为1,然后add指令再把这个值加1,结果就保存在EAX寄存器里面。
基于栈的指令集最主要的优点就是 可移植性,寄存器由硬件直接提供,程序直接依赖这些硬件寄存器则不可避免地要受到硬件的约束。例如,现在32位x86体系的处理器中提供了8个32位的寄存器,而ARM体系的CPU(在当前的手机、PDA中相当流行的一种处理器)则提供了16个32位的通用寄存器。如果使用栈架构的指令集,用户程序不会直接用到这些寄存器,那就可以由虚拟机实现来自行决定把一些访问最频繁的数据(程序计数器、栈顶缓存等)放到寄存器中以获取尽量好的性能,这样实现起来也更加简单。栈架构的指令集还有一些其他优点,如代码相对更紧凑(字节码中每个字节就对应一条指令,而多地址指令集中还需要存放参数)、编译器实现更加简单(不需要考虑空间分配的问题,所需空间都在栈上操作)等。
栈架构指令集的主要缺点是执行速度相对来说稍慢一些。所有主流物理机的指令集都是寄存器架构也从侧面印证了这一点。
栈架构指令集的代码虽然紧凑,但是完成相同功能所需的指令数量一般会比寄存器架构多,因为出栈、入栈操作本身就产生了相当多的指令。更重要的是 栈实现在内存之中,频繁的栈访问也就意味着频繁的内存访问,相对于处理器来说,内存始终是执行速度的瓶颈。尽管虚拟机可以采取栈顶缓存的手段,把最常用的操作映射到寄存器中以避免直接内存访问,但这也只能是优化措施而不是解决本质问题的方法。因此,由于指令数量和内存访问的原因,导致了栈架构指令集的执行速度相对较慢。
4.3 基于栈的解释器执行过程
初步的理论已经讲解完了,本小节准备了一段Jva代码,看看在虚拟机中实际上是如何执行的。前面曾经举过一个计算“1+1”的例子,下面给出的例子涉及的是四则运算加减乘除法,如代码清单所示。
public int calc(){
int a = 100;
int b = 200;
int c = 300;
return (a+b) * c;
}
我们使用javap命令查看字节码指令
public int calc();
descriptor: ()I
flags: (0x0001) ACC_PUBLIC
Code:
stack=2, locals=4, args_size=1
0: bipush 100
2: istore_1
3: sipush 200
6: istore_2
7: sipush 300
10: istore_3
11: iload_1
12: iload_2
13: iadd
14: iload_3
15: imul
16: ireturn
javap提示这段代码需要深度为2的操作数栈和4个Slot的局部变量空间
-
首先,执行偏移地址为0的指令,
bipush指令的作用是将单字节的整型常量值(-128~127)推人操作数栈顶,后跟一个参数,指明推送的常量值,这里是100。

-
执行偏移地址为1的指令,
istore_1指令的作用是将操作数栈顶的整型值出栈并存放到第1个局部变量Slot中。后续四条指令(直到偏移为11的指令为止)都是做同样的事情,也就是在对应代码中把变量a、b、c赋值为100、200、300。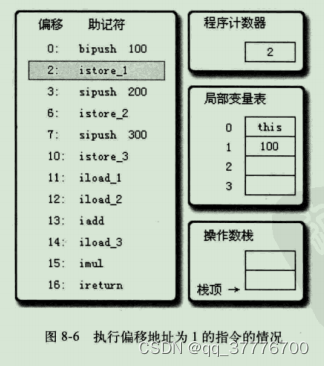
-
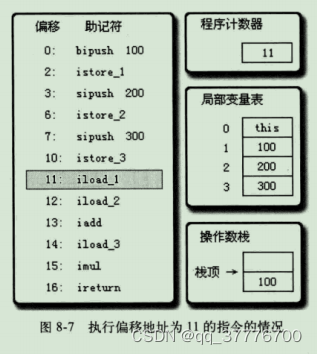
执行偏移地址为11的指令,
iload_1指令的作用是将局部变量表第1个Slot中的整型值复制到操作数栈顶。
-
执行偏移地址为12的指令,
iload_2指令的执行过程与iload_1类似,把第2个Slot的整型值入栈。画出这个指令的图示主要是为了显示下一条iadd指令执行前的堆栈状况。

-
执行偏移地址为13的指令,
iadd指令的作用是将操作数栈中前两个栈顶元素出栈,做整型加法,然后把结果重新入栈。在iadd指令执行完毕后,栈中原有的100和200出栈,它们的和300重新人栈。
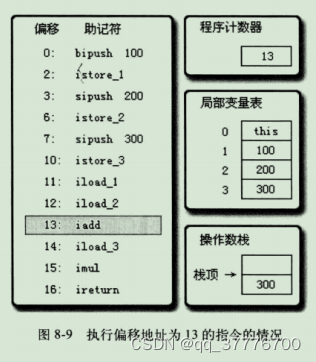
-
执行偏移地址为14的指令,
iload_3指令把存放在第3个局部变量Slot中的300人栈到操作数栈中。这时操作数栈为两个整数300。下一条指令imul是将操作数栈中前两个栈顶元素出栈,做整型乘法,然后把结果重新入栈,这里与idd完全类似 -
执行偏移地址为16的指令,
ireturn指令是方法返回指令之一,它将结束方法执行并将操作数栈顶的整型值返回给此方法的调用者。到此为止,这段方法执行结束。
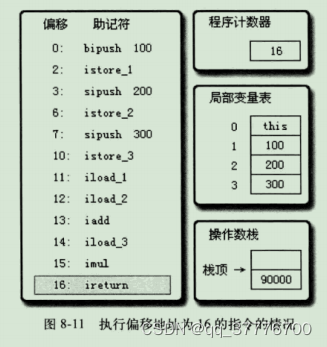
上面的执行过程仅仅是一种概念模型,虚拟机最终会对执行过程做出一些优化来提高性能,实际的运作过程不一定完全符合概念模型的描述,更准确地说,实际情况会和上面描述的概念模型有非常大的差距,差距产生的原因是虚拟机中解析器和即时编译器都会对输人的字节码进行优化,例如,HotSpot虚拟机中就有很多以“fast”开头的非标准字节码指令用于合并和替换输入的字节码以提升解释执行性能,即时编译器的优化手段更是花样繁多。
不过我们从这段程序的执行中也可以看出栈结构指令集的一般运行过程,整个运算过程的中间变量都以操作数栈的出栈和入栈为信息交换途径,符合我们在前面分析的特点。