作者 | 加纳斯
导读
说起百度的BFE可能不少人都听说过,但是其实在百度内部还有一个几百万qps的通用网关服务:Janus。截止当前,Janus服务不仅覆盖了百度内部FEED、评论、点赞、关注、直播等十多个中台服务的内网流量,而且为百度app、知道、经验、passport、百科、问一问等业务提供了外网流量服务。
在百度已有BFE且BFE开源的情况下,为什么要建设Janus网关?Janus网关区别于其他网关的核心点有哪些?面对众多的接入方,如何实现既能通用又能个性化的流量调度呢?
来本文一探究竟吧。
全文3802字,预计阅读时间10分钟。
01 为什么要建设Janus
在百度已有BFE且BFE开源的情况下,为什么要建设Janus网关?
从场景上看,与BFE面向通用功能的流量网关场景不同,Janus不仅可以作为流量网关,也可以作为业务网关、混合网关;不仅面向通用功能,也支持个性化需求。从实现上看,Janus的部分技术参考了BFE,但是与厂内BFE主要提供saas类的服务不同,Janus提供的是一个通用技术方案,谁使用谁部署,谁有个性化需求谁自己定制插件。因此,Janus网关的应用场景相对更广一些,当前的使用场景主要包含流量网关、业务网关、混合网关三种模式,流量拓扑如下:
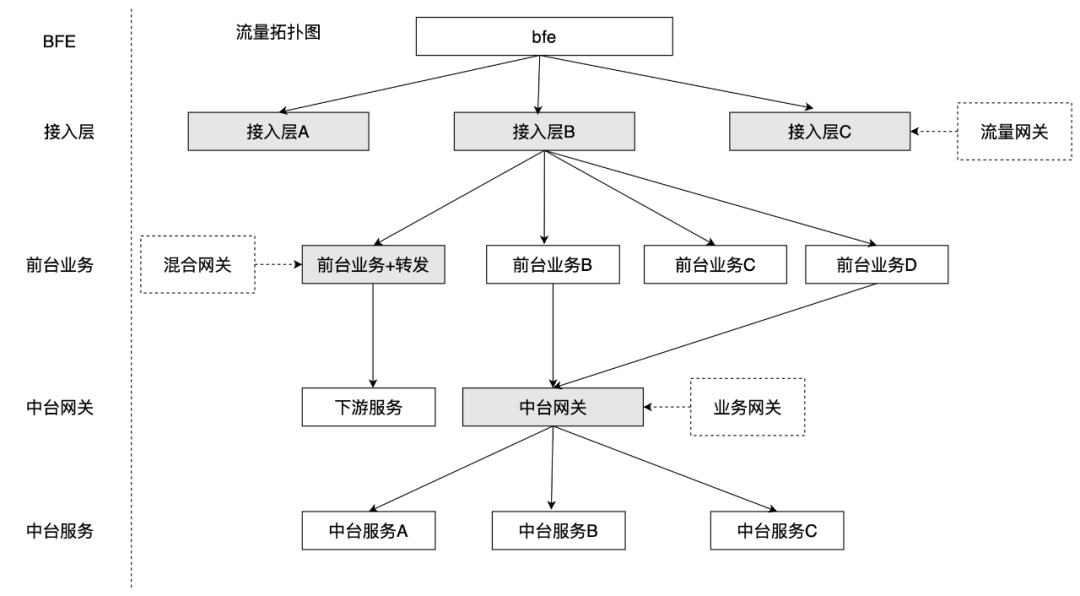
部署拓扑:
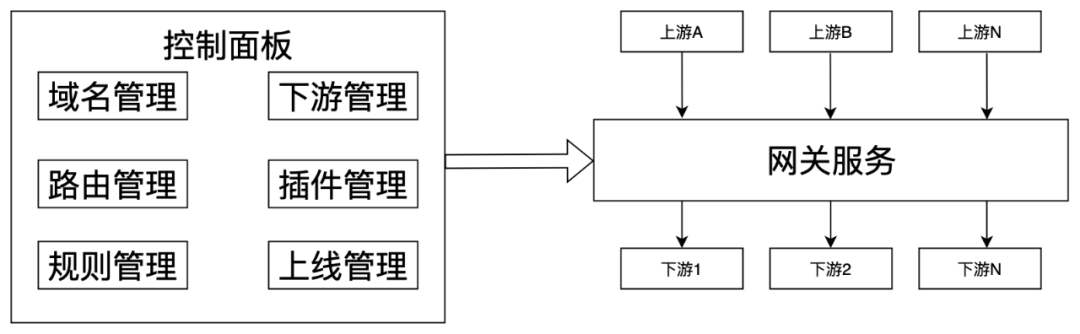
02 核心问题
从流量调度规则为例,大部分的使用方的转发规则都相对比较简单,但是部分业务的转发规则来自于原来的nginx配置,相对比较复杂,更有些使用方会有偏业务的逻辑在里面,例如:
-
从某时刻后,将API1的A机房和B机房的流量切30%到C机房;
-
将某个APP的某个版本之上的android流量切到新的路由规则;
-
cookie有某些特征或者query中有某些特征的流量转发到预览环境。
那么在调度阶段如何更好地解决如下两个问题呢:
-
如何让简单的路由规则配置起来特别简单,性能较高?
-
如何实现复杂甚至业务个性化的调度策略实现?
把问题放大到网关的全局应用场景来看,如何既能通用,写个插件大家都能用;又能支持个性化,尽量能通过通用插件满足业务特例的问题;还能灵活,流量网关、业务网关都能胜任。既要、又要、还要的问题通常是使用tradeoff的方式加以平衡解决,但是Janus的解决方案同时满足了上面的三个需求:通过插件机制满足通用化需求+通过可动态下发编程能力的方式进行差异化配置+通过SDK集成到业务部署的方式支持灵活使用。
03 流量调度方案设计
3.1 方案思路概述
为了将服务的转发规则更加清晰,Janus将路由分为了三级(与nginx类似):
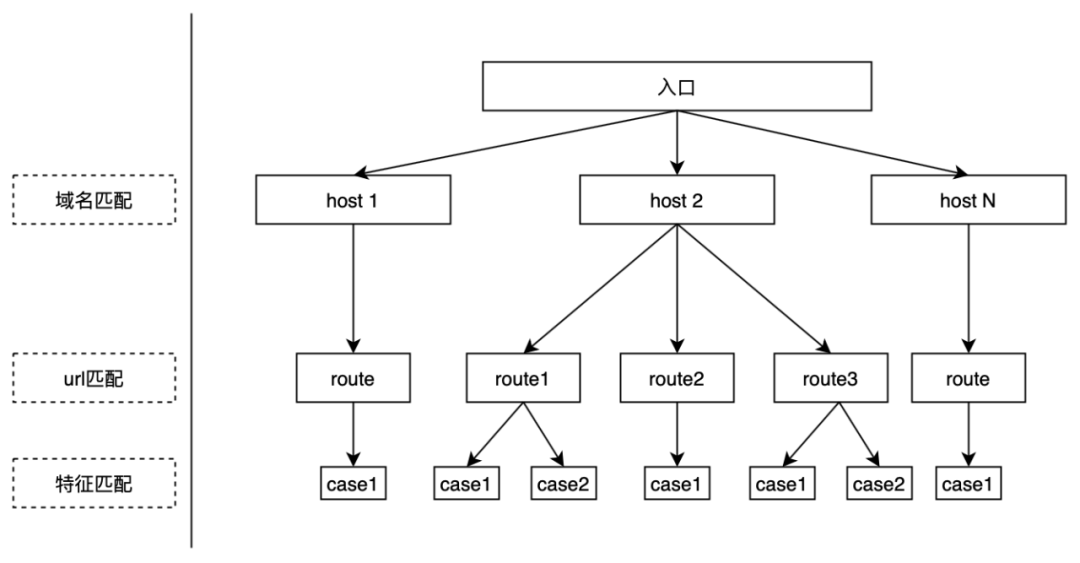
由上面的挑战分析可知:
-
对于大多数的简单路由规则需要相对简单,性能相对高,通过域名匹配+树路由实现的url匹配即可;
-
对于少量的复杂路由规则需要扩展性足够强,可以在特征匹配阶段引入一个极简的脚本语言来实现。
3.2 基础路由规则支持
通过树路由支持的部分规则如下:

3.3 进阶路由规则支持
上述的简单路由规则可以满足90%+的业务需求,但是对于类似`从某时刻后,将API1的A机房和B机房的流量切30%到C机房`这种需求是满足不了的。因此,在特征匹配阶段可以通过`变量表达式`+`条件表达式`进行精细化匹配。
变量表达式
为了能根据系统里面的常见特征进行精细化匹配,首先我们要对系统里面的常见特征进行描述。例如:
-
通过${idc}表示当前所属的机房
-
通过${time}表示当前时间
-
通过${query}表示get参数
-
通过${header}表示header里面的数值
但是当特征越来越多的时候,就会略显臃肿,存在的特征变量越来越多,这时候Janus引入了分级的概念,比如:
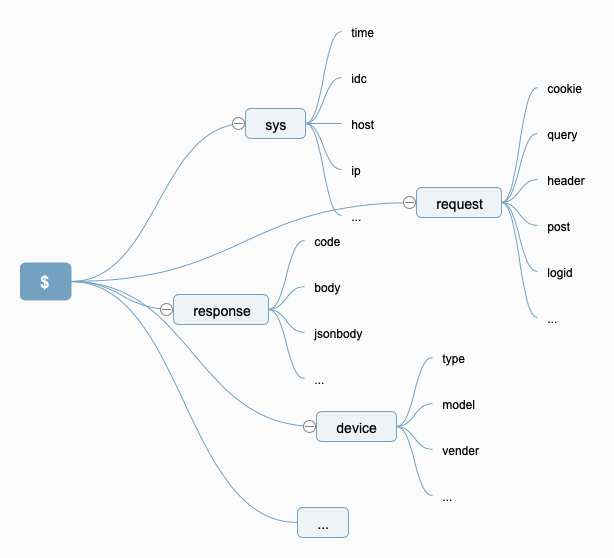
如图所示,就可以用${request.query.id}来表示本次请求中key为id的query值。并且如上的特征变量是可以扩充的,每个使用方可以根据自己的系统差异、环境差异定义自己的特征变量体系。
条件表达式
有了上面实现的变量表达式,我们就可以用$描述我们需要的特征变量了,但是如何对这些特征变量进行操作呢?
Janus的方案是定义一门极简的语言(无论是用yacc等一类的生成语法分析的工具,还是自己做词法分析、语法分析,实现都比较简单,这里不再赘述实现细节),只支持逻辑运算+函数调用,部分例子如下:
函数调用:
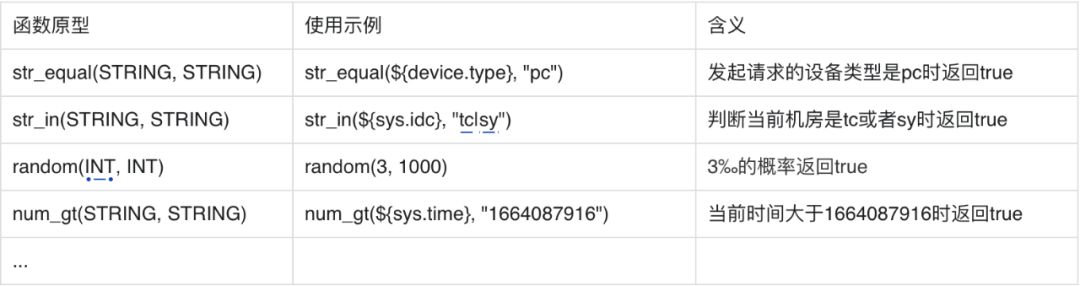
逻辑运算:

Janus在有变量表达式来表示系统特征的基础上,添加了条件表达式来对系统特征进行操作、判断。由于可以不断扩充变量表达式和条件表达式,因此Janus几乎可以满足用户的任意需求。
性能对比
通过如上方案介绍可以看出,采用从控制面下发表达式的方式,可以满足绝大部分场景的需求,但是,对性能影响如何呢?
在数据面接收到控制面下发转发规则时,首先会对变量表达式和条件表达式进行编译,映射成go的代码,在后续运行时,与直接调用原生的go语言差异并不大。对比数据如下:
条件表达式:
“random(0,100) || random(100,100)”
对应的benchmark数据:
goos: windows
goarch: amd64
cpu: 11th Gen Intel(R) Core(TM) i5-1145G7 @ 2.60GHz
BenchmarkRandom-8 35817918 34.52 ns/op 0 B/op 0 allocs/op
原生go代码:
(0 > rand.Intn(100)) || (100 > rand.Intn(100))
对应的benchmark数据:
goos: windows
goarch: amd64
cpu: 11th Gen Intel(R) Core(TM) i5-1145G7 @ 2.60GHz
BenchmarkRawRandom-8 39136900 31.63 ns/op 0 B/op 0 allocs/op
可以看到使用表达式与使用原生go代码在性能上相差不到10%,区别并不是特别大。
04 方案泛化
通过上面的变量表达式+条件表达式的方式,很好地解决了流量调度问题。实际上,该方案可以作为一个通用解决方案解决很多类似问题。以Janus网关为例,在很多地方都大量存在这个变量表达式和条件表达式。
4.1 插件的运行条件
以容灾插件为例,用户可以把容灾插件配置在任意路由规则上,但是大家认定的触发容灾的规则可能不一样,比如:
-
有些业务认为:只有后端的http协议返回5xx才需要容灾
-
有些业务认为:后端的http协议返回5xx 或者 返回值的json里面errno != 0需要容灾
-
更有些业务认为:后端的http协议返回5xx 或者 header里面的sla_status=0需要容灾
一方面,我们想做一个通用的容灾插件,另一方面,大家的触发规则的标准又千奇百怪、各不相同。怎么解决这个矛盾呢?
Janus的答案是:把控制权交给用户,用户配置容灾插件的时候同时配置一个条件表达式,只有条件表达式返回true,才会运行容灾逻辑。
上面的问题对应的下发配置如下:
-
num_gt(${response.code}, 499)
-
num_gt($ {response.code}, 499) || (!str_equal($ {response.jsonbody.errno}, 0))
-
num_gt($ {response.code}, 499) || (!str_equal(${response.header.sla_status}, 0))
这样就做到了既是一个通用容灾插件,又可以做到个性化的触发逻辑。
4.2 通用缓存插件的设计
当我们想做一个通用的redis缓存插件时,存取逻辑比较简单:
// 请求下游前
if data, ok := redis.Get(key); ok {
return data
}
// 请求下游
data := reqeust(xxx)
// 请求下游后
redis.Set(key, data)
但是,与上面的插件面临的问题类似,通用缓存插件的key怎么定义呢?
-
评论接口只要id一样就认为是同一个请求
-
我的粉丝接口不仅需要id一样,还需要uk一样才是同一个请求
-
主页接口需要uk一样才认为是同一个请求
解决思路是用变量表达式来把key的定义交给用户,用户配置缓存插件的时候同时配置key的规则,比如:
-
comment_${request.query.id}
-
fans_$ {request.query.id}_${request.query.uk}
-
homepage_${request.query.uk}
这样就解决了通用缓存插件中的通用与个性化之间的矛盾。
05 展望
在Janus网关服务中,通过常规路由规则+变量表达式+条件表达式的方式实现了各种流量调度策略,并将方案泛化到了各种其他功能的实现上,支撑了几百万QPS的流量及众多使用方的接入。通过已经实现的系统变量及规则的组合,基本可以实现任意功能,但是当需要新的规则时,则需要在Janus中上线新的条件表达式实现。为了进一步强化Janus中的动态配置表现能力,Janus正在进行表示式与Go官方标准库的无缝打通。这样就可以在控制面进行更加灵活的配置下发动态编程能力,满足更广泛的需求。
——END——
推荐阅读:
深入浅出DDD编程
百度APP iOS端内存优化实践-内存管控方案
Ernie-SimCSE对比学习在内容反作弊上应用
质量评估模型助力风险决策水平提升
合约广告平台架构演进实践
AI技术在基于风险测试模式转型中的应用