目录
前言:
1.定义测试数据结构
2.从文件中加载测试数据
3.使用faker库生成随机测试数据
4.在测试用例中使用测试数据
总结:

前言:
在进行接口自动化测试时,测试数据的准备和处理是至关重要的一环。测试数据的准确性和完整性直接影响到测试结果的可靠性和有效性。在本文中,我们将讨论在接口自动化测试中如何处理测试数据。
1.定义测试数据结构
测试数据结构定义是测试数据处理的第一步。在进行接口自动化测试时,根据被测接口的输入和输出参数定义相应的测试数据结构。测试数据结构可以使用Python的字典(dict)或类(class)来定义,具体应用取决于测试数据的复杂程度。
以下是一个使用字典定义测试数据结构的例子:
test_data = {
'login': {
'username': 'testuser',
'passwor': 'testpwd'
},
'add_order': {
'product_id': 'P001',
'quantity': 2,
'price': 10.0
}
}
2.从文件中加载测试数据
当测试数据量比较大时,手动编写测试数据不仅费时费力,而且容易出错。因此,我们通常会将测试数据存储在文件中,并通过代码读取文件中的测试数据。
以下是一个从CSV文件中读取测试数据的例子:
import csv
def load_test_data_from_csv(file_path):
test_data = []
with open(file_path, 'r') as f:
reader = csv.DictReader(f)
for row in reader:
test_data.append(row)
return test_data
以上代码使用Python内置的csv模块读取CSV文件中的测试数据,并将每行数据转换为字典格式,最终返回一个包含所有测试数据的列表。
3.使用faker库生成随机测试数据
在某些情况下,我们需要使用随机测试数据进行接口自动化测试。例如,在进行用户注册接口测试时,每个新注册的用户都需要具有唯一的用户名和邮箱地址。这时,我们可以使用faker库生成随机测试数据。
以下是一个使用faker库生成随机测试数据的例子:
from faker import Faker
def generate_random_user():
fake = Faker()
return {
'username': fake.user_name(),
'email': fake.email()
}
以上代码使用faker库生成随机用户名和邮箱地址,并将其封装到字典中作为测试数据返回。
4.在测试用例中使用测试数据
测试数据处理完成后,我们需要在测试用例中使用这些测试数据。在pytest框架中,我们可以通过@pytest.mark.parametrize注解来传递测试数据。
以下是一个使用pytest框架和测试数据的例子:
import pytest
@pytest.mark.parametrize('username,password', [
('testuser1', 'pwd1'),
('testuser2', 'pwd2')
])
def test_login(username, password):
# 测试代码
pass
以上代码使用pytest框架的@pytest.mark.parametrize注解传递了两组测试数据,分别是(username='testuser1', passwor='pwd1')和(username='testuser2', passwor='pwd2')。在测试用例中,我们可以直接使用这些测试数据进行接口测试。
总结:
综上所述,测试数据处理是接口自动化测试中重要的一环。定义测试数据结构、从文件中加载测试数据、使用faker库生成随机测试数据以及在测试用例中使用测试数据是常见的测试数据处理方式。通过合理地处理测试数据,我们可以提高接口自动化测试的可靠性和有效性。
![]()
自动化测试学习步骤框架图:
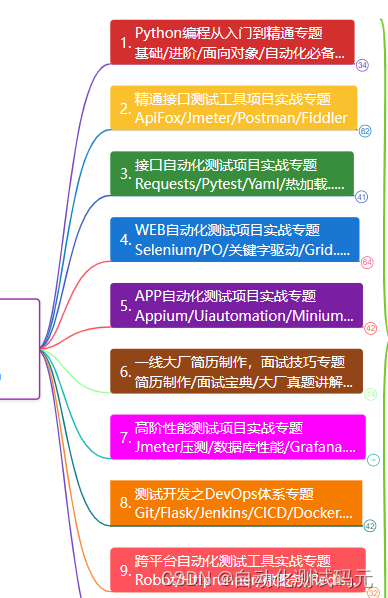
小编还准备了福利: