一、高并发下如何保证读写一致
1.1 写操作
对于写操作,一致性级别支持 quorum/one/all,默认为 quorum,即只有当大多数分片可用时才允许写操作。但即使大多数可用,也可能存在因为网络等原因导致写入副本失败,这样该副本被认为故障,副本将会在一个不同的节点上重建。
one:写操作只要有一个primary shard是active活跃可用的,就可以执行
all:写操作必须所有的primary shard和replica shard都是活跃可用的,才可以执行
quorum:默认值,要求ES中大部分的shard是活跃可用的,才可以执行写操作1.2 读操作
对于读操作,可以设置 replication 为 sync(默认),这使得在写入操作时,在主分片和副本分片都完成后才会返回;如果设置replication 为 async 时,也可以通过设置搜索请求参数 _preference 为 primary 来查询主分片,确保文档是最新版本。
1.3 更新操作 通过版本号使用乐观锁并发控制
每个文档都有一个_version 版本号,这个版本号在文档被改变时加一。Elasticsearch使用这个 _version 保证所有修改都被正确排序,当一个旧版本出现在新版本之后,它会被简单的忽略。
利用_version的这一优点确保数据不会因为修改冲突而丢失,比如指定文档的version来做更改,如果那个版本号不是现在的,我们的请求就失败了。
二、ES数据写入流程
2.1、ES写数据的整体流程:
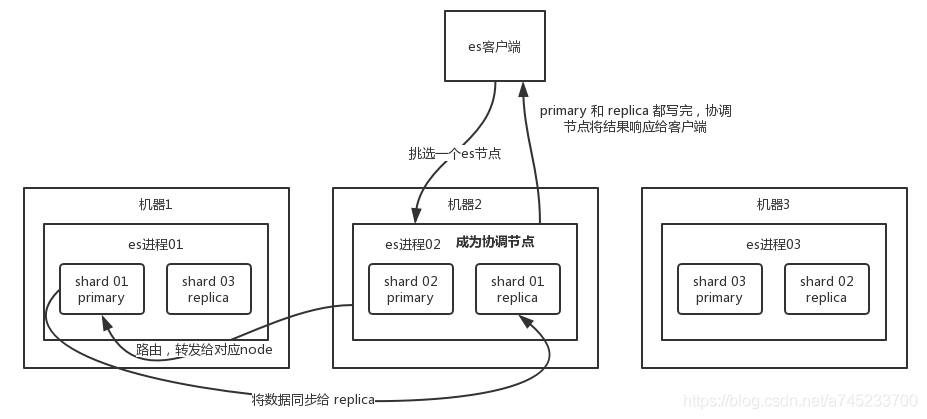
(1)客户端选择 ES 的某个 node 发送请求过去,这个 node 就是协调节点 coordinating node
(2)coordinating node 对 document 进行路由,将请求转发给对应的 node(有 primary shard)
(3)实际的 node 上的 primary shard 处理请求,然后将数据同步到 replica node
(4)coordinating node 等到 primary node 和所有 replica node 都执行成功之后,最后返回响应结果给客户端。
2.2、ES主分片写数据的详细流程:
(1)主分片先将数据写入ES的 memory buffer,然后定时(默认1s)将 memory buffer 中的数据写入一个新的 segment 文件中,并进入操作系统缓存 Filesystem cache(同时清空 memory buffer),这个过程就叫做 refresh;每个 segment 文件实际上是一些倒排索引的集合, 只有经历了 refresh 操作之后,这些数据才能变成可检索的。
ES 的近实时性:数据存在 memory buffer 时是搜索不到的,只有数据被 refresh 到 Filesystem cache 之后才能被搜索到,而 refresh 是每秒一次, 所以称 es 是近实时的;可以手动调用 es 的 api 触发一次 refresh 操作,让数据马上可以被搜索到;
(2)由于 memory Buffer 和 Filesystem Cache 都是基于内存,假设服务器宕机,那么数据就会丢失,所以 ES 通过 translog 日志文件来保证数据的可靠性,在数据写入 memory buffer 的同时,将数据也写入 translog 日志文件中,当机器宕机重启时,es 会自动读取 translog 日志文件中的数据,恢复到 memory buffer 和 Filesystem cache 中去。
ES 数据丢失的问题:translog 也是先写入 Filesystem cache,然后默认每隔 5 秒刷一次到磁盘中,所以默认情况下,可能有 5 秒的数据会仅仅停留在 memory buffer 或者 translog 文件的 Filesystem cache中,而不在磁盘上,如果此时机器宕机,会丢失 5 秒钟的数据。也可以将 translog 设置成每次写操作必须是直接 fsync 到磁盘,但是性能会差很多。
(3)flush 操作:不断重复上面的步骤,translog 会变得越来越大,不过 translog 文件默认每30分钟或者 阈值超过 512M 时,就会触发 commit 操作,即 flush操作,将 memory buffer 中所有的数据写入新的 segment 文件中, 并将内存中所有的 segment 文件全部落盘,最后清空 translog 事务日志。
① 将 memory buffer 中的数据 refresh 到 Filesystem Cache 中去,清空 buffer;
② 创建一个新的 commit point(提交点),同时强行将 Filesystem Cache 中目前所有的数据都 fsync 到磁盘文件中;
③ 删除旧的 translog 日志文件并创建一个新的 translog 日志文件,此时 commit 操作完成
三、ES的搜索流程
搜索被执行成一个两阶段过程,即 Query Then Fetch:
3.1、Query阶段:
客户端发送请求到 coordinate node,协调节点将搜索请求广播到所有的 primary shard 或 replica,每个分片在本地执行搜索并构建一个匹配文档的大小为 from + size 的优先队列。接着每个分片返回各自优先队列中 所有 docId 和 打分值 给协调节点,由协调节点进行数据的合并、排序、分页等操作,产出最终结果。
3.2、Fetch阶段:
协调节点根据 Query阶段产生的结果,去各个节点上查询 docId 实际的 document 内容,最后由协调节点返回结果给客户端。
coordinate node 对 doc id 进行哈希路由,将请求转发到对应的 node,此时会使用 round-robin 随机轮询算法,在 primary shard 以及其所有 replica 中随机选择一个,让读请求负载均衡。
接收请求的 node 返回 document 给 coordinate node 。
coordinate node 返回 document 给客户端。
Query Then Fetch 的搜索类型在文档相关性打分的时候参考的是本分片的数据,这样在文档数量较少的时候可能不够准确,DFS Query Then Fetch 增加了一个预查询的处理,询问 Term 和 Document frequency,这个评分更准确,但是性能会变差。