浙江顶誉集团是一家知名的食品加工集团,拥有久久丫、留夫鸭等多个品牌。一直重视企业信息化建设,更是把数字化作为集团的一大发展方向,立志不断加大数字化投入和建设,成为一个数字化的企业。因此,该企业与亿信华辰合作,建主数据管理平台,提供数据共享应用,提升组织效率。本案例旨在为企业的主数据平台建设提供经验借鉴。
01
案例企业
众所周知的久久丫品牌创立于2002年,其母公司是浙江顶誉集团,是一家聚焦于做卤味的连锁企业。除了久久丫外,浙江顶誉集团还有专注家庭餐桌的“留夫鸭”品牌,专注年轻的“玩儿串串”品牌,以及做长效的包装品“E铺多”品牌。
浙江顶誉集团作为卤味产品的代表企业,在浙江、上海、北京、广州、成都五大基地的基础上不断开拓新领域。集团在全国覆盖门店已超3000家,行业从业人员超过12000人,成为国内名副其实的卤味代表。
02
业务挑战
顶誉集团过去一直重视企业信息化建设,更是把数字化作为集团的一大发展方向,立志不断加大数字化投入和建设,成为一个数字化的企业。
经历了多年的信息化发展,集团拥有将近有40多套 IT系统,有相当多的历史数据沉淀,各业务系统之间接口也比较多,形成一个比较严重的数据孤岛现象,主要体现在于一套数据在多个信息系统里面都会存在,并且在各个系统里面的口径、维度等都不太一样。同时数据质量堪忧,数据流程急需优化。
在主数据管理方面存在以下4大问题,也是亟需需上主数据管理系统的主要原因:

第一:基础数据质量堪忧
举一个最典型的例子,物料主数据存在一物多码的问题。
比如顶誉有一个物料主数据叫做小米椒,但它会产生有多个名称,包括小米椒、小米辣、小米辣椒,就形成了3条主数据。还有加上空格、不同的规格型号等,导致这样的主数据比较多。
第二:多点维护、各自为政
这个问题在组织主数据上来讲相对比较突出。因为顶誉有5大战区,每个战区下面的组织规划调整也比较频繁,导致了各个业务系统之间的组织架构不太同步。
比如要增加一个业务部门叫销售部,那可能在OA系统里增加了叫销售部,在CRM系统里可能叫销售管理部。当然在其他系统里每个人理解不同,那么增加的编码、命名等都会存在问题,导致编码不统一,核心属性有个性、少共性等的问题。
第三:缺乏标准化规则
在大部分企业的主数据里面,也会存在物料编码、物料名称、规格型号等比较常见的数据名称、数据属性,那么它已经存在命名规范。但比如说客户、供应商、人员等更多属性里面缺乏统一规则和数据维护的口径。
第四:没有明确的责任部门
集团层面目前对各类核心主数据没有明确责任部门,比如说物料可能采购部在管、物资部在管,但是如果具体细分到比如原材料、原辅料、包装辅材等,那么每一个细分都可能有自己的部门,但是没有一个明确的责任部门。
集团层面没有明确的负责主体对主数据内容和质量负责,比如说某个主数据出现质量问题,想去找到责任部门的话,可能这一条主数据有涉及多个部门,并且这条属性维护也会存在多个部门在牵头维护,导致这个主数据的质量就没有责任部门,那么责任没办法落实了。这个是顶誉主数据项目面临的一个主要问题。
03
解决方案
争取高层领导支持
获取甲方高层支持是主数据成功的重要因素,顶誉这个项目争取到了集团CIO和CFO两方高层的支持,这个是主数据实施的一个前提。
主数据项目相对一般信息化项目,有一个特点:共享性、协同性。比如顶誉物料主数据的维护横跨将近有五六个部门,从采购、研发、销售、财务等各个部门都会牵涉到,那么每个部门负责的字段也不太一样。
而且在项目流程梳理时非常重要的一个工作,就是对整个制度和流程的优化。它是基于人的,获得了高层支撑,在各个业务部门之间有协同问题时,可以给出一个最优化的解决方案。很多时候,项目的难点不在于制度的建设,也不在于决策规划,而是在于制度的执行。
主数据体系框架
基于项目痛点,给顶誉集团设计了一套主数据体系框架:
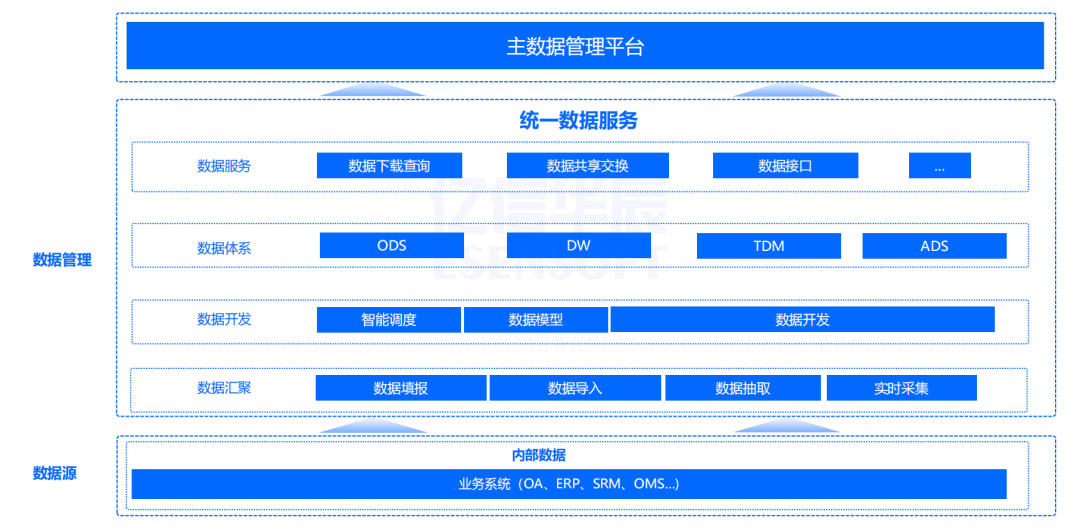
最底层是数据源层,打通和主数据相关的近20套业务系统。在没上主数据系统之前,包括像OA和ERP、SRM以及ERP和财务共享,都做了不同程度的主数据集成。比如建了一个物料,在OA做个物料申请,部分字段可能会推送ERP,那么在这里就形成类似于像蜘蛛网的关联,导致接口稳定性也会存在问题。后来把数据系统都平铺过来,所有的系统和主数据系统进行对接。
第二层就是数据汇聚层、开发层、体系层和服务层,包括数据下载查询、数据交换、数据接口。最上面就是整个主数据服务平台,当然在这里面也涵盖了亿信华辰主数据管理平台的重要功能,包括建模、数据导入、数据录入、数据流程、数据抽取等。
业务演进
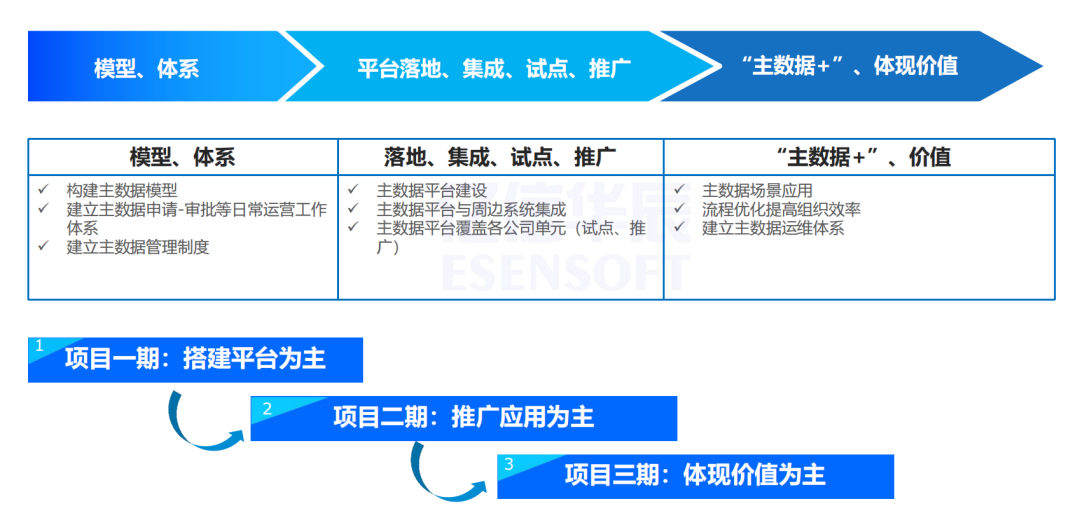
顶誉项目的业务演进大概经历了几个过程,第一个过程就是模型和体系的架构,基本上以主数据模型和流程梳理以及建立主数据管理制度为主。第二个阶段就是主数据平台的建设以及周边系统的一个集成,第三个阶段就是把主数据的实际应用推广起来,主要包括主数据场景的一些应用流程优化、提高组织效率。
授人以鱼,不如授人以渔。此项目一个非常重要的目标是建立主数据的一个运维体系,就是把整个主数据管理规范、制度建设、系统应用都交付培训。因为主数据它不是一成不变的,随着企业业务系统的发展、时间的推移会发生变化,不能一直依赖于乙方顾问团队长期服务,那么甲方团队建立一个专业团队也是非常重要的。
建设范围

实施范围涵盖了整个顶誉这个集团包括久久丫、留夫鸭等等。
数据范围主要做了物料类、客户类、供应商类、组织人员类和财务类主数据。
服务对象包括整个集团,业务部门涵盖了财务部、招商部、采购部、力资源以及生产和信息部等。
建设范围除了主数据平台建设,项目的培训服务和项目维保服务也是非常重要的环节。
04
价值与成果
成果总结
此次顶誉集团主数据项目的成果总结起来,包括以下6个方面:

第一:规范流程
在做这个项目之前,顶誉也建立了自己的一些流程,有OA系统、SRM系统等等这样的业务系统在运转。比如说供应商有集采供应商和零散供应商,流程也不一样,走的系统也不太一样,通过此次项目,主要规范统一的数据的申请、变更等等相应的流程。规范流程管理,降低了管理上的风险。
第二:建立主数据分发机制
上线前:顶誉上主数据系统之前已有系统之间的集成,但没有形成主数据分发的标准和规范,导致各业务系统之间的分发随意性比较大,接口的语言、接口的标准比较多。
上线后:统一规范,建立了主数据的一个分发机制,减少各个系统之间的一个工作量。并且在主数据系统上线之后,更新迭代了新的HR系统,经受住了考验,依照于新的标准,去接入一套新的系统之后,发现比之前没有主数据系统来,大大提升工作效率。
第三:大量期初数据整理
截止到21年4月份,项目上线时整个梳理各类主数据将近有2万条。当然还没有全部完成,在上线之后还在分阶段去完成。
第四:实现数据留痕,多版本对比
上线前:主数据修改是流程审批中一个很重要的痛点,比如说整个物料的主数据梳理下来有100个字段,每次退回审批修改可能只会修改其中一个字段,而审批人员很难去发现改了哪个字段。
上线后:引入亿信华辰的数据版本管理的概念,实现了数据留痕、多版本的一个对比,实现了各个版本的一个修改信息及内容,可以随时随地对每个版本进行横向对比。比如把当前的版本和最近那个版本对比,或者把当前版本和最初的一个版本进行对比,都是可以的,并且系统里面每一步修改都有留痕的。
第五 :主数据申请相似度检测
上线前:在主数据申请时经常会存在一物多码的情况,有时候是没有特定工具去把名字给检索出来。或者随着时间推移,维护主数据的人员发生变更,他不知道是之前维护的物料名称是什么,拿到一个新的物料申请时,可能为了省事就会按照自己的习惯去填写。
上线后:此项目引入主数据相似度检测解决这个问题,把每个字段来进行权重的设置,比如说输入“杯子”,马上就会发现系统里已经有杯子,但规格型号不一样,那规格型号比如占权重50%、名称占50% ,相当于整体重复度有50%,系统就会提示主数据可能会存在重复,需要复核,并且会把所有和相似度相关的按照权重得出重复分值后进行排名展示。
第六:梳理整合了大量的数据规则
制度很重要,人也很重要,但也不能完全依赖于制度和人员。项目组整理了各类主数据规则约239条,并固化到系统里面,帮助于减少数据质量问题,尽量避免发生一些低级的错误。
效益体现
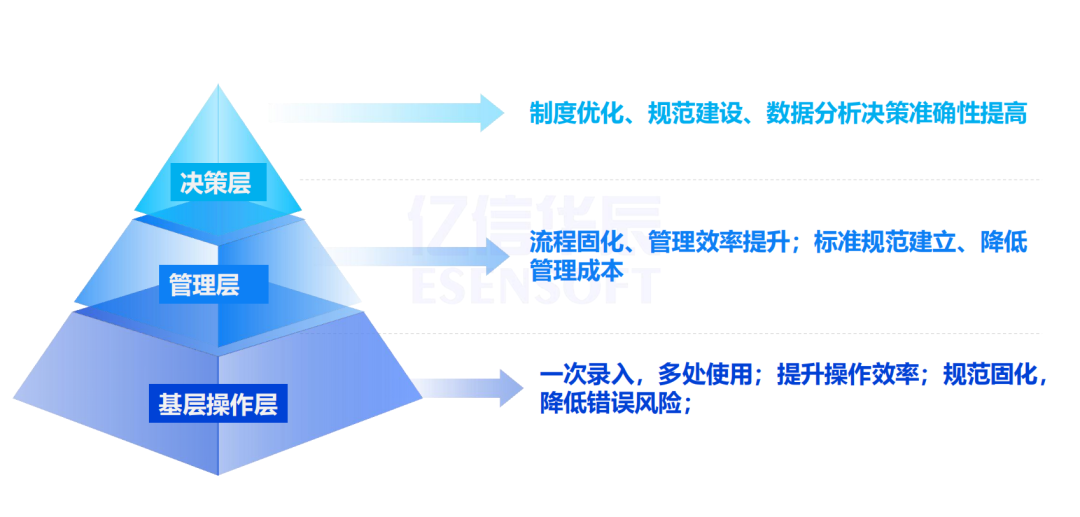
对于最基础的基础的操作人员,实现一次录入,多处使用;提升操作效率;规范固化,降低错误风险。
比如说组织主数据新增或变更一个部门,之前需要马上通知各个业务系统去做组织相应的调整。只要主数据系统里作为变更之后,就会自动同步到各个业务系统的。对于基层操作人员而言,节省了大量的工作量,并且降低了错误率。
对于中层管理层上来讲,实现流程固化、管理效率提升;标准规范建立、降低管理成本。
整个流程在没有上主数据系统之前,没有固化、没有标准化,在管理上还是有障碍的。对于我们标准规范的建立,降低管理成本也是非常重要的。以前要不停地去检查主数据的质量,现在只要经过主数据系统的一个数据,基本上已经解决了一些比较低级的一些错误的问题。
当然对于决策层来说,实现制度优化、规范建设、数据分析决策准确性提高。
项目上线之前决策层总是会对数据提出一些质疑,比如说在集采的时要统计每一个物料的采购以及使用量,像前面提到的像小米椒、小米辣、小米辣椒在系统里采购量可能就变成3个不同采购量了,对真实采购量就变低了。上了主数据管理系统之后,基本上解决了这些问题,统计的数据提高了准确性,解决了在决策上面的数据支撑问题。