回溯/DFS算法专题
- 框架篇
- 全排列问题
- N 皇后问题
- 如果只需要一个合法答案,怎么办?
- 排列组合问题
- 子集(元素无重不可复选)
- LeetCode 78. 子集
- 解题思路
- 代码实现
- 组合(元素无重不可复选)
- LeetCode 77. 组合
- 解题思路
- 代码实现
- 排列(元素无重不可复选)
- LeetCode 46. 全排列
- 解题思路
- 代码实现
- 子集/组合(元素可重不可复选)
- LeetCode 90. 子集 II
- 解题思路
- 代码实现
- LeetCode 40. 组合总和 II
- 解题思路
- 代码实现
- 排列(元素可重不可复选)
- LeetCode 47. 全排列 II
- 解题思路
- 代码实现
- 子集/组合(元素无重可复选)
- LeetCode 39. 组合总和
- 解题思路
- 代码实现
- 排列(元素无重可复选)
- 解题思路
- 代码实现
- 排列组合问题套路
- 总结
不要纠结,干就完事了,熟练度很重要!!!多练习,多总结!!!
框架篇
直接上回溯算法框架。解决一个回溯问题,实际上就是一个决策树的遍历过程。你只需要思考 3 个问题:
- 路径:也就是已经做出的选择。
- 选择列表:也就是你当前可以做的选择。
- 结束条件:也就是到达决策树底层,无法再做选择的条件。
result = []
def backtrack(路径, 选择列表):
if 满足结束条件:
result.add(路径)
return
for 选择 in 选择列表:
做选择
backtrack(路径, 选择列表)
撤销选择
其核心就是 for 循环里面的递归,在递归调用之前「做选择」,在递归调用之后「撤销选择」。
全排列问题
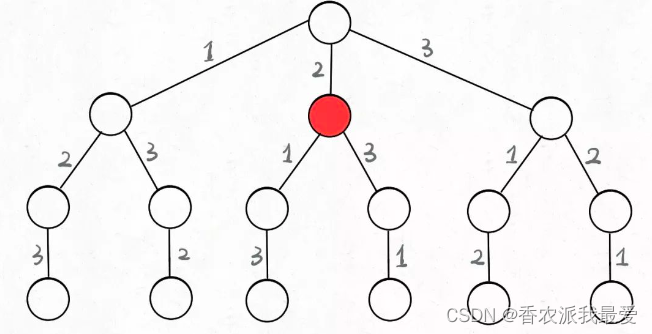
不妨把这棵树称为回溯算法的「决策树」。为啥说这是决策树呢,因为你在每个节点上其实都在做决策。
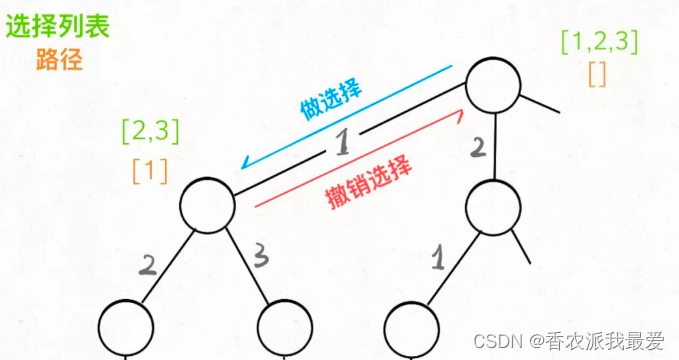
可以选择 1 那条树枝,也可以选择 3 那条树枝。为啥只能在 1 和 3 之中选择呢?因为 2 这个树枝在你身后,这个选择你之前做过了,而全排列是不允许重复使用数字的。
现在可以解答开头的几个名词:[2]就是「路径」,记录你已经做过的选择;[1,3]就是「选择列表」,表示你当前可以做出的选择;「结束条件」就是遍历到树的底层,在这里就是选择列表为空的时候。
如果明白了这几个名词,可以把「路径」和「选择列表」作为决策树上每个节点的属性,比如下图列出了几个节点的属性:
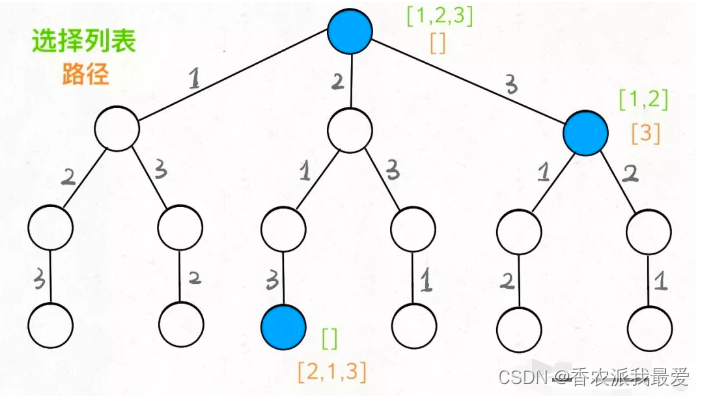
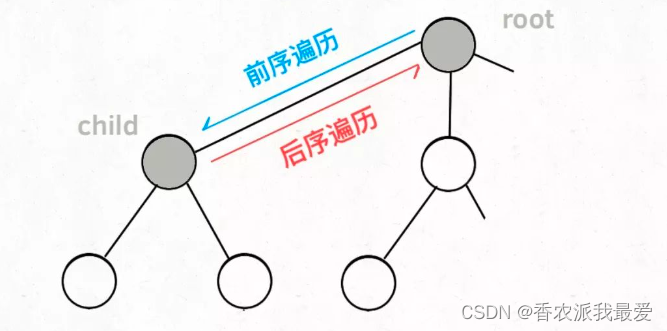
前序遍历的代码在进入某一个节点之前的那个时间点执行,后序遍历代码在离开某个节点之后的那个时间点执行。
回想我们刚才说的,「路径」和「选择」是每个节点的属性,函数在树上游走要正确维护节点的属性,那么就要在这两个特殊时间点搞点动作:
List<List<Integer>> res = new LinkedList<>();
/* 主函数,输入一组不重复的数字,返回它们的全排列 */
List<List<Integer>> permute(int[] nums) {
// 记录「路径」
LinkedList<Integer> track = new LinkedList<>();
backtrack(nums, track);
return res;
}
// 路径:记录在 track 中
// 选择列表:nums 中不存在于 track 的那些元素
// 结束条件:nums 中的元素全都在 track 中出现
void backtrack(int[] nums, LinkedList<Integer> track) {
// 触发结束条件
if (track.size() == nums.length) {
res.add(new LinkedList(track));
return;
}
for (int i = 0; i < nums.length; i++) {
// 排除不合法的选择
if (track.contains(nums[i]))
continue;
// 做选择
track.add(nums[i]);
// 进入下一层决策树
backtrack(nums, track);
// 取消选择
track.removeLast();
}
}
必须说明的是,不管怎么优化,都符合回溯框架,而且时间复杂度都不可能低于 O(N!),因为穷举整棵决策树是无法避免的。这也是回溯算法的一个特点,不像动态规划存在重叠子问题可以优化,回溯算法就是纯暴力穷举,复杂度一般都很高。
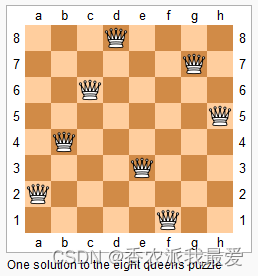
N 皇后问题
给你一个 N×N 的棋盘,让你放置 N 个皇后,使得它们不能互相攻击。
(皇后可以攻击同一行、同一列、左上左下右上右下四个方向的任意单位)
vector<vector<string>> res;
/* 输入棋盘边长 n,返回所有合法的放置 */
vector<vector<string>> solveNQueens(int n) {
// '.' 表示空,'Q' 表示皇后,初始化空棋盘。
vector<string> board(n, string(n, '.'));
backtrack(board, 0);
return res;
}
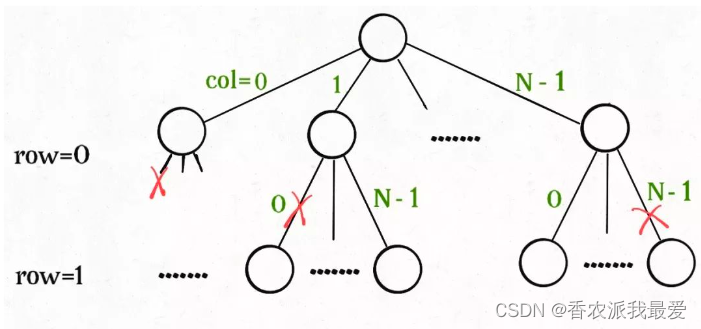
// 路径:board 中小于 row 的那些行都已经成功放置了皇后
// 选择列表:第 row 行的所有列都是放置皇后的选择
// 结束条件:row 超过 board 的最后一行
void backtrack(vector<string>& board, int row) {
// 触发结束条件
if (row == board.size()) {
res.push_back(board);
return;
}
int n = board[row].size();
for (int col = 0; col < n; col++) {
// 排除不合法选择
if (!isValid(board, row, col))
continue;
// 做选择
board[row][col] = 'Q';
// 进入下一行决策
backtrack(board, row + 1);
// 撤销选择
board[row][col] = '.';
}
}
/* 是否可以在 board[row][col] 放置皇后? */
bool isValid(vector<string>& board, int row, int col) {
int n = board.size();
// 检查列是否有皇后互相冲突
for (int i = 0; i < n; i++) {
if (board[i][col] == 'Q')
return false;
}
// 检查右上方是否有皇后互相冲突
for (int i = row - 1, j = col + 1;
i >= 0 && j < n; i--, j++) {
if (board[i][j] == 'Q')
return false;
}
// 检查左上方是否有皇后互相冲突
for (int i = row - 1, j = col - 1;
i >= 0 && j >= 0; i--, j--) {
if (board[i][j] == 'Q')
return false;
}
return true;
}
函数backtrack依然像个在决策树上游走的指针,每个节点就表示在board[row][col]上放置皇后,通过isValid函数可以将不符合条件的情况剪枝:
如果只需要一个合法答案,怎么办?
// 函数找到一个答案后就返回 true
bool backtrack(vector<string>& board, int row) {
// 触发结束条件
if (row == board.size()) {
res.push_back(board);
return true;
}
...
for (int col = 0; col < n; col++) {
...
board[row][col] = 'Q';
if (backtrack(board, row + 1))
return true;
board[row][col] = '.';
}
return false;
}
排列组合问题
无论是排列、组合还是子集问题,简单说无非就是让你从序列nums中以给定规则取若干元素,主要有以下几种变体:
-
形式一、元素无重不可复选,即nums中的元素都是唯一的,每个元素最多只能被使用一次,这也是最基本的形式。
以组合为例,如果输入nums = [2,3,6,7],和为 7 的组合应该只有[7]。 -
形式二、元素可重不可复选,即nums中的元素可以存在重复,每个元素最多只能被使用一次。
以组合为例,如果输入nums = [2,5,2,1,2],和为 7 的组合应该有两种[2,2,2,1]和[5,2]。 -
形式三、元素无重可复选,即nums中的元素都是唯一的,每个元素可以被使用若干次。
以组合为例,如果输入nums = [2,3,6,7],和为 7 的组合应该有两种[2,2,3]和[7]。
除此之外,题目也可以再添加各种限制条件,比如让你求和为target且元素个数为k的组合。
但无论形式怎么变化,其本质就是穷举所有解,而这些解呈现树形结构,所以合理使用回溯算法框架,稍改代码框架即可把这些问题一网打尽。
子集/组合问题的回溯树

排列问题的回溯树

首先,组合问题和子集问题其实是等价的,这个后面会讲;至于之前说的三种变化形式,无非是在这两棵树上剪掉或者增加一些树枝罢了。
子集(元素无重不可复选)
LeetCode 78. 子集

解题思路
因为集合中的元素不用考虑顺序,[1,2,3]中2后面只有3,如果你向前考虑1,那么[2,1]会和之前已经生成的子集[1,2]重复。
换句话说,我们通过保证元素之间的相对顺序不变来防止出现重复的子集。
如果把根节点作为第 0 层,将每个节点和根节点之间树枝上的元素作为该节点的值,那么第n层的所有节点就是大小为n的所有子集。
比如大小为 2 的子集就是这一层节点的值:

代码实现
class Solution {
List<List<Integer>> res = new LinkedList<>();
LinkedList<Integer> track = new LinkedList<>();
public List<List<Integer>> subsets(int[] nums) {
backtrack(nums, 0);
return res;
}
public void backtrack(int[] nums, int start){
res.add(new LinkedList<>(track));
for(int i = start; i < nums.length;i++){
track.addLast(nums[i]);
backtrack(nums, i+1);
track.removeLast();
}
}
}
组合(元素无重不可复选)
LeetCode 77. 组合

解题思路
组合和子集是一样的:大小为k的组合就是大小为k的子集。
以nums = [1,2,3]为例,刚才让你求所有子集,就是把所有节点的值都收集起来;现在你只需要把第 2 层(根节点视为第 0 层)的节点收集起来,就是大小为 2 的所有组合:

代码实现
class Solution {
List<List<Integer>> res = new LinkedList<>();
LinkedList<Integer> track = new LinkedList<>();
public List<List<Integer>> combine(int n, int k) {
backtrack(n, 1, k);
return res;
}
public void backtrack(int n, int start, int k){
if(track.size() == k){
res.add(new LinkedList<>(track));
}
for(int i = start;i <= n;i++){
track.addLast(i);
backtrack(n, i+1, k);
track.removeLast();
}
}
}
排列(元素无重不可复选)
LeetCode 46. 全排列

解题思路
排列问题的本质就是穷举元素的位置,nums[i]之后也可以出现nums[i]左边的元素,所以之前的那一套玩不转了,需要额外使用used数组来标记哪些元素还可以被选择。

代码实现
class Solution {
List<List<Integer>> res = new LinkedList<>();
LinkedList<Integer> track = new LinkedList<>();
boolean[] used;
public List<List<Integer>> permute(int[] nums) {
used = new boolean[nums.length];
backtrack(nums);
return res;
}
public void backtrack(int[] nums){
if(track.size() == nums.length){
res.add(new LinkedList<>(track));
}
for(int i = 0; i < nums.length;i++){
if(used[i]){
continue;
}
track.addLast(nums[i]);
used[i] = true;
backtrack(nums);
track.removeLast();
used[i] = false;
}
}
}
子集/组合(元素可重不可复选)
LeetCode 90. 子集 II

解题思路
以nums = [1,2,2]为例,为了区别两个2是不同元素,后面我们写作nums = [1,2,2’]。

需要进行剪枝,如果一个节点有多条值相同的树枝相邻,则只遍历第一条,剩下的都剪掉,不要去遍历:

体现在代码上,需要先进行排序,让相同的元素靠在一起,如果发现nums[i] == nums[i-1],则跳过。
代码实现
class Solution {
List<List<Integer>> res = new LinkedList<>();
LinkedList<Integer> track = new LinkedList<>();
public List<List<Integer>> subsetsWithDup(int[] nums) {
Arrays.sort(nums);
backtrack(nums, 0);
return res;
}
public void backtrack(int[] nums, int start){
res.add(new LinkedList<>(track));
for(int i = start; i < nums.length;i++){
if(i > start && nums[i] == nums[i-1]){
continue;
}
track.addLast(nums[i]);
backtrack(nums, i+1);
track.removeLast();
}
}
}
LeetCode 40. 组合总和 II

解题思路
说了组合问题和子集问题是等价的,给你输入candidates和一个目标和target,从candidates中找出中所有和为target的组合。candidates可能存在重复元素,且其中的每个数字最多只能使用一次。
对比子集问题的解法,只要额外用一个trackSum变量记录回溯路径上的元素和,然后将 base case 改一改即可解决这道题。
代码实现
class Solution {
List<List<Integer>> res = new LinkedList<>();
LinkedList<Integer> track = new LinkedList<>();
int sum = 0;
public List<List<Integer>> combinationSum2(int[] candidates, int target) {
Arrays.sort(candidates);
if(candidates.length == 0){
return null;
}
backtrack(candidates, 0, target);
return res;
}
public void backtrack(int[] nums, int start, int target){
if(sum == target){
res.add(new LinkedList<>(track));
}
if(sum > target){
return;
}
for(int i = start;i < nums.length;i++){
if(i > start && nums[i] == nums[i-1]){
continue;
}
sum+=nums[i];
track.addLast(nums[i]);
backtrack(nums, i+1, target);
sum-=nums[i];
track.removeLast();
}
}
}
排列(元素可重不可复选)
LeetCode 47. 全排列 II

解题思路
假设输入为nums = [1,2,2’],标准的全排列算法会得出如下答案:
[1,2,2'],[1,2',2],
[2,1,2'],[2,2',1],
[2',1,2],[2',2,1]
这个结果存在重复,比如[1,2,2’]和[1,2’,2]应该只被算作同一个排列,但被算作了两个不同的排列。
如何设计剪枝逻辑,把这种重复去除掉?
答案是,保证相同元素在排列中的相对位置保持不变。
标准全排列算法之所以出现重复,是因为把相同元素形成的排列序列视为不同的序列,但实际上它们应该是相同的;而如果固定相同元素形成的序列顺序,当然就避免了重复。
// 新添加的剪枝逻辑,固定相同的元素在排列中的相对位置
if (i > 0 && nums[i] == nums[i - 1] && !used[i - 1]) {
// 如果前面的相邻相等元素没有用过,则跳过
continue;
}
// 选择 nums[i]
[关键思路]当出现重复元素时,比如输入nums = [1,2,2’,2’‘],2’只有在2已经被使用的情况下才会被选择,2’'只有在2’已经被使用的情况下才会被选择,这就保证了相同元素在排列中的相对位置保证固定。
代码实现
class Solution {
List<List<Integer>> res = new LinkedList<>();
LinkedList<Integer> track = new LinkedList<>();
boolean[] used;
public List<List<Integer>> permuteUnique(int[] nums) {
used = new boolean[nums.length];
Arrays.sort(nums);
backtrack(nums);
return res;
}
public void backtrack(int[] nums){
if(nums.length == track.size()){
res.add(new LinkedList<>(track));
return;
}
for(int i = 0; i < nums.length;i++){
if(used[i]){
continue;
}
if(i > 0 && nums[i] == nums[i-1] && !used[i-1]){
continue;
}
track.addLast(nums[i]);
used[i] = true;
backtrack(nums);
track.removeLast();
used[i] = false;
}
}
}
子集/组合(元素无重可复选)
LeetCode 39. 组合总和

解题思路
先思考思考,标准的子集/组合问题是如何保证不重复使用元素的?
// 回溯算法标准框架
for (int i = start; i < nums.length; i++) {
// ...
// 递归遍历下一层回溯树,注意参数
backtrack(nums, i + 1, target);
// ...
}
这个i从start开始,那么下一层回溯树就是从start + 1开始,从而保证nums[start]这个元素不会被重复使用:

如果我想让每个元素被重复使用,我只要把i + 1改成i即可:
// 回溯算法标准框架
for (int i = start; i < nums.length; i++) {
// ...
// 递归遍历下一层回溯树
backtrack(nums, i, target);
// ...
}
这相当于给之前的回溯树添加了一条树枝,在遍历这棵树的过程中,一个元素可以被无限次使用:

代码实现
class Solution {
List<List<Integer>> res = new LinkedList<>();
LinkedList<Integer> track = new LinkedList<>();
int sum = 0;
public List<List<Integer>> combinationSum(int[] candidates, int target) {
Arrays.sort(candidates);
backtrack(candidates, 0, target);
return res;
}
public void backtrack(int[] nums, int start, int target){
if(sum == target){
res.add(new LinkedList<>(track));
return;
}
if(sum > target){
return;
}
for(int i = start;i < nums.length;i++){
sum+=nums[i];
track.addLast(nums[i]);
backtrack(nums, i, target);
sum-=nums[i];
track.removeLast();
}
}
}
排列(元素无重可复选)
比如输入nums = [1,2,3],那么这种条件下的全排列共有 3^3 = 27 种:
[1,1,1],[1,1,2],[1,1,3],[1,2,1],[1,2,2],[1,2,3],[1,3,1],[1,3,2],[1,3,3],
[2,1,1],[2,1,2],[2,1,3],[2,2,1],[2,2,2],[2,2,3],[2,3,1],[2,3,2],[2,3,3],
[3,1,1],[3,1,2],[3,1,3],[3,2,1],[3,2,2],[3,2,3],[3,3,1],[3,3,2],[3,3,3]
解题思路
标准的全排列算法利用used数组进行剪枝,避免重复使用同一个元素。如果允许重复使用元素的话,直接放飞自我,去除所有used数组的剪枝逻辑就行了。
代码实现
class Solution {
List<List<Integer>> res = new LinkedList<>();
LinkedList<Integer> track = new LinkedList<>();
public List<List<Integer>> permuteRepeat(int[] nums) {
backtrack(nums);
return res;
}
// 回溯算法核心函数
public void backtrack(int[] nums) {
// base case,到达叶子节点
if (track.size() == nums.length) {
// 收集叶子节点上的值
res.add(new LinkedList(track));
return;
}
// 回溯算法标准框架
for (int i = 0; i < nums.length; i++) {
// 做选择
track.add(nums[i]);
// 进入下一层回溯树
backtrack(nums);
// 取消选择
track.removeLast();
}
}
}
排列组合问题套路
- 形式一、元素无重不可复选,即nums中的元素都是唯一的,每个元素最多只能被使用一次,backtrack核心代码如下:
/* 组合/子集问题回溯算法框架 */
void backtrack(int[] nums, int start) {
// 回溯算法标准框架
for (int i = start; i < nums.length; i++) {
// 做选择
track.addLast(nums[i]);
// 注意参数
backtrack(nums, i + 1);
// 撤销选择
track.removeLast();
}
}
/* 排列问题回溯算法框架 */
void backtrack(int[] nums) {
for (int i = 0; i < nums.length; i++) {
// 剪枝逻辑
if (used[i]) {
continue;
}
// 做选择
used[i] = true;
track.addLast(nums[i]);
backtrack(nums);
// 取消选择
track.removeLast();
used[i] = false;
}
}
- 形式二、元素可重不可复选,即nums中的元素可以存在重复,每个元素最多只能被使用一次,其关键在于排序和剪枝,backtrack核心代码如下:
Arrays.sort(nums);
/* 组合/子集问题回溯算法框架 */
void backtrack(int[] nums, int start) {
// 回溯算法标准框架
for (int i = start; i < nums.length; i++) {
// 剪枝逻辑,跳过值相同的相邻树枝
if (i > start && nums[i] == nums[i - 1]) {
continue;
}
// 做选择
track.addLast(nums[i]);
// 注意参数
backtrack(nums, i + 1);
// 撤销选择
track.removeLast();
}
}
Arrays.sort(nums);
/* 排列问题回溯算法框架 */
void backtrack(int[] nums) {
for (int i = 0; i < nums.length; i++) {
// 剪枝逻辑
if (used[i]) {
continue;
}
// 剪枝逻辑,固定相同的元素在排列中的相对位置
if (i > 0 && nums[i] == nums[i - 1] && !used[i - 1]) {
continue;
}
// 做选择
used[i] = true;
track.addLast(nums[i]);
backtrack(nums);
// 取消选择
track.removeLast();
used[i] = false;
}
}
- 形式三、元素无重可复选,即nums中的元素都是唯一的,每个元素可以被使用若干次,只要删掉去重逻辑即可,backtrack核心代码如下:
/* 组合/子集问题回溯算法框架 */
void backtrack(int[] nums, int start) {
// 回溯算法标准框架
for (int i = start; i < nums.length; i++) {
// 做选择
track.addLast(nums[i]);
// 注意参数
backtrack(nums, i);
// 撤销选择
track.removeLast();
}
}
/* 排列问题回溯算法框架 */
void backtrack(int[] nums) {
for (int i = 0; i < nums.length; i++) {
// 做选择
track.addLast(nums[i]);
backtrack(nums);
// 取消选择
track.removeLast();
}
}
总结
本题来源于Leetcode中 归属于回溯/DFS算法类型题目。
同许多在算法道路上不断前行的人一样,不断练习,修炼自己!
如有博客中存在的疑问或者建议,可以在下方留言一起交流,感谢各位!
觉得本博客有用的客官,可以给个点赞+收藏哦! 嘿嘿
喜欢本系列博客的可以关注下,以后除了会继续更新面试手撕代码文章外,还会出其他系列的文章!