【图像抠图】【深度学习】Ubuntu18.04下GFM官方代码Pytorch实现
提示:最近开始在【图像抠图】方面进行研究,记录相关知识点,分享学习中遇到的问题已经解决的方法。
文章目录
- 【图像抠图】【深度学习】Ubuntu18.04下GFM官方代码Pytorch实现
- 前言
- 数据集说明
- 1.AM-2k【自然动物】
- 2.BG-20k【背景】
- GFM模型运行
- 下载源码并安装环境
- 下载数据集
- 训练AM-2k
- 测试AM-2k
- 测试个人数据集
- 总结
前言
GFM是由悉尼大学的Li J, Zhang J等人在《Bridging Composite and Real: Towards End-to-end Deep Image Matting [IJCV-2022]》【论文地址】一文中提出的模型,研究了语义和细节对图像抠图的不同作用,并将任务分解为两个并行的子任务:高级语义分割和低级细节抠图。
在详细解析GFM网络之前,首要任务是搭建GFM【Pytorch-demo地址】所需的运行环境,并模型完成训练和测试工作,展开后续工作才有意义。
数据集说明
1.AM-2k【自然动物】
AM-2k包含来自 20 个类别的 2,000 张高分辨率自然动物图像以及手动标记的 alpha 遮罩。
百度云链接【提取码:29r1】:
2.BG-20k【背景】
BG-20k包含 20,000 张排除显着物体的高分辨率背景图像,可用于帮助生成高质量的合成数据。
百度云链接【提取码:dffp】:
GFM模型运行
用docker搭建Ubuntu18.04的朋友查看这里
下载源码并安装环境
在Ubuntu18.04环境下装anaconda环境,方便搭建专用于PointNet模型的虚拟环境。
【Pytorch-教程】
# 创建虚拟环境
conda create -n gfm python=3.7.7
# 查看新环境是否安装成功
conda env list
# 激活环境
conda activate gfm
# 下载githup源代码到合适文件夹,并cd到代码文件夹内
git clone https://github.com/JizhiziLi/GFM.git
cd GFM
# 通过清华源,下载所需的第三方包
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt
# 分别安装pytorch和torchvision
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu117
# 查看所有安装的包
pip list
conda list
最终的安装的所有包。

检查torch版,已经安装torch-gpu版本
# 查看pytorch版本
import torch
print(torch.__version__)
# 查看cuda版本
print(torch.version.cuda)
# 查看cuda是否可用
print(torch.cuda.is_available())
# 查看可用cuda数量
print(torch.cuda.device_count())

下载数据集
下载以下五个数据集(本人放置在Documents/目录下,方便学习其他模型共用数据集)
【AM-2k,提取码:29r1】
【BG-20k,提取码:dffp】
【MS COCO/train ,提取码:gi5l 】
【am2k_fg_denoise】
【bg20k_train_denoise】
# 看情况挨个或者全部一起移动到Documents/目录下
sudo mv am2k_fg_denoise.zip /root/Documents/
sudo mv *.zip /root/Documents/
cd /root/Documents/
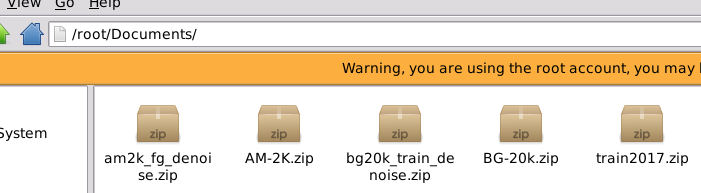
解压五个数据集
# 看情况挨个或者全部一起解压文件
sudo unzip am2k_fg_denoise.zip
ls *.zip | xargs -n1 unzip
AM-2k数据集结构

BG-20k数据集结构

MS COCO/train数据集结构
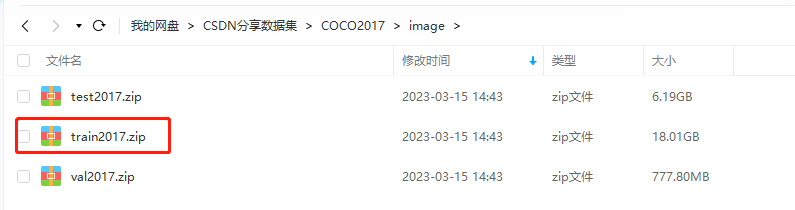

这和分别是AM-2k和BG-20k的噪声训练图片,根据上图,是要对应加入到和train目录下的。
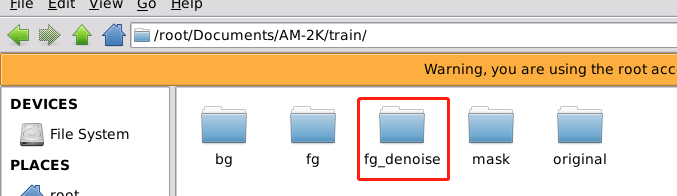
am2k_fg_denoise移动到AM-2k/train目录下并重命名为fg_denoise:

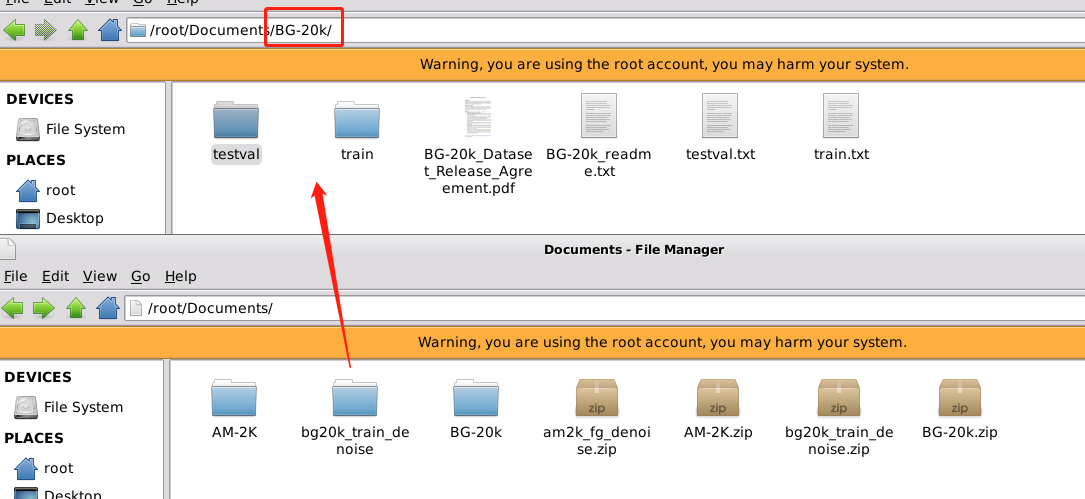
bg20k_train_denoise移动到BG-20k/目录下并重命名为train_denoise:
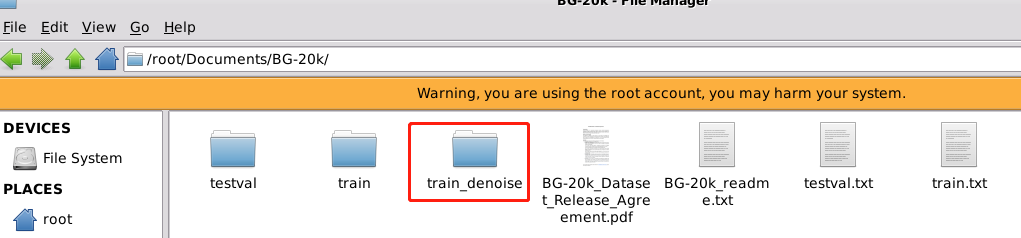
设置"GFM/core/config.py"

训练AM-2k
# 在GFM目录下执行命令,设置sh文件执行权限
chmod +x scripts/train/*
# 源码提供了五种不同训练
# Train on the ORI-Track
./scripts/train/train_ori.sh # 1
./scripts/train/train_ori_easier.sh # 2
# Train on the COMP-Track
./scripts/train/train_hd_rssn.sh # 3
./scripts/train/train_hd_rssn_easier.sh # 4
./scripts/train/train_coco.sh # 5
关于几种训练方式区别和用途,博主会在学习研究了论文和代码之后再作出自己的讲解。
这里以train_ori.sh为例,train_ori.sh文件内容
batchsizePerGPU=32
GPUNum=1
batchsize=`expr $batchsizePerGPU \* $GPUNum`
backbone='r34'
rosta='TT'
bg_choice='original'
fg_generate='closed_form'
nEpochs=5
lr=0.00001
threads=8
nickname=gfm_ori_track
python core/train.py \
--logname=$nickname \
--backbone=$backbone \
--rosta=$rosta \
--batchSize=$batchsize \
--nEpochs=$nEpochs \
--lr=$lr \
--threads=$threads \
--bg_choice=$bg_choice \
--fg_generate=$fg_generate \
--model_save_dir=models/trained/$nickname/ \
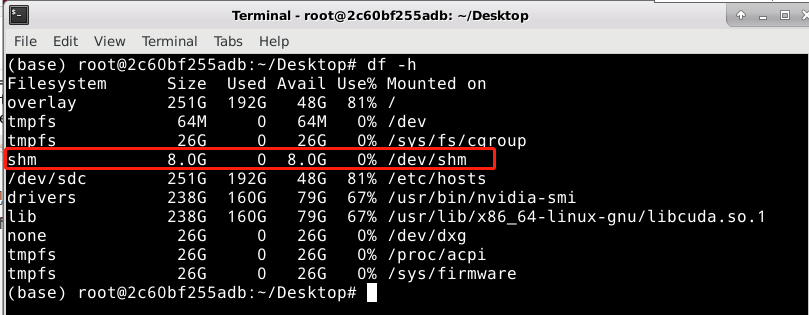
使用docker可能出现的错误"ERROR: Unexpected bus error encountered in worker. This might be caused by insufficient shared memory (shm)"表示共享内存不够了。
# 查看磁盘
df -h

博主容器的shared memory默认只有64MB。但训练程序中,DataLoader设置的threads(线程,也经常写作workers)数目比较多,该程序中为8,这些workers通过共享内存进行协作,导致默认的共享内存不够用。
解决方法:
- 将threads数量降低,例如设置threads=0;
- 将容器的共享内存加大,可通过–ipc=host或–shm-size进行设置。【推荐】
注:windows系统下的docker操作比较操蛋,不能更改容器的设置(有知道的朋友欢迎在评论区指导),只有创建容器时才能设置,为了保存容器的内容,因此建议曲线救国,先将容器制作成镜像,再用镜像重新新建容器。
【docker常用指令】
# 制作镜像
docker commit container_id image_name:tag
# eg: docker commit 2c60bf255adb deeplearn:1.0
# 创建容器(gpu版本)
docker run -it --shm-size 8g --gpus all --name container_name -p 5900:5900 -p 22:22 -d image_name:tag
# eg: docker run -it --shm-size 8g --gpus all --name Pytorch_for_ImageMatting_ubu18 -p 5900:5900 -p 22:22 -d deeplearn:1.0
重新新建容器后查看磁盘可以看到shared memory已经修改成了8g:
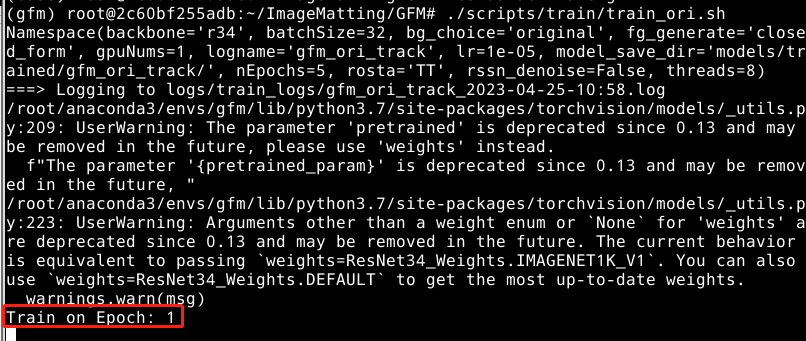
开始训练:
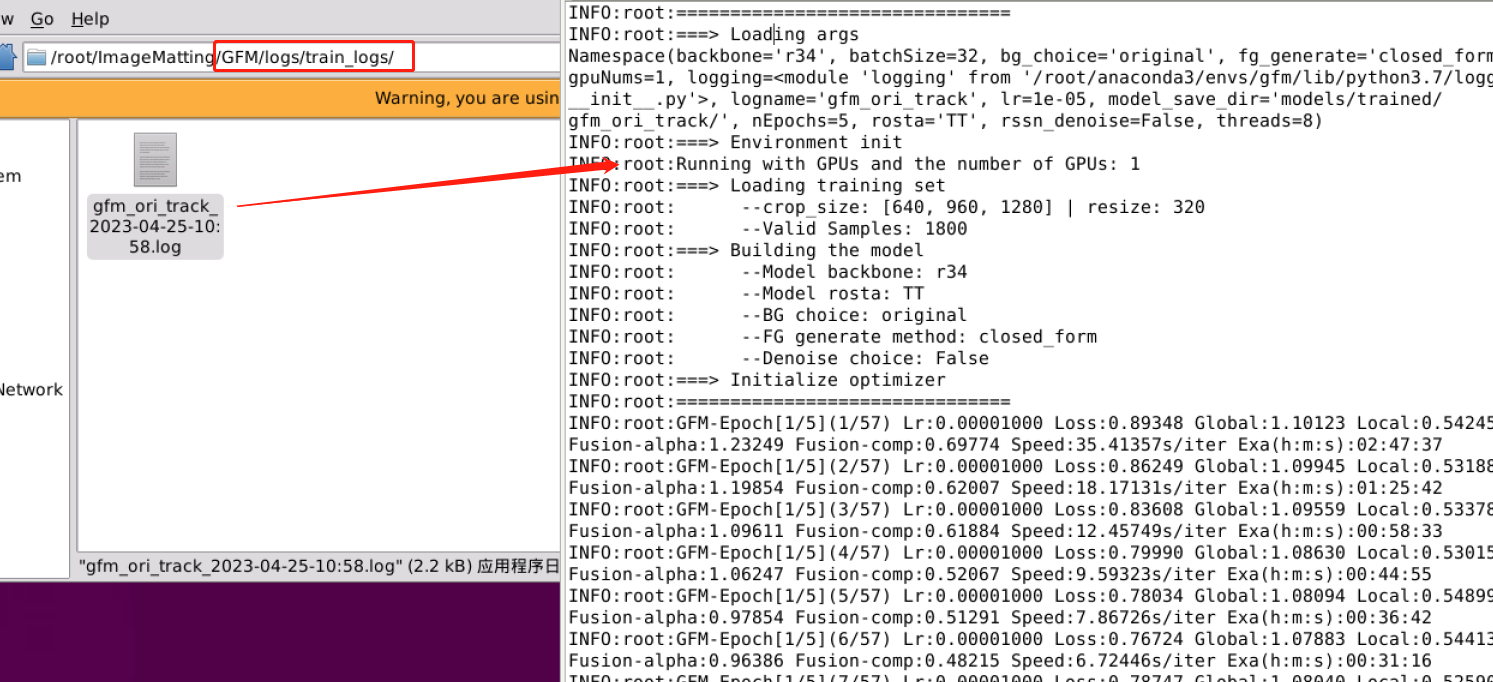
训练的详细数据保存在logs/train_logs/目录下的日志文件中:
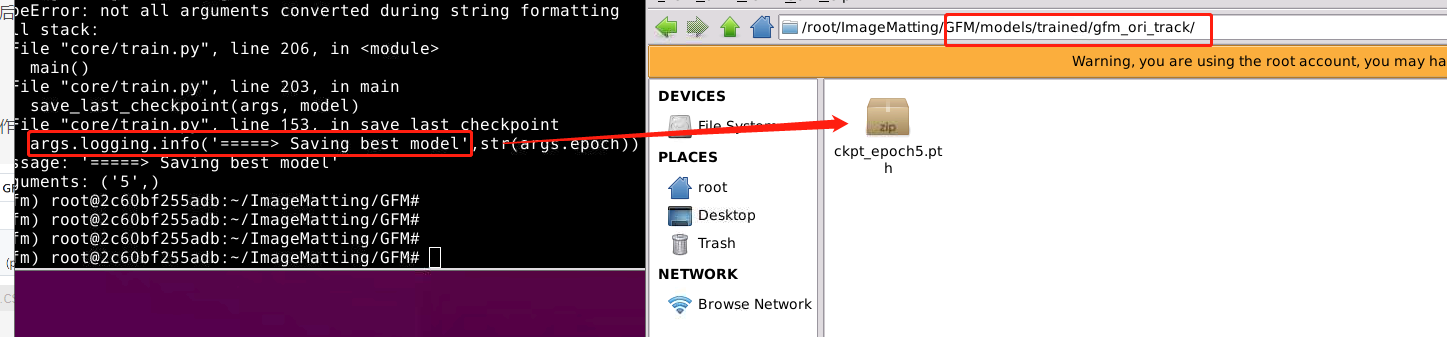
源码作者只保存最后一次的模型权重(博主epoch仅设为5,方便讲解):
测试AM-2k
博主这里使用源码作者提供的预训练权重(Train on the ORI-Track )作为测试

# 在GFM目录下执行命令,设置sh文件执行权限
chmod +x scripts/test/*
# 测试
./scripts/test/test_dataset.sh
预训练模型的权重与test_dataset.sh的配置要对应
test_dataset.sh文件内容
backbone='r34'
rosta='TT'
model_path='models/pretrained/gfm_r34_tt.pth'
dataset_choice='AM_2K'
test_choice='HYBRID'
pred_choice=3
test_result_dir='results/am2k_gfm_r34_tt/'
nickname='am2k_gfm_r34_tt'
python core/test.py \
--cuda \
--backbone=$backbone \
--rosta=$rosta \
--model_path=$model_path \
--test_choice=$test_choice \
--dataset_choice=$dataset_choice \
--pred_choice=$pred_choice \
--test_result_dir=$test_result_dir \
--logname=$nickname \
开始测试:

测试的详细数据保存在logs/test_logs/目录下的日志文件中,这里还得自己创建test_logs目录:
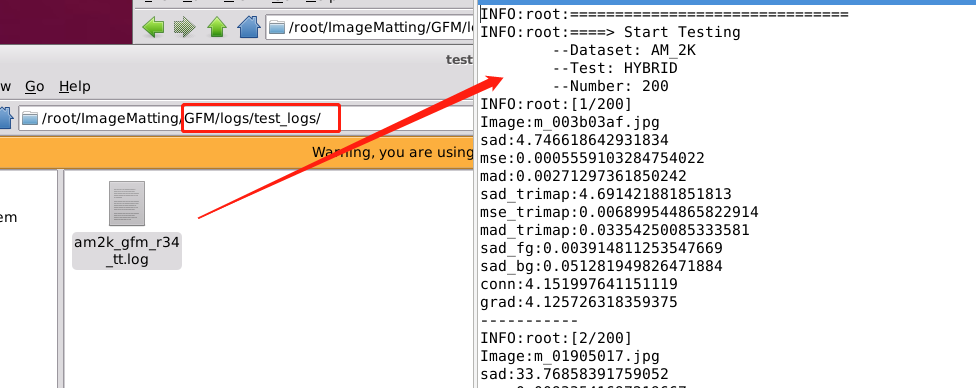
测试结果:

测试个人数据集
博主这里还是使用源码作者提供的预训练权重(Train on the ORI-Track )作为测试。
# 测试
./scripts/test/test_samples.sh
预训练模型的权重与test_samples.sh的配置要对应
test_samples.sh文件内容
backbone='r34'
rosta='TT'
model_path='models/pretrained/gfm_r34_tt.pth'
dataset_choice='SAMPLES'
test_choice='HYBRID'
pred_choice=3
python core/test.py \
--cuda \
--backbone=$backbone \
--rosta=$rosta \
--model_path=$model_path \
--test_choice=$test_choice \
--dataset_choice=$dataset_choice \
--pred_choice=$pred_choice \
将自己的数据集保存在samples/original/目录下,执行命令生成目标的alpha和彩色图。
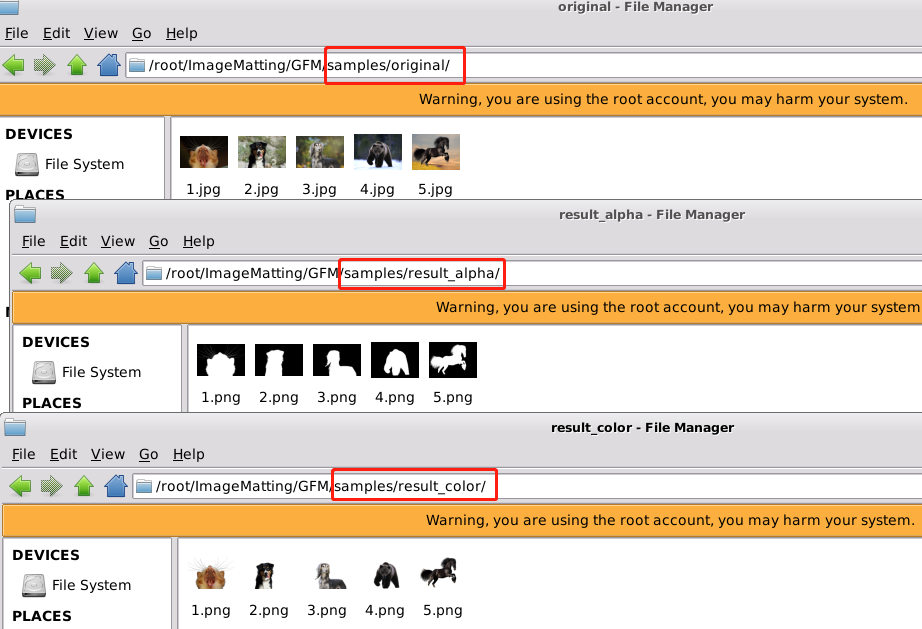
总结
尽可能简单、详细的介绍GFM的安装流程以及解决了安装过程中可能存在的问题。后续会根据自己学到的知识结合个人理解讲解GFM的原理和代码。