Kafka强依赖ZK,如果想要使用Kafka,就必须安装ZK,Kafka中的消费偏置信息、kafka集群、topic信息会被存储在ZK中。有人可能会说我在使用Kafka的时候就没有安装ZK,那是因为Kafka内置了一个ZK,一般我们不使用它。
部署说明
本文使用kafka单节点安装及配置,并使用kafka自带的zookeeper。一般kafka需要起三个kafka构成集群,可以连单独的zookeeper,本文不涉及。
kafka下载
根据需要下载对应版本的安装包,下载地址:
https://archive.apache.org/dist/kafka/
上传安装包并解压重命名(路径自定义):
如:上传到 /opt 路径下
解压和重命名:
cd opt
tar -zxvf kafka_2.12-2.5.0.tgz
mv kafka_2.12-2.5.0 kafka
修改zookeeper配置
vim kafka/config/zookeeper.properties
dataDir=/opt/kafka
# the port at which the clients will connect
clientPort=2181
# disable the per-ip limit on the number of connections since this is a non-production config
maxClientCnxns=100
# Disable the adminserver by default to avoid port conflicts.
# Set the port to something non-conflicting if choosing to enable this
admin.enableServer=false
# admin.serverPort=8080
修改kafka配置
vim kafka/config/server.properties
broker.id=0
listeners=PLAINTEXT://192.168.1.1:9092
advertised.listeners=PLAINTEXT://192.168.1.1:9092
log.dirs=/opt/kafka/kafka-logs
zookeeper.connect=192.168.1.1:2181
# 本机ip
host.name=192.168.1.1
启动zookeeper
./zookeeper-server-start.sh ../config/zookeeper.properties &
启动kafka
./kafka-server-start.sh ../config/server.properties &
第二种
Kafka 单节点部署
下载安装
下载Zookeeper并解压到指定目录
ZooKeeper官网:http://zookeeper.apache.org/
[root@spark1 soft]# tar -zxvf zookeeper-3.4.5.tar.gz -C /application/配置ZK
配置zoo.cfg
拷贝zoo_sample.cfg文件重命名为zoo.cfg,然后修改dataDir属性
[root@spark1 soft]# cd /application/zookeeper-3.4.5/conf/
[root@spark1 conf]# cat zoo.cfg
....
# 数据的存放目录
dataDir=/application/zookeeper-3.4.5/data
# 端口,默认就是2181
clientPort=2181
....
[root@spark1 conf]# 配置环境变量
[root@spark1 ~]# cat /etc/profile
......
#ZooKeeper环境变量
export ZOOKEEPER_HOME=/application/zookeeper-3.4.5
export PATH=$PATH:$ZOOKEEPER_HOME/bin
......Zookeeper 启动停止命令
$ zkServer.sh start
$ zkServer.sh stopKafka 单节点单Broker部署及使用
部署架构

安装Kafka
Apache Kafka
tar -zxvf kafka_2.10-0.10.2.1.tgz -C /application/
#然后分别在各机器上创建软连
cd /application/
ln -s kafka_2.10-0.10.2.1 kafka说明:
1)版本最好注意下;在Java调用kafka的时候可能有问题就是版本造成的;
配置Kafka
配置server.properties
进入kafka的config目录下,有一个server.properties,添加如下配置
# broker的全局唯一编号,不能重复
broker.id=0
#这个最好配置,否则Java调用报错
advertised.listeners=PLAINTEXT://192.168.2.1:9092
# 日志目录
log.dirs=/application/kafka/logs/kafka-logs
# 配置zookeeper的连接(如果不是本机,需要该为ip或主机名)
zookeeper.connect=localhost:2181启动Kafka
启动Zookeeper
zkServer.sh start启动Kafka
[root@spark1 application]# /application/kafka/bin/kafka-server-start.sh /application/kafka/config/server.properties后台启动
nohup /application/kafka/bin/kafka-server-start.sh /application/kafka/config/server.properties & 创建topic
[root@spark1 ~]# /application/kafka/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
Created topic "test".
[root@spark1 ~]# 说明:
1)--zookeeper:指定kafka连接zk的连接url,该值和server.properties文件中的配置项{zookeeper.connect}一样
2)--replication-factor:指定副本数量
3)--partitions:指定分区数量
4)--topic:主题名称
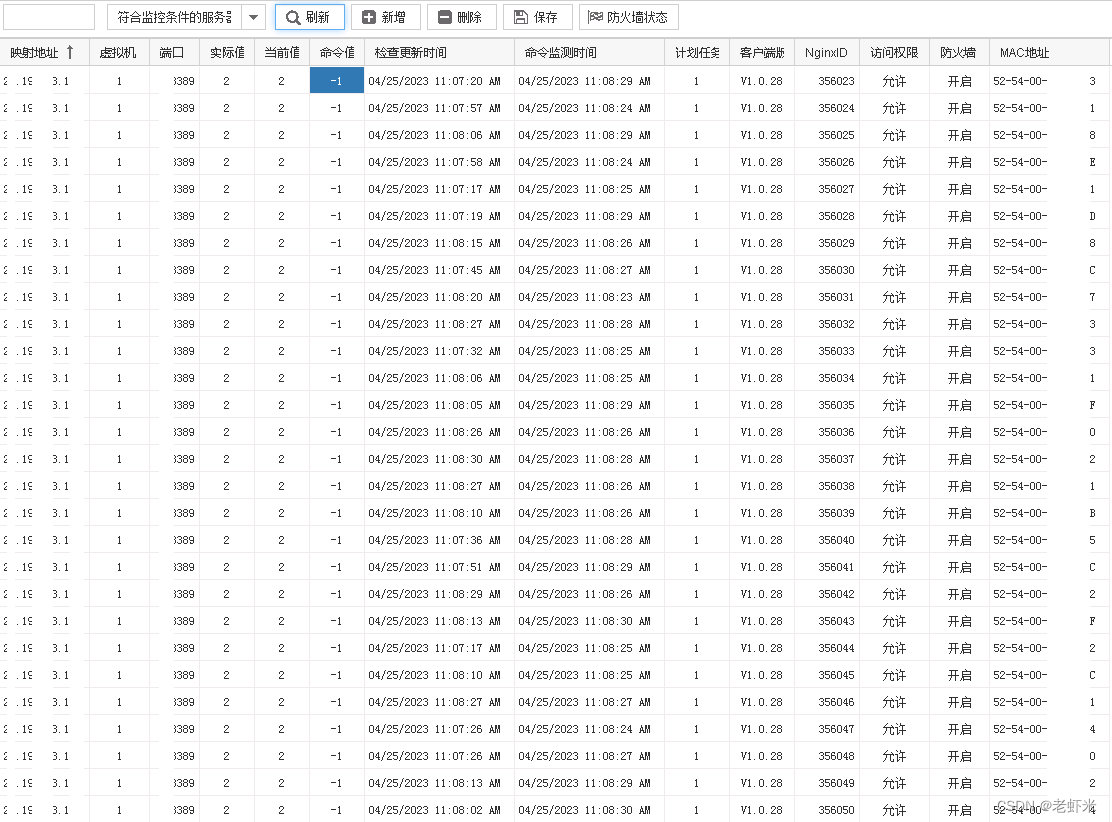
查看所有的topic信息
[root@spark1 ~]# /application/kafka/bin/kafka-topics.sh --list --zookeeper localhost:2181
TestTopic
WordCount
test
[root@spark1 ~]# 启动生产者
[root@spark1 ~]# /application/kafka/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test启动消费者
[root@spark1 ~]# /application/kafka/bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning0.90版本之后启动消费者的方法:
[root@spark1 ~]# /application/kafka/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic productscanlog --from-beginning测试
产者生产数据
[root@spark1 ~]# /application/kafka/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
aa
bb
hello world
hello kafka 消费者消费数据
[root@spark1 ~]# /application/kafka/bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning
aa
bb
hello world
hello kafka说明:
1)--from-beginning参数如果有表示从最开始消费数据,旧的和新的数据都会被消费,而没有该参数表示只会消费新产生的数据;
第三种
1.下载
从官网下载kafka,由于测试需要,我下载的是kafka_2.11-0.9.0.0.tgz
2.上传解压
将安装包上传到/opt/software目录,并解压
tar -zxf kafka_2.11-0.9.0.0.tgz -C /opt/module/3.修改配置文件
创建logs目录
[root@hadoop01 module]# cd kafka_2.11-0.9.0.0/
[root@hadoop01 kafka_2.11-0.9.0.1]# ll
total 28
drwxr-xr-x 3 root root 4096 Feb 12 2016 bin
drwxr-xr-x 2 root root 4096 Feb 12 2016 config
drwxr-xr-x 2 root root 4096 May 8 09:39 libs
-rw-r--r-- 1 root root 11358 Feb 12 2016 LICENSE
-rw-r--r-- 1 root root 162 Feb 12 2016 NOTICE
drwxr-xr-x 2 root root 46 Feb 12 2016 site-docs
[root@hadoop01 kafka_2.11-0.9.0.1]# mkdir logs修改server.properties配置文件
[root@hadoop01 kafka_2.11-0.9.0.1]# cd config/
You have new mail in /var/spool/mail/root
[root@hadoop01 config]# vim server.properties 配置以下内容
#broker的全局唯一编号,不能重复
broker.id=0
#删除topic功能使能
delete.topic.enable=true
#处理网络请求的线程数量
num.network.threads=3
#用来处理磁盘IO的现成数量
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600
#kafka运行日志存放的路径
log.dirs=/opt/module/kafka_2.11-0.9.0.0/logs
#topic在当前broker上的分区个数
num.partitions=1
#用来恢复和清理data下数据的线程数量
num.recovery.threads.per.data.dir=1
#segment文件保留的最长时间,超时将被删除
log.retention.hours=168
#配置连接Zookeeper集群地址
zookeeper.connect=hadoop01:21814.配置环境变量
[root@hadoop01]# sudo vim /etc/profile
#KAFKA_HOME
export KAFKA_HOME=/opt/module/kafka_2.11-0.9.0.0
export PATH=$PATH:$KAFKA_HOME/bin
[root@hadoop01]# source /etc/profile5.修改zookeeper配置
[root@hadoop01 config]# vim zookeeper.properties
dataDir=/opt/module/kafka_2.11-0.9.0.0/zookeeper
# the port at which the clients will connect
clientPort=2181
# disable the per-ip limit on the number of connections since this is a non-production config
#maxClientCnxns=0
tickTime=2000
initLimit=10
syncLimit=5
server.1=hadoop01:2888:3888在zookeeper的数据目录添加myid文件,写入服务broker.id属性值,如这里的目录是/opt/module/kafka_2.11-0.9.0.1/zookeeper
[root@hadoop01 kafka_2.11-0.9.0.0]# cd /opt/module/kafka_2.11-0.9.0.1/zookeeper
[root@hadoop01 zookeeper]#
[root@hadoop01 zookeeper]# touch myid
[root@hadoop01 zookeeper]# echo 1 > myid
[root@hadoop01 zookeeper]# cat myid
16.启动kafka
启动kafka之前要先启动zookeeper,这里使用的是kafka自带的zk
[root@hadoop01 ~]# cd /opt/module/kafka_2.11-0.9.0.0/
[root@hadoop01 kafka_2.11-0.9.0.0]# ls
bin config libs LICENSE logs NOTICE site-docs zookeeper
[root@hadoop01 kafka_2.11-0.9.0.0]#
[root@hadoop01 kafka_2.11-0.9.0.0]# bin/zookeeper-server-start.sh ./config/zookeeper.properties >./logs/zk.log &
[root@hadoop01 kafka_2.11-0.9.0.0]# jps
2326 Jps
[root@hadoop01 kafka_2.11-0.9.0.0]# bin/zookeeper-server-start.sh ./config/zookeeper.properties >./logs/zk.log &
[1] 2341
[root@hadoop01 kafka_2.11-0.9.0.0]# jps
2341 QuorumPeerMain
2367 Jps
[root@hadoop01 kafka_2.11-0.9.0.0]# 启动kafka
[root@hadoop01 tools]# cd /opt/module/kafka_2.11-0.9.0.0/
[root@hadoop01 kafka_2.11-0.9.0.0]# bin/kafka-server-start.sh -daemon config/server.properties
[root@hadoop01 kafka_2.11-0.9.0.0]#
[root@hadoop01 kafka_2.11-0.9.0.0]# jps
33593 QuorumPeerMain
33707 Kafka
33739 Jps
[root@hadoop01 kafka_2.11-0.9.0.1]#停止kafka
[root@hadoop01 kafka_2.11-0.9.0.1]# bin/kafka-server-stop.sh stop7.测试
创建topic
[root@hadoop01 kafka_2.11-0.9.0.0]# bin/kafka-topics.sh --create --zookeeper hadoop01:2181 --replication-factor 1 --partitions 1 --topic kafka_streaming_topic参数说明:
–zookeeper:指定kafka连接zk的连接url,该值和server.properties文件中的配置项{zookeeper.connect}一样
–replication-factor:指定副本数量
–partitions:指定分区数量
–topic:主题名称
查看kafka中所有topic信息
[root@hadoop01 kafka_2.11-0.9.0.0]# bin/kafka-topics.sh --list --zookeeper hadoop01:2181创建生产者
bin/kafka-console-producer.sh --broker-list hadoop01:9092 --topic kafka_streaming_topic创建消费者
bin/kafka-console-consumer.sh --zookeeper hadoop01:2181 --topic kafka_streaming_topic --from-beginning参数说明:
–from-beginning 从头开始消费
–bootstrap-server 指的是目标集群kafka的服务器地址,新版本之后(新版本指的是kafka 0.8.0之后的版本)开始使用 --bootstrap-server代替 --zookeeper