文章目录
- 什么是逻辑回归?
- 逻辑回归的优缺点
- 逻辑回归示例——预测回头客
- 逻辑回归示例——预测西瓜好坏
- 逻辑回归示例——预测垃圾邮件
什么是逻辑回归?
逻辑回归是一种流行的预测分类响应的方法。它是预测结果概率的广义线性模型的特例。在逻辑回归中,可以通过使用二项式逻辑回归来预测二元结果,也可以通过使用多项式逻辑回归来预测多类结果。
常应用于以下类型的场景:
- 预测一个西瓜的好坏;
- 预测这封邮件是否是垃圾邮件;
- 预测用户是否会成为回头客等等
官网:分类和回归
逻辑回归的优缺点
优点:
- 训练速度较快,分类的时候,计算量仅仅只和特征的数目相关;
- 简单易理解,模型的可解释性非常好,从特征的权重可以看到不同的特征对最后结果的影响;
- 适合二分类问题,不需要缩放输入特征;
- 内存资源占用小,因为只需要存储各个维度的特征值。
缺点:
- 不能用 Logistic 回归去解决非线性问题,因为 Logistic 的决策面试线性的;
- 对多重共线性数据较为敏感;
- 很难处理数据不平衡的问题;
- 准确率并不是很高,因为形式非常的简单(非常类似线性模型),很难去拟合数据的真实分布;
- 逻辑回归本身无法筛选特征,有时会用 gbdt 来筛选特征,然后再上逻辑回归。
参考博客:逻辑回归的优缺点
逻辑回归示例——预测回头客
数据集下载:
链接:
https://pan.baidu.com/s/1AshgNxx1wOWhLgKxgjrZww?pwd=lz3l
提取码:
lz3l
数据集介绍:
tb_train.csv 为训练集数据,其中共有五个字段,四个特征字段:user_id、age_range、gender、merchant_id,一个标签字段:label。
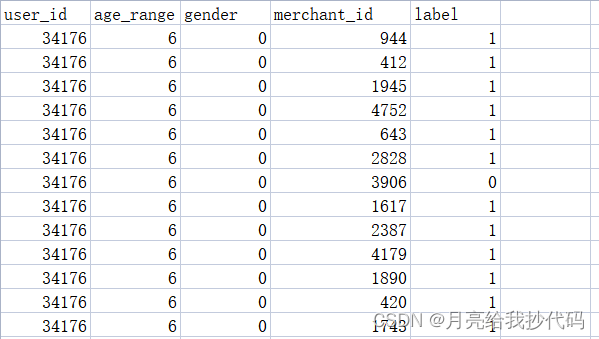
训练集中的标签字段只有值 0 和 1,0 表示不是回头客,1 表示是回头客。
tb_test.csv 为测试集数据,其中共有五个字段,四个特征字段:user_id、age_range、gender、merchant_id,一个标签字段:label。
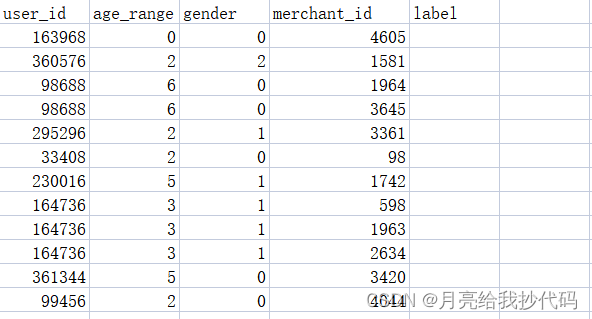
测试集中的标签字段都为空值。
需求实现:
import org.apache.spark.ml.classification.{LogisticRegression, LogisticRegressionModel}
import org.apache.spark.ml.feature.LabeledPoint
import org.apache.spark.ml.linalg.Vectors
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
object logistic{
// TODO 预测用户是否会成为回头客
def main(args: Array[String]): Unit = {
val sc: SparkSession = SparkSession.builder().appName("logistic").master("local[*]").getOrCreate()
// 1.加载训练集数据
val train_rdd: RDD[Row] = sc.read
.option("header", "true")
.csv("tb_train.csv").rdd
// 2.向量转换
import sc.implicits._
val train: DataFrame = train_rdd.map(lines => {
val arr: Array[String] = lines.mkString(",").split(",")
LabeledPoint(arr(4).toDouble, Vectors.dense(arr.slice(0, 4).map(_.toDouble)))
}).toDF("label","features")
// 3.创建逻辑回归对象
val lr = new LogisticRegression()
// 设置最大迭代次数与正则化参数
lr.setMaxIter(10).setRegParam(0.01)
// 4. 模型训练
val model: LogisticRegressionModel = lr.fit(train)
// 5.模型保存示例
model.save("./logistic/")
// 6.加载模型示例
val regressionModel: LogisticRegressionModel = LogisticRegressionModel.load("./logistic/")
// 7.加载测试集
val test_rdd: RDD[Row] = sc.read
.option("header", "true")
.csv("tb_test.csv").rdd
// 8.测试集变量转换
val test: DataFrame = test_rdd.map(lines => {
val arr: Array[String] = lines.mkString(",").split(",")
LabeledPoint(0D, Vectors.dense(arr.slice(0, 4).map(_.toDouble)))
}).toDF("label", "features")
// 9.预测测试集数据的结果(不带标签)
regressionModel
.transform(test.select("features"))
.select("features","prediction")
.limit(100)
.show(100)
}
}
逻辑回归示例——预测西瓜好坏
数据集下载:
链接:
https://pan.baidu.com/s/1AshgNxx1wOWhLgKxgjrZww?pwd=lz3l
提取码:
lz3l
数据集介绍:
西瓜集.csv 数据集中共有八个字段,六个特征字段:色泽、根蒂、敲声、纹理、脐部、触感,一个标签字段:好瓜,还有一个编号字段。

训练集中的随机百分之20的数据为测试集。
需求实现:
import org.apache.spark.ml.classification.{LogisticRegression, LogisticRegressionModel}
import org.apache.spark.ml.feature.LabeledPoint
import org.apache.spark.ml.linalg.Vectors
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
object Watermelon {
def main(args: Array[String]): Unit = {
val sc: SparkSession = SparkSession
.builder()
.appName("watermelon")
.master("local[*]").getOrCreate()
// 1.加载训练数据集
val train_rdd: RDD[String] = sc.read
.option("header", "true")
.textFile("西瓜集.csv")
.rdd
// 2.取出百分之80作为训练集,其余为测试集
val data: Array[RDD[String]] = train_rdd.randomSplit(Array(0.8, 0.2))
// 3.转换向量
import sc.implicits._
val trainDF: DataFrame = data(0).map(lines => {
val arr: Array[String] = lines.split(",")
LabeledPoint(
if (arr(7).equals("是")) {
1D
} else {
0D
},
Vectors.dense(
// 色泽转换
if (arr(1).equals("青绿")){
1D
}else if (arr(1).equals("乌黑")){
2D
}else{
3D
},
// 根蒂转换
if (arr(2).equals("硬挺")){
1D
}else if (arr(2).equals("蜷缩")){
2D
}else{
3D
},
// 敲声转换
if (arr(3).equals("清脆")){
1D
}else if (arr(3).equals("沉闷")){
2D
}else{
3D
},
// 纹理转换
if (arr(4).equals("清晰")){
1D
}else if (arr(4).equals("模糊")){
2D
}else{
3D
},
// 脐部转换
if (arr(5).equals("平坦")){
1D
}else if (arr(5).equals("凹陷")){
2D
}else{
3D
},
// 触感转换
if (arr(6).equals("软黏")){
1D
}else if (arr(6).equals("硬滑")){
2D
}else{
3D
}
)
)
}).toDF("label", "features")
// 4.创建逻辑回归模型
val lr = new LogisticRegression()
// 设置参数
lr.setMaxIter(10).setRegParam(0.01)
// 5.模型训练
val model: LogisticRegressionModel = lr.fit(trainDF)
// 6.将测试数据集转换为向量
val testDF: DataFrame = data(1).map(lines => {
val arr: Array[String] = lines.split(",")
LabeledPoint(
if (arr(7).equals("是")) {
1D
} else {
0D
},
Vectors.dense(
// 色泽转换
if (arr(1).equals("青绿")){
1D
}else if (arr(1).equals("乌黑")){
2D
}else{
3D
},
// 根蒂转换
if (arr(2).equals("硬挺")){
1D
}else if (arr(2).equals("蜷缩")){
2D
}else{
3D
},
// 敲声转换
if (arr(3).equals("清脆")){
1D
}else if (arr(3).equals("沉闷")){
2D
}else{
3D
},
// 纹理转换
if (arr(4).equals("清晰")){
1D
}else if (arr(4).equals("模糊")){
2D
}else{
3D
},
// 脐部转换
if (arr(5).equals("平坦")){
1D
}else if (arr(5).equals("凹陷")){
2D
}else{
3D
},
// 触感转换
if (arr(6).equals("软黏")){
1D
}else if (arr(6).equals("硬滑")){
2D
}else{
3D
}
)
)
}).toDF("label", "features")
// 7.预测西瓜是否是好瓜(带标签)
println("预测西瓜是否是好瓜(带标签):")
model.transform(testDF)
.select("label", "features","prediction")
.show()
// 8.预测西瓜是否是好瓜(不带标签)
println("预测西瓜是否是好瓜(不带标签):")
model.transform(testDF.select("features"))
.select("features","prediction")
.show()
}
}
逻辑回归示例——预测垃圾邮件
直接看代码
import org.apache.spark.ml.{Pipeline, PipelineModel}
import org.apache.spark.ml.classification.LogisticRegression
import org.apache.spark.ml.feature.{HashingTF, Tokenizer}
import org.apache.spark.sql.{DataFrame, SparkSession}
object Email {
// TODO 预测垃圾邮件
def main(args: Array[String]): Unit = {
val sc: SparkSession = SparkSession
.builder()
.appName("email")
.master("local[*]").getOrCreate()
// 训练数据集
val train_data: DataFrame = sc.createDataFrame(Seq(
("you@example.com", "hope you are well", 0.0),
("raj@example.com", "nice to hear from you", 0.0),
("thomas@example.com", "happy holidays", 0.0),
("mark@example.com", "see you tomorrow", 0.0),
("dog@example.com", "save loan money", 1.0),
("xyz@example.com", "save money", 1.0),
("top10@example.com", "low interest rate", 1.0),
("marketing@example.com", "cheap loan", 1.0)
)).toDF("email", "message", "label")
// 1.使用分词器,对信息内容进行分词,指定输入与输出列
val tokenizer: Tokenizer = new Tokenizer().setInputCol("message").setOutputCol("words")
// 2.哈希词频统计,将同一个单词分配到同一个分区
val hashingTF: HashingTF = new HashingTF().setNumFeatures(1000).setInputCol("words").setOutputCol("features")
// 3.创建逻辑回归模型
val lr = new LogisticRegression()
// 设置参数
lr.setMaxIter(10).setRegParam(0.01)
// 4.设置管线,进行组合
val pipeline: Pipeline = new Pipeline().setStages(Array(tokenizer,hashingTF, lr))
// 5.生成训练模型
val model: PipelineModel = pipeline.fit(train_data)
// 6.创建测试数据集
val test: DataFrame = sc.createDataFrame(Seq(
("you@example.com", "ab how are you"),
("jain@example.com", "ab hope doing well"),
("caren@example.com", "ab want some money"),
("zhou@example.com", "ab secure loan"),
("ted@example.com", "ab need loan")
)).toDF("email", "message")
// 7.对测试集进行预测
model.transform(test)
.select("email","message","prediction")
.show()
}
}
参考博客:Spark(五)————MLlib








![[附源码]Python计算机毕业设计SSM基于Java的民宿运营管理网站(程序+LW)](https://img-blog.csdnimg.cn/d80c924307924d0b9ba229c3ef02acb2.png)