提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
一、队列的初步认识
二、Java中队列的使用
三、队列的模拟实现
四、力扣刷题演练
4.1 设计循环队列
4.2 用栈实现队列
4.3 最小栈
总结
前言
今天我们将介绍有关队列的有关内容;我们将对队列的一些初步认识;以及常见队列的使用;
提示:以下是本篇文章正文内容,下面案例可供参考
一、队列的初步认识
队列,和栈一样,也是一种对数据的"存"和"取"有严格要求的线性储存结构。
与栈结构不同的是,队列的两端都"开口",要求数据只能从一端进,从另一端出;
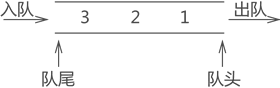
如图所示:
通常,称进数据的一端为 "队尾",出数据的一端为 "队头",数据元素进队列的过程称为 "入队",出队列的过程称为 "出队"。
比如上图中的元素3就是队尾,元素1就是队头。从图中我们也可以看出,元素1是最先进入队列中的,同样他也是最先出队的,所以说队列是一种先进先出的结构。

二、Java中队列的使用
在Java中,队列Queue是个接口,底层是用双向链表实现的。
他主要的方法有一下这几个:
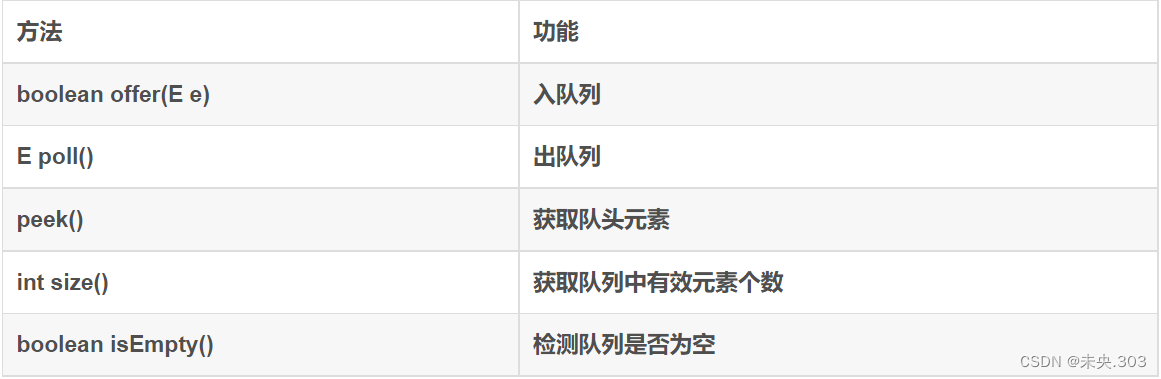
注意:Queue是个接口,我们不能直接对Queue进行实例化,但我们可以用Queue接口实例化LinkedList的对象,因为LinkedList实现了Queue接口。
使用实例:
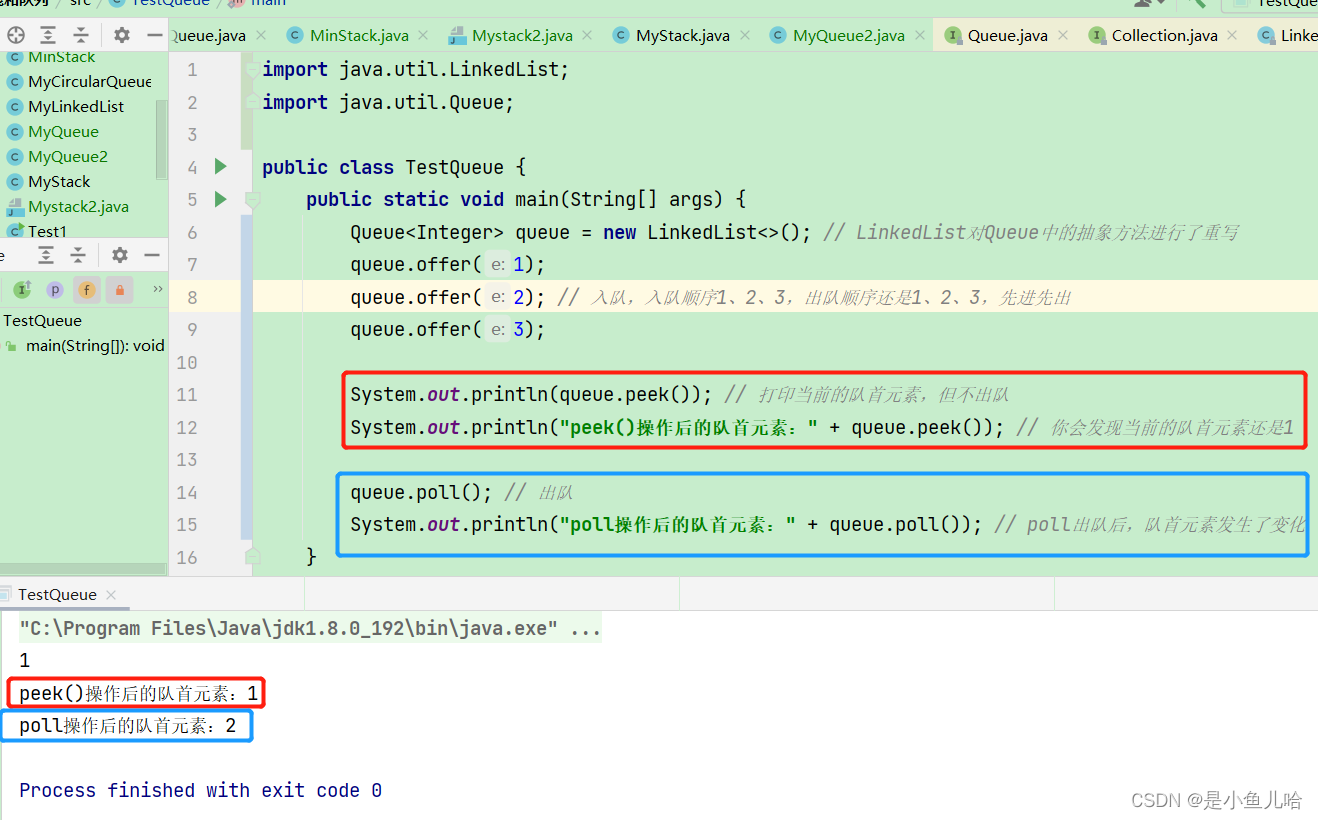
三、队列的模拟实现
// 用单链表实现的队列,入队和出队的时间复杂度都是O(1) public class MyQueue2 { class ListNode{ public int val; public ListNode next; ListNode(int val) { this.val = val; } } ListNode head; ListNode last; // 入队,从尾入,从头出 public void offer(int x) { ListNode node = new ListNode(x); if (empty()) { // 如果此时队列为空,新插入的结点就是头结点和尾巴结点 head = node; last = node; } else { last.next = node; } last = node; } // 出队 public int poll() { if (empty()) { throw new NullPointerException("当前队列为空,你的操作不合法!"); } if (head == last) head = last = null; int tmp = head.val; // 先保留一下头节点的值,然后再更改指向 head = head.next; return tmp; } // 只是获取将要出队的元素的值,不删除元素 public int peek() { return head.val; } // 判断当前队列是否为空 public boolean empty() { if (head == null) { return true; } return false; } }思路:
1.用单链表实现的队列,为了入队和出队的时间复杂度都是O(1),
2.我们还在单链表中设置了一个对尾结点的引用last,同时还需要保证我们都是尾插入队,头删出队
为什么呢?因为单链表只有后驱,没有前驱(即只知道后一个是谁,但不知道前一个是谁)
1.如果我们要尾删出队——就必须找到该结点的前一个是谁,就需要遍历链表O(N)时间复杂度
2.而如果头删,我们直接更改当前头结点的指向就好了,时间复杂度自然是O(1)
那为啥要尾插入队呢?我们如果从尾巴插入,是不是只要将当前的的尾巴结点指向新插入的结点就行了,
此时新插入的结点就变成了新的尾巴结点,时间复杂度也是O(1);
测试:

四、力扣刷题演练
4.1 设计循环队列
题目链接:力扣

分析 :
我们刚才是用链表实现的队列,而这道题目要求我们用数组这种线性储存结构来实现队列的各种操作,所以我们就需要改变一下设计思想
数组是线性储存元素,那么我们的新增和删除该怎么操作呢?新增和删除时数组的下标是怎样变化的呢?题目中说的循序是怎样进行的呢?
思路:
在这个循环队列中,我们用front来表示队头的数组下标、rear表示队尾的数组下标。为了实现循环我们发现,所谓的头和尾其实是在不断变化着的,和链表一样,我们还是从尾巴入队,从头部出队;
当front == rear是表示当前队列为空,当一个元素入队后,表示队尾的数组下标rear就加一;出队后表示队头的数组下标front就加一,但问题了来了——如何判断当前队列是否满了呢?
有三种方法
- 设置一个标记flag;
- 每增加或减少一个元素后,用计数器usedSize记录当前队列中元素的个数。当usedSize == 数组的长度时说明满了;
- 空一格,当(rear + 1) % 数组的长度 == front 的时候说明数组满了;
说到这里,你可能对取模有点疑惑,为什么要取模呢???
📝数组的下标是可以一直增加的——很有可能会超过数组的长度,因为随着数组的增加和删除front和rear都是不断往前走的;
📝比如数组中能容纳的元素总个数是8,即最大下标是7。当我们新增了7个元素,rear变成了 6,然后我们又删除了4个元素,即front变成了3;
📝此时数组中只剩下了3个元素——也就是还能增加5个元素,即rear还能加5,但rear + 5不就等于11了吗?超过最大下标了呀!但其实此时的增加的确是合法的呀!所以要对数组下标及时的取模;
💖代码实现:
class MyCircularQueue {
int[] elem; // 我们这个队列是用数组实现的
int front; // 表示队头的数组下标
int rear; // 表示队尾的数组下标
/**
* 构造方法
* @param 数组长度是k
*/
public MyCircularQueue(int k) {
elem = new int[k + 1]; // 为啥要k + 1,因为我们在判断队列是否满的时候,浪费了一个数组空间——即定义数组长度为k,但我实际只能放k - 1个就显示满了,所以我们要想放k个元素就要定义k + 1个长度的数组
}
/**
* 入队
* @param value
* @return 插入成功返回true,失败返回false
*/
public boolean enQueue(int value) {
if (isFull()) { // 如果当前队列满了,就不能再入队了
return false;
}
else {
elem[rear] = value; // 再当前的数组尾巴下标下新增数据
// 新增数据后要对尾巴下标进行更新
rear = (rear + 1) % elem.length; // 注意这里,防止数组越界
}
return true;
}
/**
* 出队
* @return 出队成功返回true,失败返回false
*/
public boolean deQueue() {
if (isEmpty()) {
return false;
}
else {
front = (front + 1) % elem.length;
}
return true;
}
/**
* 得到队头元素
* @return 返回队头元素,如果队列为空返回-1
*/
public int Front() {
if (isEmpty()) {
return -1;
}
return elem[front];
}
/**
* 得到队尾元素 返回队尾元素,如果队列为空返回-1
有小伙伴可能会说,直接返回elem[rear - 1]不就好了吗?但如果此时rear == 0, 数组下标不就越界了吗?
但此时如果此时队列不为空,rear等于0说明当前的队尾下标是 数组长度-1,因为是循环队列呀
* @return
*/
public int Rear() {
if (isEmpty()) return -1;
int index = (rear == 0) ? elem.length - 1 : rear - 1;
return elem[index];
}
/**
* 当前循环队列是否为空
* @return
*/
public boolean isEmpty() {
if (rear == front) return true; // 他们相遇证明是空的
return false;
}
/**
* 判断当前队列是否为满
* @return 满了返回true, 不满返回false
*/
public boolean isFull() {
// 因为我们空了一个,相当于有一个数组下标没有用到,所以说比如我定义了一个长度为4的数组,我就只能放3个元素(就显示数组满了)
if ((rear + 1) % elem.length == front) { // 空一个格子,和一开始rear == front 为空的情况区分开来
return true;
}
return false;
}
}4.2 用栈实现队列
题目链接:力扣

思路:
我们入栈的时候把数据都放到s1中
*即用s1来存放数据,s2用来输出数据,如果s2为空,就把s1的数据全部放到s2中
*意思就是push的存的数据都放到了s1中,我们pop输出的数据都是从s2里输出的;
💖代码实现:
class MyQueue {
Stack<Integer> s1;
Stack<Integer> s2;
public MyQueue() {
s1 = new Stack<>();
s2 = new Stack<>();
}
// 入队
public void push(int x) {
s1.push(x);
}
// 出队
public int pop() {
// 我们输出数据都是从s2里拿的,如果s2为空,就把s1里的元素放到s2里面
if (s2.empty()) {
while (!s1.empty()) { // 把s1里的数据全部放到s2里面
int tmp = s1.pop();
s2.push(tmp);
}
return s2.pop();
}
else {
return s2.pop();
}
}
// 返回队列开头的元素
public int peek() {
// 和上面出队的操作相似,不同的是在对s2进行出栈操作时,只是获取栈顶元素的值,而不是删除当前栈顶
if (s2.empty()) {
while (!s1.empty()) {
int tmp = s1.pop();
s2.push(tmp);
}
return s2.peek();
}
else {
return s2.peek();
}
}
// 判断当前队列是否为空,空返回true,非空返回false
public boolean empty() {
return s1.empty() && s2.empty();
}
}4.3 最小栈
题目链接:力扣

分析:
在本题中,push,pop,top等操作功能和普通的栈都相同,不同的就是多了一个getMin()获取栈中元素最小值的操作;
思路:
为了让我们能够在常数时间内检测到当前栈中的最小元素,我们不妨用两个栈s1和minStack,s1栈就正常的进行数据的存放和处理,另一个minStack栈就专门存放当前栈中的最小元素,并随着s1栈中元素的变化不断的进行更新;
💖代码实现:
class MinStack {
Stack<Integer> s1;
Stack<Integer> minStack;
public MinStack() {
s1 = new Stack<>();
minStack = new Stack<>();
}
// 入栈
public void push(int val) {
s1.push(val); // 把元素都先放到s1栈中
if (minStack.empty()) { // 如果当前最小栈minStack中为空,直接把当前元素放到minStack就行
minStack.push(val);
}
else if (val <= minStack.peek()){ // 下面有详细解释
minStack.push(val);
}
}
public void pop() {
int x = s1.pop();
// 当s1中要出栈的元素等于最小栈中的元素,即此时栈中元素的最小值已经发生了变化,所以最小栈中元素也要出栈
if (x == minStack.peek()) {
minStack.pop();
}
}
public int top() {
return s1.peek();
}
public int getMin() {
if (!minStack.empty()) {
return minStack.peek();
}
return -1;
}
}对其中一些代码的解释:
// 入栈 public void push(int val) { s1.push(val); // 把元素都先放到s1栈中 if (minStack.empty()) { // 如果当前最小栈minStack中为空,直接把当前元素放到minStack就行 minStack.push(val); } // 如果minStack不为空,就需要进行判断, // 如果新添加的元素比minStack中的元素小或等于就放进去 else if (val <= minStack.peek()){ minStack.push(val); } } 为啥要包含等于这种情况 比如s1栈中放的是0、1、0,如果没有等于minStack中存放的只有一个0, 但如果s1中的元素发生了变化——栈顶元素0出栈了,按我们下面出栈的规则来说的话, 此时minStack中的0也要出栈,此时栈不就为空了吗?
总结
今天的内容就介绍到这里,下一节我们将介绍有关二叉树的有关内容;让我们下一期内容再见!!