Spring框架对于后置处理器的最佳实践
PostProcessor译为后置处理器,大多数开发人员都使用过springboot对后置处理器的实例级别实践,也就是BeanPostProcessor接口。其实spring还提供了两种容器级别的实践:BeanDefinitionRegistryPostProcessor与BeanFactoryPostProcessor接口。这里不过多赘述spring实践的具体用法,简单的说明beanPostprocessor接口扩展执行的时机:重写的handleBefore方法执行在bean初始化之前,属性填充之后,而handleAfter则执行在bean的初始化结束之后,具体的应用场景也有很多,比如修改bean的个性化配置,亦或者修改某一类bean实例化配置。
后置处理器机制能带来什么
原始的mvc结构的代码是java开发的流行层级,那么随着用户需求的更变与增加,定制化越来越常用,我们不断地在service组件中增加if、或者是增加service组件数量,亦或是使用aop做前后置处理(但是我有一个习惯,绝不在aop方法上做耗时操作)。那么后期随着项目时间的增加,很容易出现某个组件代码成为垃圾堆,不仅读起来麻烦,修改起来更麻烦,有可能修改了一个无关紧要的地方都会影响到我们的主流程。
所以这里笔者给读者们带来一种解决方案,后置处理器机制的实现,也可以叫它扩展与埋点思想的实现,这是一种编程方法,开闭原则的一种实践。
实践postprocessor机制过程
接口依赖流程图:
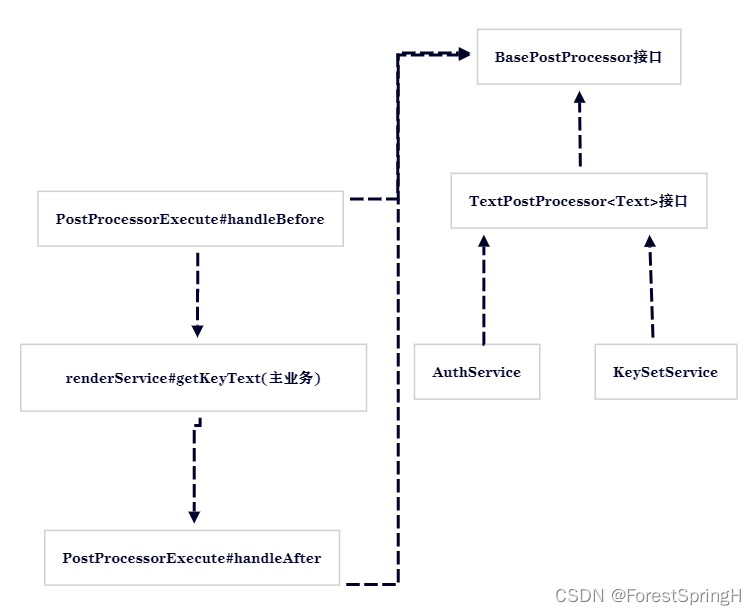
跟随笔者一起研究整个demo实现过程中的开发方法与postprocessor机制使用的巧妙。
需要区分的是postprocessor机制属于一种靠近容器级别的切面实现,并不是aspectJ那种方法级别的切面实现,postprocessor可以做到预留扩展(也叫做埋点,等待后续使用,或者通过这个点拿到我们想拿到的信息对象,比如applicationContextAware感知扩展,可以在这个埋点的set方法里拿到容器的applicationContext对象的引用从而获取它的信息),且可以使得各种实现扩展的组件按照某种顺序依次处理,而不是像aspectJ一样只能单切,一不小心就会使得代码冗余,逻辑复杂化。
1、定义一个基础扩展接口BasePostProcessor<T>
public interface BasePostProcessor<T>{
default boolean handleBefore(PostContext<T> postContext){
return true;
}
default boolean handleAfter(PostContext<T> postContext){
return true;
}
default int getLevel(){
return 0;
}
}它包含前置处理。后置处理,处理优先级三个方法,需要注意的是这里的优先级我们可以在其余的处理组件上重写,以做到后续依次执行前置方法,后置方法的排序依据。
这里也充分体现java8之后接口默认方法可以增加方法体的特性,有兴趣的小伙伴可以去查询java8的新变动。
2、定义一个识别BasePostProcessor扩展接口并按照优先级依次执行前后置方法的驱动类
public class PostProcessorExecute<T> {
private Class<BasePostProcessor> initPostProcessor;
public static <T> PostProcessorExecute getInstance(Class<T> serviceClazz) {
PostProcessorExecute postProcessorExecute = new PostProcessorExecute();
postProcessorExecute.initPostProcessor = serviceClazz;
return postProcessorExecute;
}
public Boolean handleBefore(PostContext<T> postContext) {
List<? extends BasePostProcessor> list = ApplicationContextUtil.getBeanListByType(initPostProcessor);
if (CollectionUtils.isEmpty(list)) {
return true;
}
list.stream()
.sorted(Comparator.comparing(BasePostProcessor::getLevel))
.forEach(e -> e.handleBefore(postContext));
return false;
}
public void handleAfter(PostContext<T> postContext) {
List<? extends BasePostProcessor> list = ApplicationContextUtil.getBeanListByType(initPostProcessor);
if (CollectionUtils.isEmpty(list)) {
return;
}
list.stream()
.sorted(Comparator.comparing(BasePostProcessor::getLevel, Comparator.reverseOrder()))
.forEach(e -> e.handleAfter(postContext));
}
}笔者将详细说明以上驱动类的代码逻辑:
private Class<BasePostProcessor> initPostProcessor;
public static <T> PostProcessorExecute getInstance(Class<T> serviceClazz) {
PostProcessorExecute postProcessorExecute = new PostProcessorExecute();
postProcessorExecute.initPostProcessor = serviceClazz;
return postProcessorExecute;
}定义一个扩展类型的类型变量initPostProcessor,利用getInstance方法获取驱动类实例时,先利用传入的类型变量覆盖我们的initPostProcessor变量;
List<? extends BasePostProcessor> list = ApplicationContextUtil.getBeanListByType(initPostProcessor);
if (CollectionUtils.isEmpty(list)) {
return true;
}获取所有BasePostProcessor类型的bean(这里的bean其实就是我们自定义增加的非通用service外的定制或可复用service),如果为null则立刻返回true,进入主流程;
list.stream()
.sorted(Comparator.comparing(BasePostProcessor::getLevel))
.forEach(e -> e.handleBefore(postContext));
return false;根据每一个service复写的优先级进行升序排序并依次执行它们的前置处理方法,这里需要注意优先级越高越靠近我们的主流程(也就是业务内核),之后返回false,主流程可根据接收的布尔值进行判断处理后续逻辑;
list.stream()
.sorted(Comparator.comparing(BasePostProcessor::getLevel, Comparator.reverseOrder()))
.forEach(e -> e.handleAfter(postContext));需要注意的点是我们定义过优先级高的靠近主流程,那么后置处理时一定是倒序排序。
3、定义业务承载实体
@Data
public class Text {
private String textCode;
private String textTitle;
private String textCreat;
private Integer textAuthLevel;
private String textInfo;
private LocalDateTime optionTime;
}4、定义承载实体类型定制的扩展接口,注意该接口是埋入的通用扩展(Text处理流程的主要扩展类型)
public interface TextPostProcessor extends BasePostProcessor<Text> {
}直接规定泛型的类型,便于规定实现它的所有service组件都能在重写方法时直接获取Text类型。
5、定义承载实体类的包装类型(可能后续会传入其余数据,可在此类型添加接收)
public class PostContext<T> {
private T data;
public T getData(){
return this.data;
}
public void setData(T data){
this.data = data;
}
}这里重写的set与get方法是为了便捷后续对data的覆盖
6、编写主流程service中的getKetText方法
@Service("renderService")
@Slf4j
public class RenderServiceImpl implements RenderService{
@Override
public String getKeyContext(Text text) {
log.info("---------renderService------------>");
PostContext<Text> postContext = new PostContext<>();
postContext.setData(text);
PostProcessorExecute postProcessorExecute = PostProcessorExecute.getInstance(TextPostProcessor.class);
try {
Boolean handleBefore = postProcessorExecute.handleBefore(postContext);
if (!handleBefore) {
//返回已经经过前置处理过的文本内容
return text.getTextInfo();
}
//下面就是未经过文本处理的内容,非定制需求走通用返回
postProcessorExecute.handleAfter(postContext);
}catch (RuntimeException e){
e.printStackTrace();
return null;
}
return text.getTextInfo();
}
}从这个方法我们可以看出通用流程被保护(判断驱动类前置处理的返回值不同采取不同的行动)
7、新增需求1:现在需要根据用户文本的校验等级决定主流程处理或者不处理该文本
方案一:直接在主流程加入if(text.getTextAuthLevel() > 校验等级值)......等代码。
方案二:新增扩展AuthLevelService组件处理校验等级业务(如下代码)
@Service
@Slf4j
public class AuthServiceImpl implements TextPostProcessor {
@Override
public int getLevel() {
return Integer.MIN_VALUE;
}
@Override
public boolean handleBefore(PostContext<Text> postContext) {
log.info("---------authService------------>");
Text data = postContext.getData();
if (data.getTextAuthLevel() < 1){
throw new RuntimeException("权限校验失败");
}
return true;
}
}这里将它的优先级定义为最小的原因是,业务的处理流程中 等级的校验操作 一定是最早的。
8、新增需求2:现在需要给文本创建公司H 新增文本渲染在页面上的变大处理
方案一:直接在主流程加入代码 if(text.getTextCreat() == "H").....等代码
方案二:新增扩展KeySetService组件处理H公司的定制文本处理需求(如下代码)
@Service
@Slf4j
public class KeySetServiceImpl implements TextPostProcessor {
@Override
public boolean handleBefore(PostContext<Text> postContext) {
log.info("---------keySetService------------>");
Text data = postContext.getData();
//推荐不要使用魔法值
if ("H".equals(data.getTextCreat())){
String textInfo = data.getTextInfo();
if (StringUtils.isEmpty(textInfo)){
throw new RuntimeException("文本读取为空文本");
}
textInfo = "<h1>"+textInfo+"</h1>";
data.setTextInfo(textInfo);
postContext.setData(data);
}
return true;
}
@Override
public int getLevel() {
return Integer.MAX_VALUE;
}
}
9、附上获取容器中某一类型的Bean链表的组件类
@Component
@Lazy(value = false)
public class ApplicationContextUtil implements ApplicationContextAware {
private static ApplicationContext applicationContext;
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
ApplicationContextUtil.applicationContext = applicationContext;
}
public static <T> List<T> getBeanListByType(Class<T> beanType) {
Map<String, T> beansOfType = applicationContext.getBeansOfType(beanType);
if (CollectionUtils.isEmpty(beansOfType)) {
return null;
}
return new ArrayList<>(beansOfType.values());
}
}我们可以深入思考一下:
假设H公司后续又提出了不同的文本处理需求,采用8中的方案1的话我们就会无穷无尽的陷入if-else中,代码越来越长,代码垃圾堆就出现了。
假设后续还要接入其他定制业务?假设还需要对文本做过滤不健康内容呢?
PostProcessor机制只是一种设计上的优化,它还有很多可以让我们深省自己开发时遇到的设计上问题之思考。