目录
中断的进入过程
中断的进入过程
为方便实验,本章以配套的目标板 FS4412为例来介绍 Linux 的中断子系统,并且编写相应的中断处理程序。FS4412 上的处理器是 SAMSUNG公司的 Exynos4412,该处理器使用的是4核的 Cortex-A9,(初学者单核A7就行这个太贵了。)对应的中断控制器被称为 GIC(32的叫NVIC),相比于一般的中断控制器而言,其最主要的特点在于可以将一个特定的中断分发给一个特定的 ARM 核。但这并不是我们关注的重点,在后面的分析中,应该主要知道当中断发生后要如何调用驱动中的中断处理函数,以及在这个过程中所涉及的重要数据结构。整个过程中涉及较多的和体系结构相关的内容,主要体现在中断处理的前期阶段,为了更方便读者理解这部分内容在下面的讨论中会重新改写这部分代码。汇编阶段的主要相关代码如下。
/*arch/arm/kernel/entry-armv.S */
/*
* linux/arch/arm/kernel/entry-armv.S
*
* Copyright (C) 1996,1997,1998 Russell King.
* ARM700 fix by Matthew Godbolt (linux-user@willothewisp.demon.co.uk)
* nommu support by Hyok S. Choi (hyok.choi@samsung.com)
*
* This program is free software; you can redistribute it and/or modify
* it under the terms of the GNU General Public License version 2 as
* published by the Free Software Foundation.
*
* Low-level vector interface routines
*
* Note: there is a StrongARM bug in the STMIA rn, {regs}^ instruction
* that causes it to save wrong values... Be aware!
*/
#include <asm/assembler.h>
#include <asm/memory.h>
#include <asm/glue-df.h>
#include <asm/glue-pf.h>
#include <asm/vfpmacros.h>
#ifndef CONFIG_MULTI_IRQ_HANDLER
#include <mach/entry-macro.S>
#endif
#include <asm/thread_notify.h>
#include <asm/unwind.h>
#include <asm/unistd.h>
#include <asm/tls.h>
#include <asm/system_info.h>
#include "entry-header.S"
#include <asm/entry-macro-multi.S>
/*
* Interrupt handling.
*/
.macro irq_handler
#ifdef CONFIG_MULTI_IRQ_HANDLER
ldr r1, =handle_arch_irq
mov r0, sp
adr lr, BSYM(9997f)
ldr pc, [r1]
#else
arch_irq_handler_default
#endif
9997:
.endm
.macro pabt_helper
@ PABORT handler takes pt_regs in r2, fault address in r4 and psr in r5
#ifdef MULTI_PABORT
ldr ip, .LCprocfns
mov lr, pc
ldr pc, [ip, #PROCESSOR_PABT_FUNC]
#else
bl CPU_PABORT_HANDLER
#endif
.endm
.macro dabt_helper
@
@ Call the processor-specific abort handler:
@
@ r2 - pt_regs
@ r4 - aborted context pc
@ r5 - aborted context psr
@
@ The abort handler must return the aborted address in r0, and
@ the fault status register in r1. r9 must be preserved.
@
#ifdef MULTI_DABORT
ldr ip, .LCprocfns
mov lr, pc
ldr pc, [ip, #PROCESSOR_DABT_FUNC]
#else
bl CPU_DABORT_HANDLER
#endif
.endm
#ifdef CONFIG_KPROBES
.section .kprobes.text,"ax",%progbits
#else
.text
#endif
/*
* Invalid mode handlers
*/
.macro inv_entry, reason
sub sp, sp, #S_FRAME_SIZE
ARM( stmib sp, {r1 - lr} )
THUMB( stmia sp, {r0 - r12} )
THUMB( str sp, [sp, #S_SP] )
THUMB( str lr, [sp, #S_LR] )
mov r1, #\reason
.endm
__pabt_invalid:
inv_entry BAD_PREFETCH
b common_invalid
ENDPROC(__pabt_invalid)
__dabt_invalid:
inv_entry BAD_DATA
b common_invalid
ENDPROC(__dabt_invalid)
__irq_invalid:
inv_entry BAD_IRQ
b common_invalid
ENDPROC(__irq_invalid)
__und_invalid:
inv_entry BAD_UNDEFINSTR
@
@ XXX fall through to common_invalid
@
@
@ common_invalid - generic code for failed exception (re-entrant version of handlers)
@
common_invalid:
zero_fp
ldmia r0, {r4 - r6}
add r0, sp, #S_PC @ here for interlock avoidance
mov r7, #-1 @ "" "" "" ""
str r4, [sp] @ save preserved r0
stmia r0, {r5 - r7} @ lr_<exception>,
@ cpsr_<exception>, "old_r0"
mov r0, sp
b bad_mode
ENDPROC(__und_invalid)
/*
* SVC mode handlers
*/
#if defined(CONFIG_AEABI) && (__LINUX_ARM_ARCH__ >= 5)
#define SPFIX(code...) code
#else
#define SPFIX(code...)
#endif
.macro svc_entry, stack_hole=0
UNWIND(.fnstart )
UNWIND(.save {r0 - pc} )
sub sp, sp, #(S_FRAME_SIZE + \stack_hole - 4)
#ifdef CONFIG_THUMB2_KERNEL
SPFIX( str r0, [sp] ) @ temporarily saved
SPFIX( mov r0, sp )
SPFIX( tst r0, #4 ) @ test original stack alignment
SPFIX( ldr r0, [sp] ) @ restored
#else
SPFIX( tst sp, #4 )
#endif
SPFIX( subeq sp, sp, #4 )
stmia sp, {r1 - r12}
ldmia r0, {r3 - r5}
add r7, sp, #S_SP - 4 @ here for interlock avoidance
mov r6, #-1 @ "" "" "" ""
add r2, sp, #(S_FRAME_SIZE + \stack_hole - 4)
SPFIX( addeq r2, r2, #4 )
str r3, [sp, #-4]! @ save the "real" r0 copied
@ from the exception stack
mov r3, lr
@
@ We are now ready to fill in the remaining blanks on the stack:
@
@ r2 - sp_svc
@ r3 - lr_svc
@ r4 - lr_<exception>, already fixed up for correct return/restart
@ r5 - spsr_<exception>
@ r6 - orig_r0 (see pt_regs definition in ptrace.h)
@
stmia r7, {r2 - r6}
#ifdef CONFIG_TRACE_IRQFLAGS
bl trace_hardirqs_off
#endif
.endm
.align 5
__dabt_svc:
svc_entry
mov r2, sp
dabt_helper
THUMB( ldr r5, [sp, #S_PSR] ) @ potentially updated CPSR
svc_exit r5 @ return from exception
UNWIND(.fnend )
ENDPROC(__dabt_svc)
.align 5
__irq_svc:
svc_entry
irq_handler
#ifdef CONFIG_PREEMPT
get_thread_info tsk
ldr r8, [tsk, #TI_PREEMPT] @ get preempt count
ldr r0, [tsk, #TI_FLAGS] @ get flags
teq r8, #0 @ if preempt count != 0
movne r0, #0 @ force flags to 0
tst r0, #_TIF_NEED_RESCHED
blne svc_preempt
#endif
svc_exit r5, irq = 1 @ return from exception
UNWIND(.fnend )
ENDPROC(__irq_svc)
.ltorg
#ifdef CONFIG_PREEMPT
svc_preempt:
mov r8, lr
1: bl preempt_schedule_irq @ irq en/disable is done inside
ldr r0, [tsk, #TI_FLAGS] @ get new tasks TI_FLAGS
tst r0, #_TIF_NEED_RESCHED
moveq pc, r8 @ go again
b 1b
#endif
__und_fault:
@ Correct the PC such that it is pointing at the instruction
@ which caused the fault. If the faulting instruction was ARM
@ the PC will be pointing at the next instruction, and have to
@ subtract 4. Otherwise, it is Thumb, and the PC will be
@ pointing at the second half of the Thumb instruction. We
@ have to subtract 2.
ldr r2, [r0, #S_PC]
sub r2, r2, r1
str r2, [r0, #S_PC]
b do_undefinstr
ENDPROC(__und_fault)
.align 5
__und_svc:
#ifdef CONFIG_KPROBES
@ If a kprobe is about to simulate a "stmdb sp..." instruction,
@ it obviously needs free stack space which then will belong to
@ the saved context.
svc_entry 64
#else
svc_entry
#endif
@
@ call emulation code, which returns using r9 if it has emulated
@ the instruction, or the more conventional lr if we are to treat
@ this as a real undefined instruction
@
@ r0 - instruction
@
#ifndef CONFIG_THUMB2_KERNEL
ldr r0, [r4, #-4]
#else
mov r1, #2
ldrh r0, [r4, #-2] @ Thumb instruction at LR - 2
cmp r0, #0xe800 @ 32-bit instruction if xx >= 0
blo __und_svc_fault
ldrh r9, [r4] @ bottom 16 bits
add r4, r4, #2
str r4, [sp, #S_PC]
orr r0, r9, r0, lsl #16
#endif
adr r9, BSYM(__und_svc_finish)
mov r2, r4
bl call_fpe
mov r1, #4 @ PC correction to apply
__und_svc_fault:
mov r0, sp @ struct pt_regs *regs
bl __und_fault
__und_svc_finish:
ldr r5, [sp, #S_PSR] @ Get SVC cpsr
svc_exit r5 @ return from exception
UNWIND(.fnend )
ENDPROC(__und_svc)
.align 5
__pabt_svc:
svc_entry
mov r2, sp @ regs
pabt_helper
svc_exit r5 @ return from exception
UNWIND(.fnend )
ENDPROC(__pabt_svc)
.align 5
.LCcralign:
.word cr_alignment
#ifdef MULTI_DABORT
.LCprocfns:
.word processor
#endif
.LCfp:
.word fp_enter
/*
* User mode handlers
*
* EABI note: sp_svc is always 64-bit aligned here, so should S_FRAME_SIZE
*/
#if defined(CONFIG_AEABI) && (__LINUX_ARM_ARCH__ >= 5) && (S_FRAME_SIZE & 7)
#error "sizeof(struct pt_regs) must be a multiple of 8"
#endif
.macro usr_entry
UNWIND(.fnstart )
UNWIND(.cantunwind ) @ don't unwind the user space
sub sp, sp, #S_FRAME_SIZE
ARM( stmib sp, {r1 - r12} )
THUMB( stmia sp, {r0 - r12} )
ldmia r0, {r3 - r5}
add r0, sp, #S_PC @ here for interlock avoidance
mov r6, #-1 @ "" "" "" ""
str r3, [sp] @ save the "real" r0 copied
@ from the exception stack
@
@ We are now ready to fill in the remaining blanks on the stack:
@
@ r4 - lr_<exception>, already fixed up for correct return/restart
@ r5 - spsr_<exception>
@ r6 - orig_r0 (see pt_regs definition in ptrace.h)
@
@ Also, separately save sp_usr and lr_usr
@
stmia r0, {r4 - r6}
ARM( stmdb r0, {sp, lr}^ )
THUMB( store_user_sp_lr r0, r1, S_SP - S_PC )
@
@ Enable the alignment trap while in kernel mode
@
alignment_trap r0
@
@ Clear FP to mark the first stack frame
@
zero_fp
#ifdef CONFIG_IRQSOFF_TRACER
bl trace_hardirqs_off
#endif
ct_user_exit save = 0
.endm
.macro kuser_cmpxchg_check
#if !defined(CONFIG_CPU_32v6K) && defined(CONFIG_KUSER_HELPERS) && \
!defined(CONFIG_NEEDS_SYSCALL_FOR_CMPXCHG)
#ifndef CONFIG_MMU
#warning "NPTL on non MMU needs fixing"
#else
@ Make sure our user space atomic helper is restarted
@ if it was interrupted in a critical region. Here we
@ perform a quick test inline since it should be false
@ 99.9999% of the time. The rest is done out of line.
cmp r4, #TASK_SIZE
blhs kuser_cmpxchg64_fixup
#endif
#endif
.endm
.align 5
__dabt_usr:
usr_entry
kuser_cmpxchg_check
mov r2, sp
dabt_helper
b ret_from_exception
UNWIND(.fnend )
ENDPROC(__dabt_usr)
.align 5
__irq_usr:
usr_entry
kuser_cmpxchg_check
irq_handler
get_thread_info tsk
mov why, #0
b ret_to_user_from_irq
UNWIND(.fnend )
ENDPROC(__irq_usr)
.ltorg
.align 5
__und_usr:
usr_entry
mov r2, r4
mov r3, r5
@ r2 = regs->ARM_pc, which is either 2 or 4 bytes ahead of the
@ faulting instruction depending on Thumb mode.
@ r3 = regs->ARM_cpsr
@
@ The emulation code returns using r9 if it has emulated the
@ instruction, or the more conventional lr if we are to treat
@ this as a real undefined instruction
@
adr r9, BSYM(ret_from_exception)
tst r3, #PSR_T_BIT @ Thumb mode?
bne __und_usr_thumb
sub r4, r2, #4 @ ARM instr at LR - 4
1: ldrt r0, [r4]
ARM_BE8(rev r0, r0) @ little endian instruction
@ r0 = 32-bit ARM instruction which caused the exception
@ r2 = PC value for the following instruction (:= regs->ARM_pc)
@ r4 = PC value for the faulting instruction
@ lr = 32-bit undefined instruction function
adr lr, BSYM(__und_usr_fault_32)
b call_fpe
__und_usr_thumb:
@ Thumb instruction
sub r4, r2, #2 @ First half of thumb instr at LR - 2
#if CONFIG_ARM_THUMB && __LINUX_ARM_ARCH__ >= 6 && CONFIG_CPU_V7
/*
* Thumb-2 instruction handling. Note that because pre-v6 and >= v6 platforms
* can never be supported in a single kernel, this code is not applicable at
* all when __LINUX_ARM_ARCH__ < 6. This allows simplifying assumptions to be
* made about .arch directives.
*/
#if __LINUX_ARM_ARCH__ < 7
/* If the target CPU may not be Thumb-2-capable, a run-time check is needed: */
#define NEED_CPU_ARCHITECTURE
ldr r5, .LCcpu_architecture
ldr r5, [r5]
cmp r5, #CPU_ARCH_ARMv7
blo __und_usr_fault_16 @ 16bit undefined instruction
/*
* The following code won't get run unless the running CPU really is v7, so
* coding round the lack of ldrht on older arches is pointless. Temporarily
* override the assembler target arch with the minimum required instead:
*/
.arch armv6t2
#endif
2: ldrht r5, [r4]
ARM_BE8(rev16 r5, r5) @ little endian instruction
cmp r5, #0xe800 @ 32bit instruction if xx != 0
blo __und_usr_fault_16 @ 16bit undefined instruction
3: ldrht r0, [r2]
ARM_BE8(rev16 r0, r0) @ little endian instruction
add r2, r2, #2 @ r2 is PC + 2, make it PC + 4
str r2, [sp, #S_PC] @ it's a 2x16bit instr, update
orr r0, r0, r5, lsl #16
adr lr, BSYM(__und_usr_fault_32)
@ r0 = the two 16-bit Thumb instructions which caused the exception
@ r2 = PC value for the following Thumb instruction (:= regs->ARM_pc)
@ r4 = PC value for the first 16-bit Thumb instruction
@ lr = 32bit undefined instruction function
#if __LINUX_ARM_ARCH__ < 7
/* If the target arch was overridden, change it back: */
#ifdef CONFIG_CPU_32v6K
.arch armv6k
#else
.arch armv6
#endif
#endif /* __LINUX_ARM_ARCH__ < 7 */
#else /* !(CONFIG_ARM_THUMB && __LINUX_ARM_ARCH__ >= 6 && CONFIG_CPU_V7) */
b __und_usr_fault_16
#endif
UNWIND(.fnend)
ENDPROC(__und_usr)
/*
* The out of line fixup for the ldrt instructions above.
*/
.pushsection .fixup, "ax"
.align 2
4: mov pc, r9
.popsection
.pushsection __ex_table,"a"
.long 1b, 4b
#if CONFIG_ARM_THUMB && __LINUX_ARM_ARCH__ >= 6 && CONFIG_CPU_V7
.long 2b, 4b
.long 3b, 4b
#endif
.popsection
/*
* Check whether the instruction is a co-processor instruction.
* If yes, we need to call the relevant co-processor handler.
*
* Note that we don't do a full check here for the co-processor
* instructions; all instructions with bit 27 set are well
* defined. The only instructions that should fault are the
* co-processor instructions. However, we have to watch out
* for the ARM6/ARM7 SWI bug.
*
* NEON is a special case that has to be handled here. Not all
* NEON instructions are co-processor instructions, so we have
* to make a special case of checking for them. Plus, there's
* five groups of them, so we have a table of mask/opcode pairs
* to check against, and if any match then we branch off into the
* NEON handler code.
*
* Emulators may wish to make use of the following registers:
* r0 = instruction opcode (32-bit ARM or two 16-bit Thumb)
* r2 = PC value to resume execution after successful emulation
* r9 = normal "successful" return address
* r10 = this threads thread_info structure
* lr = unrecognised instruction return address
* IRQs disabled, FIQs enabled.
*/
@
@ Fall-through from Thumb-2 __und_usr
@
#ifdef CONFIG_NEON
get_thread_info r10 @ get current thread
adr r6, .LCneon_thumb_opcodes
b 2f
#endif
call_fpe:
get_thread_info r10 @ get current thread
#ifdef CONFIG_NEON
adr r6, .LCneon_arm_opcodes
2: ldr r5, [r6], #4 @ mask value
ldr r7, [r6], #4 @ opcode bits matching in mask
cmp r5, #0 @ end mask?
beq 1f
and r8, r0, r5
cmp r8, r7 @ NEON instruction?
bne 2b
mov r7, #1
strb r7, [r10, #TI_USED_CP + 10] @ mark CP#10 as used
strb r7, [r10, #TI_USED_CP + 11] @ mark CP#11 as used
b do_vfp @ let VFP handler handle this
1:
#endif
tst r0, #0x08000000 @ only CDP/CPRT/LDC/STC have bit 27
tstne r0, #0x04000000 @ bit 26 set on both ARM and Thumb-2
moveq pc, lr
and r8, r0, #0x00000f00 @ mask out CP number
THUMB( lsr r8, r8, #8 )
mov r7, #1
add r6, r10, #TI_USED_CP
ARM( strb r7, [r6, r8, lsr #8] ) @ set appropriate used_cp[]
THUMB( strb r7, [r6, r8] ) @ set appropriate used_cp[]
#ifdef CONFIG_IWMMXT
@ Test if we need to give access to iWMMXt coprocessors
ldr r5, [r10, #TI_FLAGS]
rsbs r7, r8, #(1 << 8) @ CP 0 or 1 only
movcss r7, r5, lsr #(TIF_USING_IWMMXT + 1)
bcs iwmmxt_task_enable
#endif
ARM( add pc, pc, r8, lsr #6 )
THUMB( lsl r8, r8, #2 )
THUMB( add pc, r8 )
nop
movw_pc lr @ CP#0
W(b) do_fpe @ CP#1 (FPE)
W(b) do_fpe @ CP#2 (FPE)
movw_pc lr @ CP#3
#ifdef CONFIG_CRUNCH
b crunch_task_enable @ CP#4 (MaverickCrunch)
b crunch_task_enable @ CP#5 (MaverickCrunch)
b crunch_task_enable @ CP#6 (MaverickCrunch)
#else
movw_pc lr @ CP#4
movw_pc lr @ CP#5
movw_pc lr @ CP#6
#endif
movw_pc lr @ CP#7
movw_pc lr @ CP#8
movw_pc lr @ CP#9
#ifdef CONFIG_VFP
W(b) do_vfp @ CP#10 (VFP)
W(b) do_vfp @ CP#11 (VFP)
#else
movw_pc lr @ CP#10 (VFP)
movw_pc lr @ CP#11 (VFP)
#endif
movw_pc lr @ CP#12
movw_pc lr @ CP#13
movw_pc lr @ CP#14 (Debug)
movw_pc lr @ CP#15 (Control)
#ifdef NEED_CPU_ARCHITECTURE
.align 2
.LCcpu_architecture:
.word __cpu_architecture
#endif
#ifdef CONFIG_NEON
.align 6
.LCneon_arm_opcodes:
.word 0xfe000000 @ mask
.word 0xf2000000 @ opcode
.word 0xff100000 @ mask
.word 0xf4000000 @ opcode
.word 0x00000000 @ mask
.word 0x00000000 @ opcode
.LCneon_thumb_opcodes:
.word 0xef000000 @ mask
.word 0xef000000 @ opcode
.word 0xff100000 @ mask
.word 0xf9000000 @ opcode
.word 0x00000000 @ mask
.word 0x00000000 @ opcode
#endif
do_fpe:
enable_irq
ldr r4, .LCfp
add r10, r10, #TI_FPSTATE @ r10 = workspace
ldr pc, [r4] @ Call FP module USR entry point
/*
* The FP module is called with these registers set:
* r0 = instruction
* r2 = PC+4
* r9 = normal "successful" return address
* r10 = FP workspace
* lr = unrecognised FP instruction return address
*/
.pushsection .data
ENTRY(fp_enter)
.word no_fp
.popsection
ENTRY(no_fp)
mov pc, lr
ENDPROC(no_fp)
__und_usr_fault_32:
mov r1, #4
b 1f
__und_usr_fault_16:
mov r1, #2
1: enable_irq
mov r0, sp
adr lr, BSYM(ret_from_exception)
b __und_fault
ENDPROC(__und_usr_fault_32)
ENDPROC(__und_usr_fault_16)
.align 5
__pabt_usr:
usr_entry
mov r2, sp @ regs
pabt_helper
UNWIND(.fnend )
/* fall through */
/*
* This is the return code to user mode for abort handlers
*/
ENTRY(ret_from_exception)
UNWIND(.fnstart )
UNWIND(.cantunwind )
get_thread_info tsk
mov why, #0
b ret_to_user
UNWIND(.fnend )
ENDPROC(__pabt_usr)
ENDPROC(ret_from_exception)
/*
* Register switch for ARMv3 and ARMv4 processors
* r0 = previous task_struct, r1 = previous thread_info, r2 = next thread_info
* previous and next are guaranteed not to be the same.
*/
ENTRY(__switch_to)
UNWIND(.fnstart )
UNWIND(.cantunwind )
add ip, r1, #TI_CPU_SAVE
ARM( stmia ip!, {r4 - sl, fp, sp, lr} ) @ Store most regs on stack
THUMB( stmia ip!, {r4 - sl, fp} ) @ Store most regs on stack
THUMB( str sp, [ip], #4 )
THUMB( str lr, [ip], #4 )
ldr r4, [r2, #TI_TP_VALUE]
ldr r5, [r2, #TI_TP_VALUE + 4]
#ifdef CONFIG_CPU_USE_DOMAINS
ldr r6, [r2, #TI_CPU_DOMAIN]
#endif
switch_tls r1, r4, r5, r3, r7
#if defined(CONFIG_CC_STACKPROTECTOR) && !defined(CONFIG_SMP)
ldr r7, [r2, #TI_TASK]
ldr r8, =__stack_chk_guard
ldr r7, [r7, #TSK_STACK_CANARY]
#endif
#ifdef CONFIG_CPU_USE_DOMAINS
mcr p15, 0, r6, c3, c0, 0 @ Set domain register
#endif
mov r5, r0
add r4, r2, #TI_CPU_SAVE
ldr r0, =thread_notify_head
mov r1, #THREAD_NOTIFY_SWITCH
bl atomic_notifier_call_chain
#if defined(CONFIG_CC_STACKPROTECTOR) && !defined(CONFIG_SMP)
str r7, [r8]
#endif
THUMB( mov ip, r4 )
mov r0, r5
ARM( ldmia r4, {r4 - sl, fp, sp, pc} ) @ Load all regs saved previously
THUMB( ldmia ip!, {r4 - sl, fp} ) @ Load all regs saved previously
THUMB( ldr sp, [ip], #4 )
THUMB( ldr pc, [ip] )
UNWIND(.fnend )
ENDPROC(__switch_to)
__INIT
/*
* User helpers.
*
* Each segment is 32-byte aligned and will be moved to the top of the high
* vector page. New segments (if ever needed) must be added in front of
* existing ones. This mechanism should be used only for things that are
* really small and justified, and not be abused freely.
*
* See Documentation/arm/kernel_user_helpers.txt for formal definitions.
*/
THUMB( .arm )
.macro usr_ret, reg
#ifdef CONFIG_ARM_THUMB
bx \reg
#else
mov pc, \reg
#endif
.endm
.macro kuser_pad, sym, size
.if (. - \sym) & 3
.rept 4 - (. - \sym) & 3
.byte 0
.endr
.endif
.rept (\size - (. - \sym)) / 4
.word 0xe7fddef1
.endr
.endm
#ifdef CONFIG_KUSER_HELPERS
.align 5
.globl __kuser_helper_start
__kuser_helper_start:
/*
* Due to the length of some sequences, __kuser_cmpxchg64 spans 2 regular
* kuser "slots", therefore 0xffff0f80 is not used as a valid entry point.
*/
__kuser_cmpxchg64: @ 0xffff0f60
#if defined(CONFIG_NEEDS_SYSCALL_FOR_CMPXCHG)
/*
* Poor you. No fast solution possible...
* The kernel itself must perform the operation.
* A special ghost syscall is used for that (see traps.c).
*/
stmfd sp!, {r7, lr}
ldr r7, 1f @ it's 20 bits
swi __ARM_NR_cmpxchg64
ldmfd sp!, {r7, pc}
1: .word __ARM_NR_cmpxchg64
#elif defined(CONFIG_CPU_32v6K)
stmfd sp!, {r4, r5, r6, r7}
ldrd r4, r5, [r0] @ load old val
ldrd r6, r7, [r1] @ load new val
smp_dmb arm
1: ldrexd r0, r1, [r2] @ load current val
eors r3, r0, r4 @ compare with oldval (1)
eoreqs r3, r1, r5 @ compare with oldval (2)
strexdeq r3, r6, r7, [r2] @ store newval if eq
teqeq r3, #1 @ success?
beq 1b @ if no then retry
smp_dmb arm
rsbs r0, r3, #0 @ set returned val and C flag
ldmfd sp!, {r4, r5, r6, r7}
usr_ret lr
#elif !defined(CONFIG_SMP)
#ifdef CONFIG_MMU
/*
* The only thing that can break atomicity in this cmpxchg64
* implementation is either an IRQ or a data abort exception
* causing another process/thread to be scheduled in the middle of
* the critical sequence. The same strategy as for cmpxchg is used.
*/
stmfd sp!, {r4, r5, r6, lr}
ldmia r0, {r4, r5} @ load old val
ldmia r1, {r6, lr} @ load new val
1: ldmia r2, {r0, r1} @ load current val
eors r3, r0, r4 @ compare with oldval (1)
eoreqs r3, r1, r5 @ compare with oldval (2)
2: stmeqia r2, {r6, lr} @ store newval if eq
rsbs r0, r3, #0 @ set return val and C flag
ldmfd sp!, {r4, r5, r6, pc}
.text
kuser_cmpxchg64_fixup:
@ Called from kuser_cmpxchg_fixup.
@ r4 = address of interrupted insn (must be preserved).
@ sp = saved regs. r7 and r8 are clobbered.
@ 1b = first critical insn, 2b = last critical insn.
@ If r4 >= 1b and r4 <= 2b then saved pc_usr is set to 1b.
mov r7, #0xffff0fff
sub r7, r7, #(0xffff0fff - (0xffff0f60 + (1b - __kuser_cmpxchg64)))
subs r8, r4, r7
rsbcss r8, r8, #(2b - 1b)
strcs r7, [sp, #S_PC]
#if __LINUX_ARM_ARCH__ < 6
bcc kuser_cmpxchg32_fixup
#endif
mov pc, lr
.previous
#else
#warning "NPTL on non MMU needs fixing"
mov r0, #-1
adds r0, r0, #0
usr_ret lr
#endif
#else
#error "incoherent kernel configuration"
#endif
kuser_pad __kuser_cmpxchg64, 64
__kuser_memory_barrier: @ 0xffff0fa0
smp_dmb arm
usr_ret lr
kuser_pad __kuser_memory_barrier, 32
__kuser_cmpxchg: @ 0xffff0fc0
#if defined(CONFIG_NEEDS_SYSCALL_FOR_CMPXCHG)
/*
* Poor you. No fast solution possible...
* The kernel itself must perform the operation.
* A special ghost syscall is used for that (see traps.c).
*/
stmfd sp!, {r7, lr}
ldr r7, 1f @ it's 20 bits
swi __ARM_NR_cmpxchg
ldmfd sp!, {r7, pc}
1: .word __ARM_NR_cmpxchg
#elif __LINUX_ARM_ARCH__ < 6
#ifdef CONFIG_MMU
/*
* The only thing that can break atomicity in this cmpxchg
* implementation is either an IRQ or a data abort exception
* causing another process/thread to be scheduled in the middle
* of the critical sequence. To prevent this, code is added to
* the IRQ and data abort exception handlers to set the pc back
* to the beginning of the critical section if it is found to be
* within that critical section (see kuser_cmpxchg_fixup).
*/
1: ldr r3, [r2] @ load current val
subs r3, r3, r0 @ compare with oldval
2: streq r1, [r2] @ store newval if eq
rsbs r0, r3, #0 @ set return val and C flag
usr_ret lr
.text
kuser_cmpxchg32_fixup:
@ Called from kuser_cmpxchg_check macro.
@ r4 = address of interrupted insn (must be preserved).
@ sp = saved regs. r7 and r8 are clobbered.
@ 1b = first critical insn, 2b = last critical insn.
@ If r4 >= 1b and r4 <= 2b then saved pc_usr is set to 1b.
mov r7, #0xffff0fff
sub r7, r7, #(0xffff0fff - (0xffff0fc0 + (1b - __kuser_cmpxchg)))
subs r8, r4, r7
rsbcss r8, r8, #(2b - 1b)
strcs r7, [sp, #S_PC]
mov pc, lr
.previous
#else
#warning "NPTL on non MMU needs fixing"
mov r0, #-1
adds r0, r0, #0
usr_ret lr
#endif
#else
smp_dmb arm
1: ldrex r3, [r2]
subs r3, r3, r0
strexeq r3, r1, [r2]
teqeq r3, #1
beq 1b
rsbs r0, r3, #0
/* beware -- each __kuser slot must be 8 instructions max */
ALT_SMP(b __kuser_memory_barrier)
ALT_UP(usr_ret lr)
#endif
kuser_pad __kuser_cmpxchg, 32
__kuser_get_tls: @ 0xffff0fe0
ldr r0, [pc, #(16 - 8)] @ read TLS, set in kuser_get_tls_init
usr_ret lr
mrc p15, 0, r0, c13, c0, 3 @ 0xffff0fe8 hardware TLS code
kuser_pad __kuser_get_tls, 16
.rep 3
.word 0 @ 0xffff0ff0 software TLS value, then
.endr @ pad up to __kuser_helper_version
__kuser_helper_version: @ 0xffff0ffc
.word ((__kuser_helper_end - __kuser_helper_start) >> 5)
.globl __kuser_helper_end
__kuser_helper_end:
#endif
THUMB( .thumb )
/*
* Vector stubs.
*
* This code is copied to 0xffff1000 so we can use branches in the
* vectors, rather than ldr's. Note that this code must not exceed
* a page size.
*
* Common stub entry macro:
* Enter in IRQ mode, spsr = SVC/USR CPSR, lr = SVC/USR PC
*
* SP points to a minimal amount of processor-private memory, the address
* of which is copied into r0 for the mode specific abort handler.
*/
.macro vector_stub, name, mode, correction=0
.align 5
vector_\name:
.if \correction
sub lr, lr, #\correction
.endif
@
@ Save r0, lr_<exception> (parent PC) and spsr_<exception>
@ (parent CPSR)
@
stmia sp, {r0, lr} @ save r0, lr
mrs lr, spsr
str lr, [sp, #8] @ save spsr
@
@ Prepare for SVC32 mode. IRQs remain disabled.
@
mrs r0, cpsr
eor r0, r0, #(\mode ^ SVC_MODE | PSR_ISETSTATE)
msr spsr_cxsf, r0
@
@ the branch table must immediately follow this code
@
and lr, lr, #0x0f
THUMB( adr r0, 1f )
THUMB( ldr lr, [r0, lr, lsl #2] )
mov r0, sp
ARM( ldr lr, [pc, lr, lsl #2] )
movs pc, lr @ branch to handler in SVC mode
ENDPROC(vector_\name)
.align 2
@ handler addresses follow this label
1:
.endm
.section .stubs, "ax", %progbits
__stubs_start:
@ This must be the first word
.word vector_swi
vector_rst:
ARM( swi SYS_ERROR0 )
THUMB( svc #0 )
THUMB( nop )
b vector_und
/*
* Interrupt dispatcher
*/
vector_stub irq, IRQ_MODE, 4
.long __irq_usr @ 0 (USR_26 / USR_32)
.long __irq_invalid @ 1 (FIQ_26 / FIQ_32)
.long __irq_invalid @ 2 (IRQ_26 / IRQ_32)
.long __irq_svc @ 3 (SVC_26 / SVC_32)
.long __irq_invalid @ 4
.long __irq_invalid @ 5
.long __irq_invalid @ 6
.long __irq_invalid @ 7
.long __irq_invalid @ 8
.long __irq_invalid @ 9
.long __irq_invalid @ a
.long __irq_invalid @ b
.long __irq_invalid @ c
.long __irq_invalid @ d
.long __irq_invalid @ e
.long __irq_invalid @ f
/*
* Data abort dispatcher
* Enter in ABT mode, spsr = USR CPSR, lr = USR PC
*/
vector_stub dabt, ABT_MODE, 8
.long __dabt_usr @ 0 (USR_26 / USR_32)
.long __dabt_invalid @ 1 (FIQ_26 / FIQ_32)
.long __dabt_invalid @ 2 (IRQ_26 / IRQ_32)
.long __dabt_svc @ 3 (SVC_26 / SVC_32)
.long __dabt_invalid @ 4
.long __dabt_invalid @ 5
.long __dabt_invalid @ 6
.long __dabt_invalid @ 7
.long __dabt_invalid @ 8
.long __dabt_invalid @ 9
.long __dabt_invalid @ a
.long __dabt_invalid @ b
.long __dabt_invalid @ c
.long __dabt_invalid @ d
.long __dabt_invalid @ e
.long __dabt_invalid @ f
/*
* Prefetch abort dispatcher
* Enter in ABT mode, spsr = USR CPSR, lr = USR PC
*/
vector_stub pabt, ABT_MODE, 4
.long __pabt_usr @ 0 (USR_26 / USR_32)
.long __pabt_invalid @ 1 (FIQ_26 / FIQ_32)
.long __pabt_invalid @ 2 (IRQ_26 / IRQ_32)
.long __pabt_svc @ 3 (SVC_26 / SVC_32)
.long __pabt_invalid @ 4
.long __pabt_invalid @ 5
.long __pabt_invalid @ 6
.long __pabt_invalid @ 7
.long __pabt_invalid @ 8
.long __pabt_invalid @ 9
.long __pabt_invalid @ a
.long __pabt_invalid @ b
.long __pabt_invalid @ c
.long __pabt_invalid @ d
.long __pabt_invalid @ e
.long __pabt_invalid @ f
/*
* Undef instr entry dispatcher
* Enter in UND mode, spsr = SVC/USR CPSR, lr = SVC/USR PC
*/
vector_stub und, UND_MODE
.long __und_usr @ 0 (USR_26 / USR_32)
.long __und_invalid @ 1 (FIQ_26 / FIQ_32)
.long __und_invalid @ 2 (IRQ_26 / IRQ_32)
.long __und_svc @ 3 (SVC_26 / SVC_32)
.long __und_invalid @ 4
.long __und_invalid @ 5
.long __und_invalid @ 6
.long __und_invalid @ 7
.long __und_invalid @ 8
.long __und_invalid @ 9
.long __und_invalid @ a
.long __und_invalid @ b
.long __und_invalid @ c
.long __und_invalid @ d
.long __und_invalid @ e
.long __und_invalid @ f
.align 5
/*=============================================================================
* Address exception handler
*-----------------------------------------------------------------------------
* These aren't too critical.
* (they're not supposed to happen, and won't happen in 32-bit data mode).
*/
vector_addrexcptn:
b vector_addrexcptn
/*=============================================================================
* Undefined FIQs
*-----------------------------------------------------------------------------
* Enter in FIQ mode, spsr = ANY CPSR, lr = ANY PC
* MUST PRESERVE SVC SPSR, but need to switch to SVC mode to show our msg.
* Basically to switch modes, we *HAVE* to clobber one register... brain
* damage alert! I don't think that we can execute any code in here in any
* other mode than FIQ... Ok you can switch to another mode, but you can't
* get out of that mode without clobbering one register.
*/
vector_fiq:
subs pc, lr, #4
.globl vector_fiq_offset
.equ vector_fiq_offset, vector_fiq
.section .vectors, "ax", %progbits
__vectors_start:
W(b) vector_rst
W(b) vector_und
W(ldr) pc, __vectors_start + 0x1000
W(b) vector_pabt
W(b) vector_dabt
W(b) vector_addrexcptn
W(b) vector_irq
W(b) vector_fiq
.data
.globl cr_alignment
.globl cr_no_alignment
cr_alignment:
.space 4
cr_no_alignment:
.space 4
#ifdef CONFIG_MULTI_IRQ_HANDLER
.globl handle_arch_irq
handle_arch_irq:
.space 4
#endif
S文件是预处理加汇编文件,s是汇编文件。
__vectors_start是异常向量表的起始地址,在内核的启动过程中会将异常向量表搬移到0xFFFF0000的位置,通过设置处理器的相关寄存器可以对异常向量表进行重映射。当IRQ中断发生后,程序将直接跳转到0xFFFF0018 地址处,去执行“b vector_irq”这条指令,从而程序再次跳转,去执行 vector_irq 后的代码。代码第 7行至第 10行调整了链接寄存器Ir 中的中断返回地址的值,然后将 r0、Ir、spsr 的寄存器保存到IRQ模式下的栈(注意,此时的栈是向上生长的)。代码第 11 行至第 13 行取出了 cpsr 的值,并将模式位修改为SVC模式且保存到spsr 寄存器中,这是为后面将模式由IRQ模式切换到SVC模式准备。代码第 14 行至第 22行 将lr的低4位(即 spsr 的低4位,这是在中断发生前的处理模式的低4位)取出来,并根据其值来选择是调用_irq_usr还是调用_irq_svc,代码第16行利用 pc 寄存器来做间接寻址,pc 的值是下两条指令的地址值,所以如果中断发生前是 USER 模式,那么将会把 __irq_usr 的地址装载到lr 存器中,进而装到pc寄存器中,从而跳转到 __irq_usr 处执行代码。相应的,如果之前是 SVC模式,那么就会跳转到 __irq_svc 处执行代码。这里分别对应了中断是打断了应用层的代码,还是内核层的代码。
__irq_usr 调用了usr_entry 和 kuser_cmpxchg_check 两个宏分别进行了栈的准备,寄存器入栈和应用层的原子比较交换检查的相关操作,然后调用 irq_handler 宏进一步处理中断。 __irq_svc相对要简单一些,只调用了 svc_entry宏进行了栈的准备,寄存器入栈的操作,最后也调用irq_handler 宏进一步处理中断。
irq_handler宏获取了标号 handle_arch_irg 内存中的内容,然后将sp 的值复制到r0寄存器作为后面调用函数的第一个参数,接下来将返回地址保存至 lr 寄存器,最后调用了handle_arch_irg 内存中记录的函数,在 Exynos4412 处理器所对应的代码中,该函数是gic_handle_irq,后面将会进一步分析。irq _handler 返回后,进行了一些现场恢复的操作。在__irq_svc 中还判断了是否配置了内核抢占来决定是否可以重新调度,从而抢占内核。而__irq_usr 则不管内核抢占是否配置,都要检查是否需要重新调度,因为中断可能把具有高优先级的进程唤醒,那么应该立即调度这个被唤醒的进程。
gic_handle_irq函数的关键代码如下。
/*drivers/irqchip/irq-gic.c */
/*
* linux/arch/arm/common/gic.c
*
* Copyright (C) 2002 ARM Limited, All Rights Reserved.
*
* This program is free software; you can redistribute it and/or modify
* it under the terms of the GNU General Public License version 2 as
* published by the Free Software Foundation.
*
* Interrupt architecture for the GIC:
*
* o There is one Interrupt Distributor, which receives interrupts
* from system devices and sends them to the Interrupt Controllers.
*
* o There is one CPU Interface per CPU, which sends interrupts sent
* by the Distributor, and interrupts generated locally, to the
* associated CPU. The base address of the CPU interface is usually
* aliased so that the same address points to different chips depending
* on the CPU it is accessed from.
*
* Note that IRQs 0-31 are special - they are local to each CPU.
* As such, the enable set/clear, pending set/clear and active bit
* registers are banked per-cpu for these sources.
*/
#include <linux/init.h>
#include <linux/kernel.h>
#include <linux/err.h>
#include <linux/module.h>
#include <linux/list.h>
#include <linux/smp.h>
#include <linux/cpu.h>
#include <linux/cpu_pm.h>
#include <linux/cpumask.h>
#include <linux/io.h>
#include <linux/of.h>
#include <linux/of_address.h>
#include <linux/of_irq.h>
#include <linux/irqdomain.h>
#include <linux/interrupt.h>
#include <linux/percpu.h>
#include <linux/slab.h>
#include <linux/irqchip/chained_irq.h>
#include <linux/irqchip/arm-gic.h>
#include <asm/irq.h>
#include <asm/exception.h>
#include <asm/smp_plat.h>
#include "irqchip.h"
union gic_base {
void __iomem *common_base;
void __percpu __iomem **percpu_base;
};
struct gic_chip_data {
union gic_base dist_base;
union gic_base cpu_base;
#ifdef CONFIG_CPU_PM
u32 saved_spi_enable[DIV_ROUND_UP(1020, 32)];
u32 saved_spi_conf[DIV_ROUND_UP(1020, 16)];
u32 saved_spi_target[DIV_ROUND_UP(1020, 4)];
u32 __percpu *saved_ppi_enable;
u32 __percpu *saved_ppi_conf;
#endif
struct irq_domain *domain;
unsigned int gic_irqs;
#ifdef CONFIG_GIC_NON_BANKED
void __iomem *(*get_base)(union gic_base *);
#endif
};
static DEFINE_RAW_SPINLOCK(irq_controller_lock);
/*
* The GIC mapping of CPU interfaces does not necessarily match
* the logical CPU numbering. Let's use a mapping as returned
* by the GIC itself.
*/
#define NR_GIC_CPU_IF 8
static u8 gic_cpu_map[NR_GIC_CPU_IF] __read_mostly;
/*
* Supported arch specific GIC irq extension.
* Default make them NULL.
*/
struct irq_chip gic_arch_extn = {
.irq_eoi = NULL,
.irq_mask = NULL,
.irq_unmask = NULL,
.irq_retrigger = NULL,
.irq_set_type = NULL,
.irq_set_wake = NULL,
};
#ifndef MAX_GIC_NR
#define MAX_GIC_NR 1
#endif
static struct gic_chip_data gic_data[MAX_GIC_NR] __read_mostly;
#ifdef CONFIG_GIC_NON_BANKED
static void __iomem *gic_get_percpu_base(union gic_base *base)
{
return *__this_cpu_ptr(base->percpu_base);
}
static void __iomem *gic_get_common_base(union gic_base *base)
{
return base->common_base;
}
static inline void __iomem *gic_data_dist_base(struct gic_chip_data *data)
{
return data->get_base(&data->dist_base);
}
static inline void __iomem *gic_data_cpu_base(struct gic_chip_data *data)
{
return data->get_base(&data->cpu_base);
}
static inline void gic_set_base_accessor(struct gic_chip_data *data,
void __iomem *(*f)(union gic_base *))
{
data->get_base = f;
}
#else
#define gic_data_dist_base(d) ((d)->dist_base.common_base)
#define gic_data_cpu_base(d) ((d)->cpu_base.common_base)
#define gic_set_base_accessor(d, f)
#endif
static inline void __iomem *gic_dist_base(struct irq_data *d)
{
struct gic_chip_data *gic_data = irq_data_get_irq_chip_data(d);
return gic_data_dist_base(gic_data);
}
static inline void __iomem *gic_cpu_base(struct irq_data *d)
{
struct gic_chip_data *gic_data = irq_data_get_irq_chip_data(d);
return gic_data_cpu_base(gic_data);
}
static inline unsigned int gic_irq(struct irq_data *d)
{
return d->hwirq;
}
/*
* Routines to acknowledge, disable and enable interrupts
*/
static void gic_mask_irq(struct irq_data *d)
{
u32 mask = 1 << (gic_irq(d) % 32);
raw_spin_lock(&irq_controller_lock);
writel_relaxed(mask, gic_dist_base(d) + GIC_DIST_ENABLE_CLEAR + (gic_irq(d) / 32) * 4);
if (gic_arch_extn.irq_mask)
gic_arch_extn.irq_mask(d);
raw_spin_unlock(&irq_controller_lock);
}
static void gic_unmask_irq(struct irq_data *d)
{
u32 mask = 1 << (gic_irq(d) % 32);
raw_spin_lock(&irq_controller_lock);
if (gic_arch_extn.irq_unmask)
gic_arch_extn.irq_unmask(d);
writel_relaxed(mask, gic_dist_base(d) + GIC_DIST_ENABLE_SET + (gic_irq(d) / 32) * 4);
raw_spin_unlock(&irq_controller_lock);
}
static void gic_eoi_irq(struct irq_data *d)
{
if (gic_arch_extn.irq_eoi) {
raw_spin_lock(&irq_controller_lock);
gic_arch_extn.irq_eoi(d);
raw_spin_unlock(&irq_controller_lock);
}
writel_relaxed(gic_irq(d), gic_cpu_base(d) + GIC_CPU_EOI);
}
static int gic_set_type(struct irq_data *d, unsigned int type)
{
void __iomem *base = gic_dist_base(d);
unsigned int gicirq = gic_irq(d);
u32 enablemask = 1 << (gicirq % 32);
u32 enableoff = (gicirq / 32) * 4;
u32 confmask = 0x2 << ((gicirq % 16) * 2);
u32 confoff = (gicirq / 16) * 4;
bool enabled = false;
u32 val;
/* Interrupt configuration for SGIs can't be changed */
if (gicirq < 16)
return -EINVAL;
if (type != IRQ_TYPE_LEVEL_HIGH && type != IRQ_TYPE_EDGE_RISING)
return -EINVAL;
raw_spin_lock(&irq_controller_lock);
if (gic_arch_extn.irq_set_type)
gic_arch_extn.irq_set_type(d, type);
val = readl_relaxed(base + GIC_DIST_CONFIG + confoff);
if (type == IRQ_TYPE_LEVEL_HIGH)
val &= ~confmask;
else if (type == IRQ_TYPE_EDGE_RISING)
val |= confmask;
/*
* As recommended by the spec, disable the interrupt before changing
* the configuration
*/
if (readl_relaxed(base + GIC_DIST_ENABLE_SET + enableoff) & enablemask) {
writel_relaxed(enablemask, base + GIC_DIST_ENABLE_CLEAR + enableoff);
enabled = true;
}
writel_relaxed(val, base + GIC_DIST_CONFIG + confoff);
if (enabled)
writel_relaxed(enablemask, base + GIC_DIST_ENABLE_SET + enableoff);
raw_spin_unlock(&irq_controller_lock);
return 0;
}
static int gic_retrigger(struct irq_data *d)
{
if (gic_arch_extn.irq_retrigger)
return gic_arch_extn.irq_retrigger(d);
/* the genirq layer expects 0 if we can't retrigger in hardware */
return 0;
}
#ifdef CONFIG_SMP
static int gic_set_affinity(struct irq_data *d, const struct cpumask *mask_val,
bool force)
{
void __iomem *reg = gic_dist_base(d) + GIC_DIST_TARGET + (gic_irq(d) & ~3);
unsigned int shift = (gic_irq(d) % 4) * 8;
unsigned int cpu = cpumask_any_and(mask_val, cpu_online_mask);
u32 val, mask, bit;
if (cpu >= NR_GIC_CPU_IF || cpu >= nr_cpu_ids)
return -EINVAL;
raw_spin_lock(&irq_controller_lock);
mask = 0xff << shift;
bit = gic_cpu_map[cpu] << shift;
val = readl_relaxed(reg) & ~mask;
writel_relaxed(val | bit, reg);
raw_spin_unlock(&irq_controller_lock);
return IRQ_SET_MASK_OK;
}
#endif
#ifdef CONFIG_PM
static int gic_set_wake(struct irq_data *d, unsigned int on)
{
int ret = -ENXIO;
if (gic_arch_extn.irq_set_wake)
ret = gic_arch_extn.irq_set_wake(d, on);
return ret;
}
#else
#define gic_set_wake NULL
#endif
static asmlinkage void __exception_irq_entry gic_handle_irq(struct pt_regs *regs)
{
u32 irqstat, irqnr;
struct gic_chip_data *gic = &gic_data[0];
void __iomem *cpu_base = gic_data_cpu_base(gic);
do {
irqstat = readl_relaxed(cpu_base + GIC_CPU_INTACK);
irqnr = irqstat & ~0x1c00;
if (likely(irqnr > 15 && irqnr < 1021)) {
irqnr = irq_find_mapping(gic->domain, irqnr);
handle_IRQ(irqnr, regs);
continue;
}
if (irqnr < 16) {
writel_relaxed(irqstat, cpu_base + GIC_CPU_EOI);
#ifdef CONFIG_SMP
handle_IPI(irqnr, regs);
#endif
continue;
}
break;
} while (1);
}
static void gic_handle_cascade_irq(unsigned int irq, struct irq_desc *desc)
{
struct gic_chip_data *chip_data = irq_get_handler_data(irq);
struct irq_chip *chip = irq_get_chip(irq);
unsigned int cascade_irq, gic_irq;
unsigned long status;
chained_irq_enter(chip, desc);
raw_spin_lock(&irq_controller_lock);
status = readl_relaxed(gic_data_cpu_base(chip_data) + GIC_CPU_INTACK);
raw_spin_unlock(&irq_controller_lock);
gic_irq = (status & 0x3ff);
if (gic_irq == 1023)
goto out;
cascade_irq = irq_find_mapping(chip_data->domain, gic_irq);
if (unlikely(gic_irq < 32 || gic_irq > 1020))
handle_bad_irq(cascade_irq, desc);
else
generic_handle_irq(cascade_irq);
out:
chained_irq_exit(chip, desc);
}
static struct irq_chip gic_chip = {
.name = "GIC",
.irq_mask = gic_mask_irq,
.irq_unmask = gic_unmask_irq,
.irq_eoi = gic_eoi_irq,
.irq_set_type = gic_set_type,
.irq_retrigger = gic_retrigger,
#ifdef CONFIG_SMP
.irq_set_affinity = gic_set_affinity,
#endif
.irq_set_wake = gic_set_wake,
};
void __init gic_cascade_irq(unsigned int gic_nr, unsigned int irq)
{
if (gic_nr >= MAX_GIC_NR)
BUG();
if (irq_set_handler_data(irq, &gic_data[gic_nr]) != 0)
BUG();
irq_set_chained_handler(irq, gic_handle_cascade_irq);
}
static u8 gic_get_cpumask(struct gic_chip_data *gic)
{
void __iomem *base = gic_data_dist_base(gic);
u32 mask, i;
for (i = mask = 0; i < 32; i += 4) {
mask = readl_relaxed(base + GIC_DIST_TARGET + i);
mask |= mask >> 16;
mask |= mask >> 8;
if (mask)
break;
}
if (!mask)
pr_crit("GIC CPU mask not found - kernel will fail to boot.\n");
return mask;
}
static void __init gic_dist_init(struct gic_chip_data *gic)
{
unsigned int i;
u32 cpumask;
unsigned int gic_irqs = gic->gic_irqs;
void __iomem *base = gic_data_dist_base(gic);
writel_relaxed(0, base + GIC_DIST_CTRL);
/*
* Set all global interrupts to be level triggered, active low.
*/
for (i = 32; i < gic_irqs; i += 16)
writel_relaxed(0, base + GIC_DIST_CONFIG + i * 4 / 16);
/*
* Set all global interrupts to this CPU only.
*/
cpumask = gic_get_cpumask(gic);
cpumask |= cpumask << 8;
cpumask |= cpumask << 16;
for (i = 32; i < gic_irqs; i += 4)
writel_relaxed(cpumask, base + GIC_DIST_TARGET + i * 4 / 4);
/*
* Set priority on all global interrupts.
*/
for (i = 32; i < gic_irqs; i += 4)
writel_relaxed(0xa0a0a0a0, base + GIC_DIST_PRI + i * 4 / 4);
/*
* Disable all interrupts. Leave the PPI and SGIs alone
* as these enables are banked registers.
*/
for (i = 32; i < gic_irqs; i += 32)
writel_relaxed(0xffffffff, base + GIC_DIST_ENABLE_CLEAR + i * 4 / 32);
writel_relaxed(1, base + GIC_DIST_CTRL);
}
static void gic_cpu_init(struct gic_chip_data *gic)
{
void __iomem *dist_base = gic_data_dist_base(gic);
void __iomem *base = gic_data_cpu_base(gic);
unsigned int cpu_mask, cpu = smp_processor_id();
int i;
/*
* Get what the GIC says our CPU mask is.
*/
BUG_ON(cpu >= NR_GIC_CPU_IF);
cpu_mask = gic_get_cpumask(gic);
gic_cpu_map[cpu] = cpu_mask;
/*
* Clear our mask from the other map entries in case they're
* still undefined.
*/
for (i = 0; i < NR_GIC_CPU_IF; i++)
if (i != cpu)
gic_cpu_map[i] &= ~cpu_mask;
/*
* Deal with the banked PPI and SGI interrupts - disable all
* PPI interrupts, ensure all SGI interrupts are enabled.
*/
writel_relaxed(0xffff0000, dist_base + GIC_DIST_ENABLE_CLEAR);
writel_relaxed(0x0000ffff, dist_base + GIC_DIST_ENABLE_SET);
/*
* Set priority on PPI and SGI interrupts
*/
for (i = 0; i < 32; i += 4)
writel_relaxed(0xa0a0a0a0, dist_base + GIC_DIST_PRI + i * 4 / 4);
writel_relaxed(0xf0, base + GIC_CPU_PRIMASK);
writel_relaxed(1, base + GIC_CPU_CTRL);
}
void gic_cpu_if_down(void)
{
void __iomem *cpu_base = gic_data_cpu_base(&gic_data[0]);
writel_relaxed(0, cpu_base + GIC_CPU_CTRL);
}
#ifdef CONFIG_CPU_PM
/*
* Saves the GIC distributor registers during suspend or idle. Must be called
* with interrupts disabled but before powering down the GIC. After calling
* this function, no interrupts will be delivered by the GIC, and another
* platform-specific wakeup source must be enabled.
*/
static void gic_dist_save(unsigned int gic_nr)
{
unsigned int gic_irqs;
void __iomem *dist_base;
int i;
if (gic_nr >= MAX_GIC_NR)
BUG();
gic_irqs = gic_data[gic_nr].gic_irqs;
dist_base = gic_data_dist_base(&gic_data[gic_nr]);
if (!dist_base)
return;
for (i = 0; i < DIV_ROUND_UP(gic_irqs, 16); i++)
gic_data[gic_nr].saved_spi_conf[i] =
readl_relaxed(dist_base + GIC_DIST_CONFIG + i * 4);
for (i = 0; i < DIV_ROUND_UP(gic_irqs, 4); i++)
gic_data[gic_nr].saved_spi_target[i] =
readl_relaxed(dist_base + GIC_DIST_TARGET + i * 4);
for (i = 0; i < DIV_ROUND_UP(gic_irqs, 32); i++)
gic_data[gic_nr].saved_spi_enable[i] =
readl_relaxed(dist_base + GIC_DIST_ENABLE_SET + i * 4);
}
/*
* Restores the GIC distributor registers during resume or when coming out of
* idle. Must be called before enabling interrupts. If a level interrupt
* that occured while the GIC was suspended is still present, it will be
* handled normally, but any edge interrupts that occured will not be seen by
* the GIC and need to be handled by the platform-specific wakeup source.
*/
static void gic_dist_restore(unsigned int gic_nr)
{
unsigned int gic_irqs;
unsigned int i;
void __iomem *dist_base;
if (gic_nr >= MAX_GIC_NR)
BUG();
gic_irqs = gic_data[gic_nr].gic_irqs;
dist_base = gic_data_dist_base(&gic_data[gic_nr]);
if (!dist_base)
return;
writel_relaxed(0, dist_base + GIC_DIST_CTRL);
for (i = 0; i < DIV_ROUND_UP(gic_irqs, 16); i++)
writel_relaxed(gic_data[gic_nr].saved_spi_conf[i],
dist_base + GIC_DIST_CONFIG + i * 4);
for (i = 0; i < DIV_ROUND_UP(gic_irqs, 4); i++)
writel_relaxed(0xa0a0a0a0,
dist_base + GIC_DIST_PRI + i * 4);
for (i = 0; i < DIV_ROUND_UP(gic_irqs, 4); i++)
writel_relaxed(gic_data[gic_nr].saved_spi_target[i],
dist_base + GIC_DIST_TARGET + i * 4);
for (i = 0; i < DIV_ROUND_UP(gic_irqs, 32); i++)
writel_relaxed(gic_data[gic_nr].saved_spi_enable[i],
dist_base + GIC_DIST_ENABLE_SET + i * 4);
writel_relaxed(1, dist_base + GIC_DIST_CTRL);
}
static void gic_cpu_save(unsigned int gic_nr)
{
int i;
u32 *ptr;
void __iomem *dist_base;
void __iomem *cpu_base;
if (gic_nr >= MAX_GIC_NR)
BUG();
dist_base = gic_data_dist_base(&gic_data[gic_nr]);
cpu_base = gic_data_cpu_base(&gic_data[gic_nr]);
if (!dist_base || !cpu_base)
return;
ptr = __this_cpu_ptr(gic_data[gic_nr].saved_ppi_enable);
for (i = 0; i < DIV_ROUND_UP(32, 32); i++)
ptr[i] = readl_relaxed(dist_base + GIC_DIST_ENABLE_SET + i * 4);
ptr = __this_cpu_ptr(gic_data[gic_nr].saved_ppi_conf);
for (i = 0; i < DIV_ROUND_UP(32, 16); i++)
ptr[i] = readl_relaxed(dist_base + GIC_DIST_CONFIG + i * 4);
}
static void gic_cpu_restore(unsigned int gic_nr)
{
int i;
u32 *ptr;
void __iomem *dist_base;
void __iomem *cpu_base;
if (gic_nr >= MAX_GIC_NR)
BUG();
dist_base = gic_data_dist_base(&gic_data[gic_nr]);
cpu_base = gic_data_cpu_base(&gic_data[gic_nr]);
if (!dist_base || !cpu_base)
return;
ptr = __this_cpu_ptr(gic_data[gic_nr].saved_ppi_enable);
for (i = 0; i < DIV_ROUND_UP(32, 32); i++)
writel_relaxed(ptr[i], dist_base + GIC_DIST_ENABLE_SET + i * 4);
ptr = __this_cpu_ptr(gic_data[gic_nr].saved_ppi_conf);
for (i = 0; i < DIV_ROUND_UP(32, 16); i++)
writel_relaxed(ptr[i], dist_base + GIC_DIST_CONFIG + i * 4);
for (i = 0; i < DIV_ROUND_UP(32, 4); i++)
writel_relaxed(0xa0a0a0a0, dist_base + GIC_DIST_PRI + i * 4);
writel_relaxed(0xf0, cpu_base + GIC_CPU_PRIMASK);
writel_relaxed(1, cpu_base + GIC_CPU_CTRL);
}
static int gic_notifier(struct notifier_block *self, unsigned long cmd, void *v)
{
int i;
for (i = 0; i < MAX_GIC_NR; i++) {
#ifdef CONFIG_GIC_NON_BANKED
/* Skip over unused GICs */
if (!gic_data[i].get_base)
continue;
#endif
switch (cmd) {
case CPU_PM_ENTER:
gic_cpu_save(i);
break;
case CPU_PM_ENTER_FAILED:
case CPU_PM_EXIT:
gic_cpu_restore(i);
break;
case CPU_CLUSTER_PM_ENTER:
gic_dist_save(i);
break;
case CPU_CLUSTER_PM_ENTER_FAILED:
case CPU_CLUSTER_PM_EXIT:
gic_dist_restore(i);
break;
}
}
return NOTIFY_OK;
}
static struct notifier_block gic_notifier_block = {
.notifier_call = gic_notifier,
};
static void __init gic_pm_init(struct gic_chip_data *gic)
{
gic->saved_ppi_enable = __alloc_percpu(DIV_ROUND_UP(32, 32) * 4,
sizeof(u32));
BUG_ON(!gic->saved_ppi_enable);
gic->saved_ppi_conf = __alloc_percpu(DIV_ROUND_UP(32, 16) * 4,
sizeof(u32));
BUG_ON(!gic->saved_ppi_conf);
if (gic == &gic_data[0])
cpu_pm_register_notifier(&gic_notifier_block);
}
#else
static void __init gic_pm_init(struct gic_chip_data *gic)
{
}
#endif
#ifdef CONFIG_SMP
void gic_raise_softirq(const struct cpumask *mask, unsigned int irq)
{
int cpu;
unsigned long flags, map = 0;
raw_spin_lock_irqsave(&irq_controller_lock, flags);
/* Convert our logical CPU mask into a physical one. */
for_each_cpu(cpu, mask)
map |= gic_cpu_map[cpu];
/*
* Ensure that stores to Normal memory are visible to the
* other CPUs before issuing the IPI.
*/
dsb();
/* this always happens on GIC0 */
writel_relaxed(map << 16 | irq, gic_data_dist_base(&gic_data[0]) + GIC_DIST_SOFTINT);
raw_spin_unlock_irqrestore(&irq_controller_lock, flags);
}
#endif
#ifdef CONFIG_BL_SWITCHER
/*
* gic_send_sgi - send a SGI directly to given CPU interface number
*
* cpu_id: the ID for the destination CPU interface
* irq: the IPI number to send a SGI for
*/
void gic_send_sgi(unsigned int cpu_id, unsigned int irq)
{
BUG_ON(cpu_id >= NR_GIC_CPU_IF);
cpu_id = 1 << cpu_id;
/* this always happens on GIC0 */
writel_relaxed((cpu_id << 16) | irq, gic_data_dist_base(&gic_data[0]) + GIC_DIST_SOFTINT);
}
/*
* gic_get_cpu_id - get the CPU interface ID for the specified CPU
*
* @cpu: the logical CPU number to get the GIC ID for.
*
* Return the CPU interface ID for the given logical CPU number,
* or -1 if the CPU number is too large or the interface ID is
* unknown (more than one bit set).
*/
int gic_get_cpu_id(unsigned int cpu)
{
unsigned int cpu_bit;
if (cpu >= NR_GIC_CPU_IF)
return -1;
cpu_bit = gic_cpu_map[cpu];
if (cpu_bit & (cpu_bit - 1))
return -1;
return __ffs(cpu_bit);
}
/*
* gic_migrate_target - migrate IRQs to another CPU interface
*
* @new_cpu_id: the CPU target ID to migrate IRQs to
*
* Migrate all peripheral interrupts with a target matching the current CPU
* to the interface corresponding to @new_cpu_id. The CPU interface mapping
* is also updated. Targets to other CPU interfaces are unchanged.
* This must be called with IRQs locally disabled.
*/
void gic_migrate_target(unsigned int new_cpu_id)
{
unsigned int cur_cpu_id, gic_irqs, gic_nr = 0;
void __iomem *dist_base;
int i, ror_val, cpu = smp_processor_id();
u32 val, cur_target_mask, active_mask;
if (gic_nr >= MAX_GIC_NR)
BUG();
dist_base = gic_data_dist_base(&gic_data[gic_nr]);
if (!dist_base)
return;
gic_irqs = gic_data[gic_nr].gic_irqs;
cur_cpu_id = __ffs(gic_cpu_map[cpu]);
cur_target_mask = 0x01010101 << cur_cpu_id;
ror_val = (cur_cpu_id - new_cpu_id) & 31;
raw_spin_lock(&irq_controller_lock);
/* Update the target interface for this logical CPU */
gic_cpu_map[cpu] = 1 << new_cpu_id;
/*
* Find all the peripheral interrupts targetting the current
* CPU interface and migrate them to the new CPU interface.
* We skip DIST_TARGET 0 to 7 as they are read-only.
*/
for (i = 8; i < DIV_ROUND_UP(gic_irqs, 4); i++) {
val = readl_relaxed(dist_base + GIC_DIST_TARGET + i * 4);
active_mask = val & cur_target_mask;
if (active_mask) {
val &= ~active_mask;
val |= ror32(active_mask, ror_val);
writel_relaxed(val, dist_base + GIC_DIST_TARGET + i*4);
}
}
raw_spin_unlock(&irq_controller_lock);
/*
* Now let's migrate and clear any potential SGIs that might be
* pending for us (cur_cpu_id). Since GIC_DIST_SGI_PENDING_SET
* is a banked register, we can only forward the SGI using
* GIC_DIST_SOFTINT. The original SGI source is lost but Linux
* doesn't use that information anyway.
*
* For the same reason we do not adjust SGI source information
* for previously sent SGIs by us to other CPUs either.
*/
for (i = 0; i < 16; i += 4) {
int j;
val = readl_relaxed(dist_base + GIC_DIST_SGI_PENDING_SET + i);
if (!val)
continue;
writel_relaxed(val, dist_base + GIC_DIST_SGI_PENDING_CLEAR + i);
for (j = i; j < i + 4; j++) {
if (val & 0xff)
writel_relaxed((1 << (new_cpu_id + 16)) | j,
dist_base + GIC_DIST_SOFTINT);
val >>= 8;
}
}
}
/*
* gic_get_sgir_physaddr - get the physical address for the SGI register
*
* REturn the physical address of the SGI register to be used
* by some early assembly code when the kernel is not yet available.
*/
static unsigned long gic_dist_physaddr;
unsigned long gic_get_sgir_physaddr(void)
{
if (!gic_dist_physaddr)
return 0;
return gic_dist_physaddr + GIC_DIST_SOFTINT;
}
void __init gic_init_physaddr(struct device_node *node)
{
struct resource res;
if (of_address_to_resource(node, 0, &res) == 0) {
gic_dist_physaddr = res.start;
pr_info("GIC physical location is %#lx\n", gic_dist_physaddr);
}
}
#else
#define gic_init_physaddr(node) do { } while (0)
#endif
static int gic_irq_domain_map(struct irq_domain *d, unsigned int irq,
irq_hw_number_t hw)
{
if (hw < 32) {
irq_set_percpu_devid(irq);
irq_set_chip_and_handler(irq, &gic_chip,
handle_percpu_devid_irq);
set_irq_flags(irq, IRQF_VALID | IRQF_NOAUTOEN);
} else {
irq_set_chip_and_handler(irq, &gic_chip,
handle_fasteoi_irq);
set_irq_flags(irq, IRQF_VALID | IRQF_PROBE);
}
irq_set_chip_data(irq, d->host_data);
return 0;
}
static int gic_irq_domain_xlate(struct irq_domain *d,
struct device_node *controller,
const u32 *intspec, unsigned int intsize,
unsigned long *out_hwirq, unsigned int *out_type)
{
if (d->of_node != controller)
return -EINVAL;
if (intsize < 3)
return -EINVAL;
/* Get the interrupt number and add 16 to skip over SGIs */
*out_hwirq = intspec[1] + 16;
/* For SPIs, we need to add 16 more to get the GIC irq ID number */
if (!intspec[0])
*out_hwirq += 16;
*out_type = intspec[2] & IRQ_TYPE_SENSE_MASK;
return 0;
}
#ifdef CONFIG_SMP
static int gic_secondary_init(struct notifier_block *nfb, unsigned long action,
void *hcpu)
{
if (action == CPU_STARTING || action == CPU_STARTING_FROZEN)
gic_cpu_init(&gic_data[0]);
return NOTIFY_OK;
}
/*
* Notifier for enabling the GIC CPU interface. Set an arbitrarily high
* priority because the GIC needs to be up before the ARM generic timers.
*/
static struct notifier_block gic_cpu_notifier = {
.notifier_call = gic_secondary_init,
.priority = 100,
};
#endif
const struct irq_domain_ops gic_irq_domain_ops = {
.map = gic_irq_domain_map,
.xlate = gic_irq_domain_xlate,
};
void __init gic_init_bases(unsigned int gic_nr, int irq_start,
void __iomem *dist_base, void __iomem *cpu_base,
u32 percpu_offset, struct device_node *node)
{
irq_hw_number_t hwirq_base;
struct gic_chip_data *gic;
int gic_irqs, irq_base, i;
BUG_ON(gic_nr >= MAX_GIC_NR);
gic = &gic_data[gic_nr];
#ifdef CONFIG_GIC_NON_BANKED
if (percpu_offset) { /* Frankein-GIC without banked registers... */
unsigned int cpu;
gic->dist_base.percpu_base = alloc_percpu(void __iomem *);
gic->cpu_base.percpu_base = alloc_percpu(void __iomem *);
if (WARN_ON(!gic->dist_base.percpu_base ||
!gic->cpu_base.percpu_base)) {
free_percpu(gic->dist_base.percpu_base);
free_percpu(gic->cpu_base.percpu_base);
return;
}
for_each_possible_cpu(cpu) {
unsigned long offset = percpu_offset * cpu_logical_map(cpu);
*per_cpu_ptr(gic->dist_base.percpu_base, cpu) = dist_base + offset;
*per_cpu_ptr(gic->cpu_base.percpu_base, cpu) = cpu_base + offset;
}
gic_set_base_accessor(gic, gic_get_percpu_base);
} else
#endif
{ /* Normal, sane GIC... */
WARN(percpu_offset,
"GIC_NON_BANKED not enabled, ignoring %08x offset!",
percpu_offset);
gic->dist_base.common_base = dist_base;
gic->cpu_base.common_base = cpu_base;
gic_set_base_accessor(gic, gic_get_common_base);
}
/*
* Initialize the CPU interface map to all CPUs.
* It will be refined as each CPU probes its ID.
*/
for (i = 0; i < NR_GIC_CPU_IF; i++)
gic_cpu_map[i] = 0xff;
/*
* For primary GICs, skip over SGIs.
* For secondary GICs, skip over PPIs, too.
*/
if (gic_nr == 0 && (irq_start & 31) > 0) {
hwirq_base = 16;
if (irq_start != -1)
irq_start = (irq_start & ~31) + 16;
} else {
hwirq_base = 32;
}
/*
* Find out how many interrupts are supported.
* The GIC only supports up to 1020 interrupt sources.
*/
gic_irqs = readl_relaxed(gic_data_dist_base(gic) + GIC_DIST_CTR) & 0x1f;
gic_irqs = (gic_irqs + 1) * 32;
if (gic_irqs > 1020)
gic_irqs = 1020;
gic->gic_irqs = gic_irqs;
gic_irqs -= hwirq_base; /* calculate # of irqs to allocate */
irq_base = irq_alloc_descs(irq_start, 16, gic_irqs, numa_node_id());
if (IS_ERR_VALUE(irq_base)) {
WARN(1, "Cannot allocate irq_descs @ IRQ%d, assuming pre-allocated\n",
irq_start);
irq_base = irq_start;
}
gic->domain = irq_domain_add_legacy(node, gic_irqs, irq_base,
hwirq_base, &gic_irq_domain_ops, gic);
if (WARN_ON(!gic->domain))
return;
if (gic_nr == 0) {
#ifdef CONFIG_SMP
set_smp_cross_call(gic_raise_softirq);
register_cpu_notifier(&gic_cpu_notifier);
#endif
set_handle_irq(gic_handle_irq);
}
gic_chip.flags |= gic_arch_extn.flags;
gic_dist_init(gic);
gic_cpu_init(gic);
gic_pm_init(gic);
}
#ifdef CONFIG_OF
static int gic_cnt __initdata;
int __init gic_of_init(struct device_node *node, struct device_node *parent)
{
void __iomem *cpu_base;
void __iomem *dist_base;
u32 percpu_offset;
int irq;
if (WARN_ON(!node))
return -ENODEV;
dist_base = of_iomap(node, 0);
WARN(!dist_base, "unable to map gic dist registers\n");
cpu_base = of_iomap(node, 1);
WARN(!cpu_base, "unable to map gic cpu registers\n");
if (of_property_read_u32(node, "cpu-offset", &percpu_offset))
percpu_offset = 0;
gic_init_bases(gic_cnt, -1, dist_base, cpu_base, percpu_offset, node);
if (!gic_cnt)
gic_init_physaddr(node);
if (parent) {
irq = irq_of_parse_and_map(node, 0);
gic_cascade_irq(gic_cnt, irq);
}
gic_cnt++;
return 0;
}
IRQCHIP_DECLARE(cortex_a15_gic, "arm,cortex-a15-gic", gic_of_init);
IRQCHIP_DECLARE(cortex_a9_gic, "arm,cortex-a9-gic", gic_of_init);
IRQCHIP_DECLARE(msm_8660_qgic, "qcom,msm-8660-qgic", gic_of_init);
IRQCHIP_DECLARE(msm_qgic2, "qcom,msm-qgic2", gic_of_init);
#endif
代码第294 行和第 295 行得到硬件的中断线IRQ号,代码第298 行将硬件的IRQ号转换为Linux 内核内部的IRQ 号,然后调用 handle_IRQ 来处理中断。另外,gic 能够记录最高优先级的中断,所以 handle_IRQ 返回后,可以再次读取是否有新的中断产生,从而处理新的中断。是否有新的中断可以通过中断号的值来判定。
在 handle_IRQ函数中主要对内核抢占计数器的值进行了操作(这部分内容在后面讲解),然后调用了 generic_handle_irq 函数,generic_handle_irq 函数的代码如下。/* kernel/irg/irgdesc.c*/
/*
* Copyright (C) 1992, 1998-2006 Linus Torvalds, Ingo Molnar
* Copyright (C) 2005-2006, Thomas Gleixner, Russell King
*
* This file contains the interrupt descriptor management code
*
* Detailed information is available in Documentation/DocBook/genericirq
*
*/
#include <linux/irq.h>
#include <linux/slab.h>
#include <linux/export.h>
#include <linux/interrupt.h>
#include <linux/kernel_stat.h>
#include <linux/radix-tree.h>
#include <linux/bitmap.h>
#include "internals.h"
/*
* lockdep: we want to handle all irq_desc locks as a single lock-class:
*/
static struct lock_class_key irq_desc_lock_class;
#if defined(CONFIG_SMP)
static void __init init_irq_default_affinity(void)
{
alloc_cpumask_var(&irq_default_affinity, GFP_NOWAIT);
cpumask_setall(irq_default_affinity);
}
#else
static void __init init_irq_default_affinity(void)
{
}
#endif
#ifdef CONFIG_SMP
static int alloc_masks(struct irq_desc *desc, gfp_t gfp, int node)
{
if (!zalloc_cpumask_var_node(&desc->irq_data.affinity, gfp, node))
return -ENOMEM;
#ifdef CONFIG_GENERIC_PENDING_IRQ
if (!zalloc_cpumask_var_node(&desc->pending_mask, gfp, node)) {
free_cpumask_var(desc->irq_data.affinity);
return -ENOMEM;
}
#endif
return 0;
}
static void desc_smp_init(struct irq_desc *desc, int node)
{
desc->irq_data.node = node;
cpumask_copy(desc->irq_data.affinity, irq_default_affinity);
#ifdef CONFIG_GENERIC_PENDING_IRQ
cpumask_clear(desc->pending_mask);
#endif
}
static inline int desc_node(struct irq_desc *desc)
{
return desc->irq_data.node;
}
#else
static inline int
alloc_masks(struct irq_desc *desc, gfp_t gfp, int node) { return 0; }
static inline void desc_smp_init(struct irq_desc *desc, int node) { }
static inline int desc_node(struct irq_desc *desc) { return 0; }
#endif
static void desc_set_defaults(unsigned int irq, struct irq_desc *desc, int node,
struct module *owner)
{
int cpu;
desc->irq_data.irq = irq;
desc->irq_data.chip = &no_irq_chip;
desc->irq_data.chip_data = NULL;
desc->irq_data.handler_data = NULL;
desc->irq_data.msi_desc = NULL;
irq_settings_clr_and_set(desc, ~0, _IRQ_DEFAULT_INIT_FLAGS);
irqd_set(&desc->irq_data, IRQD_IRQ_DISABLED);
desc->handle_irq = handle_bad_irq;
desc->depth = 1;
desc->irq_count = 0;
desc->irqs_unhandled = 0;
desc->name = NULL;
desc->owner = owner;
for_each_possible_cpu(cpu)
*per_cpu_ptr(desc->kstat_irqs, cpu) = 0;
desc_smp_init(desc, node);
}
int nr_irqs = NR_IRQS;
EXPORT_SYMBOL_GPL(nr_irqs);
static DEFINE_MUTEX(sparse_irq_lock);
static DECLARE_BITMAP(allocated_irqs, IRQ_BITMAP_BITS);
#ifdef CONFIG_SPARSE_IRQ
static RADIX_TREE(irq_desc_tree, GFP_KERNEL);
static void irq_insert_desc(unsigned int irq, struct irq_desc *desc)
{
radix_tree_insert(&irq_desc_tree, irq, desc);
}
struct irq_desc *irq_to_desc(unsigned int irq)
{
return radix_tree_lookup(&irq_desc_tree, irq);
}
EXPORT_SYMBOL(irq_to_desc);
static void delete_irq_desc(unsigned int irq)
{
radix_tree_delete(&irq_desc_tree, irq);
}
#ifdef CONFIG_SMP
static void free_masks(struct irq_desc *desc)
{
#ifdef CONFIG_GENERIC_PENDING_IRQ
free_cpumask_var(desc->pending_mask);
#endif
free_cpumask_var(desc->irq_data.affinity);
}
#else
static inline void free_masks(struct irq_desc *desc) { }
#endif
static struct irq_desc *alloc_desc(int irq, int node, struct module *owner)
{
struct irq_desc *desc;
gfp_t gfp = GFP_KERNEL;
desc = kzalloc_node(sizeof(*desc), gfp, node);
if (!desc)
return NULL;
/* allocate based on nr_cpu_ids */
desc->kstat_irqs = alloc_percpu(unsigned int);
if (!desc->kstat_irqs)
goto err_desc;
if (alloc_masks(desc, gfp, node))
goto err_kstat;
raw_spin_lock_init(&desc->lock);
lockdep_set_class(&desc->lock, &irq_desc_lock_class);
desc_set_defaults(irq, desc, node, owner);
return desc;
err_kstat:
free_percpu(desc->kstat_irqs);
err_desc:
kfree(desc);
return NULL;
}
static void free_desc(unsigned int irq)
{
struct irq_desc *desc = irq_to_desc(irq);
unregister_irq_proc(irq, desc);
mutex_lock(&sparse_irq_lock);
delete_irq_desc(irq);
mutex_unlock(&sparse_irq_lock);
free_masks(desc);
free_percpu(desc->kstat_irqs);
kfree(desc);
}
static int alloc_descs(unsigned int start, unsigned int cnt, int node,
struct module *owner)
{
struct irq_desc *desc;
int i;
for (i = 0; i < cnt; i++) {
desc = alloc_desc(start + i, node, owner);
if (!desc)
goto err;
mutex_lock(&sparse_irq_lock);
irq_insert_desc(start + i, desc);
mutex_unlock(&sparse_irq_lock);
}
return start;
err:
for (i--; i >= 0; i--)
free_desc(start + i);
mutex_lock(&sparse_irq_lock);
bitmap_clear(allocated_irqs, start, cnt);
mutex_unlock(&sparse_irq_lock);
return -ENOMEM;
}
static int irq_expand_nr_irqs(unsigned int nr)
{
if (nr > IRQ_BITMAP_BITS)
return -ENOMEM;
nr_irqs = nr;
return 0;
}
int __init early_irq_init(void)
{
int i, initcnt, node = first_online_node;
struct irq_desc *desc;
init_irq_default_affinity();
/* Let arch update nr_irqs and return the nr of preallocated irqs */
initcnt = arch_probe_nr_irqs();
printk(KERN_INFO "NR_IRQS:%d nr_irqs:%d %d\n", NR_IRQS, nr_irqs, initcnt);
if (WARN_ON(nr_irqs > IRQ_BITMAP_BITS))
nr_irqs = IRQ_BITMAP_BITS;
if (WARN_ON(initcnt > IRQ_BITMAP_BITS))
initcnt = IRQ_BITMAP_BITS;
if (initcnt > nr_irqs)
nr_irqs = initcnt;
for (i = 0; i < initcnt; i++) {
desc = alloc_desc(i, node, NULL);
set_bit(i, allocated_irqs);
irq_insert_desc(i, desc);
}
return arch_early_irq_init();
}
#else /* !CONFIG_SPARSE_IRQ */
struct irq_desc irq_desc[NR_IRQS] __cacheline_aligned_in_smp = {
[0 ... NR_IRQS-1] = {
.handle_irq = handle_bad_irq,
.depth = 1,
.lock = __RAW_SPIN_LOCK_UNLOCKED(irq_desc->lock),
}
};
int __init early_irq_init(void)
{
int count, i, node = first_online_node;
struct irq_desc *desc;
init_irq_default_affinity();
printk(KERN_INFO "NR_IRQS:%d\n", NR_IRQS);
desc = irq_desc;
count = ARRAY_SIZE(irq_desc);
for (i = 0; i < count; i++) {
desc[i].kstat_irqs = alloc_percpu(unsigned int);
alloc_masks(&desc[i], GFP_KERNEL, node);
raw_spin_lock_init(&desc[i].lock);
lockdep_set_class(&desc[i].lock, &irq_desc_lock_class);
desc_set_defaults(i, &desc[i], node, NULL);
}
return arch_early_irq_init();
}
struct irq_desc *irq_to_desc(unsigned int irq)
{
return (irq < NR_IRQS) ? irq_desc + irq : NULL;
}
EXPORT_SYMBOL(irq_to_desc);
static void free_desc(unsigned int irq)
{
dynamic_irq_cleanup(irq);
}
static inline int alloc_descs(unsigned int start, unsigned int cnt, int node,
struct module *owner)
{
u32 i;
for (i = 0; i < cnt; i++) {
struct irq_desc *desc = irq_to_desc(start + i);
desc->owner = owner;
}
return start;
}
static int irq_expand_nr_irqs(unsigned int nr)
{
return -ENOMEM;
}
#endif /* !CONFIG_SPARSE_IRQ */
/**
* generic_handle_irq - Invoke the handler for a particular irq
* @irq: The irq number to handle
*
*/
int generic_handle_irq(unsigned int irq)
{
struct irq_desc *desc = irq_to_desc(irq);
if (!desc)
return -EINVAL;
generic_handle_irq_desc(irq, desc);
return 0;
}
EXPORT_SYMBOL_GPL(generic_handle_irq);
/* Dynamic interrupt handling */
/**
* irq_free_descs - free irq descriptors
* @from: Start of descriptor range
* @cnt: Number of consecutive irqs to free
*/
void irq_free_descs(unsigned int from, unsigned int cnt)
{
int i;
if (from >= nr_irqs || (from + cnt) > nr_irqs)
return;
for (i = 0; i < cnt; i++)
free_desc(from + i);
mutex_lock(&sparse_irq_lock);
bitmap_clear(allocated_irqs, from, cnt);
mutex_unlock(&sparse_irq_lock);
}
EXPORT_SYMBOL_GPL(irq_free_descs);
/**
* irq_alloc_descs - allocate and initialize a range of irq descriptors
* @irq: Allocate for specific irq number if irq >= 0
* @from: Start the search from this irq number
* @cnt: Number of consecutive irqs to allocate.
* @node: Preferred node on which the irq descriptor should be allocated
* @owner: Owning module (can be NULL)
*
* Returns the first irq number or error code
*/
int __ref
__irq_alloc_descs(int irq, unsigned int from, unsigned int cnt, int node,
struct module *owner)
{
int start, ret;
if (!cnt)
return -EINVAL;
if (irq >= 0) {
if (from > irq)
return -EINVAL;
from = irq;
}
mutex_lock(&sparse_irq_lock);
start = bitmap_find_next_zero_area(allocated_irqs, IRQ_BITMAP_BITS,
from, cnt, 0);
ret = -EEXIST;
if (irq >=0 && start != irq)
goto err;
if (start + cnt > nr_irqs) {
ret = irq_expand_nr_irqs(start + cnt);
if (ret)
goto err;
}
bitmap_set(allocated_irqs, start, cnt);
mutex_unlock(&sparse_irq_lock);
return alloc_descs(start, cnt, node, owner);
err:
mutex_unlock(&sparse_irq_lock);
return ret;
}
EXPORT_SYMBOL_GPL(__irq_alloc_descs);
/**
* irq_reserve_irqs - mark irqs allocated
* @from: mark from irq number
* @cnt: number of irqs to mark
*
* Returns 0 on success or an appropriate error code
*/
int irq_reserve_irqs(unsigned int from, unsigned int cnt)
{
unsigned int start;
int ret = 0;
if (!cnt || (from + cnt) > nr_irqs)
return -EINVAL;
mutex_lock(&sparse_irq_lock);
start = bitmap_find_next_zero_area(allocated_irqs, nr_irqs, from, cnt, 0);
if (start == from)
bitmap_set(allocated_irqs, start, cnt);
else
ret = -EEXIST;
mutex_unlock(&sparse_irq_lock);
return ret;
}
/**
* irq_get_next_irq - get next allocated irq number
* @offset: where to start the search
*
* Returns next irq number after offset or nr_irqs if none is found.
*/
unsigned int irq_get_next_irq(unsigned int offset)
{
return find_next_bit(allocated_irqs, nr_irqs, offset);
}
struct irq_desc *
__irq_get_desc_lock(unsigned int irq, unsigned long *flags, bool bus,
unsigned int check)
{
struct irq_desc *desc = irq_to_desc(irq);
if (desc) {
if (check & _IRQ_DESC_CHECK) {
if ((check & _IRQ_DESC_PERCPU) &&
!irq_settings_is_per_cpu_devid(desc))
return NULL;
if (!(check & _IRQ_DESC_PERCPU) &&
irq_settings_is_per_cpu_devid(desc))
return NULL;
}
if (bus)
chip_bus_lock(desc);
raw_spin_lock_irqsave(&desc->lock, *flags);
}
return desc;
}
void __irq_put_desc_unlock(struct irq_desc *desc, unsigned long flags, bool bus)
{
raw_spin_unlock_irqrestore(&desc->lock, flags);
if (bus)
chip_bus_sync_unlock(desc);
}
int irq_set_percpu_devid(unsigned int irq)
{
struct irq_desc *desc = irq_to_desc(irq);
if (!desc)
return -EINVAL;
if (desc->percpu_enabled)
return -EINVAL;
desc->percpu_enabled = kzalloc(sizeof(*desc->percpu_enabled), GFP_KERNEL);
if (!desc->percpu_enabled)
return -ENOMEM;
irq_set_percpu_devid_flags(irq);
return 0;
}
/**
* dynamic_irq_cleanup - cleanup a dynamically allocated irq
* @irq: irq number to initialize
*/
void dynamic_irq_cleanup(unsigned int irq)
{
struct irq_desc *desc = irq_to_desc(irq);
unsigned long flags;
raw_spin_lock_irqsave(&desc->lock, flags);
desc_set_defaults(irq, desc, desc_node(desc), NULL);
raw_spin_unlock_irqrestore(&desc->lock, flags);
}
unsigned int kstat_irqs_cpu(unsigned int irq, int cpu)
{
struct irq_desc *desc = irq_to_desc(irq);
return desc && desc->kstat_irqs ?
*per_cpu_ptr(desc->kstat_irqs, cpu) : 0;
}
unsigned int kstat_irqs(unsigned int irq)
{
struct irq_desc *desc = irq_to_desc(irq);
int cpu;
int sum = 0;
if (!desc || !desc->kstat_irqs)
return 0;
for_each_possible_cpu(cpu)
sum += *per_cpu_ptr(desc->kstat_irqs, cpu);
return sum;
}
这里涉及一个结构类型 struct irq_desc,它是对系统中的单个中断的抽象,系统有多少个中断源就应该至少有多少个这样的对象。这些对象可能是放在一个数组中的,也可能是放在一个基数树中的,并且是内核在启动过程中构建好的。irq_to_desc 就是根据前面获得的 Linux 内部的 IRQ 号来从数组或基数树中得到这个对象,如果对象有效,那将会调用 generic_handle_irg_desc 来进一步处理中断。在 generic_handle_irq_desc 函数将会调用struct irq_desc 结够中的成员 handle_irq 函数指针所指的函数,而根据中断的触发类型是边沿触发还是电平触发,被调用的函数又分为 handle_edge_irq 和handle_level_irg。在这两个函数中都会测同一个IRQ号所对应的中断处理函数是否在执行,如果是则拒绝进一步执行,这也就防止了同一IRQ 号的中断处理函数的嵌套执行。这两个函数又都调用 handle_irq_event函数来处理中断,handle_irq_event函数又进一步调用了handle_irq_event_percpu函数,相关的关键代码如下。
/* kernel/irg/handle.c */
/*
* linux/kernel/irq/handle.c
*
* Copyright (C) 1992, 1998-2006 Linus Torvalds, Ingo Molnar
* Copyright (C) 2005-2006, Thomas Gleixner, Russell King
*
* This file contains the core interrupt handling code.
*
* Detailed information is available in Documentation/DocBook/genericirq
*
*/
#include <linux/irq.h>
#include <linux/random.h>
#include <linux/sched.h>
#include <linux/interrupt.h>
#include <linux/kernel_stat.h>
#include <trace/events/irq.h>
#include "internals.h"
/**
* handle_bad_irq - handle spurious and unhandled irqs
* @irq: the interrupt number
* @desc: description of the interrupt
*
* Handles spurious and unhandled IRQ's. It also prints a debugmessage.
*/
void handle_bad_irq(unsigned int irq, struct irq_desc *desc)
{
print_irq_desc(irq, desc);
kstat_incr_irqs_this_cpu(irq, desc);
ack_bad_irq(irq);
}
/*
* Special, empty irq handler:
*/
irqreturn_t no_action(int cpl, void *dev_id)
{
return IRQ_NONE;
}
static void warn_no_thread(unsigned int irq, struct irqaction *action)
{
if (test_and_set_bit(IRQTF_WARNED, &action->thread_flags))
return;
printk(KERN_WARNING "IRQ %d device %s returned IRQ_WAKE_THREAD "
"but no thread function available.", irq, action->name);
}
static void irq_wake_thread(struct irq_desc *desc, struct irqaction *action)
{
/*
* In case the thread crashed and was killed we just pretend that
* we handled the interrupt. The hardirq handler has disabled the
* device interrupt, so no irq storm is lurking.
*/
if (action->thread->flags & PF_EXITING)
return;
/*
* Wake up the handler thread for this action. If the
* RUNTHREAD bit is already set, nothing to do.
*/
if (test_and_set_bit(IRQTF_RUNTHREAD, &action->thread_flags))
return;
/*
* It's safe to OR the mask lockless here. We have only two
* places which write to threads_oneshot: This code and the
* irq thread.
*
* This code is the hard irq context and can never run on two
* cpus in parallel. If it ever does we have more serious
* problems than this bitmask.
*
* The irq threads of this irq which clear their "running" bit
* in threads_oneshot are serialized via desc->lock against
* each other and they are serialized against this code by
* IRQS_INPROGRESS.
*
* Hard irq handler:
*
* spin_lock(desc->lock);
* desc->state |= IRQS_INPROGRESS;
* spin_unlock(desc->lock);
* set_bit(IRQTF_RUNTHREAD, &action->thread_flags);
* desc->threads_oneshot |= mask;
* spin_lock(desc->lock);
* desc->state &= ~IRQS_INPROGRESS;
* spin_unlock(desc->lock);
*
* irq thread:
*
* again:
* spin_lock(desc->lock);
* if (desc->state & IRQS_INPROGRESS) {
* spin_unlock(desc->lock);
* while(desc->state & IRQS_INPROGRESS)
* cpu_relax();
* goto again;
* }
* if (!test_bit(IRQTF_RUNTHREAD, &action->thread_flags))
* desc->threads_oneshot &= ~mask;
* spin_unlock(desc->lock);
*
* So either the thread waits for us to clear IRQS_INPROGRESS
* or we are waiting in the flow handler for desc->lock to be
* released before we reach this point. The thread also checks
* IRQTF_RUNTHREAD under desc->lock. If set it leaves
* threads_oneshot untouched and runs the thread another time.
*/
desc->threads_oneshot |= action->thread_mask;
/*
* We increment the threads_active counter in case we wake up
* the irq thread. The irq thread decrements the counter when
* it returns from the handler or in the exit path and wakes
* up waiters which are stuck in synchronize_irq() when the
* active count becomes zero. synchronize_irq() is serialized
* against this code (hard irq handler) via IRQS_INPROGRESS
* like the finalize_oneshot() code. See comment above.
*/
atomic_inc(&desc->threads_active);
wake_up_process(action->thread);
}
irqreturn_t
handle_irq_event_percpu(struct irq_desc *desc, struct irqaction *action)
{
irqreturn_t retval = IRQ_NONE;
unsigned int flags = 0, irq = desc->irq_data.irq;
do {
irqreturn_t res;
trace_irq_handler_entry(irq, action);
res = action->handler(irq, action->dev_id);
trace_irq_handler_exit(irq, action, res);
if (WARN_ONCE(!irqs_disabled(),"irq %u handler %pF enabled interrupts\n",
irq, action->handler))
local_irq_disable();
switch (res) {
case IRQ_WAKE_THREAD:
/*
* Catch drivers which return WAKE_THREAD but
* did not set up a thread function
*/
if (unlikely(!action->thread_fn)) {
warn_no_thread(irq, action);
break;
}
irq_wake_thread(desc, action);
/* Fall through to add to randomness */
case IRQ_HANDLED:
flags |= action->flags;
break;
default:
break;
}
retval |= res;
action = action->next;
} while (action);
add_interrupt_randomness(irq, flags);
if (!noirqdebug)
note_interrupt(irq, desc, retval);
return retval;
}
irqreturn_t handle_irq_event(struct irq_desc *desc)
{
struct irqaction *action = desc->action;
irqreturn_t ret;
desc->istate &= ~IRQS_PENDING;
irqd_set(&desc->irq_data, IRQD_IRQ_INPROGRESS);
raw_spin_unlock(&desc->lock);
ret = handle_irq_event_percpu(desc, action);
raw_spin_lock(&desc->lock);
irqd_clear(&desc->irq_data, IRQD_IRQ_INPROGRESS);
return ret;
}
代码第184行从前面得到的 struct irq_desc 结构对象中得到action 成员,该成员是一个指向struct irgaction 结构的指针,struct irqaction 结构类型的定义如下。
/* interrupt.h */
#ifndef _LINUX_INTERRUPT_H
#define _LINUX_INTERRUPT_H
#include <linux/kernel.h>
#include <linux/linkage.h>
#include <linux/bitops.h>
#include <linux/preempt.h>
#include <linux/cpumask.h>
#include <linux/irqreturn.h>
#include <linux/irqnr.h>
#include <linux/hardirq.h>
#include <linux/irqflags.h>
#include <linux/hrtimer.h>
#include <linux/kref.h>
#include <linux/workqueue.h>
#include <linux/atomic.h>
#include <asm/ptrace.h>
#include <asm/irq.h>
/*
* These correspond to the IORESOURCE_IRQ_* defines in
* linux/ioport.h to select the interrupt line behaviour. When
* requesting an interrupt without specifying a IRQF_TRIGGER, the
* setting should be assumed to be "as already configured", which
* may be as per machine or firmware initialisation.
*/
#define IRQF_TRIGGER_NONE 0x00000000
#define IRQF_TRIGGER_RISING 0x00000001
#define IRQF_TRIGGER_FALLING 0x00000002
#define IRQF_TRIGGER_HIGH 0x00000004
#define IRQF_TRIGGER_LOW 0x00000008
#define IRQF_TRIGGER_MASK (IRQF_TRIGGER_HIGH | IRQF_TRIGGER_LOW | \
IRQF_TRIGGER_RISING | IRQF_TRIGGER_FALLING)
#define IRQF_TRIGGER_PROBE 0x00000010
/*
* These flags used only by the kernel as part of the
* irq handling routines.
*
* IRQF_DISABLED - keep irqs disabled when calling the action handler.
* DEPRECATED. This flag is a NOOP and scheduled to be removed
* IRQF_SHARED - allow sharing the irq among several devices
* IRQF_PROBE_SHARED - set by callers when they expect sharing mismatches to occur
* IRQF_TIMER - Flag to mark this interrupt as timer interrupt
* IRQF_PERCPU - Interrupt is per cpu
* IRQF_NOBALANCING - Flag to exclude this interrupt from irq balancing
* IRQF_IRQPOLL - Interrupt is used for polling (only the interrupt that is
* registered first in an shared interrupt is considered for
* performance reasons)
* IRQF_ONESHOT - Interrupt is not reenabled after the hardirq handler finished.
* Used by threaded interrupts which need to keep the
* irq line disabled until the threaded handler has been run.
* IRQF_NO_SUSPEND - Do not disable this IRQ during suspend
* IRQF_FORCE_RESUME - Force enable it on resume even if IRQF_NO_SUSPEND is set
* IRQF_NO_THREAD - Interrupt cannot be threaded
* IRQF_EARLY_RESUME - Resume IRQ early during syscore instead of at device
* resume time.
*/
#define IRQF_DISABLED 0x00000020
#define IRQF_SHARED 0x00000080
#define IRQF_PROBE_SHARED 0x00000100
#define __IRQF_TIMER 0x00000200
#define IRQF_PERCPU 0x00000400
#define IRQF_NOBALANCING 0x00000800
#define IRQF_IRQPOLL 0x00001000
#define IRQF_ONESHOT 0x00002000
#define IRQF_NO_SUSPEND 0x00004000
#define IRQF_FORCE_RESUME 0x00008000
#define IRQF_NO_THREAD 0x00010000
#define IRQF_EARLY_RESUME 0x00020000
#define IRQF_TIMER (__IRQF_TIMER | IRQF_NO_SUSPEND | IRQF_NO_THREAD)
/*
* These values can be returned by request_any_context_irq() and
* describe the context the interrupt will be run in.
*
* IRQC_IS_HARDIRQ - interrupt runs in hardirq context
* IRQC_IS_NESTED - interrupt runs in a nested threaded context
*/
enum {
IRQC_IS_HARDIRQ = 0,
IRQC_IS_NESTED,
};
typedef irqreturn_t (*irq_handler_t)(int, void *);
/**
* struct irqaction - per interrupt action descriptor
* @handler: interrupt handler function
* @name: name of the device
* @dev_id: cookie to identify the device
* @percpu_dev_id: cookie to identify the device
* @next: pointer to the next irqaction for shared interrupts
* @irq: interrupt number
* @flags: flags (see IRQF_* above)
* @thread_fn: interrupt handler function for threaded interrupts
* @thread: thread pointer for threaded interrupts
* @thread_flags: flags related to @thread
* @thread_mask: bitmask for keeping track of @thread activity
* @dir: pointer to the proc/irq/NN/name entry
*/
struct irqaction {
irq_handler_t handler;
void *dev_id;
void __percpu *percpu_dev_id;
struct irqaction *next;
irq_handler_t thread_fn;
struct task_struct *thread;
unsigned int irq;
unsigned int flags;
unsigned long thread_flags;
unsigned long thread_mask;
const char *name;
struct proc_dir_entry *dir;
} ____cacheline_internodealigned_in_smp;
extern irqreturn_t no_action(int cpl, void *dev_id);
extern int __must_check
request_threaded_irq(unsigned int irq, irq_handler_t handler,
irq_handler_t thread_fn,
unsigned long flags, const char *name, void *dev);
static inline int __must_check
request_irq(unsigned int irq, irq_handler_t handler, unsigned long flags,
const char *name, void *dev)
{
return request_threaded_irq(irq, handler, NULL, flags, name, dev);
}
extern int __must_check
request_any_context_irq(unsigned int irq, irq_handler_t handler,
unsigned long flags, const char *name, void *dev_id);
extern int __must_check
request_percpu_irq(unsigned int irq, irq_handler_t handler,
const char *devname, void __percpu *percpu_dev_id);
extern void free_irq(unsigned int, void *);
extern void free_percpu_irq(unsigned int, void __percpu *);
struct device;
extern int __must_check
devm_request_threaded_irq(struct device *dev, unsigned int irq,
irq_handler_t handler, irq_handler_t thread_fn,
unsigned long irqflags, const char *devname,
void *dev_id);
static inline int __must_check
devm_request_irq(struct device *dev, unsigned int irq, irq_handler_t handler,
unsigned long irqflags, const char *devname, void *dev_id)
{
return devm_request_threaded_irq(dev, irq, handler, NULL, irqflags,
devname, dev_id);
}
extern int __must_check
devm_request_any_context_irq(struct device *dev, unsigned int irq,
irq_handler_t handler, unsigned long irqflags,
const char *devname, void *dev_id);
extern void devm_free_irq(struct device *dev, unsigned int irq, void *dev_id);
/*
* On lockdep we dont want to enable hardirqs in hardirq
* context. Use local_irq_enable_in_hardirq() to annotate
* kernel code that has to do this nevertheless (pretty much
* the only valid case is for old/broken hardware that is
* insanely slow).
*
* NOTE: in theory this might break fragile code that relies
* on hardirq delivery - in practice we dont seem to have such
* places left. So the only effect should be slightly increased
* irqs-off latencies.
*/
#ifdef CONFIG_LOCKDEP
# define local_irq_enable_in_hardirq() do { } while (0)
#else
# define local_irq_enable_in_hardirq() local_irq_enable()
#endif
extern void disable_irq_nosync(unsigned int irq);
extern void disable_irq(unsigned int irq);
extern void disable_percpu_irq(unsigned int irq);
extern void enable_irq(unsigned int irq);
extern void enable_percpu_irq(unsigned int irq, unsigned int type);
/* The following three functions are for the core kernel use only. */
extern void suspend_device_irqs(void);
extern void resume_device_irqs(void);
#ifdef CONFIG_PM_SLEEP
extern int check_wakeup_irqs(void);
#else
static inline int check_wakeup_irqs(void) { return 0; }
#endif
#if defined(CONFIG_SMP)
extern cpumask_var_t irq_default_affinity;
extern int irq_set_affinity(unsigned int irq, const struct cpumask *cpumask);
extern int irq_can_set_affinity(unsigned int irq);
extern int irq_select_affinity(unsigned int irq);
extern int irq_set_affinity_hint(unsigned int irq, const struct cpumask *m);
/**
* struct irq_affinity_notify - context for notification of IRQ affinity changes
* @irq: Interrupt to which notification applies
* @kref: Reference count, for internal use
* @work: Work item, for internal use
* @notify: Function to be called on change. This will be
* called in process context.
* @release: Function to be called on release. This will be
* called in process context. Once registered, the
* structure must only be freed when this function is
* called or later.
*/
struct irq_affinity_notify {
unsigned int irq;
struct kref kref;
struct work_struct work;
void (*notify)(struct irq_affinity_notify *, const cpumask_t *mask);
void (*release)(struct kref *ref);
};
extern int
irq_set_affinity_notifier(unsigned int irq, struct irq_affinity_notify *notify);
#else /* CONFIG_SMP */
static inline int irq_set_affinity(unsigned int irq, const struct cpumask *m)
{
return -EINVAL;
}
static inline int irq_can_set_affinity(unsigned int irq)
{
return 0;
}
static inline int irq_select_affinity(unsigned int irq) { return 0; }
static inline int irq_set_affinity_hint(unsigned int irq,
const struct cpumask *m)
{
return -EINVAL;
}
#endif /* CONFIG_SMP */
/*
* Special lockdep variants of irq disabling/enabling.
* These should be used for locking constructs that
* know that a particular irq context which is disabled,
* and which is the only irq-context user of a lock,
* that it's safe to take the lock in the irq-disabled
* section without disabling hardirqs.
*
* On !CONFIG_LOCKDEP they are equivalent to the normal
* irq disable/enable methods.
*/
static inline void disable_irq_nosync_lockdep(unsigned int irq)
{
disable_irq_nosync(irq);
#ifdef CONFIG_LOCKDEP
local_irq_disable();
#endif
}
static inline void disable_irq_nosync_lockdep_irqsave(unsigned int irq, unsigned long *flags)
{
disable_irq_nosync(irq);
#ifdef CONFIG_LOCKDEP
local_irq_save(*flags);
#endif
}
static inline void disable_irq_lockdep(unsigned int irq)
{
disable_irq(irq);
#ifdef CONFIG_LOCKDEP
local_irq_disable();
#endif
}
static inline void enable_irq_lockdep(unsigned int irq)
{
#ifdef CONFIG_LOCKDEP
local_irq_enable();
#endif
enable_irq(irq);
}
static inline void enable_irq_lockdep_irqrestore(unsigned int irq, unsigned long *flags)
{
#ifdef CONFIG_LOCKDEP
local_irq_restore(*flags);
#endif
enable_irq(irq);
}
/* IRQ wakeup (PM) control: */
extern int irq_set_irq_wake(unsigned int irq, unsigned int on);
static inline int enable_irq_wake(unsigned int irq)
{
return irq_set_irq_wake(irq, 1);
}
static inline int disable_irq_wake(unsigned int irq)
{
return irq_set_irq_wake(irq, 0);
}
#ifdef CONFIG_IRQ_FORCED_THREADING
extern bool force_irqthreads;
#else
#define force_irqthreads (0)
#endif
#ifndef __ARCH_SET_SOFTIRQ_PENDING
#define set_softirq_pending(x) (local_softirq_pending() = (x))
#define or_softirq_pending(x) (local_softirq_pending() |= (x))
#endif
/* Some architectures might implement lazy enabling/disabling of
* interrupts. In some cases, such as stop_machine, we might want
* to ensure that after a local_irq_disable(), interrupts have
* really been disabled in hardware. Such architectures need to
* implement the following hook.
*/
#ifndef hard_irq_disable
#define hard_irq_disable() do { } while(0)
#endif
/* PLEASE, avoid to allocate new softirqs, if you need not _really_ high
frequency threaded job scheduling. For almost all the purposes
tasklets are more than enough. F.e. all serial device BHs et
al. should be converted to tasklets, not to softirqs.
*/
enum
{
HI_SOFTIRQ=0,
TIMER_SOFTIRQ,
NET_TX_SOFTIRQ,
NET_RX_SOFTIRQ,
BLOCK_SOFTIRQ,
BLOCK_IOPOLL_SOFTIRQ,
TASKLET_SOFTIRQ,
SCHED_SOFTIRQ,
HRTIMER_SOFTIRQ,
RCU_SOFTIRQ, /* Preferable RCU should always be the last softirq */
NR_SOFTIRQS
};
#define SOFTIRQ_STOP_IDLE_MASK (~(1 << RCU_SOFTIRQ))
/* map softirq index to softirq name. update 'softirq_to_name' in
* kernel/softirq.c when adding a new softirq.
*/
extern const char * const softirq_to_name[NR_SOFTIRQS];
/* softirq mask and active fields moved to irq_cpustat_t in
* asm/hardirq.h to get better cache usage. KAO
*/
struct softirq_action
{
void (*action)(struct softirq_action *);
};
asmlinkage void do_softirq(void);
asmlinkage void __do_softirq(void);
#ifdef __ARCH_HAS_DO_SOFTIRQ
void do_softirq_own_stack(void);
#else
static inline void do_softirq_own_stack(void)
{
__do_softirq();
}
#endif
extern void open_softirq(int nr, void (*action)(struct softirq_action *));
extern void softirq_init(void);
extern void __raise_softirq_irqoff(unsigned int nr);
extern void raise_softirq_irqoff(unsigned int nr);
extern void raise_softirq(unsigned int nr);
DECLARE_PER_CPU(struct task_struct *, ksoftirqd);
static inline struct task_struct *this_cpu_ksoftirqd(void)
{
return this_cpu_read(ksoftirqd);
}
/* Tasklets --- multithreaded analogue of BHs.
Main feature differing them of generic softirqs: tasklet
is running only on one CPU simultaneously.
Main feature differing them of BHs: different tasklets
may be run simultaneously on different CPUs.
Properties:
* If tasklet_schedule() is called, then tasklet is guaranteed
to be executed on some cpu at least once after this.
* If the tasklet is already scheduled, but its execution is still not
started, it will be executed only once.
* If this tasklet is already running on another CPU (or schedule is called
from tasklet itself), it is rescheduled for later.
* Tasklet is strictly serialized wrt itself, but not
wrt another tasklets. If client needs some intertask synchronization,
he makes it with spinlocks.
*/
struct tasklet_struct
{
struct tasklet_struct *next;
unsigned long state;
atomic_t count;
void (*func)(unsigned long);
unsigned long data;
};
#define DECLARE_TASKLET(name, func, data) \
struct tasklet_struct name = { NULL, 0, ATOMIC_INIT(0), func, data }
#define DECLARE_TASKLET_DISABLED(name, func, data) \
struct tasklet_struct name = { NULL, 0, ATOMIC_INIT(1), func, data }
enum
{
TASKLET_STATE_SCHED, /* Tasklet is scheduled for execution */
TASKLET_STATE_RUN /* Tasklet is running (SMP only) */
};
#ifdef CONFIG_SMP
static inline int tasklet_trylock(struct tasklet_struct *t)
{
return !test_and_set_bit(TASKLET_STATE_RUN, &(t)->state);
}
static inline void tasklet_unlock(struct tasklet_struct *t)
{
smp_mb__before_clear_bit();
clear_bit(TASKLET_STATE_RUN, &(t)->state);
}
static inline void tasklet_unlock_wait(struct tasklet_struct *t)
{
while (test_bit(TASKLET_STATE_RUN, &(t)->state)) { barrier(); }
}
#else
#define tasklet_trylock(t) 1
#define tasklet_unlock_wait(t) do { } while (0)
#define tasklet_unlock(t) do { } while (0)
#endif
extern void __tasklet_schedule(struct tasklet_struct *t);
static inline void tasklet_schedule(struct tasklet_struct *t)
{
if (!test_and_set_bit(TASKLET_STATE_SCHED, &t->state))
__tasklet_schedule(t);
}
extern void __tasklet_hi_schedule(struct tasklet_struct *t);
static inline void tasklet_hi_schedule(struct tasklet_struct *t)
{
if (!test_and_set_bit(TASKLET_STATE_SCHED, &t->state))
__tasklet_hi_schedule(t);
}
extern void __tasklet_hi_schedule_first(struct tasklet_struct *t);
/*
* This version avoids touching any other tasklets. Needed for kmemcheck
* in order not to take any page faults while enqueueing this tasklet;
* consider VERY carefully whether you really need this or
* tasklet_hi_schedule()...
*/
static inline void tasklet_hi_schedule_first(struct tasklet_struct *t)
{
if (!test_and_set_bit(TASKLET_STATE_SCHED, &t->state))
__tasklet_hi_schedule_first(t);
}
static inline void tasklet_disable_nosync(struct tasklet_struct *t)
{
atomic_inc(&t->count);
smp_mb__after_atomic_inc();
}
static inline void tasklet_disable(struct tasklet_struct *t)
{
tasklet_disable_nosync(t);
tasklet_unlock_wait(t);
smp_mb();
}
static inline void tasklet_enable(struct tasklet_struct *t)
{
smp_mb__before_atomic_dec();
atomic_dec(&t->count);
}
static inline void tasklet_hi_enable(struct tasklet_struct *t)
{
smp_mb__before_atomic_dec();
atomic_dec(&t->count);
}
extern void tasklet_kill(struct tasklet_struct *t);
extern void tasklet_kill_immediate(struct tasklet_struct *t, unsigned int cpu);
extern void tasklet_init(struct tasklet_struct *t,
void (*func)(unsigned long), unsigned long data);
struct tasklet_hrtimer {
struct hrtimer timer;
struct tasklet_struct tasklet;
enum hrtimer_restart (*function)(struct hrtimer *);
};
extern void
tasklet_hrtimer_init(struct tasklet_hrtimer *ttimer,
enum hrtimer_restart (*function)(struct hrtimer *),
clockid_t which_clock, enum hrtimer_mode mode);
static inline
int tasklet_hrtimer_start(struct tasklet_hrtimer *ttimer, ktime_t time,
const enum hrtimer_mode mode)
{
return hrtimer_start(&ttimer->timer, time, mode);
}
static inline
void tasklet_hrtimer_cancel(struct tasklet_hrtimer *ttimer)
{
hrtimer_cancel(&ttimer->timer);
tasklet_kill(&ttimer->tasklet);
}
/*
* Autoprobing for irqs:
*
* probe_irq_on() and probe_irq_off() provide robust primitives
* for accurate IRQ probing during kernel initialization. They are
* reasonably simple to use, are not "fooled" by spurious interrupts,
* and, unlike other attempts at IRQ probing, they do not get hung on
* stuck interrupts (such as unused PS2 mouse interfaces on ASUS boards).
*
* For reasonably foolproof probing, use them as follows:
*
* 1. clear and/or mask the device's internal interrupt.
* 2. sti();
* 3. irqs = probe_irq_on(); // "take over" all unassigned idle IRQs
* 4. enable the device and cause it to trigger an interrupt.
* 5. wait for the device to interrupt, using non-intrusive polling or a delay.
* 6. irq = probe_irq_off(irqs); // get IRQ number, 0=none, negative=multiple
* 7. service the device to clear its pending interrupt.
* 8. loop again if paranoia is required.
*
* probe_irq_on() returns a mask of allocated irq's.
*
* probe_irq_off() takes the mask as a parameter,
* and returns the irq number which occurred,
* or zero if none occurred, or a negative irq number
* if more than one irq occurred.
*/
#if !defined(CONFIG_GENERIC_IRQ_PROBE)
static inline unsigned long probe_irq_on(void)
{
return 0;
}
static inline int probe_irq_off(unsigned long val)
{
return 0;
}
static inline unsigned int probe_irq_mask(unsigned long val)
{
return 0;
}
#else
extern unsigned long probe_irq_on(void); /* returns 0 on failure */
extern int probe_irq_off(unsigned long); /* returns 0 or negative on failure */
extern unsigned int probe_irq_mask(unsigned long); /* returns mask of ISA interrupts */
#endif
#ifdef CONFIG_PROC_FS
/* Initialize /proc/irq/ */
extern void init_irq_proc(void);
#else
static inline void init_irq_proc(void)
{
}
#endif
struct seq_file;
int show_interrupts(struct seq_file *p, void *v);
int arch_show_interrupts(struct seq_file *p, int prec);
extern int early_irq_init(void);
extern int arch_probe_nr_irqs(void);
extern int arch_early_irq_init(void);
#endif
其中关键的成员及其含义如下(具体的使用会在后面的实例中做进一步介绍)。
handler:指向驱动开发者编写的中断处理函数的指针。
dev_id:区别共享中断中的不同设备的ID。
next:将共享同一IRQ号的struct irqaction 对象链接在一起的指针
irq:IRQ号。
flags:以IRQF_开头的一组标志。
代码第 191 行调用了 handle_irq_event_percpu,并传入了刚才得到的 action,在handle_irq_event_percpu函数中的do...while 循环中遍历了链表中的每一个action,并调用了action 中 handler 成员所指向的中断处理函数。也就是说,经过这个漫长的过程后,驱动开发者编写的中断处理函数终于得到了调用。
上面提到了“共享中断”,那么什么是“共享中断”呢? 接下来我们来讨论一下。
由于中断控制器的管脚有限,所以在某些体系结构上有两个或两个以上的设备被接到了同一根中断线上,这样这两个设备中的任何一个设备产生了中断,都会触发中断,并且引发上述代码的执行过程,这就是共享中断。Linux 内核不能判断新产生的这个中断究竟属于哪个设备,于是将共用一根中断线的中断处理函数通过不同的struct irqaction结构包装起来,然后用链表链接起来。内核得到IRQ号后,就遍历该链表上的每一个 struct irqaction对象,然后调用其 handler 成员所指向的中断处理函数。而在中断处理函数中,驱动开发者应该判断该中断是否是自己所管理的设备产生的,如果是则进行相应的中断处理,如果不是则直接返回。自然地,dev_id 就成为了从链表中删除对应struct irqaction对象的一个重要信息(删除函数的参数只有IRQ号没有struct irqaction 结构对象的地址这个我们将在后面的实例中看到)。
通过上面的分析,我们不难得出如图 5.1 所示的示意图
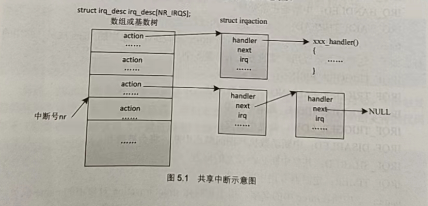





![C++ [STL之string的使用]](https://img-blog.csdnimg.cn/84e4fd60d85a42619862f999bd6ec9ea.png#pic_center)