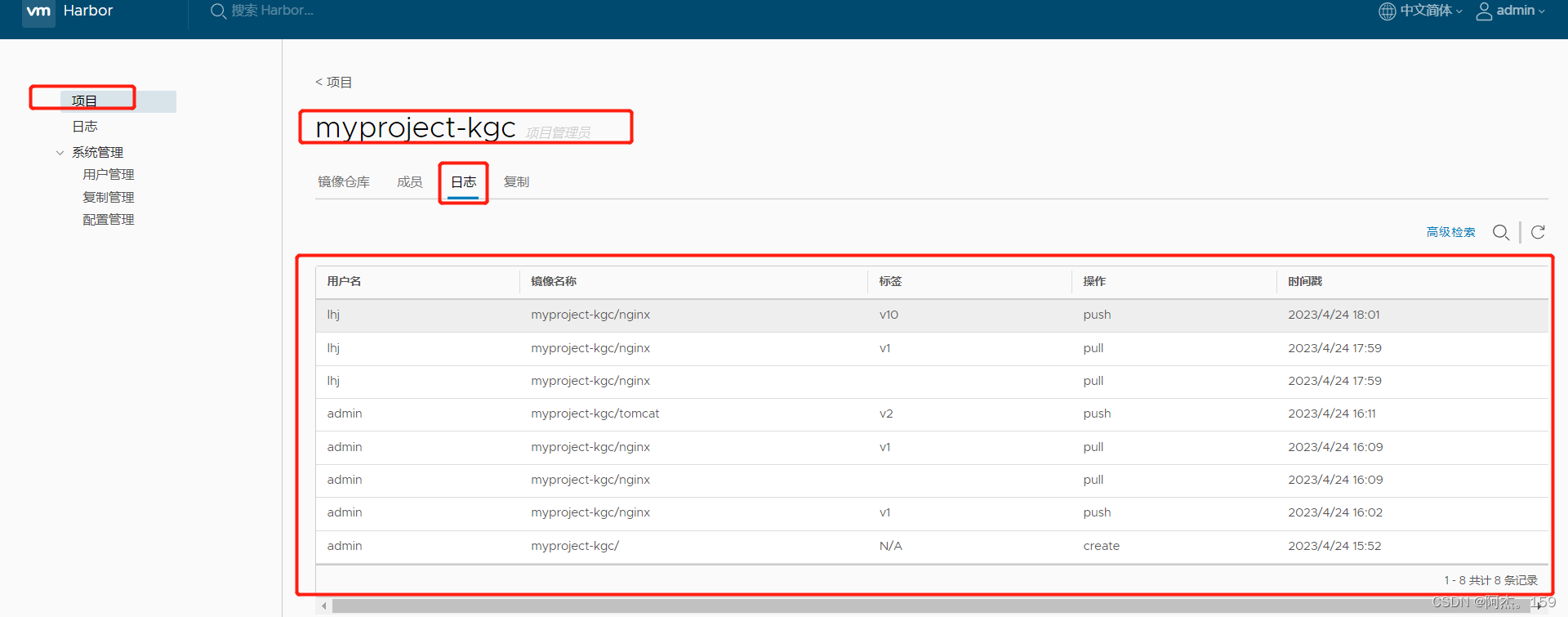
RNN Encoder–Decoder

每一个时刻都有一个隐藏状态向量 S_t,当这个向量传递到最后的一个 token 时,即 S_n (n为输入序列的最大长度),它就是语义编码向量 C
C 参与了Decoder过程中每一时刻隐藏状态和输出的计算.
![]()
最大的局限性就在于编码和解码之间的唯一联系就是一个固定长度的语义向量C。也就是说,编码器要将整个序列的信息压缩进一个固定长度的向量中去。
1.语义向量无法完全表示整个序列的信息,
2.先输入的内容携带的信息会被后输入的信息稀释掉,或者说,被覆盖了
论文:K. Cho et al., “Learning phrase representations using RNN encoder– decoder for statistical machine translation,” in Proc. Conf. Empirical Methods Natural Lang. Process., 2014, pp. 1724–1734.
Sequence Prediction Using Spectral RNNs
1. STFT对数据加窗并将每个窗口移动到频域。随后的递归网络处理多个样本窗口而不是单个数据点,因此以较低的时钟速率运行,这减少了每个时间步长的RNN单元评估总数:
在频域中通常可以更紧凑且信息量更大。
2. 在频域中工作允许通过低通滤波来减小参数:
傅立叶基将最重要的信息聚集在低频系数中。它方便地允许我们集成低通滤波器,不仅可以减少表示大小,还可以消除可能破坏RNN学习的噪声影响。
3. 通过正向和反向变换传播梯度:
保留了相位信息。
论文:M.Wolter, J.Gall, andA.Yao, “Sequenceprediction using spectral RNNs,” in Proc. Int. Conf. Artif. Neural Netw., 2020, pp. 825–837.
这篇论文用能够实现无限多个变换的广义变换来提高模型性能
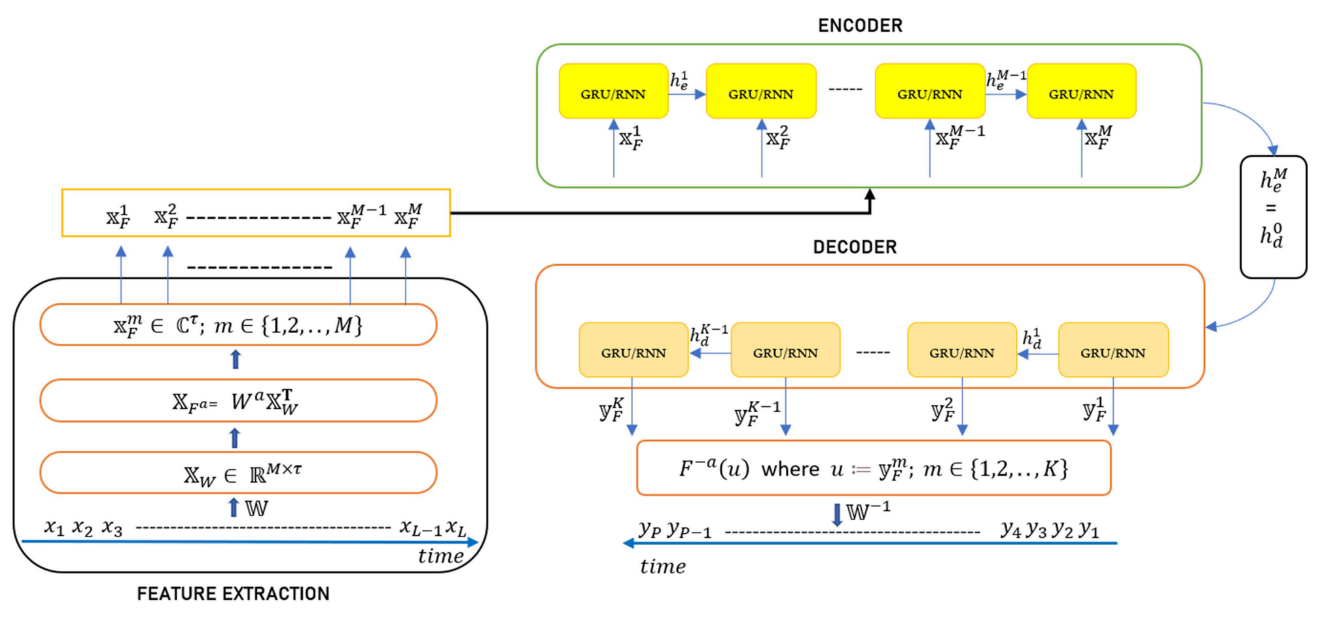
FRFT的用法与前面的STFT基本一样。
第一阶段(特征提取)包括从顺序时间序列数据生成特征向量的一系列级联操作

第二阶段(Encoder-Decoder)包括具有门控递归单元(GRU)或基本RNN单元的多对多编码器-解码器架构
在沿着编码器的每个单元中,使用当前输入和先前状态产生新的隐藏状态,并将其传递到下一个单元。
最后一个单元的状态信息被传送到解码器以初始化解码器的隐藏状态。沿着解码器,每个单元的输出向量被计算为隐藏状态向量 h_d 与输出权重 W_hy 的乘积,并通过 tanh 激活函数。
Decoder 的长度可以与 Encoder 的长度不同
由第一阶段产生的特征被馈送到第二阶段的编码器块中,而解码器部分仅处理原始时域数据。

RNN Cell

LSTM Cell
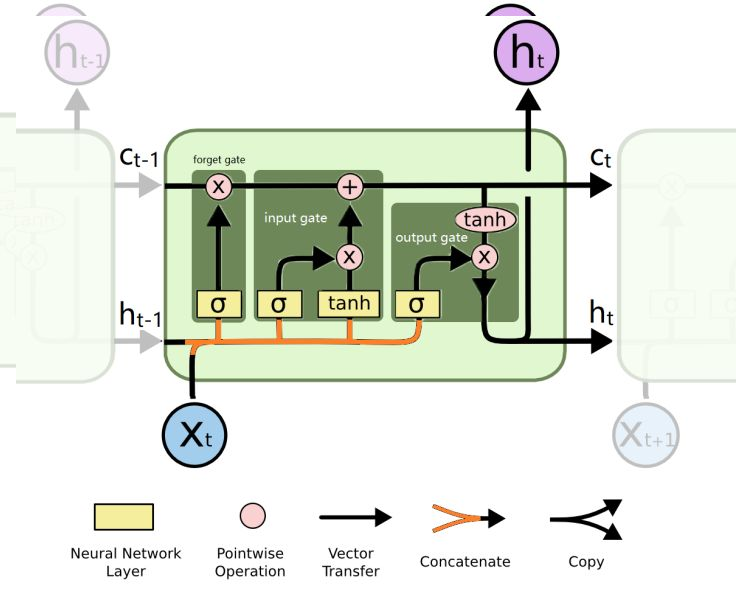
LSTM 减小了RNN 的梯度消失和梯度爆炸问题。
GRU Cell
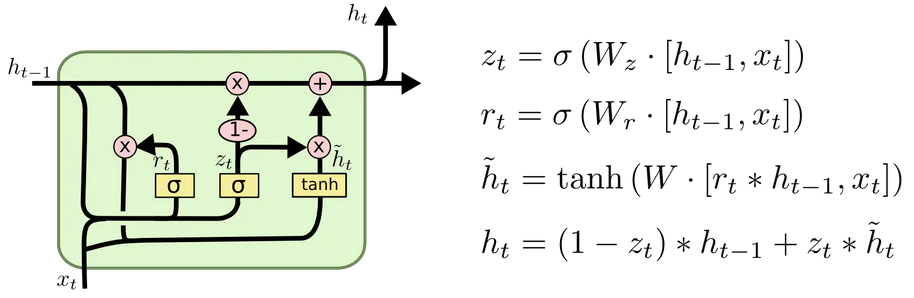
GRU是LSTM的一个变体,保持了LSTM效果的同时又使得结构更加简单。将遗忘门和输入门合并成为了一个单一的更新门。并且GRU没有细胞状态,大大简化了结构,相比于LSTM,GRU有更少的参数,训练的时候过拟合问题没有那么严重。
Instead of manually searching for the optimal value, α is randomly initialized from the uniform distribution U ∼ (0.5, 1.5) and learned in the network iteratively to minimize training loss.
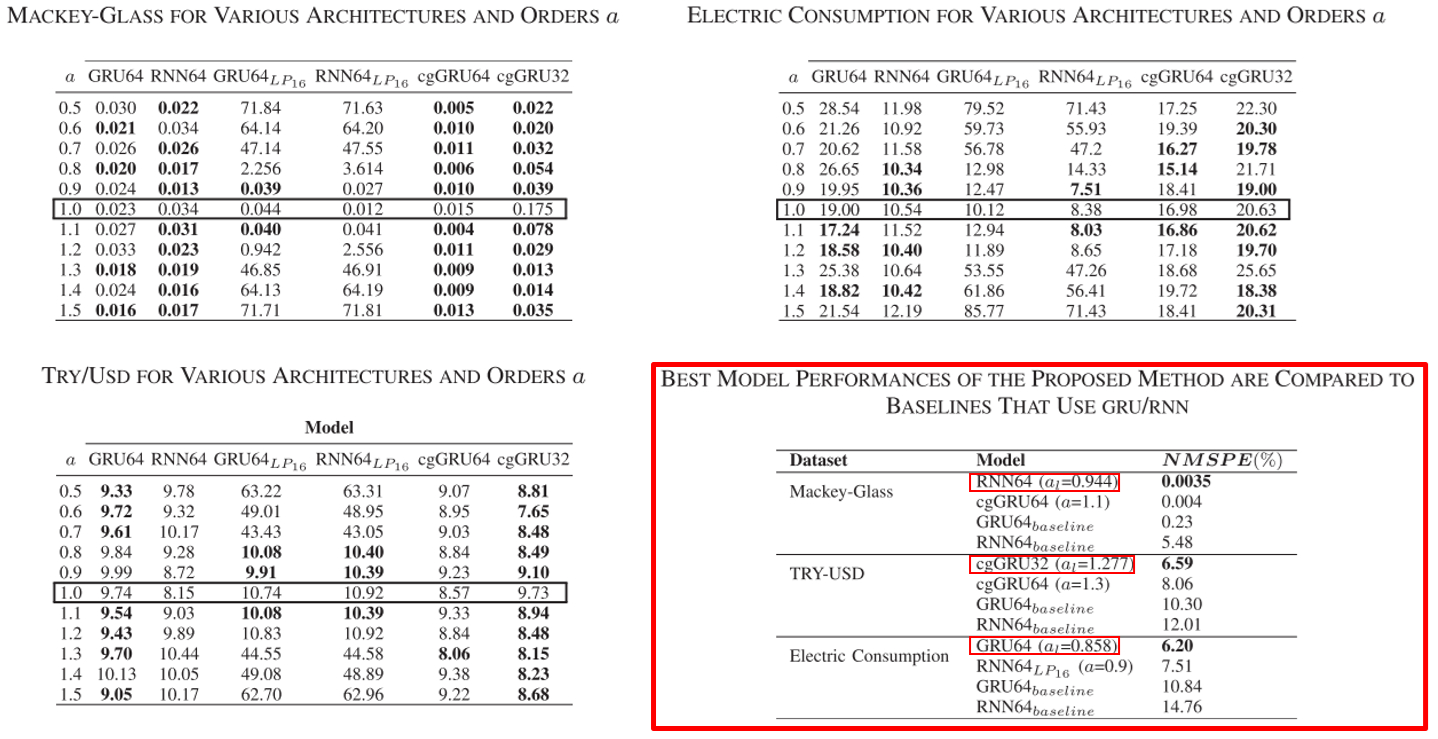
训练得到的阶次 α_l 效果比起手动选择的 α 性能更好。