目录
对话到行动:通过行动级生成构建面向任务的对话系统
1介绍
2框架描述
2.1概述
2.2第一步:对话动作构造
2.3步骤2:响应标准化响应标准化
2.4步骤3:动作序列预测
2.5步骤4:生成响应
3实验
3.1实验设置
3.2主要结果
3.3深度分析
4结论
5主持人简介
6公司简介
对话到行动:通过行动级生成构建面向任务的对话系统
Dialog-to-Actions: Building Task-Oriented Dialogue System via Action-Level Generation
摘要:基于端到端生成的方法已经被研究并应用于面向任务的对话系统中。然而,在工业场景中,现有的方法面临着可靠性(如域响应不一致、重复问题等)和效率(如计算时间长等)的瓶颈。在本文中,我们提出了一个以任务为导向的对话系统。具体来说,我们首先从大规模对话中构建对话动作,并将每个自然语言(NL)响应表示为对话动作的序列。此外,我们训练了一个sequence - tosequence模型,该模型将对话历史作为输入并输出一系列对话动作。生成的对话动作被转换成口头反应。实验结果表明,该方法具有较好的性能,且具有可靠和高效的优点。
关键词:任务导向对话系统,行动级生成,对话-行动
1介绍
最近,直接输出适当的自然语言响应或API调用的端到端生成方法在面向任务的聊天机器人中得到了深入研究[2,5,9,16,22],并被证明对现实世界的业务有价值,特别是售后客户服务[1,7,8,13,14,19,21,24,25]。基于生成的方法基于大规模预训练的语言模型[10,11],具有架构更简单和拟人化交互的优势。尽管取得了重大进展,但我们发现这些令牌级生成方法在实际场景中存在以下两个限制。
1. 令牌级生成方法的可靠性有限,这对面向任务的工业对话系统至关重要。由于预训练语言模型的特点,模型可能会产生从预训练语料库中学习到的响应。在某些情况下,这样的响应是无意义的,并且在语义上与当前业务领域不一致,从而中断了在线交互。更糟糕的是,模型偶尔会在多个回合中产生重复的反应(例如,反复询问用户相同的信息)。以上问题也被其他研究者[4,12]和实践者广泛观察到。
2.研究者[4,12]与实践者。令牌级生成方法可能无法满足工业系统的效率要求,特别是解码步骤较大时。令牌级生成模型的长计算时间导致在线对话系统的响应延迟不可接受,特别是当模型生成的句子长度超过阈值时(例如,对于30个单词的句子,T5为1,544 ms,如图3所示)。由于延迟问题,在高峰期可能会有大量的业务请求被挂起或阻塞。此外,上述系统所需的计算资源(例如gpu)对于小型公司来说可能负担不起。
针对以上两个问题,本文提出了一种基于行动级生成方法的面向任务的对话系统。[19]中,我们用对话动作(Dialogue Actions)来表示响应,即一类具有唯一和相同语义的响应,可以通过聚类自动获得。[19]直接将整个响应视为特定的对话动作,我们将一个响应拆分为多个响应段[6]和每个段都可以映射到一个对话动作。通过这种方式,每个响应都表示为一系列对话动作。给定对话上下文,使用带有动作级循环解码器的Seq2Seq模型来生成对话动作序列。此外,基于频率的采样方法用于根据生成的对话动作序列组成最终响应。由于我们方法的核心组件是将对话上下文作为输入和输出操作的生成模型,因此我们的方法被命名为Dialog-T - o- Actions(缩写为DTA)。与现有的基于令牌级生成的系统相比,我们的DTA具有以下优点:1)可靠性,因为生成的自然语言响应来自预定义的对话动作;2)效率,因为解码空间(即对话动作)和解码步骤要小得多。

2框架描述
2.1概述
我们遵循之前端到端面向任务的对话系统[2,9]中使用的工作流,其中系统将对话历史作为输入,并生成一个文本字符串,该文本字符串可以作为对用户或API调用的口头人员响应(例如,信息查询,操作执行等)。当调用API时,从API返回的信息将被合并到系统的下一个响应中。在图1 (b)中可以找到遵循这种系统交互生命周期的对话示例。
我们工作的关键思想是产生对话动作,然后组成一个口头回应。为此,我们首先从大规模对话中构建对话动作(步骤1),并将每个响应表示为对话动作序列(步骤2),如图1 (a)所示。使用带有动作级循环解码器的Seq2Seq模型来生成对话动作(步骤3),并使用生成的动作进一步组成口头响应(步骤4)。我们以电动自行车售后客户服务为例租赁业务,用户和员工通过短信在线交流。技术细节介绍如下。
2.2第一步:对话动作构造
对话动作是指一组具有相同语义并代表共同交际意图的话语或话语片段,如提出请求或查询信息。然而,过于简化的设置,即将整个话语抽象为一个动作,导致表达能力和可扩展性相对有限。为了使应答更有针对性和灵活性,我们基于(员工的)话语段而不是话语来构建对话动作。具体来说,每个话语被基于规则的方法[6]分成多个片段。具体来说,使用ConSERT[20]为每个话语段生成表示,然后使用K-means对片段进行聚类。我们选择簇的数量?根据经验来平衡集群的纯度和数量,并将每个片段集群视为对话动作(例如,?1和?图1 (a)中的2)。
2.3步骤2:响应标准化响应标准化
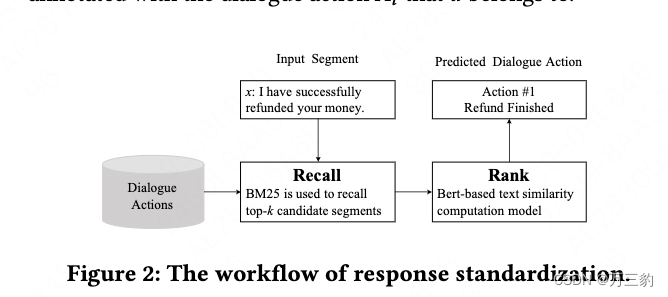
旨在通过将每个响应映射到一系列对话动作来标准化响应(来自大规模对话)。跟随Yu等人。在[23]中,我们利用了一种基于检索的方法,该方法检索与给定输入话语段最相似的聚类片段,并根据相应的聚类对输入进行标记。如图2所示,给定一个输入段?我们用BM25来召回top ?段{?1,…, ? ? }从所有聚集的段。进一步,我们开发了基于bert的文本相似度计算模型。重新排序?分段和选择。
2.4步骤3:动作序列预测
2.5步骤4:生成响应
3实验
3.1实验设置
3.2主要结果

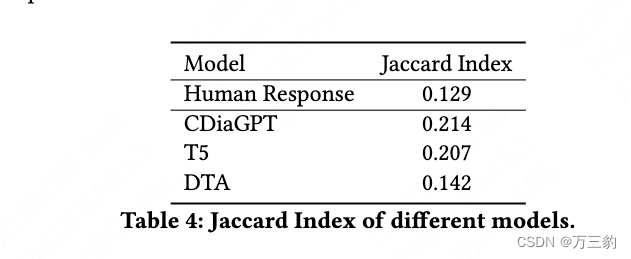
3.3深度分析
4结论
在本文中,我们提出了一个通过行动级生成的面向任务的对话系统。提出了一种有效的框架,以最小的人工工作量从大规模对话中构建生成模型。实验分析表明,该系统能够解决现有端到端生成方法所遇到的可靠性和效率问题。在未来,我们有兴趣探索将DTA中的离散模块统一到端到端架构中的集成系统。
5主持人简介
主持人:华运成。他是美团的算法工程师,专注于研究和构建对话系统。
6公司简介
美团是中国领先的购物平台,提供本地消费品和零售服务,包括娱乐、餐饮、外卖、旅游和其他服务。
Xi Xiangyu (习翔宇) - Homepage