上篇链接:C++ 类和对象(上)_chihiro1122的博客-CSDN博客
类的6个默认成员函数
我们在C当中,在写一些函数的时候,比如在栈的例子:

如上述例子,用C++ 返回这个栈是否为空,直接返回的话,这栈空间没有被释放,就会内存泄漏,如果我们直接释放这个栈,那么我们就拿不到这个栈是否为空的 bool 类型值。那么我们在C中就是用 一个 bool 类型变量来接收这函数返回的布尔值 ,然后再释放,最后返回这个 bool 类型变量的值。
这样做非常的麻烦,C++的祖师爷肯定也想到的这些,这就有了类当中的 6 个默认成员函数。
我们在 上篇中提到了 空类,那么空类当中真的是什么都不存储吗,并不是。其实在空类当中,编译器会帮我们自动的去创造 6 个默认成员函数:
其中的 构造函数和析构函数就可以帮我们自动进行 一些 如上述的初始化和 销毁的操作。
默认成员函数:用户没有显式实现,编译器会生成的成员函数称为默认成员函数。
构造函数
构造函数是一个特殊的函数,它的名字和类的名字相同,而且在创建类的类型对象的时候调用,一保证每一个成员都有一个初始值,并且,构造函数在对象的整个生命周期当中值调用一次。
特性
需要注意的是,虽然构造函数是帮助对象当中的成员初始化,但是仅仅只是初始化,并不是给这个成员创建空间。
其特性如下:
- 构造函数名和类名一样
- 没有返回值,也不需要 如 void 这样规定返回值类型
- 实例化对象时编译器会自动的调用构造函数
- 构造函数可以重载,也就是说我们可以创建多个构造函数。
定义构造函数
我们以上篇中的 栈的初始化来举例子,如果我们要用函数来实现栈的初始化的话,应该这样写:
void StackInit(Stack* ps)
{
assert(ps);
ps->array = (DataType*)malloc(sizeof(DataType) * 3);
if (NULL == ps->array)
{
assert(0);
return;
}
ps->capacity = 3;
ps->size = 0;
}如果我们用构造函数来实现话,就这样来实现:
class Stack
{
public:
Stack(int capacity = 4)
{
_array = (DataType*)malloc(sizeof(DataType) * 3);
if (NULL == _array)
{
perror("malloc申请空间失败!!!");
return;
}
_capacity = 3;
_size = 0;
}
};
我们就可以直接把在C++当中 实现的 初始化函数 copy 在这个构造函数中。
这个构造函数在创建 对象的时候就可以自动的去调用,也就是说,可以帮我们在创建对象的时候自动的去 初始化栈。这样我们在使用 这个栈的时候就不需要再去初始化一遍栈了。
而且一般构造函数都是public的,如果是private 私有的就会报错:
当然我们上述说的是一般,也就是说不是必须的,构造函数也可以是 私有的,但是这是比较 高级的玩法。
如果类中没有显式定义构造函数,则C++编译器会自动生成一个无参的默认构造函数,一旦
用户显式定义编译器将不再生成。
如果我们在类当中没有 定义 构造函数,那么编译器自动的的给我们创建一个 无参数的默认构造函数。
在C++当中分为基本类型 / 内置类型,这些是语言本身定义的类型,如 int / double / char / 指针;自定义类型,如 用 class / struct 等等来创建的类型。
如果我们不写构造函数的定义,编译器会默认生成构造函数,内置类型不做处理,自定义类型会去调用他的默认构造:
class A
{
public:
void Print()
{
cout << _a << " >>" << _b << " >> " << _c << endl;
}
protected:
int _a;
int _b;
int _c;
};
int main()
{
A a;
a.Print();
return 0;
} 输出:
我们发现没有初始化为0,这是在C++当中的语法规定的,但是现在有些新的编译器就会把这个成员默认值初始化为 0。 像VS2019 在类当中 如果在类当中定义了自定义类型的成员,那么其中的内置类型和自定义类型都会进行处理。但是 在 VS2013 就会处理。
也就是说,内置类型处不处理是编译器个性化的行为,但是在C++当中是规定 内置类型是不进行处理的,我们要默认认为他是不处理的。
所以,让编译器自己生成构造函数这种操作我们是不建议的,因为指不定这个编译器既不会对 内置类型进行 初始化0,所以,如果类当中有内置成员,我们就要自己实现构造函数来初始化 类当中的 内置成员。
如果全部都是自定义类型的成员,可以考虑让编译器自己生成。

类当中的成员的缺省值
注意:在C++11 当中,C++的开发团队也觉得,内置成员不处理,自定义成员处理,这样当时不妥当,所以大了一个补丁,不是把之前的语法改了,让函数在声明的时候可以给缺省值。
class A
{
public:
void Print()
{
cout << _a << " >>" << _b << " >> " << _c << endl;
}
protected:
int _a = 1;
int _b = 1;
int _c = 1;
};
int main()
{
A a;
a.Print();
return 0;
}输出:

我们发现上述就输出的是我们 缺省值。注意:此处不是初始化,是在声明的时候给的 缺省值。
这里的 成员的 缺省值 是给编译器默认的 构造函数用的。
因为是编译器默认使用 构造函数生成的缺省值,所以当我们在 类当中实现了 构造函数,这个缺省值就没有用了:
class A
{
public:
A(int a, int b, int c)
{
_a = a;
_b = b;
_c = c;
}
void Print()
{
cout << _a << " >>" << _b << " >> " << _c << endl;
}
protected:
int _a = 1;
int _b = 1;
int _c = 1;
};
int main()
{
A a(9,9,9);
a.Print();
return 0;
}输出:
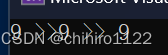
此时我们Print()函数就输出的是, 9 >> 9 >> 9 ,不是 1 >> 1 >> 1 了。
构造函数重载需要注意的点
class A
{
public:
A()
{
_a = 2;
_b = 2;
_c = 2;
}
A(int a, int b, int c)
{
_a = a;
_b = b;
_c = c;
}
void Print()
{
cout << _a << " >>" << _b << " >> " << _c << endl;
}
protected:
int _a = 1;
int _b = 1;
int _c = 1;
};如上述的两个构造函数就构成了函数重载,构造函数的形参,同样是可以有缺省参数的:
A(int a = 0, int b = 0, int c = 0)
{
_a = a;
_b = b;
_c = c;
}但是,构造函数中使用缺省参数会出现一些问题,如这个例子:
A()
{
_a = 2;
_b = 2;
_c = 2;
}
A(int a = 0, int b = 0, int c = 0)
{
_a = a;
_b = b;
_c = c;
}比如这例子,在语法上是支持的,也就是说,上述两个构造函数是支持语法的,但是在调用无参数的构造函数的时候会出现一些问题:
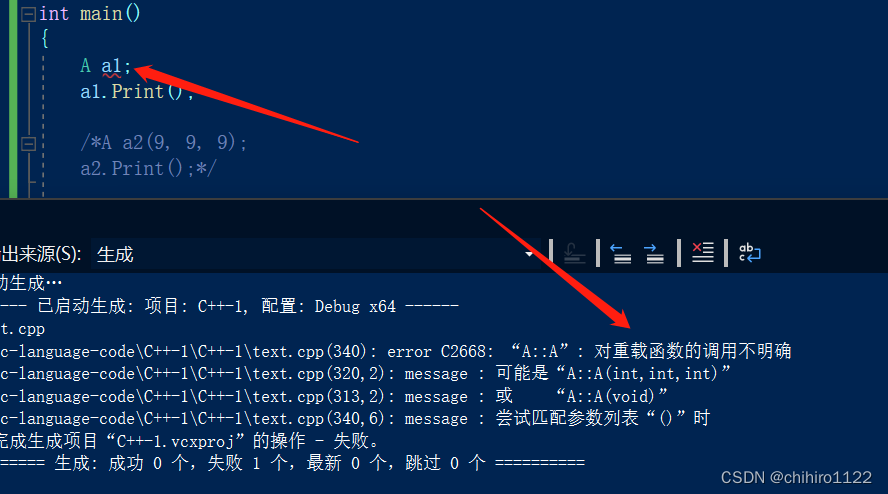
我们发现此时编译器就对该调用哪一个构造函数产生了歧义。
当然我也不能 " A a1(); " 这样写,这样写与函数声明冲突,我们在下面会讲解。
当然,我们给一个,或者两个参数都是可以的 ,因为他不会和 无参数的构造函数冲突。
所以,我们总结一下, 其实无参数构造函数和 全缺省 构造函数都属于是 默认构造函数,再加上 我们不写编译器就会生成的 默认构造函数,这三者只能有一个,因为这三者在外部的调用都是一样的编译器不能识别。
构造函数的调用
构造函数的调用跟普通函数也不太一样,普通函数代用是函数名 + 参数列表,构造函数调用是对象名 + 参数列表。
像上述的例子:
int main()
{
A a2(9,9,9);
a2.Print();
return 0;
}在类当中定义的 构造函数 是 以 类名为函数名来创建的,但是调用的时候,使用的是 创建的对象的名字。
当这个构造函数没有参数的时候,如下:
A()
{
_a = 2;
_b = 2;
_c = 2;
} 那么,就直接创建这个对象,不需要加 () 参数列表,都会自己调用 类当中 不带参数的 构造函数,如果这个例子:
class A
{
public:
A()
{
_a = 2;
_b = 2;
_c = 2;
}
A(int a, int b, int c)
{
_a = a;
_b = b;
_c = c;
}
void Print()
{
cout << _a << " >>" << _b << " >> " << _c << endl;
}
protected:
int _a = 1;
int _b = 1;
int _c = 1;
};
int main()
{
A a1;
a1.Print();
return 0;
}输出:
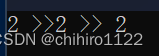
我们发现此时输出的是,无参数 构造函数 当中初始化的值。
注意:有参数是需要加 "()" 在 "()" 当中传参,而如果我们想调用 无参数的构造函数,那么我们是不能 加 "()" 的,如果加 "()" 就会报错:

这是因为,如果这样写,会跟函数声明冲突,编译器不好识别。
如上述的 " A a1(); " 是不是和 不带参数的 函数的 声明是一样,这样编译器就不好识别;但是如果是 带参数的 ,如: " A a2(9,9,9); " 这样的就不会报错了,因为这样编译器就可识别了,因为我们在声明有参数函数的时候,参数是要加 参数的类型的: " void func ( int a, int b , int c); " 这样的。而我们在调用有参数的构造函数的时候,是函数的传参,不需要 写 参数的类型。
析构函数
析构函数和构造函数的作用相反,它并不是完全的对 对象 进行销毁,局部对象进行销毁是由编译器来执行。所谓析构函数是对象在销毁的时候,才会执行的操作,来完成对象当中 一些成员的销毁工作。
特性
- 析构函数的名字和类名相同,只是在最前面加上 " ~ " 这个符号
- 没有参数和返回值
- 一个类只能有一个析构函数,若没有对析构函数进行定义,那么编译器会自动进行创建。注意:析构函数不能进行重载。
- 在对象的生命周期结束的时候,编译器会自动调用析构函数。
析构函数的定义
如上篇当中的 栈的销毁:
class Stack
{
~Stack()
{
if (_array)
{
free(_array);
_array = NULL;
_capacity = 0;
_size = 0;
}
}
}如上述的~Stack() 函数就是 析构函数,他在 栈的对象销毁的时候就会自动调用。
也就是说,在上篇中提到的,内存泄漏问题,在程序运行的最后,只需要销毁 这个对象就会自动的销毁创建的栈空间。
有了析构函数和构造函数的时候就不在怕初始化和清理函数了,也简化了。
我们上述也提到了,析构函数不写编译器也会生成默认的 析构函数,那么这个 默认的析构函数和构造函数是一样的,也是内置成员不处理,自定义成员就要按照自定义类型进行处理。
在比如上述栈的例子,如果类当中都是 自定义类型,那么我们也可以不写析构函数,编译器自动生成的 析构函数就会帮我们 清理销毁 对象空间。