CLIP 改进工作串讲(上)【论文精读·42】_哔哩哔哩_bilibili更多论文:https://github.com/mli/paper-reading, 视频播放量 64310、弹幕量 274、点赞数 1939、投硬币枚数 1332、收藏人数 821、转发人数 438, 视频作者 跟李沐学AI, 作者简介 ,相关视频:CLIP 改进工作串讲(下)【论文精读·42】,CLIP 论文逐段精读【论文精读】,Chain of Thought论文、代码和资源【论文精读·43】,72 优化算法【动手学深度学习v2】,GPT,GPT-2,GPT-3 论文精读【论文精读】,Transformer论文逐段精读【论文精读】,DALL·E 2(内含扩散模型介绍)【论文精读】,我是如何快速阅读和整理文献,AlphaFold2论文精读预告【论文精读】,如何找研究想法 1【论文精读】 https://www.bilibili.com/video/BV1FV4y1p7Lm/?spm_id_from=333.999.0.0&vd_source=4aed82e35f26bb600bc5b46e65e25c22这篇文章还是很简单的,还是通用监督分割的思路,但是融入了文本信息,其实本身在训练监督分割时也会输出类别和区域,但是这种方式就会使用文本输入产生分割区域,用text编码器给文本做强化。但是目标函数不是对比学习,也不是无监督训练的框架,并没有真正把文本当成一个监督信号来使用,还是依赖于标注的segmentation mask,数据集的稀少仍是个问题,如何摆脱标注真正的做到用文本做监督信号达到无监督训练才是最好的。
https://www.bilibili.com/video/BV1FV4y1p7Lm/?spm_id_from=333.999.0.0&vd_source=4aed82e35f26bb600bc5b46e65e25c22这篇文章还是很简单的,还是通用监督分割的思路,但是融入了文本信息,其实本身在训练监督分割时也会输出类别和区域,但是这种方式就会使用文本输入产生分割区域,用text编码器给文本做强化。但是目标函数不是对比学习,也不是无监督训练的框架,并没有真正把文本当成一个监督信号来使用,还是依赖于标注的segmentation mask,数据集的稀少仍是个问题,如何摆脱标注真正的做到用文本做监督信号达到无监督训练才是最好的。
clip应用:
分割:Lseg、GroupVit
检测:VilD、Glipv1/v2
视频:Video Clip、Clip4Clip、Actionclip
图像生成:Clipasso、VQGAN-Clip、Clip-Draw
depthclip、pointclip、anudioclip
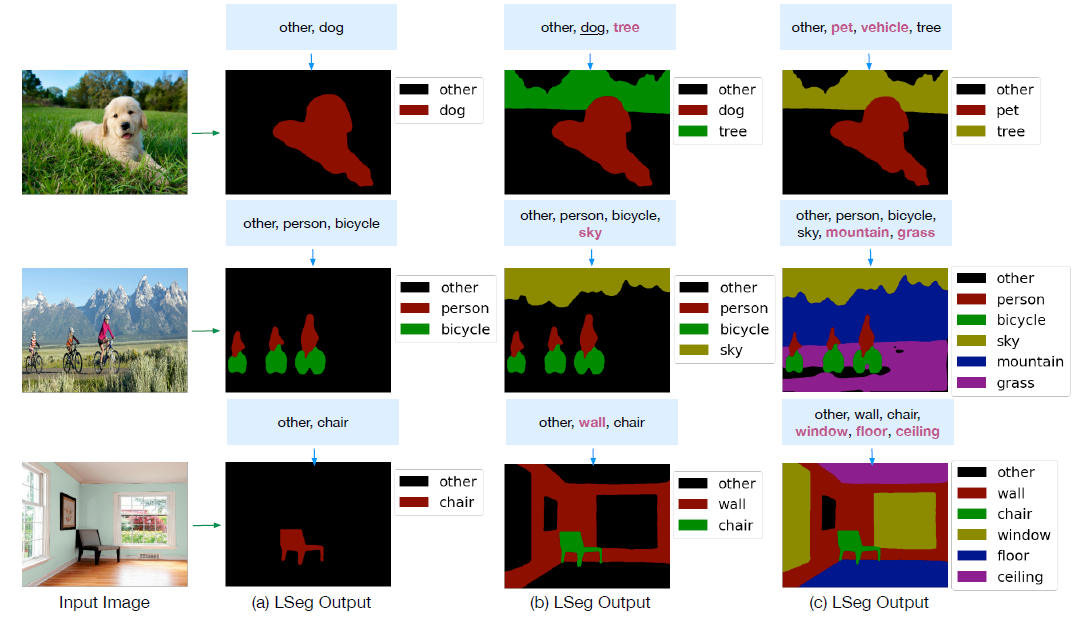
第一个例子,草地上有只狗,现在输入other和dog,就可以把狗分割出来,加上树之后,就可以把树分割出来,但是再给一个汽车的标签,图中是没有汽车的,图中确实没有分割出汽车,在给狗的超类pet,也能识别出狗,lanuage-guided的语义分割是做的挺好,虽然文章说自己是zero shot,但其实不是纯粹的自监督,还是监督标签训练的。
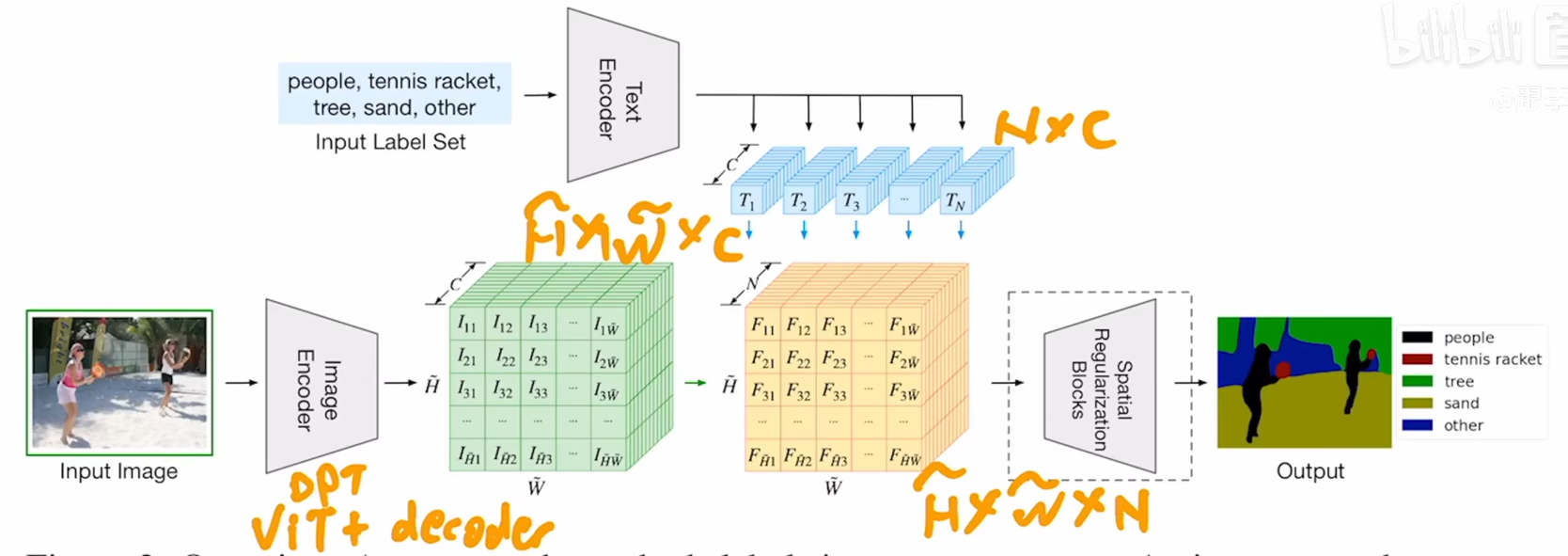
上图是本文的模型架构图,图像通过图像编码器,text经过文本编码器,先不看上面的文本编码,其实下面这个分支就是标准的语义分割,image encoder使用的是一个dpt结构,其实就是vit+decoder,decoder的作用就是把bottleneck feature慢慢的upscale上去,和之前的psp或者aspp是比较类似的层级结构,输出特征是HxWxC,其中c是512或者768,HxW可以是原来的1/4,1/16,视觉特征就抽完了。文本侧假设有n个标签,也就说people、table tennis等,把这些标签通过文本编码器,会得到n个文本特征,这里对n也是没有限制的,n是随便改变的,通过文本编码器之后,得到一个NxC矩阵,c是特征维度,是512或者768,文本和图像维特征相乘之后,得到一个HxWxN,到这里之后就和传统的监督学习一样了。拿到特征之后和gt去做cross entropy loss。
这篇文章虽说是zero shot,但其实在训练过程中,有监督训练的,在7个分割数据集上训练出来的,目标函数就是和gt做cross entropy loss,而不是像clip一样对对比学习的loss,它不是一个无监督的工作。其实只是把文本加到有监督分割中,把文本和图像特征结合起来,模型在训练时,能学到一些language aware的这种视觉特征,从而最后在做推理时,能用文本这种prompt得到分割图。
这里的文本编码器用的是clip中的文本编码器,这块是是锁住的,不参与训练,可能是分割数据集比较小,参与训练会带偏权重,图像编码器是vit+decoder,其中vit可以用clip的,也可以用预训练的vit或者deit的,后者效果要好一点,在最后输出上作者加了spatial regularization block,其实就是一些conv和depthwise conv,作者觉得在图像和文本特征相乘之后还应该有一些学习参数在后面,能够更好的学会文本和图像之间的交互,这个2个block最好,这是实验得到的。
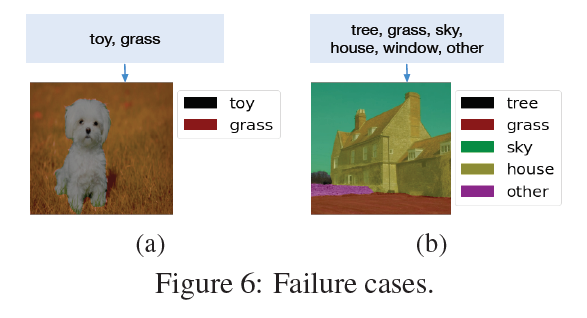
看一下这篇文章中的badcase,文本给的是toy和grass,最终把狗判成了toy,一切使用clip的工作本质上还是计算图像和文本之间的相似性,并不是在真正做一个分类,小狗肯定不是草,因此把狗分成了玩具。