一、前言
Redis在我们日常开发中是经常用到的,Redis也是功能非常强大,可以进行缓存,还会有一些排行榜、点赞、消息队列、购物车等等;当然还有分布式锁Redisson,我们使用肯定少不了集群!小编最近学习到一些内存如果满了Redis是怎么操作呢?肯定像我们JVM一样,有回收或者淘汰的机制!
Redis的数据已经设置了TTL,不是过期就已经删除了吗?为什么还存在所谓的淘汰策略呢?这个原因我们需要从redis的过期策略聊起。
二、自己配置Redis内存大小
redis安装上,如果你不配置的话,默认就是按你的电脑内存的大小。
我们打开配置文件看一下哈!这里以6.0.6配置文件为例
打开redis.conf文件:856行:
我们可以设置大小,我们可以看到是以字节为单位的哈!
maxmemory <bytes>
我们可以使用命令查询内存大小:
127.0.0.1:6379> config get maxmemory
1) "maxmemory"
2) "0"
不配置默认为0使用电脑最大内存。
当然也可以通过命令进行设置:
127.0.0.1:6379> config set maxmemory 2
OK
127.0.0.1:6379> config get maxmemory
1) "maxmemory"
2) "2"
127.0.0.1:6379> set k1 wang
(error) OOM command not allowed when used memory > 'maxmemory'.
根据测试:我们发现redis也会像JVM一样报OOM异常
心得: 我们一般不会调整Redis的内存大小,如果调也是一般像HashMap的加载因子一样,也就是3/4即可
三、三大过期策略
三大过期策略:定时删除、惰性删除、定期删除
过期策略存在原因:
Redis不可能时时刻刻遍历所有被设置了生存时间的key,来检测数据是否已经到达过期时间,然后对它进行删除。
1. 定时删除
定时删除又名立即删除:能保证内存中数据的最大新鲜度,因为它保证过期键值会在过期后马上被删除,其所占用的内存也会随之释放。但是立即删除对cpu是最不友好的。因为删除操作会占用cpu的时间,如果刚好碰上了cpu很忙的时候,比如正在做交集或排序等计算的时候,就会给cpu造成额外的压力,让CPU心累,时时需要删除,忙死。
这会产生大量的性能消耗,同时也会影响数据的读取操作。
2. 惰性删除
数据到达过期时间,不做处理。等下次访问该数据时,如果未过期,返回数据;发现已过期,删除,返回不存在。
惰性删除策略的缺点是,它对内存是很不友好的。
如果一个键已经过期,而这个键又仍然保留在数据库中,那么只要这个过期键不被删除,它所占用的内存就不会释放。
在使用惰性删除策略时,如果数据库中有非常多的过期键,而这些过期键又恰好没有被访问到的话,那么它们也许永远也不会被删除(除非用户手动执行FLUSHDB),我们甚至可以将这种情况看作是一种内存泄漏 – 无用的垃圾数据占用了大量的内存,而服务器却不会自己去释放它们,这对于运行状态非常依赖于内存的Redis服务器来说,肯定不是一个好消息。
3. 定期删除
定期删除策略是前两种策略的折中:
定期删除策略每隔一段时间执行一次删除过期键操作,并通过限制删除操作执行的时长和频率来减少删除操作对CPU时间的影响。
周期性轮询Redis库中的时效性数据,来用随机抽取的策略,利用过期数据占比的方式控制删除频度
特点1:CPU性能占用设置有峰值,检测频度可自定义设置
特点2:内存压力不是很大,长期占用内存的冷数据会被持续清理
4. 附例子:
redis默认每个100ms检查,是否有过期的key,有过期key则删除。
注意:redis不是每隔100ms将所有的key检查一次而是随机抽取进行检查(如果每隔100ms,全部key进行检查,redis直接进去ICU)。因此,如果只采用定期删除策略,会导致很多key到时间没有删除。
定期删除策略的难点是确定删除操作执行的时长和频率:如果删除操作执行得太频繁,或者执行的时间太长,定期删除策略就会退化成定时删除策略,以至于将CPU时间过多地消耗在删除过期键上面。如果删除操作执行得太少,或者执行的时间太短,定期删除策略又会和惰性删除束略一样,出现浪费内存的情况。因此,如果采用定期删除策略的话,服务器必须根据情况,合理地设置删除操作的执行时长和执行频率。
5. 总结
定时删除 :对CPU不友好,用处理器性能换取存储空间(拿时间换空间) 惰性删除:对memory不友好,用存储空间换取处理器性能(拿空间换时间) 定期删除:周期性抽查存储空间,随机抽查,重点抽查(存在漏网之鱼)
6.思考
我们会发现,三种情况都存在瑕疵,如果数据量大,一定会出现内存满了,报OOM!所以我们下面引出八大淘汰策略!!
四、八大淘汰策略
我们还是打开redis.conf配置文件,找到861行:
# volatile-lru -> Evict using approximated LRU, only keys with an expire set.
# allkeys-lru -> Evict any key using approximated LRU.
# volatile-lfu -> Evict using approximated LFU, only keys with an expire set.
# allkeys-lfu -> Evict any key using approximated LFU.
# volatile-random -> Remove a random key having an expire set.
# allkeys-random -> Remove a random key, any key.
# volatile-ttl -> Remove the key with the nearest expire time (minor TTL)
# noeviction -> Don't evict anything, just return an error on write operations.
我们来翻译一下哈:
volatile-lru:当内存放不下新添加的数据时,从设置了过期时间的key中使用LRU(最近最少使用)算法进行删除key;
allkeys-lru:当内存放不下新添加的数据时,从所有key中使用LRU(最近最少使用)算法进行删除key。
volatile-lfu:当内存放不下新添加的数据时,从设置了过期时间的key中,使用LFU(最近频繁使用)算法进行删除key。
allkeys-lfu:当内存放不下新添加的数据时,从所有key中使用LFU(最近频繁使用)算法进行删除key;
volatile-random:当内存放不下新添加的数据时,从设置了过期时间的key中,随机删除key;。
allkeys-random:当内存放不下新添加的数据时,从所有key中随机删除key。
volatile-ttl:当内存放不下新添加的数据时,在设置了过期时间的key中,根据过期时间进行淘汰,越早过期的优先被删除key;
noeviction:当内存放不下新添加的数据时,新写入操作会报错。默认策略
五、手动配置淘汰策略
打开redis.conf配置文件找到:887行,把注释去掉,添加自己需要的淘汰策略
maxmemory-policy noeviction
当然我们也可以使用命令进行修改:
127.0.0.1:6379> config set maxmemory-policy allkeys-Lru
OK
127.0.0.1:6379> config get maxmemory-policy
1) "maxmemory-policy"
2) "allkeys-lru"
LRU
标准LRU实现方式
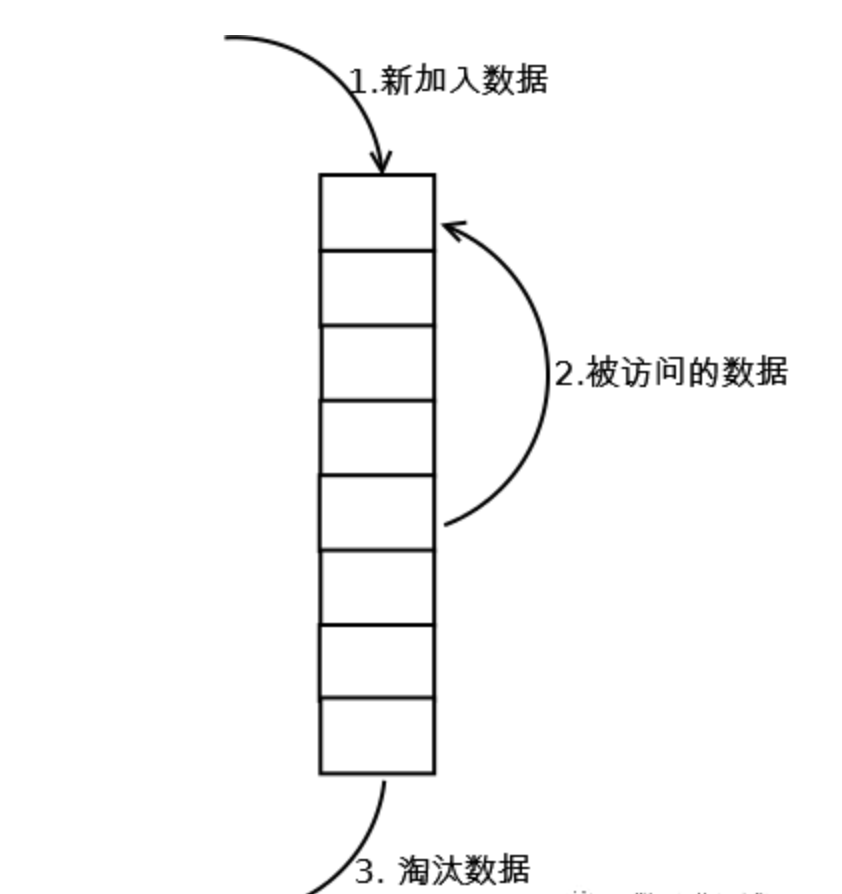
-
新增key value的时候首先在链表结尾添加Node节点,如果超过LRU设置的阈值就淘汰队头的节点并删除掉HashMap中对应的节点。
-
修改key对应的值的时候先修改对应的Node中的值,然后把Node节点移动队尾。
-
访问key对应的值的时候把访问的Node节点移动到队尾即可。
Redis的LRU实现
Redis维护了一个24位时钟,可以简单理解为当前系统的时间戳,每隔一定时间会更新这个时钟。每个key对象内部同样维护了一个24位的时钟,当新增key对象的时候会把系统的时钟赋值到这个内部对象时钟。比如我现在要进行LRU,那么首先拿到当前的全局时钟,然后再找到内部时钟与全局时钟距离时间最久的(差最大)进行淘汰,这里值得注意的是全局时钟只有24位,按秒为单位来表示才能存储194天,所以可能会出现key的时钟大于全局时钟的情况,如果这种情况出现那么就两个相加而不是相减来求最久的key。
Redis中的LRU与常规的LRU实现并不相同,常规LRU会准确的淘汰掉队头的元素,但是Redis的LRU并不维护队列,只是根据配置的策略要么从所有的key中随机选择N个(N可以配置)要么从所有的设置了过期时间的key中选出N个键,然后再从这N个键中选出最久没有使用的一个key进行淘汰。
下图是常规LRU淘汰策略与Redis随机样本取一键淘汰策略的对比,浅灰色表示已经删除的键,深灰色表示没有被删除的键,绿色表示新加入的键,越往上表示键加入的时间越久。从图中可以看出,在redis 3中,设置样本数为10的时候能够很准确的淘汰掉最久没有使用的键,与常规LRU基本持平。
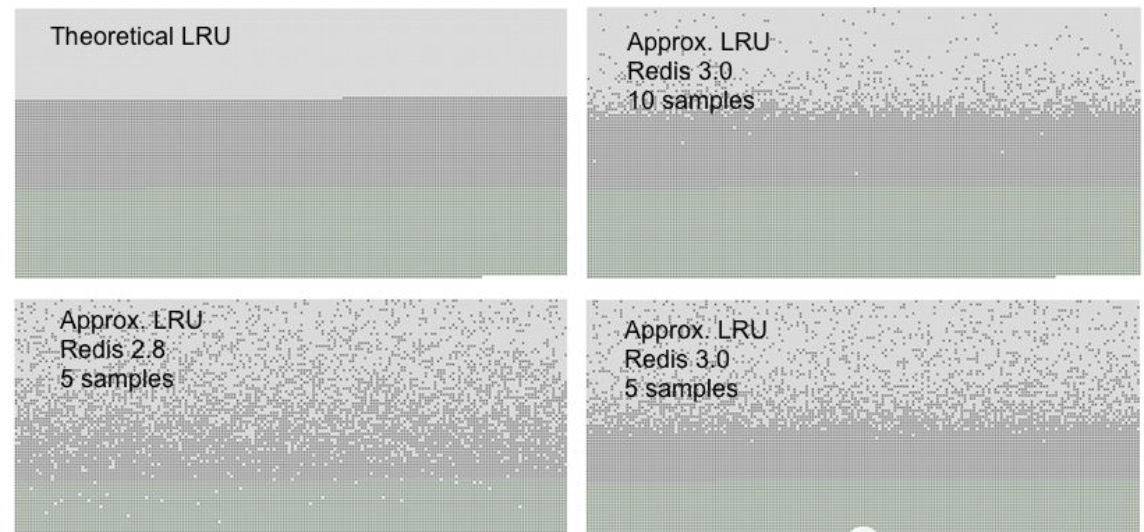
为什么要使用近似LRU?
1、性能问题,由于近似LRU算法只是最多随机采样N个key并对其进行排序,如果精准需要对所有key进行排序,这样近似LRU性能更高
2、内存占用问题,redis对内存要求很高,会尽量降低内存使用率,如果是抽样排序可以有效降低内存的占用
3、实际效果基本相等,如果请求符合长尾法则,那么真实LRU与Redis LRU之间表现基本无差异
4、在近似情况下提供可自配置的取样率来提升精准度,例如通过 CONFIG SET maxmemory-samples 指令可以设置取样数,取样数越高越精准,如果你的CPU和内存有足够,可以提高取样数看命中率来探测最佳的采样比例。
LFU
LFU是在Redis4.0后出现的,LRU的最近最少使用实际上并不精确,考虑下面的情况,如果在|处删除,那么A距离的时间最久,但实际上A的使用频率要比B频繁,所以合理的淘汰策略应该是淘汰B。LFU就是为应对这种情况而生的。
A~~A~~A~~A~~A~~A~~A~~A~~A~~A~~~|
B~~~~~B~~~~~B~~~~~B~~~~~~~~~~~~B|
LFU把原来的key对象的内部时钟的24位分成两部分,前16位还代表时钟,后8位代表一个计数器。16位的情况下如果还按照秒为单位就会导致不够用,所以一般这里以时钟为单位。而后8位表示当前key对象的访问频率,8位只能代表255,但是redis并没有采用线性上升的方式,而是通过一个复杂的公式,通过配置如下两个参数来调整数据的递增速度。
lfu-log-factor:可以调整计数器counter的增长速度,lfu-log-factor越大,counter增长的越慢。
lfu-decay-time:是一个以分钟为单位的数值,可以调整counter的减少速度。
所以这两个因素就对应到了LFU的Counter减少策略和增长策略,它们实现逻辑分别如下。
降低LFUDecrAndReturn
1、先从高16位获取最近的降低时间ldt以及低8位的计数器counter值
2、计算当前时间now与ldt的差值(now-ldt),当ldt大于now时,那说明是过了一个周期,按照65535-ldt+now计算(16位一个周期最大65535)
3、使用第2步计算的差值除以lfu_decay_time,即LFUTimeElapsed(ldt) / server.lfu_decay_time,已过去n个lfu_decay_time,则将counter减少n。
增长LFULogIncr
1、获取0-1的随机数r
2、计算0-1之间的控制因子p,它的计算逻辑如下
//LFU_INIT_VAL默认为5baseval = counter - LFU_INIT_VAL;//计算控制因子p = 1.0/(baseval*lfu_log_factor+1);
3、如果r小于p,counter增长1
p取决于当前counter值与lfu_log_factor因子,counter值与lfu_log_factor因子越大,p越小,r小于p的概率也越小,counter增长的概率也就越小。增长情况如下图:
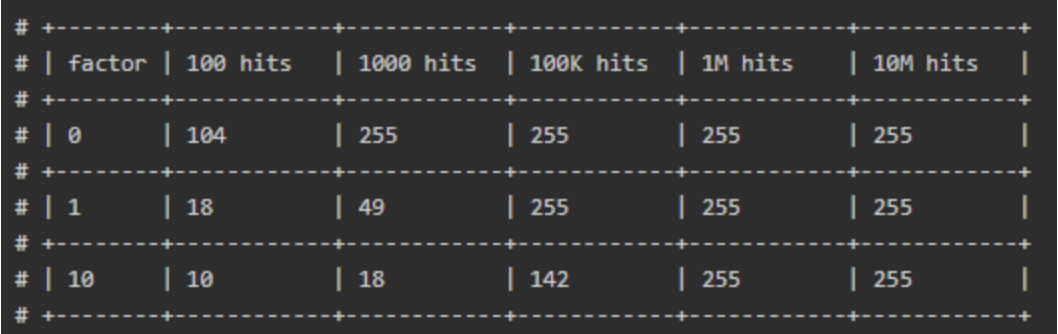
从左到右表示key的命中次数,从上到下表示影响因子,在影响因子为100的条件下,经过10M次命中才能把后8位值加满到255。
新生KEY策略
另外一个问题是,当创建新对象的时候,对象的counter如果为0,很容易就会被淘汰掉,还需要为新生key设置一个初始counter。counter会被初始化为LFU_INIT_VAL,默认5。
六、总结
这样我们对Redis就有了进一步的了解,谢谢大家跟着小编一起走下来,看到这里还不动一下你的发财小手点个关注哈!!