文章目录
- 背景
- 参考1:[输入不同长度的向量,输出相同长度](https://www.zhihu.com/question/569406523/answer/2780168200):
- 参考2:[多种尺寸的图像数据训练没有全连接层的卷积神经网络模型](https://www.zhihu.com/question/533481647)
- 参考3:[目标检测里的多尺度技术](https://zhuanlan.zhihu.com/p/266887169):
- 参考4:[SPP-Net:精进特征提取 + 开拓多尺度训练](https://blog.csdn.net/Abandon_first/article/details/117021640)
- 个人总结
- 参考
背景
在阅读《Swin Transformer using shifted windows》 时,有一段话:we consider four typical object detection frameworks: Cascade Mask R-CNN [29, 6], ATSS [79], RepPoints v2 [12], and Sparse RCNN [56] in mmdetection [10]. For these four frameworks, we utilize the same settings: multi-scale training [8, 56] (resizing the input such that the shorter side is between 480 and 800 while the longer side is at most 1333),
multi-scale training [8, 56]
end-to-end object detection with transformers
Sparse r-cnn: End-to-end object detection with learnable proposals
Swin 也采用了 multi-scale training [8, 56]。
参考1:输入不同长度的向量,输出相同长度:
之前的卷积目标检测,多尺度训练对全卷积网络有效,一般设置几种不同尺度的图片,训练时每隔一定iterations随机选取一种尺度训练。这样训练出来的模型鲁棒性强,其可以接受任意大小的图片作为输入,使用尺度小的图片测试速度会快些,但准确度低,用尺度大的图片测试速度慢,但是准确度高。
如果不是基于序列的场景,应该要求输入的信息的大小是约定好的,比如在图像分类中,一般的输入大小为 224(可以进行预处理,将不是该大小的图像进行scale,保证最长边为224后,对左右或上下进行padding保证到该大小), 在目标检测中,也约定好了训练或推理的大小,比如centernet支持大小为 512 的输入。当然,对于卷积神经网络,如果没有全连接层,训练时不同的iteration或推理时不同的输入是可以支持不同大小的。但是对于训练时的一次mini batch的输入或者多帧推理,输入大小要保持一致。
对于有全连接层的网络结构,一般是不支持输入动态变化的,除非中间有个将输入到全连接的张量约束到特定的大小的操作,比如Faster RCNN有个ROI Pooling,约束输入到全连接层的特征图大小为7 × 7 。
对于基于序列的结构,序列的长度一般变化的,如句子有长短,视频帧有多少,但好像和本题所描述的不是一个问题,本题主要说的是一个单元的输入向量。
参考2:多种尺寸的图像数据训练没有全连接层的卷积神经网络模型
可以的,目前的卷积神经网络除了最后的分类层是全连接层,而特征提取部分都是卷积或者池化操作,它们可以自适应各种尺寸的图像输入。特征提取之后一般是一个全局平均池化层,这个也自适应各种图像尺寸,得到相同大小的特征用于最后的分类层。所以,卷积神经网络完全可以采用多种尺寸的图像数据训练。
其实EfficientNetv2也采用了多尺度训练,逐步增加图像的大小。
参考3:目标检测里的多尺度技术:
- One Stage网络的Multi-scale Training。
这是今天讨论的所有情况中最简单的一个。即每sample一个batch的数据喂入网络中训练时,都会先对采样出的数据resize+padding到一个随机大小。而这个大小的波动范围是实现预设好的。我们来看一下yolov2是怎么描述多尺度训练的:
每10个batches,就随机从{320,352,…,608}这些尺度里随机采样一个,作为后10个batches的训练尺度。yolov2测试时用的尺度是固定的416x416。当然可以用更大或者更小尺度去测试完全ok,这里的416x416只是论文为了报点取的速度和精度的权衡位置。
我们再来看MMDetection里的FCOS是如何做多尺度训练的:
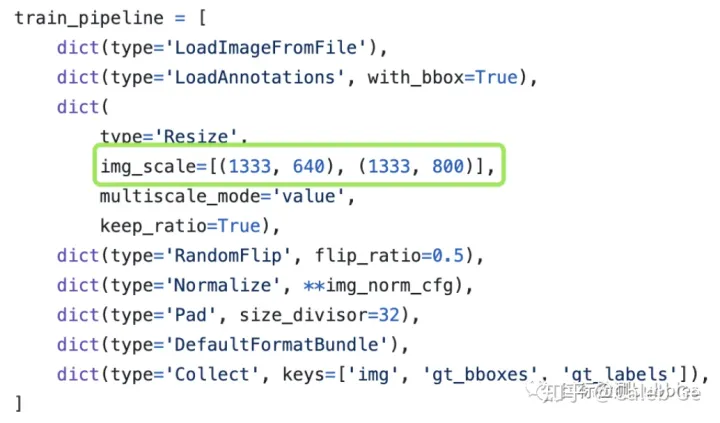
解释下这里的[(1333,640), (1333, 800)]的含义。1333表示做预处理的时候,长边不可以超过1333,那相对的,640和800就代表短边所不能超过的值。在训练阶段,长边定死不超过1333,短边会随机从[640,800]中取一个32的整数倍的数。同一张图在面对(1333,640)和(1333,800)这两种限制的时候,resize后满足条件的面积很大概率是不一样的,通过控制短边的上限,就可以达到动态控制图片大小的目的。另外MMDetection是每个batch都会去随机选取短边尺度的。
Yolo和FCOS这两种方式虽然细节上有略微区别(当然本质是yolo和retinanet默认配置的区别),但不影响对多尺度训练的理解。即训练的时候用不同的尺度去帮助模型适应各种大小的目标,获得对尺寸鲁棒性。
多尺度训练一个明显的好处是:不增加推理时间。所以不管是业务还是竞赛,大胆上多尺度训练就对了。还有一些值得一说的地方:
1). 最后输出是全连接的网络不能用多尺度。原因很简单,尺度变了,最后一层的权重数量就对不上输入数量了。比如yolov1和带有flatten接fc的分类网络(如VGG)。
2). 多尺度训练,在合理范围内扩大多尺度的范围,是能获得更高收益的。比如上文中FCOS的短边范围[640, 800]。这个域扩充到[480, 960],还可以获得非常可观的收益。当然什么是合理的范围,需要各位自己去把控品味了。
2. One Stage网络的Multi-scale Testing。
One Stage网络的测试也比较直观,见下图:
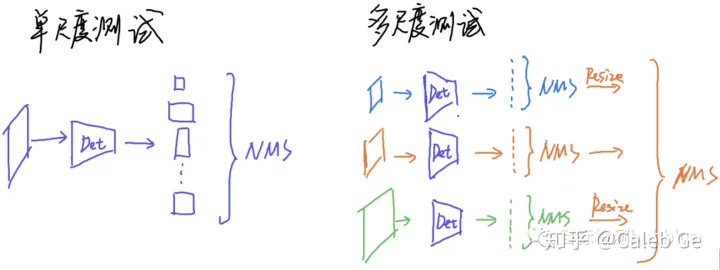
可以看到多尺度测试分为3步:
Step1. 各自尺度进行单尺度测试
Step2. 把所有尺度归一化到同一个尺度,如图,蓝色预测和绿色预测的框都是在不同大小的图片下出的,这样所有结果放到一起NMS是对不上的。所以,图里为了表示明白,把蓝色和绿色的预测框都按照图片相对橙色的大小比例进行缩放。Step3. 缩放对齐后的结果放到一起做NMS。
需要注意的是,先对每个单尺度做NMS可以大量减少后续操作的时间,所以先进行一次NMS是比较合理的。
多嘴一句 多尺度训练了一定记住开启多尺度测试 之前亲测一个比赛项目,启动了多尺度训 然后是否开启多尺度测 结果会相差10个点,…
参考4:SPP-Net:精进特征提取 + 开拓多尺度训练
现有的(传统的) CNNs 由于有全连接层所以必须需要固定输入图片的尺寸,比如 224 × 224 。本文为传统的网络结构增加了一个池化策略,即空间金字塔池化,spatial pyramid pooling,来突破全连接层对整个网络输入图像的约束。无论输入图像的尺寸是多少,SPP-Net 能够产生一个固定长度的特征向量,且能够适应形变,在分类和物体检测任务中都有很好的表现(妈妈再也不用担心我训练网络要被动地特意去 crop 或者 warp 啦~当然你还是可以主动选择用这个来做 data augmentation)。
传统 CNN 网络可以大致分为卷积和全连接两部分,其中卷积层是不挑输入图像尺寸的,完全是全连接的存在,才导致整个网络必须固定输入图像的大小。
空间金字塔池化原本就存在,是一种传统图像处理方法理论,算是一种词袋模型的拓展。它把图像的特征分成了不同的粒度有粗有细,组合在一起输出(相比单一尺度的特征要更能表达/代表原图)。
空间金字塔池化的加入,使得模型在预测/测试时可以不限定输入图像的大小,同时在训练阶段,也允许模型实现多尺度训练,这一点很有利于增强尺度不变性并降低过拟合的风险。
个人总结
1、从图像层次的多尺度。这个就是不同scale的图片输入网络,进行训练。这个对网络模型有设计要求,如果存在全连接这个硬性的尺寸约束,需要在全连接前做处理,例如采用SSP(池化策略),或全局平均池化层。如果采用yolo v2 这种全卷积的方式,没有全连接,可以支持图像的多尺度。
2、特征多尺度。这feature map上进行多尺度检测。有不同的操作方案:例如,FPN特征金字塔网络:将低层的特征和高层的特征融合起来,在不同的特征层都单独进行预测。或者SSD的从网络不同层抽取不同尺度的特征,然后在这不同尺度的特征上分别进行预测。低层的特征对于小物体检测比较有效。
参考
https://blog.csdn.net/qq_36758461/article/details/99984228
《目标检测 | 解决小目标检测!多尺度方法汇总 》